Attention as an RNN
公众号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
3. 方法
3.1 注意力作为一种(多对一的)RNN
3.2 注意力作为(多对多)RNN
3.3 Aaren: 将注意力当作 RNN
4. 实验
附录
F. 计算时间
0. 摘要
随着 Transformer 的出现,序列建模领域取得了重大突破,为利用 GPU 并行性提供了高性能的架构。然而,Transformer 在推理时计算开销较大,限制了其在低资源环境(例如移动和嵌入式设备)中的应用。为了解决这个问题,我们采取了以下步骤:
- 首先,我们展示了注意力机制可以被视为一种特殊的递归神经网络(RNN),能够高效地计算其多对一的 RNN 输出。
- 接着,我们证明了流行的基于注意力的模型(如 Transformer)可以视为 RNN 的变体。然而,与传统的 RNN(如 LSTM)不同,这些模型无法高效地用新 token 更新,这在序列建模中是一个重要特性。
- 为了解决这个问题,我们引入了一种基于并行前缀(prefix)扫描算法的新的高效计算注意力多对多 RNN 输出的方法。
- 基于新的注意力公式,我们推出了 Attention as a recurrent neural network(Aaren),这是一种基于注意力的模块,不仅可以像 Transformer 一样并行训练,还能像传统 RNN 一样高效地用新 token 进行更新,只需要固定内存来进行推理。
在实验中,我们展示了 Aaren 在四个流行的序列问题设置中的 38 个数据集上,表现与 Transformer 相当,但在时间和内存效率上更优。这些问题设置包括强化学习、事件预测、时间序列分类和时间序列预测任务。
3. 方法
3.1 注意力作为一种(多对一的)RNN
对一个查询向量 q 的注意力可以被看作一个函数,该函数将 N 个上下文 token x_(1:N) 通过它们的键和值 {(ki, vi)}^N_(i=1) 映射到一个单一的输出 o_N = Attention(q, k_(1:N), v_(1:N))。给定 s_i = dot(q, ki),输出 o_N 表示为:

将注意力视为一种 RNN,我们可以将其迭代计算为滚动求和
![]()
其中 k=1,…,N。然而,在实践中,这是一种不稳定的实现,会由于有限精度表示和可能非常小或非常大的指数(即,exp(s))而遇到数值问题。为缓解这一问题,我们通过累积最大值项
![]()
重写递归关系,改为计算
![]()
值得注意的是,最终结果是相同的,即 o_N = ^a_N / ^c_N= a_N /c_N。因此,a_k、c_k 和 m_k 递归地计算如下:

通过将 a_k、c_k 和 m_k 的递归计算从 a_(k-1)、c_(k-1) 和 m_(k-1) 中封装起来,我们引入了一个 RNN 单元,用于迭代计算注意力的输出(见图 2)。注意力的 RNN 单元以 (a_(k-1), c_(k-1), m_(k-1), q) 作为输入,并计算 (ak,ck,mk,q)。请注意,查询向量 q 在 RNN 单元中被传递。注意力的 RNN 的初始隐藏状态为 (a_0, c_0, m_0, q) = (0, 0, 0, q)。

计算注意力的方法。通过将注意力视为一种 RNN,我们可以看到有不同的计算注意力的方法:
- 在 O(1) 内存中逐 token 递归地(即,顺序地)
- 以传统方式(即,并行地)在需要线性 O(N) 内存的情况下。由于注意力可以被看作是一种 RNN,计算注意力的传统方法也可以被看作是计算注意力的一对多 RNN 输出的有效方法,即,RNN 的输出将多个上下文 token 作为输入,但在 RNN 结束时只输出一个 token(见图 1a)
- 一种按块处理 token 的 RNN,需要 O(b) 内存,其中 b 是块的大小。然而,这种方法超出了本工作的范围。因此,按块处理的 RNN 的描述包含在附录 A 中。

