提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、sizeof和strlen对比
- 二、数组之间的比较(依据strlen和sizeof来呈现)
- (一)、一维整型数组
- (二)、字符数组
- (三)、二维数组
- 三、复杂指针运算讲解
- 总结
前言
`本文主要介绍strlen与sizeof的区别,利于strlen与sizeof来对比一维数组,字符数组以及二维数组,加深理解数组之间的区别与联系,最后讲解几个复杂指针的运算
提示:以下是本篇文章正文内容,下面案例可供参考
一、sizeof和strlen对比
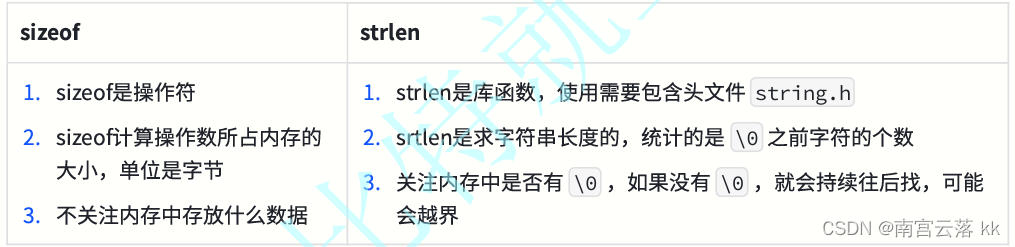
- sizeof是一种操作符,它所计算的是所占内存空间的大小,单位是字节,如果操作数是类型的话计算的是使用类型的创建的变量所占内存空间的大小。在这里注意:sizeof只关注占用内存空间的大小,不在乎内存中存放什么数据,而且sizeof参数中的表达式不实际运算。
#include<stdio.h>
int main()
{
int a = 10;
printf("%d\n", sizeof(a));
printf("%d\n", sizeof a);
printf("%d\n", sizeof(int));
return 0;
}

运行结果都是4,不管内存中存放的是什么数据,只关注占用的内存空间大小,int类型也好,a变量也好,它们都占有4个字节大小。
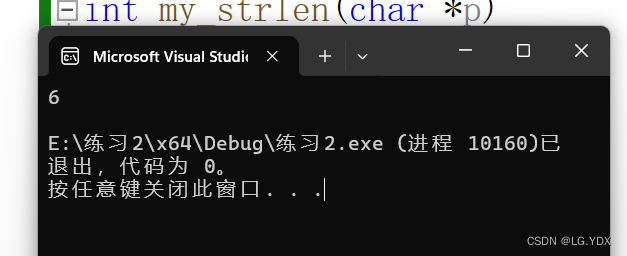
- strlen是C语言库函数,它的功能就是求字符串长度,函数原型为: size_t strlen ( const char * str );它统计的是从参数str中这个地址开始向后,到\0之前的字符个数,如果没有找到\0,strlen函数会一直向后统计,直到找到\0为止,所以可能会存在越界的行为。
#include<stdio.h>
int main()
{
char arr1[3] = { 'a', 'b', 'c' };
char arr2[] = "abc";
printf("%d\n", strlen(arr1));
printf("%d\n", strlen(arr2));
}

理论上来说,打印出来的数应该一样,但由运行结果来看,arr1的字符数量明显不对,这是因为arr1没有设置\0,而arr2用字符串赋值后面自带一个\0,所以在统计arr1的字符数量时候,存在了越界问题
- 两者对比:
二、数组之间的比较(依据strlen和sizeof来呈现)
下面代码我们是在X86环境下运行
(一)、一维整型数组
- 分析以下代码:
//在X86环境下运行
#include<stdio.h>
int main()
{
int a[] = { 1,2,3,4 };
printf("%zd\n", sizeof(a));//第一条:16,a表示的是整个数组,整个数组的大小,单位是字节
printf("%zd\n", sizeof(a + 0));//第二条:4,a代表首元素地址
printf("%zd\n", sizeof(*a));//第三条:4,a代表首元素地址,解引用后为第一个整型大小
printf("%zd\n", sizeof(a + 1));//第四条:4,a代表首元素地址,a+1代表第二个元素地址
printf("%zd\n", sizeof(a[1]));//第五条:4,为数组第二个元素整型大小
printf("%zd\n", sizeof(&a));//第六条:4//为整个数组的地址,只要是地址就是4
printf("%zd\n", sizeof(*&a));//第七条:16
//解释:
//1.&和*相互抵消sizeof(*&a)==sizeof(a)
//2.&a-是数组地址,类型是int(*)[4]数组指针类型,*&a访问的就是这个数组
printf("%zd\n", sizeof(&a + 1));//第八条:4,第二个数组的地址,只要是地址就是4
printf("%zd\n", sizeof(&a[0]));//第九条:4,第一个元素地址,只要是地址就是4
printf("%zd\n", sizeof(&a[0] + 1));//第十条:4,第二个元素地址,只要是地址就是4
}

