CUDA之线程同步
- 共享内存:线程时间需要互相交换数据才能完成任务的情况并不少见,因此,必须存在某种能让线程彼此交流的机制
- 当很多线程并行工作并且访问相同的数据或者存储器位置的时候,线程间必须正确的同步
- 线程之间交换数据并不一定要需要使用共享内存,只是共享内存较快而已
1.共享内存
- 共享内存位于芯片内部,因此它比全局内存要快得多,相比没有经过缓存的全局内存访问,共享内存大约在延迟上第100倍
- 同一个块中的线程可以访问相同的一段共享内存,不同块中的线程所见到的共享内存中的内容是不相同的
- 如果某线程的计算结果在写入到共享内存完成之前被其他线程读取,那么将会导致错误。因此应该正确的控制和管理内存访问,这是由
__syncthreads()指令完成的,该指令确保在继续执行程序之前完成对内存的所有写入操作,即同步,也被称为barrier。barrier的含义是块中的所有线程都将到达该代码行,然后在此等待其他线程完成,当所有线程都到达了这里之后,他们可以一起继续往下执行 - 举个例子:
#include <stdio.h>
//计算数组中当前元素之前所有元素的平均值
__global__ void gpu_shared_memory(float *d_a)
{
// Defining local variables which are private to each thread
int i, index = threadIdx.x;
float average, sum = 0.0f;
//定义共享内存并赋值
__shared__ float sh_arr[10];
sh_arr[index] = d_a[index];
__syncthreads(); // This ensures all the writes to shared memory have completed
for (i = 0; i<= index; i++)
{
sum += sh_arr[i];
}
average = sum / (index + 1.0f);
d_a[index] = average;
sh_arr[index] = average;
}
-
共享内存上的数字或者变量是通过
__shared__修饰符定义的 -
共享内存的大小应该等于每个块的线程数
-
当数据从全局内存复制到共享内存时,需要保证所有线程都已经完成了它们的写入操作,并使用
__syncthreads()进行一次同步 -
主函数调用如下:
int main(int argc, char **argv)
{
//Define Host Array
float h_a[10];
//Define Device Pointer
float *d_a;
for (int i = 0; i < 10; i++) {
h_a[i] = i;
}
// allocate global memory on the device
cudaMalloc((void **)&d_a, sizeof(float) * 10);
// now copy data from host memory to device memory
cudaMemcpy((void *)d_a, (void *)h_a, sizeof(float) * 10, cudaMemcpyHostToDevice);
gpu_shared_memory << <1, 10 >> >(d_a);
// copy the modified array back to the host memory
cudaMemcpy((void *)h_a, (void *)d_a, sizeof(float) * 10, cudaMemcpyDeviceToHost);
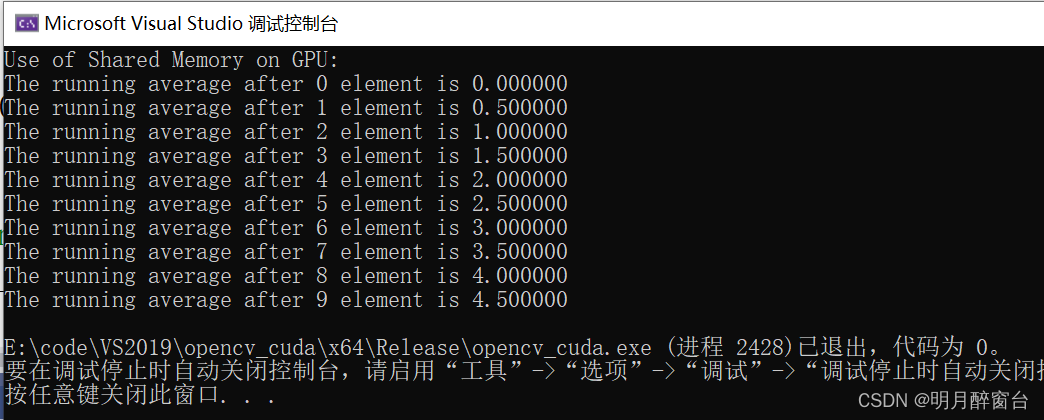
printf("Use of Shared Memory on GPU: \n");
