前言
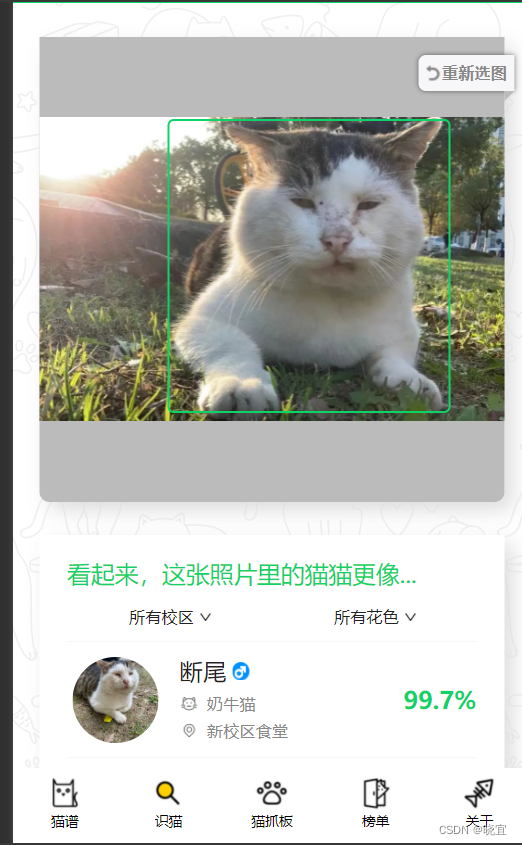
前段时间给学校的猫咪小程序搭建了识猫模型,可以通过猫咪的照片辨别出是那只猫猫,这里分享下具体的方案,先看效果图:
源代码在文末
模型训练
在训练服务器(或你的个人PC)上拉取本仓库代码。
图片数据准备
进入`data`目录,执行`npm install`安装依赖。(需要 Node.js 环境,不确定老版本 Node.js 兼容性,建议使用最新版本。)
复制`config.demo.ts`文件并改名为`config.ts`,填写Laf云环境的`LAF_APPID`;
执行`npm start`,脚本将根据小程序数据库记录拉取小程序云存储中的图片。
如果不打算从laf拉取数据,也可以自己制作数据集,只要保证文件格式如下就可以
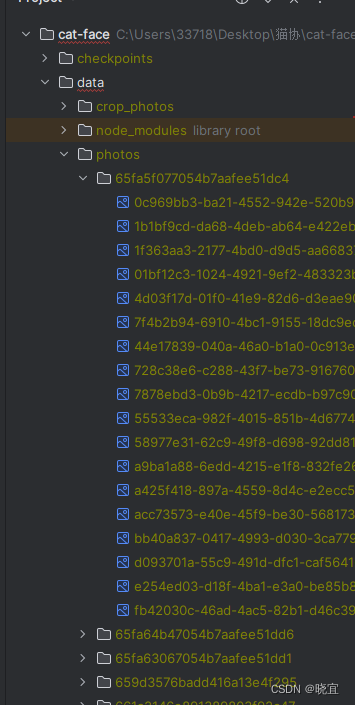
catface文件下面的data文件中的photos中有若干个文件夹,每个文件夹名称为id,文件夹下为图片。
环境搭建
返回仓库根目录,执行`python -m pip install -r requirements.txt`安装依赖。(需要Python>=3.8。不建议使用特别新版本的 Python,可能有兼容性问题。)
如果是linux系统,可以直接执行`bash prepare_yolov5.sh`拉取YOLOv5目标检测模型所需的代码,然后下载并预处理模型数据。如果是windows系统可以自己手动从gihub上拉取yolov5的模型。
执行`python3 data_preprocess.py`,脚本将使用YOLOv5从`data/photos`的图片中识别出猫猫并截取到`data/crop_photos`目录。
开始训练
执行`python3 main.py`,使用默认参数训练一个识别猫猫图片的模型。(你可以通过`python3 main.py --help`查看帮助来自定义一些训练参数。)程序运行结束时,你应当看到目录的export文件夹下存在`cat.onnx`和`cat.json`两个文件。(训练数据使用TensorBoard记录在`lightning_logs`文件夹下。若要查看准确率等信息,请自行运行TensorBoard。)
执行`python3 main.py --data data/photos --size 224 --name fallback`,使用修改后的参数训练一个在YOLOv5无法找到猫猫时使用的全图识别模型。程序运行结束时,你应当看到目录的export文件夹下存在`fallback.onnx`和`fallback.json`两个文件。
这里介绍下模型类的代码,我们定义了学习率,网络指定为densenet21
import torch
import torch.nn as nn
from torchvision import models
import torch.optim as optim
from pytorch_lightning import LightningModule
import torchmetrics
from typing import Tuple
class CatFaceModule(LightningModule):
def __init__(self, num_classes: int, lr: float):
super(CatFaceModule, self).__init__()
self.save_hyperparameters()
self.net = models.densenet121(num_classes=num_classes)
self.loss_func = nn.CrossEntropyLoss()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
def training_step(self, batch: Tuple[torch.Tensor, torch.LongTensor], batch_idx: int) -> torch.Tensor:
loss, acc = self.do_step(batch)
self.log('train/loss', loss, on_step=True, on_epoch=True)
self.log('train/acc', acc, on_step=True, on_epoch=True)
return loss
def validation_step(self, batch, batch_idx: int):
loss, acc = self.do_step(batch)
self.log('val/loss', loss, on_step=False, on_epoch=True)
self.log('val/acc', acc, on_step=False, on_epoch=True)
def do_step(self, batch: Tuple[torch.Tensor, torch.LongTensor]) -> Tuple[torch.Tensor, torch.Tensor]:
# shape: x (B, C, H, W), y (B), w (B)
x, y = batch
# shape: out (B, num_classes)
out = self.net(x)
loss = self.loss_func(out, y)
with torch.no_grad():
# 每个类别分别计算准确率,以平衡地综合考虑每只猫的准确率
accuracy_per_class = torchmetrics.functional.accuracy(out, y, task="multiclass", num_classes=self.hparams['num_classes'], average=None)
# 去掉batch中没有出现的类别,这些位置为nan
nan_mask = accuracy_per_class.isnan()
accuracy_per_class = accuracy_per_class.masked_fill(nan_mask, 0)
# 剩下的位置取均值
acc = accuracy_per_class.sum() / (~nan_mask).sum()
return loss, acc
def configure_optimizers(self) -> optim.Optimizer:
return optim.Adam(self.parameters(), lr=self.hparams['lr'])在模型训练完毕后可以运行我编写的modelTest,在这个文件中替换图片为自己的图片,观察输出是否正常,正常输出是这样的:

在这个输出中,通过yolo检测了图片中是否含有猫咪,通过densenet对图片所属于的类进行概率计算,概率和id按照概率从大到小排序返回。
接口实现
我们训练了两个densenet模型,一个是全图像的输入为228的模型a,一个是输入图像为128的模型b,当请求打到服务器时,应用程序会先通过yolo检测是否有猫,有的话就截取猫咪图像,使用模型b;否则不截取,使用模型a。
以下是代码:
from typing import Any
from werkzeug.datastructures import FileStorage
import torch
from PIL import Image
import numpy as np
import onnxruntime
from flask import Flask, request
from dotenv import load_dotenv
import os
import json
import time
from base64 import b64encode
from hashlib import sha256
load_dotenv("./env", override=True)
HOST_NAME = os.environ['HOST_NAME']
PORT = int(os.environ['PORT'])
SECRET_KEY = os.environ['SECRET_KEY']
TOLERANT_TIME_ERROR = int(os.environ['TOLERANT_TIME_ERROR']) # 可以容忍的时间戳误差(s)
IMG_SIZE = int(os.environ['IMG_SIZE'])
FALLBACK_IMG_SIZE = int(os.environ['FALLBACK_IMG_SIZE'])
CAT_BOX_MAX_RET_NUM = int(os.environ['CAT_BOX_MAX_RET_NUM']) # 最多可以返回的猫猫框个数
RECOGNIZE_MAX_RET_NUM = int(os.environ['RECOGNIZE_MAX_RET_NUM']) # 最多可以返回的猫猫识别结果个数
print("==> loading models...")
assert os.path.isdir("export"), "*** export directory not found! you should export the training checkpoint to ONNX model."
crop_model = torch.hub.load('yolov5', 'custom', 'yolov5/yolov5m.onnx', source='local')
with open("export/cat.json", "r") as fp:
cat_ids = json.load(fp)
cat_model = onnxruntime.InferenceSession("export/cat.onnx", providers=["CPUExecutionProvider"])
with open("export/cat.json", "r") as fp:
fallback_ids = json.load(fp)
fallback_model = onnxruntime.InferenceSession("export/cat.onnx", providers=["CPUExecutionProvider"])
print("==> models are loaded.")