分析:
- 第一条代码:运行结果为16.这里的数组名因为sizeof的参数只有a自己,所以代表的是整个数组,一个数组4个元素,一个整型元素4个字节(在X86环境下)所以,最终结果为16
- 第二条代码:运行结果为4.这里的数组名代表的是首元素地址,因为sizof中参数不只有a自己还有+0,在X86环境下,只要是地址,它的大小就是4个字节
- 第三条代码:运行结果为4.a代表的是首元素地址,即整型元素1的地址,然后进行解引用,得出的是整型1,它所占空间为4个字节。
- 第四条代码:运行结果为4.a代表的是首元素地址,加1后代表的是第二个元素的地址,只要是地址,其所占用的空间就是4个字节。
- 第五条代码:运行结果为4.a[1]代表的是数组第二个元素2,它是int型元素,是4个字节
- 第六条代码:运行结果为4.&a代表整个数组的地址,只要是地址,在此环境下就是4个字节。
- 第七条代码:运行结果为16.两种解释,第一种:&和 * 相互抵消sizeof( * %a)==sizeof(a),与第一条运行结果相同。第二种解释:&a是代表的是整个数组地址,类型是int( * )[4]数组指针类型,* &a访问的就是这个数组,而这个数组就是16个字节。
- 第八条代码:运行结果为4。&a+1代表的是第二个数组的地址,只要是地址就是4个字节。
- 第九条代码:运行结果为4.&a[0]代表的是第一个元素的地址,只要是地址那么大小就是4个字节。
- 第十条代码:运行结果为4.&a[0]+1代表的是第二个元素的地址,只要是地址那么大小就是4个字节。
以上的每一条代码深刻领会后,就会感受到一维数组的细节内容。像对一维数组数组名的理解,一维数组中解引用的理解,一维数组的地址的理解,一维数组中的运算操作等等。
(二)、字符数组
- 分析下面代码1:
#include<stdio.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%zd\n", strlen(arr));//第一条:随机值,arr代表数组首元素地址
printf("%zd\n", strlen(arr + 0));//第二条:随机值,arr代表数组首元素地址
//printf("%zd\n", strlen(*arr));//第三条:代码出错无法运行,这里先注释掉后面分析
//printf("%zd\n", strlen(arr[1]));第四条:代码出错无法运行,这里先注释掉后面再分析
printf("%zd\n", strlen(&arr));//第五条:随机值
printf("%zd\n", strlen(&arr + 1));//第六条:随机值
printf("%zd\n", strlen(&arr[0] + 1));//第七条:随机值
}

