Google的MLP-MIXer的复现(pytorch实现)
该模型原论文实现用的jax框架实现,先贴出原论文的代码实现:
# Copyright 2024 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Any, Optional
import einops
import flax.linen as nn
import jax
import jax.numpy as jnp
class MlpBlock(nn.Module):
mlp_dim: int
@nn.compact
def __call__(self, x):
y = nn.Dense(self.mlp_dim)(x)
y = nn.gelu(y)
return nn.Dense(x.shape[-1])(y)
class MixerBlock(nn.Module):
"""Mixer block layer."""
tokens_mlp_dim: int
channels_mlp_dim: int
@nn.compact
def __call__(self, x):
y = nn.LayerNorm()(x)
y = jnp.swapaxes(y, 1, 2)
y = MlpBlock(self.tokens_mlp_dim, name='token_mixing')(y) # (32, 512, 196)
y = jnp.swapaxes(y, 1, 2)
x = x + y
y = nn.LayerNorm()(x)
return x + MlpBlock(self.channels_mlp_dim, name='channel_mixing')(y)
class MlpMixer(nn.Module):
"""Mixer architecture."""
patches: Any
num_classes: int
num_blocks: int
hidden_dim: int
tokens_mlp_dim: int
channels_mlp_dim: int
model_name: Optional[str] = None
@nn.compact
def __call__(self, inputs, *, train):
del train
x = nn.Conv(self.hidden_dim, self.patches.size,
strides=self.patches.size, name='stem')(inputs)
x = einops.rearrange(x, 'n h w c -> n (h w) c') # 从(32,512,14,14)变成了(32,196,512)
for _ in range(self.num_blocks):
x = MixerBlock(self.tokens_mlp_dim, self.channels_mlp_dim)(x)
x = nn.LayerNorm(name='pre_head_layer_norm')(x)
x = jnp.mean(x, axis=1)
if self.num_classes:
x = nn.Dense(self.num_classes, kernel_init=nn.initializers.zeros,
name='head')(x)
return x
model_params = {
'patches': {'size': (16, 16), 'stride': (16, 16)}, # 这里需要一个描述patch大小和步长的对象,例如Flax的stem模块初始化参数
'num_classes': 10, # 分类任务的类别数
'num_blocks': 8, # Mixer Block的重复次数
'hidden_dim': 512, # 隐藏层维度
'tokens_mlp_dim': 256, # token mixing的MLP维度
'channels_mlp_dim': 2048, # channel mixing的MLP维度
}
# 准备输入数据,例如一批32张图片,每张图片尺寸为512x14x14(假设已经按要求预处理)
# 初始化模型
seed=0
key = jax.random.PRNGKey(seed)
model = MlpMixer.apply(key, **model_params)
input_data = jnp.ones((4096, 224, 224, 3)) # 示例输入数据
# 调用模型进行前向传播
output = model(input_data)
print("Output shape:", output) # 打印输出形状,预期是(32, 10)如果num_classes=10
该模型的总体框架图如下所示:
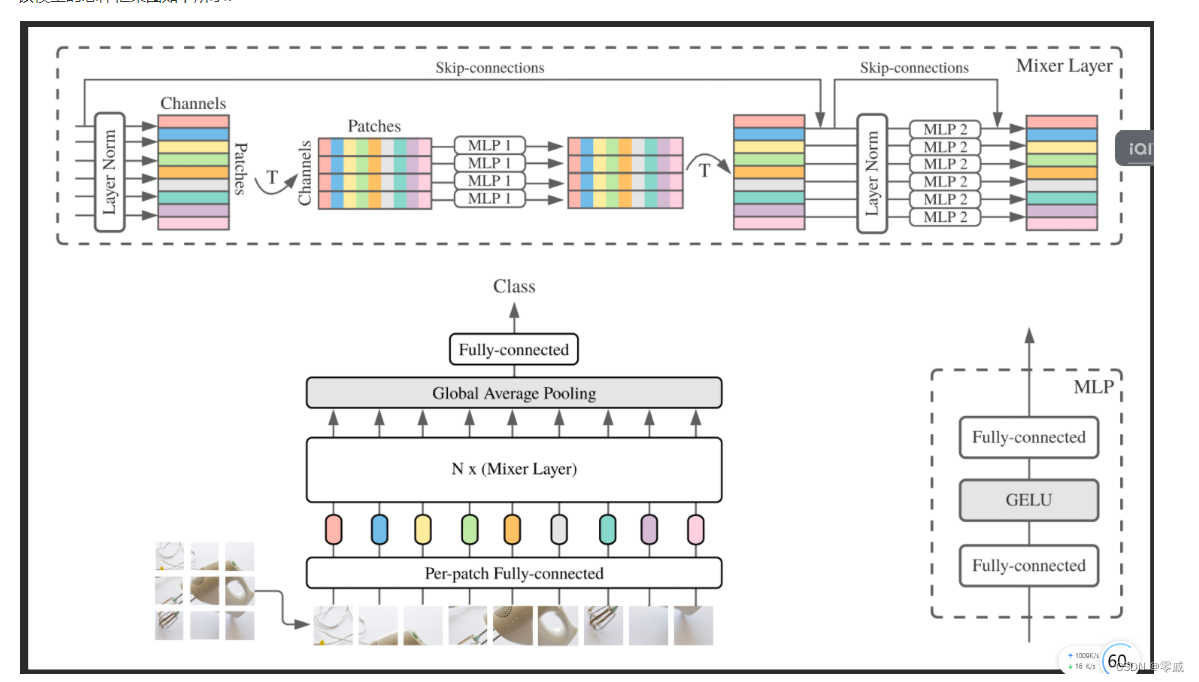
对该框架的讲解,网上已经很多了,就不在此赘述。
实现的pytorch代码如下所示:
class MlpBlock(nn.Module):
def __init__(self, in_mlp_dim=196, out_mlp_dim=256):
super(MlpBlock, self).__init__()