app = Flask(__name__)
# 限制post大小为10MB
app.config['MAX_CONTENT_LENGTH'] = 10 * 1024 * 1024
def wrap_ok_return_value(data: Any) -> str:
return json.dumps({
'ok': True,
'message': 'OK',
'data': data
})
def wrap_error_return_value(message: str) -> str:
return json.dumps({
'ok': False,
'message': message,
'data': None
})
def check_signature(photo: FileStorage, timestamp: int, signature: str) -> bool:
if abs(timestamp - time.time()) > TOLERANT_TIME_ERROR:
return False
photoBase64 = b64encode(photo.read()).decode()
photo.seek(0) # 重置读取位置,避免影响后续操作
signatureData = (photoBase64 + str(timestamp) + SECRET_KEY).encode()
return signature == sha256(signatureData).hexdigest()
@app.route("/recognizeCatPhoto", methods=["POST"])
@app.route("/recognizeCatPhoto/", methods=["POST"])
def recognize_cat_photo():
try:
photo = request.files['photo']
timestamp = int(request.form['timestamp'])
signature = request.form['signature']
if not check_signature(photo, timestamp=timestamp, signature=signature):
return wrap_error_return_value("fail signature check.")
src_img = Image.open(photo).convert("RGB")
# 使用 YOLOv5 进行目标检测,结果为[{xmin, ymin, xmax, ymax, confidence, class, name}]格式
results = crop_model(src_img).pandas().xyxy[0].to_dict('records')
# 过滤非cat目标
cat_results = list(filter(lambda target: target['name'] == 'cat', results))
if len(cat_results) >= 1:
cat_idx = int(request.form['catIdx']) if 'catIdx' in request.form and int(request.form['catIdx']) < len(cat_results) else 0
# 裁剪出(指定的)cat
cat_result = cat_results[cat_idx]
crop_box = cat_result['xmin'], cat_result['ymin'], cat_result['xmax'], cat_result['ymax']
# 裁剪后直接resize到正方形
src_img = src_img.crop(crop_box).resize((IMG_SIZE, IMG_SIZE))
# 输入到cat模型
img = np.array(src_img, dtype=np.float32).transpose((2, 0, 1)) / 255
scores = cat_model.run([node.name for node in cat_model.get_outputs()], {cat_model.get_inputs()[0].name: img[np.newaxis, :]})[0][0].tolist()
# 按概率排序
cat_id_with_score = sorted([dict(catID=cat_ids[i], score=scores[i]) for i in range(len(cat_ids))], key=lambda item: item['score'], reverse=True)
else:
# 没有检测到cat
# 整张图片直接resize到正方形
src_img = src_img.resize((FALLBACK_IMG_SIZE, FALLBACK_IMG_SIZE))
img = np.array(src_img, dtype=np.float32).transpose((2, 0, 1)) / 255
scores = fallback_model.run([node.name for node in fallback_model.get_outputs()], {fallback_model.get_inputs()[0].name: img[np.newaxis, :]})[0][0].tolist()
# 按概率排序
cat_id_with_score = sorted([dict(catID=fallback_ids[i], score=scores[i]) for i in range(len(fallback_ids))], key=lambda item: item['score'], reverse=True)
return wrap_ok_return_value({
'catBoxes': [{
'xmin': item['xmin'],
'ymin': item['ymin'],
'xmax': item['xmax'],
'ymax': item['ymax']
} for item in cat_results][:CAT_BOX_MAX_RET_NUM],
'recognizeResults': cat_id_with_score[:RECOGNIZE_MAX_RET_NUM]
})
except BaseException as err:
return wrap_error_return_value(str(err))
if __name__ == "__main__":
app.run(host=HOST_NAME, port=PORT, debug=False)我们可以在本地运行,如果想测试的小伙伴可以把接口中密钥校验的代码删除,然后直接发送post请求即可。
源码链接
cat-face: 猫脸识别程序,使用yolov5和densenet分类





![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-22讲 RTC 时钟设置](https://img-blog.csdnimg.cn/direct/bfc008b867064586a037d5e1e583bd0a.png)