分析:
-
第一条代码:运行结果为19,arr代表的是数组首元素的地址,从此地址出发,直到找到\0为止,但是我们一开始没有在数组中赋值\0,所以最终得出的是随机值。
-
第二条代码:运行结果为19.arr+0也代表首元素地址,分析同第一条代码
-
第三条代码:运行结果为程序错误,我们这里给注释掉。arr维首元素地址,对其进行解引用,*arr代表的就是‘a’字符,它的ASCII值为97,将其传给strlen,strlen会认为97就是地址,然后去访问内存,会发生访问冲突
-
第四条代码:运行结果为程序错误,arr[1],代表的是’b’字符,它的ASCII值为98,将其传给strlen,strlen会认为98就是地址,然后去访问内存,会发生访问冲突.
-
第五条代码:运行结果为19。&arr,这里arr代表的是整个数组,参数是整个数组的地址,从此地址出发,直到找到\0为止,但是我们一开始没有在数组中赋值\0,所以最终得出的是随机值。
-
第六条代码:运行结果为13.&arr+1代表的是第二个数组的地址。从此出发,后面有没有\0仍然未知,是随机值,但会比第5条代码少5,因为他们之间一定差了一个数组的元素个数
-
第七条代码:运行结果为18.&arr[0]+1,代表的是第二个元素的地址,从此地址开始访问,因为后面没有设置\0,所以访问的仍然是随机值,但比第一条代码会少1.
-
分析下面代码2:
#include<stdio.h>
int main()
{
char arr[] = "abcdef";
printf("%zd\n", sizeof(arr));//第一条:7,arr数组名表示的是整个数组计算的是整个数组的大小
printf("%zd\n", sizeof(arr+0));//第二条:4,arr+0代表的是数组首元素的地址,既然是地址,大小就是4个字节
printf("%zd\n", sizeof(*arr));//第三条:1,*arr代表的是数组首元素--a大小为一个字节
printf("%zd\n", sizeof(arr[1]));//第四条:1,arr[1]代表的是数组中第二个元素-b的大小
printf("%zd\n", sizeof(&arr));//第五条:4//&arr代表的是数组的地址
printf("%zd\n", sizeof(&arr+1));//第六条:4//&arr代表的是数组的地址,+1后代表跳过整个数组后,这指向了数组后面的那个位置,但是&arr+1仍然是地址,只要是地址,就是4个字节
printf("%zd\n", sizeof(&arr[0]+1));//第七条:4,代表的是数组第二个元素的地址,只要是地址,就是4个字节
printf("%zd\n", strlen(arr));//第八条:6,数组名代表第一个元素地址
printf("%zd\n", strlen(arr+0));//第九条:6,数组名+0代表第一个元素地址
// printf("%zd\n", strlen(*arr));//第十条:字符a-97,97作为地址传给了strlen,不能使用这个空间,注释掉
// printf("%zd\n", strlen(arr[1]));//第十一条:字符b-98,98作为地址传给了strlen,不能访问这个空间,注释掉
printf("%zd\n", strlen(&arr));//第十二条:6,&arr是数组的地址,数组的地址和数组首元素的地址是指向同一个位置的
printf("%zd\n", strlen(&arr+1));//第十三条:随机值
printf("%zd\n", strlen(&arr[0]+1));//第十四条:5,从数组第二个位置开始访问
}

分析:
-
第一条代码:运行结果为7.这里arr代表的是整个数组,sizeof(arr)计算的是整个数组的大小,因为一开始赋值的时候为字符串类型,所以末尾自动加了个\0。故而应该是7个字节大小。
-
第二条代码:运行结果为4.这里arr代表数组首元素的地址+0也代表首元素的地址,只要是地址,在X86环境下,大小就是4个字节
-
第三条代码:运行结果为1.这里arr代表的是数组首元素的地址,对其进行解引用,我们得到的是字符’a’.一个字符大小是一个字节
-
第四条代码:运行结果为1。arr[1]代表的是数组第二个元素-‘b’,它是字符,其大小就是一个字节
-
第五条代码:运行结果为4.&arr代表的是整个数组的地址,只要是地址,在x86环境下,大小就是4个字节。
-
第六条代码:运行结果为4.%arr+1代表的是下一个数组的地址,只要是地址,在X86的环境下,大小就是4个字节
-
第七条代码:运行结果为4.&arr[0]+1,代表的是第二个元素的地址,只要是地址,在X86环境下,大小就是4个字节。
-
第八条代码:运行结果为6.arr代表的是数组首元素的地址,arr数组末尾有\0,从此地址出发,到\0之间共有6个元素,故而显示的结果就是6
-
第九条代码:运行结果为6.arr+0代表的也是首元素的地址,分析结果同第一条代码。
-
第十条代码:运行结果为程序错误。arr代表的是数组首元素的地址,对其进行解引用,指的是’a’其ASCII码值为97,将其传给strlen,strlen会认为97就是地址,然后去访问内存,会发生访问冲突
-
第十一条代码:运行结果为程序错误。arr[1]代表的是字符’b’其ASCII码值为98,将其传给strlen,strlen会认为98就是地址,然后去访问内存,会发生访问冲突
-
第十二条代码:运行结果为6.&arr是整个数组的地址,而整个数组的地址和首元素地址指向的是同一个位置,故而分析同第一条代码。
-
第十三条代码:运行结果为随机值。&arr+1代表的是下一个数组的地址,而下一个数组我们没有赋值或者定义\0,故而显示的是随机值。
-
第十四条代码:运行结果为5.&arr[0]+1代表的是第二个元素’b’的地址,从此地址到\0之间的元素有5个,故而最后显示的结果是5。
-
分析下面代码3:
字符串指针:可以理解成不能改变的字符数组
#include<stdio.h>
int main()
{
char* p = "abcdef";//可以理解成不能被改变的字符数组
printf("%zd\n", sizeof(p));//第一条:4,p是指针变量。计算的是指针变量p的大小,为4个字节
printf("%zd\n", sizeof(p+1));//第二条:4,p+1代表的是b元素的地址 为4个字节
printf("%zd\n", sizeof(*p));//第三条:1,代表a元素的大小
printf("%zd\n", sizeof(p[0]));//第四条:p[0]->*(p+0),代表a元素的大小1
printf("%zd\n", sizeof(&p));//第五条:4,p指针的地址,只要是地址就是4个字节
printf("%zd\n", sizeof(&p+1));//第六条:4,&p是p的地址,&p+1是跳过p变量,指向了p的后边,只要是地址就是4个字节
printf("%zd\n", sizeof(&p[0]+1));//第七条:4,代表b的地址,只要是地址就是4个字节
printf("%zd\n", strlen(p));//第八条:6,
printf("%zd\n", strlen(p+1));//第九条:5
//printf("%zd\n", strlen(*p));//第十条:程序崩坏,注释掉,后面分析
//printf("%zd\n", strlen(p[0]));//第十一条:程序崩坏,注释掉,后面分析
printf("%zd\n", strlen(&p));//第十二条:随机值
printf("%zd\n", strlen(&p+1));//第十三条:随机值
printf("%zd\n", strlen(&p[0]+1));//第十四条:5
}