//Printing result on console
for (int i = 0; i < 10; i++) {
printf("The running average after %d element is %f \n", i, h_a[i]);
}
return 0;
}
2. 原子操作
- 原子操作的提出主要为了解决一个问题 -> 当大龄的线程需要试图修改一段较小的内存区域时引发的计算结果错误问题,尤其是在进行“读取 - 修改 - 写入” 操作序列的时候
- 例如:假设某内存区域初始值为6,两个线程p和q分别试图将区域值+1,则最终的结果应该是8.但是在实际执行的时候,可能p和q两个线程同时读取了这个值,两个都得到了6,执行+1都得到了7,然后将7写入内存区域,这个正确结果8相比肯定是错误的
- 下边给一个通过核函数进行多线程访问同一数组的小栗子(无原子操作)
#include <stdio.h>
//不同GPU算力不同,此处设置的参数也不相同,算例越高启用的块和线程数越大,实验现象越明显
#define NUM_THREADS 100000
#define SIZE 20
#define BLOCK_WIDTH 500
__global__ void gpu_increment_without_atomic(int* d_a)
{
// Calculate thread id for current thread
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// each thread increments elements wrapping at SIZE variable
tid = tid % SIZE;
d_a[tid] += 1;
}
int main(int argc, char** argv)
{
printf("%d total threads in %d blocks writing into %d array elements\n",
NUM_THREADS, NUM_THREADS / BLOCK_WIDTH, SIZE);
// declare and allocate host memory
int h_a[SIZE];
const int ARRAY_BYTES = SIZE * sizeof(int);
// declare and allocate GPU memory
int* d_a;
cudaMalloc((void**)&d_a, ARRAY_BYTES);
//Initialize GPU memory to zero
cudaMemset((void*)d_a, 0, ARRAY_BYTES);
gpu_increment_without_atomic << <NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH >> > (d_a);
// copy back the array to host memory
cudaMemcpy(h_a, d_a, ARRAY_BYTES, cudaMemcpyDeviceToHost);
printf("Number of times a particular Array index has been incremented without atomic add is: \n");
for (int i = 0; i < SIZE; i++)
{
printf("index: %d --> %d times\n ", i, h_a[i]);
}
cudaFree(d_a);
return 0;
}
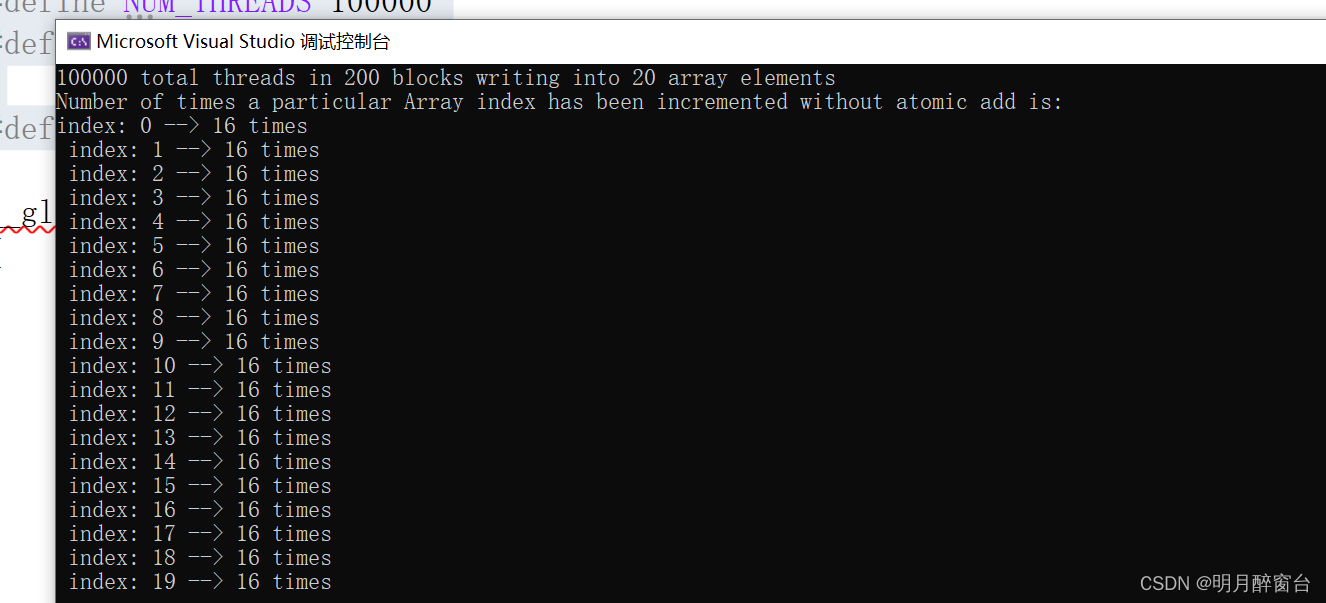