将现有基于注意力的模型视为 RNN。通过将注意力视为一种 RNN,现有的基于注意力的模型也可以被视为 RNN 的变体。例如,Transformer 的自注意力是 RNN(图 1b),其上下文 token 作为其初始隐藏状态。
Perceiver 的交叉注意力是 RNN(图 1c),其上下文相关潜变量作为其初始隐藏状态。通过利用它们注意力机制的 RNN 形式,这些现有模型可以有效地计算它们的输出内存。将注意力视为 RNN 存在的挑战。然而,将现有的基于注意力的模型,如 Transformer,视为 RNN 时,这些模型缺乏传统 RNN(如 LSTM 和 GRU)中常见的重要属性。值得注意的是,LSTM 和 GRU 能够以仅为 O(1) 的固定内存和计算高效地更新自己,这对于序列建模是一个重要特性,其中数据以流的形式接收。相比之下,将 Transformer 的 RNN 视图(见图 1b)处理新 token 的方式是添加一个新的RNN,新 token 作为其初始状态。新的 RNN 处理所有先前的 token,需要 O(N) token 数量的线性计算。在 Perceiver 中,由于其体系结构,潜变量(图 1c 中的 L_i)是与输入相关的,这意味着当接收到新 token 时,它们的值会改变。由于它们的 RNN 的初始隐藏状态(即,潜变量)会改变,因此 Perceiver 需要从头重新计算它们的 RNN,需要 O(NL) token 数量(N)和潜变量数量(L)的线性计算。

3.2 注意力作为(多对多)RNN
针对这些限制,我们提议开发一种基于注意力的模型,能够利用 RNN 形式的能力进行高效更新。为此,我们首先引入了一种高效的并行化方法,用于将注意力计算为多对多的 RNN,即,一种并行方法来计算
![]()
为此,我们利用并行前缀扫描算法(Blelloch,1990)(见算法 1),这是一种并行计算方法,用于通过关联运算符 ⊕ 从 N 个连续数据点计算 N 个前缀计算。该算法可以从 {xk}^N_(k=1) 高效地计算
![]()
回想一下,Attention(q, x(1:k)) = ok = ak / ck。为了高效计算 Attention(q, x(1:k)),我们可以通过并行扫描算法计算 {ak}^N_(k=1),{ck}^N_(k=1) 和 {mk}^N_(k=1),然后将 ak 和 ck 结合起来计算 Attention(q, x(1:k))。
为此,我们提出以下关联运算符 ⊕,它作用于形式为(m_A, u_A, w_A)的三元组,其中 A 是索引集合,
mA = max_(i∈A) si,uA = ∑_(i∈A) exp(si − mA),wA = ∑_(i∈A) exp(si − mA)vi
并行扫描算法将 {(m{i}, u{i}, w{i})}^N_(i=1) = {(si, 1, vi)}^N_(i=1) 作为输入。该算法递归地应用运算符 ⊕,其工作方式如下:
(mA, uA, wA)⊕(mB, uB, wB) = (mA∪B, uA∪B, wA∪B)
mA∪B = max(mA, mB),uA∪B = uA·exp(mA − mA∪B) + uB exp(mB − mA∪B)
wA∪B = wA· exp(mA−mA∪B) + wB·exp(mB−mA∪B)
在递归地应用运算符完成后,该算法输出
{(m{1,...,k}, u{1,...,k}, w{1,...,k})}^N_(k=1) = {(mk, ∑_(i=1) exp(si − mk), ∑_(i=1) exp(si − mk)vi)}^N_(k=1)
也称为 {(mk, ck, ak)}^N_(k=1)。
通过组合输出元组的最后两个值,我们得到 Attention(q, x(1:k)) = ok = ak / ck,从而实现了一种高效的并行化方法,用于计算注意力作为多对多的 RNN(见图 3)。
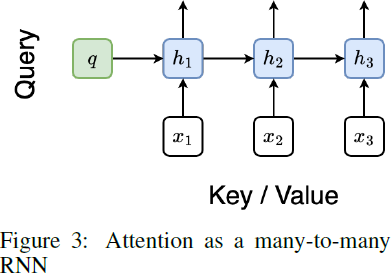
3.3 Aaren: 将注意力当作 RNN
利用注意力的并行化多对多形式,我们提出了Aaren。Aaren 的接口与 Transformer 相同,将 N 个输入映射到 N 个输出,其中第 i 个输出是从第 1 到第 i 个输入的聚合。因此,Aaren也是自然可堆叠的,且能够为每个序列 token 计算单独的损失项
然而,与使用因果自注意力的 Transformer 不同,Aaren 使用了前述的将注意力计算为多对多 RNN 的方法,使其更加高效。Aaren 的功能如下:
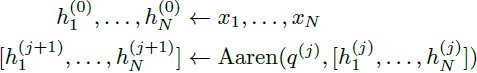
与 Transformer 中的查询是注意力的一个输入 token 不同,Aaren 的查询 token q 是通过反向传播在训练过程中学习的。在图 4 中,我们包含了一个具有输入上下文 token x_(1:3) 和输出 y_(1:3) 的堆叠 Aaren 模型的示例。值得注意的是,由于 Aaren 利用了注意力的 RNN 形式,Aaren 的堆叠也是 RNN 的堆叠。因此,Aarens 也能够以高效的方式与新 token 进行更新,即,仅需要固定计算量的 y_k 的迭代计算,因为它仅依赖于 h_(k-1) 和 x_k。与基于 Transformer 的模型不同,它们在使用 KV 缓存时需要线性内存,并且需要存储所有先前的 token,包括中间 Transformer 层中的 token,而基于 Aaren 的模型仅需要固定内存,并且不需要存储所有先前的 token,使得 Aaren 比 Transformer 更加高效。