self.mlp_dim = out_mlp_dim
self.dense1 = nn.Linear(in_mlp_dim, out_mlp_dim) # 若输入的向量为[32,196, 512]则输入的也应该是512,输出可以自己定
self.gelu = nn.GELU()
self.dense2 = nn.Linear(out_mlp_dim, in_mlp_dim)
def forward(self, x):
y = self.dense1(x)
y = self.gelu(y)
y = self.dense2(y)
return y
class MixerBlock(nn.Module):
def __init__(self, tokens_mlp_dim=256, channels_mlp_dim=2048, batch_size=32):
super(MixerBlock, self).__init__()
self.batch_size = batch_size
self.norm1 = nn.LayerNorm(512) # 对512维的做归一化,默认给最后一个维度做归一化
self.token_Mixing = MlpBlock(out_mlp_dim=tokens_mlp_dim)
self.norm2 = nn.LayerNorm(512) # 对512维的做归一化
self.channel_mixing = MlpBlock(in_mlp_dim=512, out_mlp_dim=channels_mlp_dim)
def forward(self, x):
y = self.norm1(x)
y = y.permute(0, 2, 1)
y = self.token_Mixing(y)
y = y.permute(0, 2, 1)
x = x + y
y = self.norm2(x)
return x + self.channel_mixing(y)
class MlpMixer(nn.Module):
def __init__(self, patches, num_classes, num_blocks, hidden_dim, tokens_mlp_dim, channels_mlp_dim):
super(MlpMixer, self).__init__()
self.stem = nn.Conv2d(3, hidden_dim, kernel_size=patches, stride=patches)
self.mixer_block_1 = MixerBlock()
self.mixer_blocks = nn.ModuleList([MixerBlock(tokens_mlp_dim, channels_mlp_dim) for _ in range(num_blocks)])
self.pre_head_norm = nn.LayerNorm(hidden_dim)
self.head = nn.Linear(hidden_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward(self, x):
x = self.stem(x)
b, c, h, w = x.shape
x = x.view(b, c, -1).permute(0, 2, 1)
for mixer_block in self.mixer_blocks:
x = mixer_block(x)
x = self.pre_head_norm(x)
x = x.mean(dim=1)
x = self.head(x)
return x
# model = MlpMixer(16, 10, 6, 512, 256, 2048)
# input_tensor = torch.randn(32, 3, 224, 224) # (batch size, num_patches, input_dim)
# output = model(input_tensor)
# print(output)
在将flax框架的代码改为pytorch实现的时候,还是踩了不少的坑,在此讲一下,希望后面做的人,可以避免。
1.在flax框架的nn.linear层中没有输入维度,只有一个输出维度。
2.在处理两个差异的时候,如输入维度[32,196,512],其中代表的意思分别为batch_size为32,196为图片在经过patch之后的224*224输入之后经过patch=16,变为14 * 14即196,512会在二维卷积处理之后输出的channel类似。
1.在flax框架的nn.linear层中没有输入维度,只有一个输出维度。
2.在处理两个差异的时候,如输入维度[32,196,512],其中代表的意思分别为batch_size为32,196为图片在经过patch之后的224*224输入之后经过patch=16,变为14 * 14即196,512会在二维卷积处理之后输出的channel类似。
在nn.linear那儿的in_channel与第三个维度保持一致,就可以不必将其三维的转换为二维的。同时在对layernorm那儿转换的时候,默认也是对最后一个维度进行正则化。