- tid在计算过程中的变换范围可以退出最终数组计算结果的范围,针对上述代码可以知道最终计算的正确结果是每个值被执行了5000次+1,最终的正确结果应是5000,但是运行结果显示最终只被增加了十几次(每次计算结果随机的,初始值为0),这是因为很多线程同时读取同样的位置,然后增加到了同样的值,然后将它们保存到显存中,得到了错误的结果,错误结果如下:


- 为了解决以上问题,CUDA提供了
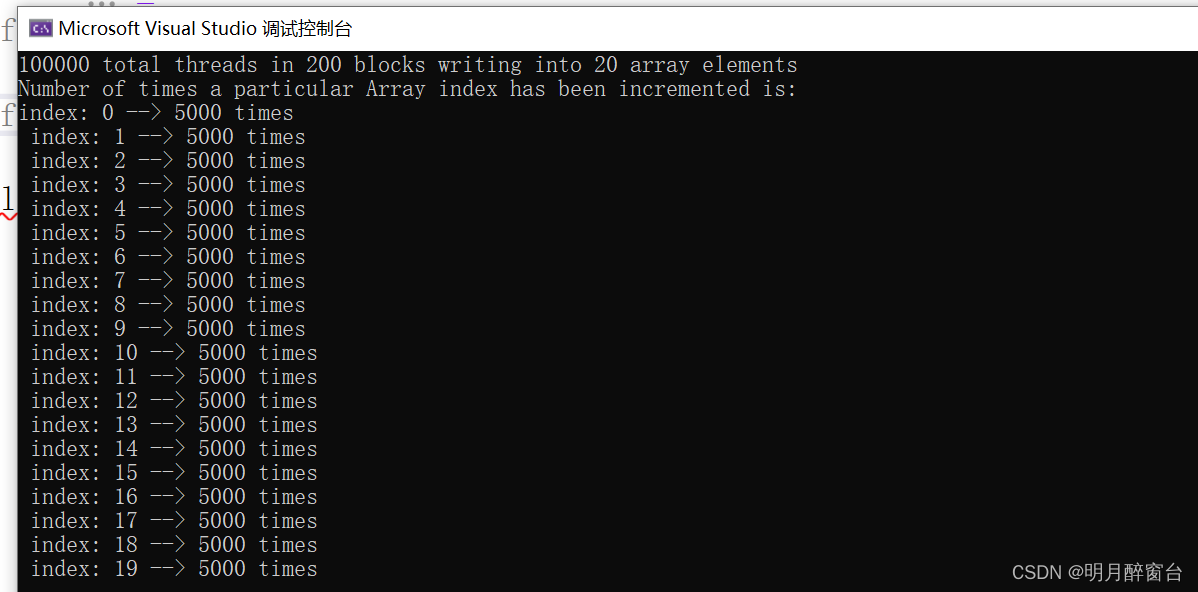
atomicAdd这种原子操作函数,该函数会从逻辑上保证,每个调用它的线程对相同的内存区域上的“读取旧值 - 累加 - 回写新值”操作时不可被其他线程扰乱的原子性的整体完成的 - 使用atomicAdd 进行原子累加的内核函数如下:
#include <stdio.h>
#define NUM_THREADS 100000
#define SIZE 20
#define BLOCK_WIDTH 500
__global__ void gpu_increment_atomic(int* d_a)
{
// Calculate thread id for current thread
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// each thread increments elements wrapping at SIZE variable
tid = tid % SIZE;
atomicAdd(&d_a[tid], 1);
}
int main(int argc, char** argv)
{
printf("%d total threads in %d blocks writing into %d array elements\n",
NUM_THREADS, NUM_THREADS / BLOCK_WIDTH, SIZE);
// declare and allocate host memory
int h_a[SIZE];
const int ARRAY_BYTES = SIZE * sizeof(int);
// declare and allocate GPU memory
int* d_a;
cudaMalloc((void**)&d_a, ARRAY_BYTES);
//Initialize GPU memory to zero
cudaMemset((void*)d_a, 0, ARRAY_BYTES);
gpu_increment_atomic << <NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH >> > (d_a);
// copy back the array to host memory
cudaMemcpy(h_a, d_a, ARRAY_BYTES, cudaMemcpyDeviceToHost);
printf("Number of times a particular Array index has been incremented is: \n");
for (int i = 0; i < SIZE; i++)
{
printf("index: %d --> %d times\n ", i, h_a[i]);
}
cudaFree(d_a);
return 0;
}
-
如果测量一下运行时间,相比之前的那个简单的在全局内存上直接进行加法操作的程它用的时间更长,这是因为使用原子操作后程序具有更大的执行代价,但可以通过共享内存来加速这些原子累加操作
-
如果线程规模不变,但原子操作的元素数量扩大,则这些同样次数的原子操作会更快的完成。这是因为更广泛的分布范围上的原子操作有利于利用多个能执行原子操作的单元,以及每个原子操作单元上面的竞争性的原子事务也相应减少了
-
---- end----






![攻防世界[GoodRe]](https://img-blog.csdnimg.cn/img_convert/e0b5dea2797384c00ae1817348a982d0.png)