分析:
- 第一条代码:运行结果为4.p是指针变量,同时也代表的是字符’a’的地址,在X86环境下指针变量的大小为4字节.
- 第二条代码:运行结果为4,p+1代表的是‘b’字符的地址,在X86环境下,其大小为4个字节
- 第三条代码:运行结果为1.*p代表的是’a’字符,其大小为一个字节。
- 第四条代码:运行结果为1.p[0]等价于* (p+0)指的是’a’字符,其大小为1个字节
- 第五条代码:运行结果为4.&p代表的是p指针变量的地址,只要是地址,在X86环境下,其大小就是4个字节
- 第六条代码:运行结果为4.&p代表的是p的地址,&p+1是跳过p变量,指向了p的后边,也代表地址,只要是地址,在X86环境下就是4个字节。
- 第七条代码:运行结果为4.&p[0]+1代表的是’b’字符的地址,只要地址,在X86环境下就是4个字节
- 第八条代码:运行结果为6.p代表的是’a’的地址,将其传给strlen函数,就是从此地址出发,统计到\0之前的元素个数,字符串末尾会自动加一个\0,故而结果为6.
- 第九条代码:运行结果为5.p+1代表的是’b’字符的地址,将其传给strlen函数,就是从此地址出发,统计到\0之前的元素个数,故而会比第八条代码少1,结果为5.
- 第十条代码:运行结果为程序错误。*p代表的是字符’a’,其ASCII码值为97,将其传给strlen,strlen会认为97就是地址,然后去访问内存,会发生访问冲突符。
- 第十一条代码:运行结果为程序错误。p[0]代表的也是字符’a’,分析同第十条代码
- 第十二条代码:运行结果为3.&p代表p变量的地址,,从此地址出发,因为后边我们没有一开始定义\0,所以最后统计的是随机值。
- 第十三条代码:运行结果为随机值。&p+1代表的是跳过p变量,指向了p的后边,从此地址出发,因为后边我们没有一开始定义\0,所以最后统计的是随机值。
- 第十四条代码:运行结果为5.&p[0]+1,代表的是’b’字符的地址,从此地址出发,到\0共有5个元素,故而结果为5.
以上的每一条代码深刻领会后,就会感受到字符数组的细节内容。像对字符数组数组名的理解,字符数组中解引用的理解,字符数组的地址的理解,字符数组中的运算操作,字符指针变量与字符数组关系等等。
(三)、二维数组
- 分析以下代码:
#include<stdio.h>
int main()
{
int a[3][4] = { 0 };
printf("%zd\n", sizeof(a));//第一条:48,a作为二维数组数组名,单独放在sizeof中,说明这里a代表整个数组,计算的是整个数组的大小,单位是字节
printf("%zd\n", sizeof(a[0][0]));//第二条:4
printf("%zd\n", sizeof(a[0]));//第三条:16
printf("%zd\n", sizeof(a[0]+1));//第四条:4
printf("%zd\n", sizeof(*(a[0]+1)));//第五条:4,代表第一行第二个元素,大小是4个字节
//************
printf("%zd\n", sizeof(a+1));//第六条:4,代表第二行第一个元素的地址。a是二维数组数组名,并没有单独放在sizeof中,a代表的是首元素地址即第一行的地址,a+1代表第二行的地址,是地址大小就是4个字节
//************
printf("%zd\n", sizeof(*(a + 1)));//第七条:16
//1.*(a+1)--a[1]-是第二行的数组名,单独放到sizeof中,指的是整个数组的大小
//2.第一行地址+1,即第二行的地址,为数组指针类型,对其进行解引用,访问的是整个第二行数组,大小是16个字节
printf("%zd\n", sizeof(&a[0]+1));//第八条:4,代表的是第二行的地址
//a[0]表示的是第一行的数组名,&数组名代表的是第一行的地址,&a[0]+1就是第二行的地址,是地址就是4个字节
printf("%zd\n", sizeof(*(&a[0] + 1)));//第九条:16;第二行地址解引用代表第二行整个数组
printf("%zd\n", sizeof(*a));//第十条:16.a代表的是第一行的地址,对第一行进行解引用代表的是第一行整个数组的大小,大小为16个字节
printf("%zd\n", sizeof(a[3]));//16第十一条:
//sizeof 内部的表达式是不会真实计算的,所以谈不上越界的问题
//a[3]-第四行的数组名,sizeof直接+数组名,代表访问整个数组(即第四行)大小为16个字节
}