4. 实验
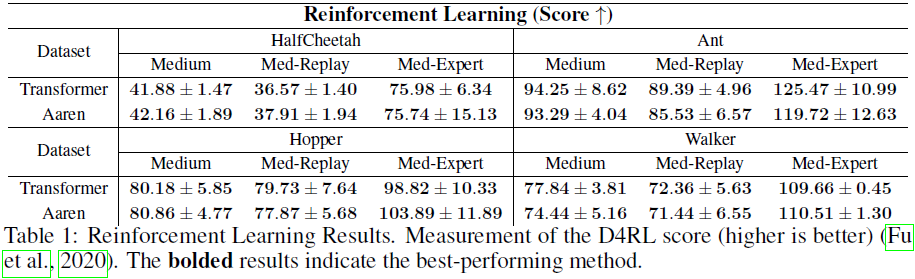

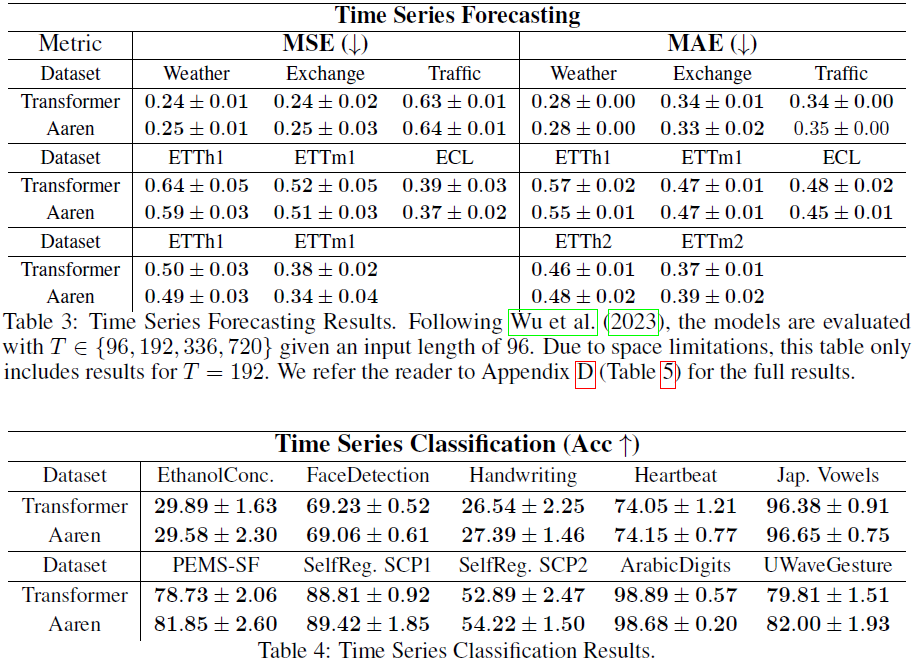

附录
F. 计算时间
我们的实验是在 Nvidia GTX 1080 Ti(12 GB)和 Nvidia Tesla P100(16 GB)GPU 的混合环境中运行的。分析是在 Nvidia GTX 1080 Ti(12 GB)上执行的。
强化学习实验大致需要相同的时间:每个实验约 2 到 4 小时。
事件预测实验的时间因数据集而异:
- MIMIC 约需 0.5 小时
- Wiki 约需 0.75 小时
- Reddit 约需 3.5 小时
- Mooc 约需 8 小时
- StackOverflow 约需 3.5 小时
- Sin 约需 1.5 小时
- Uber 约需 3 小时
- Taxi 约需1.5 小时
时间序列预测实验以 T ∈ {96, 192, 336, 720} 的单个脚本运行。实验时间因数据集而异:
- Weather 约需 6 小时
- Exchange 约需 0.5 小时
- Traffic约需 1 小时
- ECL 约需 4 小时
- ETTh1 约需 0.75 小时
- ETTm1 约需 11 小时
- ETTh2 约需 0.75 小时
- ETTm2 约需 11 小时
时间序列分类实验作为单个脚本运行。在所有数据集上运行实验总共约需 1 小时。