分析:
- 第一条代码:运行结果为48.a作为二维数组的数组名,单独放在sizeof中代表了整个二维数组,共有12个元素,一个整型元素为4个字节。所以共占48个字节大小。
- 第二条代码:运行结果为4.a[0][0]代表的是第一行第一列元素,其为整型类型,故而大小为4个字节。
- 第三条代码:运行结果为16.a[0],是第一行的数组名,单独放在sizeof中,所以a[0]代表的是二维数组中第一行的一维数组,共有4个整型元素,故而占16个字节
- 第四条代码:运行结果为4.a[0]是第一行的数组名,在这里它代表的是第一行首元素的地址,然后+1代表第一行第二个元素的地址,只要是地址,在X86环境下,大小为4个字节
- 第五条代码:运行结果为4.a[0]+1代表的是第一行第二个元素的地址,然后对其进行解引用,得到的是整型0元素,大小为4个字节。
- 第六条代码:运行结果为4.a是指二维数组数组名,在这里代表的是第一行一维数组的地址,+1后,代表的是第二行一维数组的地址,只要是地址,在X86环境下就是4个字节。
- 第七条代码:运行结果为16.有两种解释:第一种,(a+1)代表的是第二行一维数组的地址,然后对其进行解引用,代表的是整个第二行一维数组,共有4个整型元素,故而占16个字节;第二种,*(a+1)等价于a[1]是第二行的数组名,单独放在sizeof中代表的是整个第二行一维数组,共有4个整型元素,故而占16个字节。
- 第八条代码:运行结果为4.&a[0]代表的是第一行一维数组的地址,加一后,代表的是第二行一维数组的地址,只要是地址,在X86环境下,就是4个字节。
- 第九条代码:运行结果为16.&a[0]+1代表第二行一维数组的地址,对其进行解引用后,代表的是整个整个第一行,共有4个整型元素,故而占16个字节。
- 第十条代码:运行结果为16.a是二维数组的数组名,在这里代表的是第一行的地址,对第一行进行解引用代表的是第一行整个数组的大小,大小为16个字节
- 第十一条代码:运行结果为16.sizeof内部是不会真实计算的,所以谈不上越界问题。a[3]-第四行的数组名,sizeof直接+数组名,代表访问整个数组(即第四行)大小为16个字节
以上的每一条代码深刻领会后,就会感受到二维数组的细节内容。像对二维数组数组名的理解,将二维数组拆分成几个一维数组,它是几个一维数组的数组,二维数组地址的分析,解引用分析,运算等等。
三、复杂指针运算讲解
- 代码1:
#include <stdio.h>
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
运行结果:
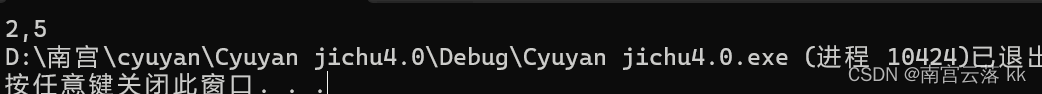
分析:&a+1代表的是指向下一个数组的地址。将其强制转换成int后,赋值给ptr指针,ptr就是简单的整型指针,-1后代表整型元素5的地址,进行解引用后,代表整型元素5.(a+1)等价于a[1],即2整型元素
- 代码2:
//在X86环境下
//结构体的大小为20个字节
#include<stdio.h>
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{
printf("%p\n", p + 0x1);//第一条:
printf("%p\n", (unsigned long)p + 0x1);//第二条:
printf("%p\n", (unsigned int*)p + 0x1);//第三条:
return 0;
}
运行结果为:

分析:%p打印的是地址。我们应该清楚,指针+1是跟类型有关系,而整数+1,就是之间+1.第一条打印代码为指针+1(16进制),struct Test*变量为20个字节,即加20个字节,因为是16进制,所以最终呈现的是00100014;第二条打印代码,为整数加1,直接加1即可,最终呈现为00100001。第三条打印代码仍然为指针+1,unsigned int类型变量是4个字节,所以最终呈现00100004
- 代码3:
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}
运行结果:

分析:注意在给二维数组赋值的时候用的是小括号,即为逗号表达式形式,等价于int a[3][2]={1,3,5};即为以下形式
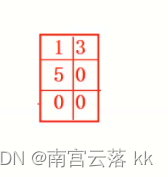
a[0]是第一行一维数组的数组名,代表第一行首元素的地址,将它赋值给p整型指针变量,p[0]等价于*(p+0)访问的是第一行的首元素1,故而输出为一。
- 代码4:
//在X86的环境下,程序的输出结果
#include <stdio.h>
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
运行结果为:

分析:p是数组指针类型,int(*)[4],而a也可以表示成数组指针的形式,它的类型就是int( * )[5],但是将a赋值为p,所以最终以p的类型为主,一开始a的地址与p的地址指向统一个位置,但是它俩类型不同,所以+1后跳过的元素也不同,p+1跳过4个元素,而a+1跳过5个元素.所以最终结果指向为:
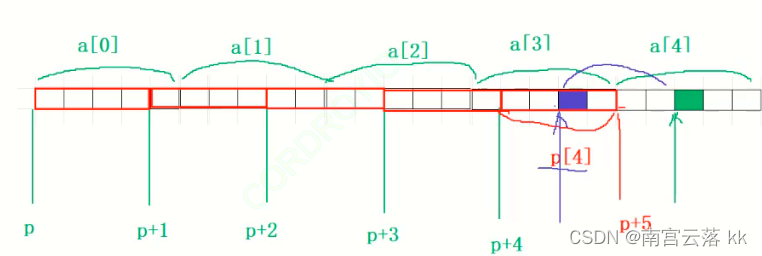
%d是有符号整数,结果就是-4.
%p是打印的地址,为无符号整数,最终是以补码形式存在
-4的补码为:11111111111111111111111111111100,它所对应的无符号整数就是FF FF FF FC
- 代码5:
#include <stdio.h>
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
运行结果为:

分析:
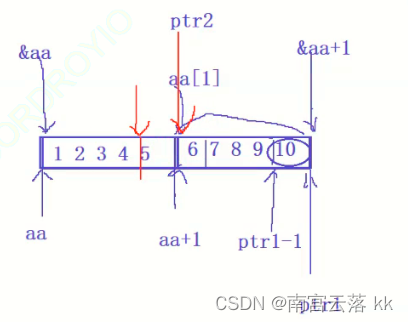
&aa代表整个二维数组的地址,+1后指向下一个二维数组,如图所示,然后强制转换成int型,-1后指向10整型元素,对其解引用后,打印出10;aa+1代表的是第二行一维数组的地址,对其解引用后代表整个第二行数组名,指的是第二行一维数组首元素的地址,然后强制类型转换成int型,-1后指向5元素地址,最后解引用后,指向元素5.
- 代码6:
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
运行结果为:

分析:

a是二维数组数组名,代表的是二维数组首元素地址(即第一行一维数组的地址),这里用二级指针pa来接受,p++后,指向的二维数组第二行的地址(即第二行一维数组的地址),打印后即第二行的内容,即at.
- 代码7:
#include <stdio.h>
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
运行结果:
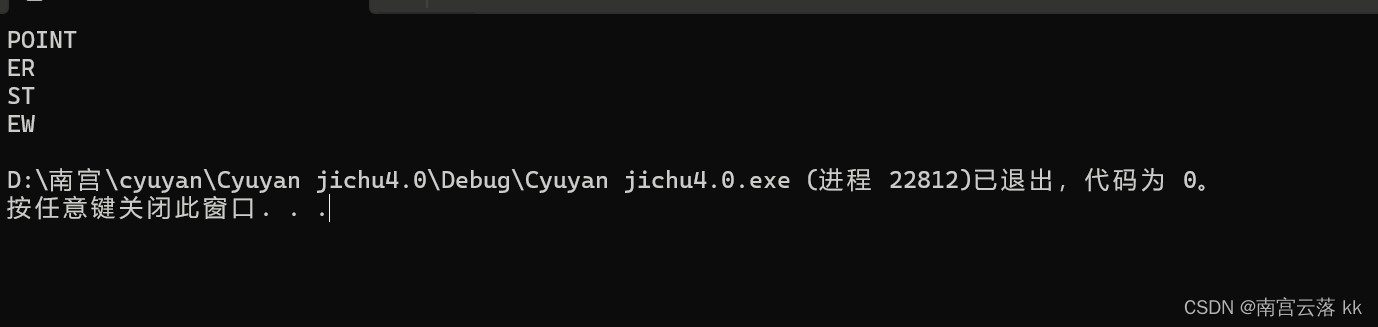
分析:
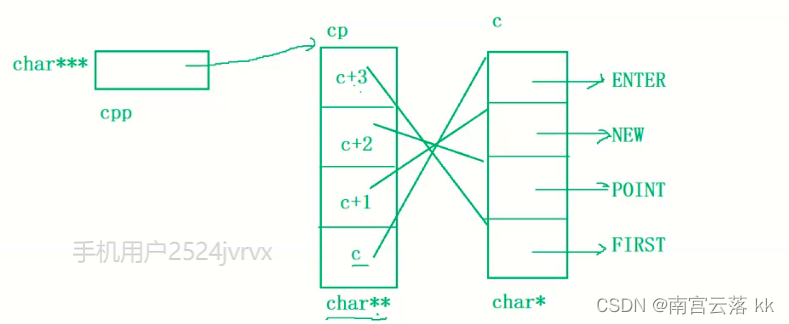
c 为指针数组类型,cp亦是指针数组类型,char为三级指针,代表的是cp首元素的地址,他们之间的对应关系如图。
注意++,–运算会改变cpp的值,影响后面计算
第一条打印代码分析:**++cpp,cpp+1是c+2的地址,进行解引用后代表c+2,在对c+2进行解引用后代表P的地址,然后进行打印后结果为POINT
第二条打印代码分析:* – ++cpp+3,前面cpp已经++了,现在cpp指向的是c+2的地址,加法的优先级比较低,++ – 的优先级比较高,顺序就是先算加加再解引用,再算–,再解引用,最后算+3.cpp先++,代表的是c+1的地址,进行解引用后代表c+1然后–,代表的是c,解引用后 c代表的是"ENTER"的首元素‘E’的地址,然后加3代表的是后面’E’的地址,然后打印出来的结果就是ER。
第三条打印代码分析:cpp[-2]+3。 cpp[-2]等价于 (cpp-2),cpp现在是代表c+1的地址,-2后代表c+3的地址,进行解引用后代表c+3,c+3,进行解引用 * (c+3)代表的是”FIRST“的首元素‘F’地址,然后+3代表的是‘S’的地址,最后打印出来的结果就是ST
第四条打印代码分析:cpp[-1][-1] + 1。cpp现在代表的是c+1的地址,cpp[-1][-1]等价于 (* (cpp-1)-1),即代表“NEW”首元素’N’的地址,然后+1即‘W’的地址,最后打印出来的结果就是EW。
总结
本文主要介绍strlen与sizeof的区别,利于strlen与sizeof来对比一维数组,字符数组以及二维数组,加深理解数组之间的区别与联系,最后讲解几个复杂指针的运算,如有错误请批评指正,感谢支持