文章目录
- Happens-Before原则
- 1.Happens-Before规则介绍
- 2.规格介绍
- 2.1.顺序性规则(as-if-serial)
- 2.2.volatile规则
- 2.3.传递性规则
- 2.4.监视锁规则
- 2.5.start规则
- 2.6.join()规则
Happens-Before原则
JVM内存屏障指令对Java开发工程师是透明的,是JMM对JVM实现的一种规范和要求。
JMM定义了一套自己的规则,Happens-Before规则(先行发生),并且确保两个Java语句必须存在Happens-Before关系,JMM尽量确保这俩个Java语句之间的内存可见性和指令的有序性。
1.Happens-Before规则介绍
- 程序顺序执行规则(as-if-serial规则)
- 在同一个线程中有依赖关系的操作规则按照先后顺序,前一个操作必须先行发生于后面一个操作(例如线程 A - 线程 B 有依赖关系,线程A必须先执行,然后才能执行线程B)。
- 总的来说就是单线程顺序无论怎么排序,对于结果来是不会变得。
- volatile变量规则
- 对于volatile修饰的变量,必须的
写操作,必须先于发生对volatile的读操作
- 对于volatile修饰的变量,必须的
- 传递性规则
- 如果
线程 A先行发生于线程 B操作,线程 B操作又先行发生于线程 C操作,那么线程 A必须先行发生于线程 C操作。
- 如果
- 监视锁规则(Monitor Lock Rule)
- 对于一个监视锁的解锁操作先行发生 于 后续对这个监视锁的加锁操作。(同一个线程,解锁操作,必须先于加锁操作之前执行)
- start规则
- 对于线程的
start操作先行发生于这个线程内部的其他任何操作。具体来说,如果线程A执行线程B的start()方法,那么线程A 启动线程 B 的 start()方法,先于发生线程B中的任意操作。
- 对于线程的
- join规则
- 如果线程A执行了
线程B的join()方法,那么线程B的任意操作,先行发生于线程A所执行的线程B的join()方法
- 如果线程A执行了
2.规格介绍
2.1.顺序性规则(as-if-serial)
顺序性规则的具体内容:一个线程内,按照代码顺序书写在前面的操作,先行发生于 书写在后面的操作。
顺序性规则是Java内存模型(JMM)中一个基本的概念,它保证了在一个线程内部观察到的操作执行顺序,会符合程序代码的逻辑顺序。这意味着,在单线程环境下,程序的执行将保持我们书写的指令顺序,不会出现乱序执行的情况。简单来说,如果在代码中先写了操作A,然后是操作B,那么在同一个线程中执行时,A必然会在B之前完成,不会出现B先于A执行的结果。
虽然可能发生重排序,但是他只对不存在数据依赖代码行,进行指令重排序
int x = 0;
int y = 0;
void method() {
x = 1; // 操作A
y = 2; // 操作B
}
根据顺序性规则,在method方法内部,操作A(x = 1;)总是会先于操作B(y = 2;)执行完成。这意味着,在同一个线程调用method方法后,任何检查x和y值的后续代码都将看到x为1且y为2,不可能看到y已经更新为2而x还未被设置为1的情况。
2.2.volatile规则
volatile的具体内容:对一个volatile变量的的写,先行发生于任意后续对这个volatile变量的读。
volatile的主要作用:
- **保证可见性:**对一个
volatile变量的修改,能够立即刷新到主内存中,所有其他线程对该变量的访问都会重新从主内存中获取最新值,从而确保了变量的可见性。 - **禁止指令重排序:**volatile除了保证变量的可见性外,还有一层重要的意义在于它能
禁止指令的重排序优化。具体来说,对volatile变量的写操作,在写后,会有一个内存屏障(Memory Barrier),确保该写操作不会被重排序到之后的读写操作之前;相应的,对volatile变量的读操作前也会有一个内存屏障,确保该读操作不会被重排序到之前的写操作之后。这正是你提到的“对一个volatile变量的写,先行发生于任意后续对这个volatile变量的读。
package com.hrfan.thread;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
// 每个参与测试的线程都将拥有其独立的实例
@State(Scope.Thread)
public class VolatileRecorderDemo {
int x = 10;
int value = 0;
boolean flag = false;
public void update() {
x = 100; // 代码1
flag = true; // 代码2
}
public synchronized void add() {
if (flag) { // 代码3
value = x + x;
System.out.println(Thread.currentThread().getName() + "- value:" + value);
}
}
@Benchmark
public void test(){
// 假设线程1 执行 update(),线程2 执行 add(),代码1 和 代码2 并没有依赖关系,所以 代码1 和 代码2 可能被重排序,他们排序后结果为
// flag = true;
// value = 100;
// 假设重排序后,线程1 执行了 flag = true; 此时还没有执行 value = 10; 线程2 开始执行 add()方法.此时value的值为 10
// 那么最终结果 value = 20 而不是 200
VolatileRecorderDemo volatileRecorderDemo = new VolatileRecorderDemo();
volatileRecorderDemo.update();
volatileRecorderDemo.add();
}
@Test
@DisplayName("测试")
public void start() {
Options opt = new OptionsBuilder()
.include(VolatileRecorderDemo.class.getSimpleName())
// 预热3轮
.warmupIterations(3)
// 度量5轮
.measurementIterations(5)
// 设置线程数,比如设置为4个线程
.threads(200)
// fork的JVM实例数量 每轮任务数量
.forks(5)
.build();
try {
new Runner(opt).run();
} catch (RunnerException e) {
throw new RuntimeException(e);
}
}
}
假设线程A执行 update()方法,线程B 执行 add()方法,因为代码1 和代码2并没有依赖关系,所以代码1 和代码2就可能会被重排序,他们重排序后的次序可能为
flag = true; // 代码2
value = 100; // 代码1
线程A执行重排代码后,在完成 代码2 之前(flag = true),假设线程B开始执行 add()方法,将 x 的值进行累加,此时的 x 的值就是 10 而不是100,那么 x 累加完成后的值就是 20。这个不是我们想要的结果,为了获取正确的结果,我们必须阻止代码进行重排序,为以上代码的flag成员属性增加 volatile修饰,
public class VolatileRecorderDemo {
int x = 10;
int value = 0;
volatile boolean flag = false;
public void update() {
x = 100; // 代码1
flag = true; // 代码2
}
public synchronized void add() {
if (flag) { // 代码3
value = x + x; // 代码4
System.out.println(Thread.currentThread().getName() + "- value:" + value);
}
}
}
从前面的顺序性规则,已经知道,如果 代码2的操作为 volatile写,无论第一个操作是什么都不能重排序。所以代码1 不会排到 代码2 后面的。
代码3 为读取 flag(volatile)变量,那么 代码4 就不会被重排序到 代码3 之前。
2.3.传递性规则
如果
线程 A先行发生于线程 B操作,线程 B操作又先行发生于线程 C操作,那么线程 A必须先行发生于线程 C操作。
例如,如果线程A修改了一个变量,然后线程B读取了这个变量的值,并且线程B接着修改了另一个变量,线程C随后读取线程B修改的变量值,根据传递性规则,线程A对第一个变量的修改操作在逻辑上必须在C线程读取第二个变量值之前发生,保证了跨线程间操作的正确序列化。
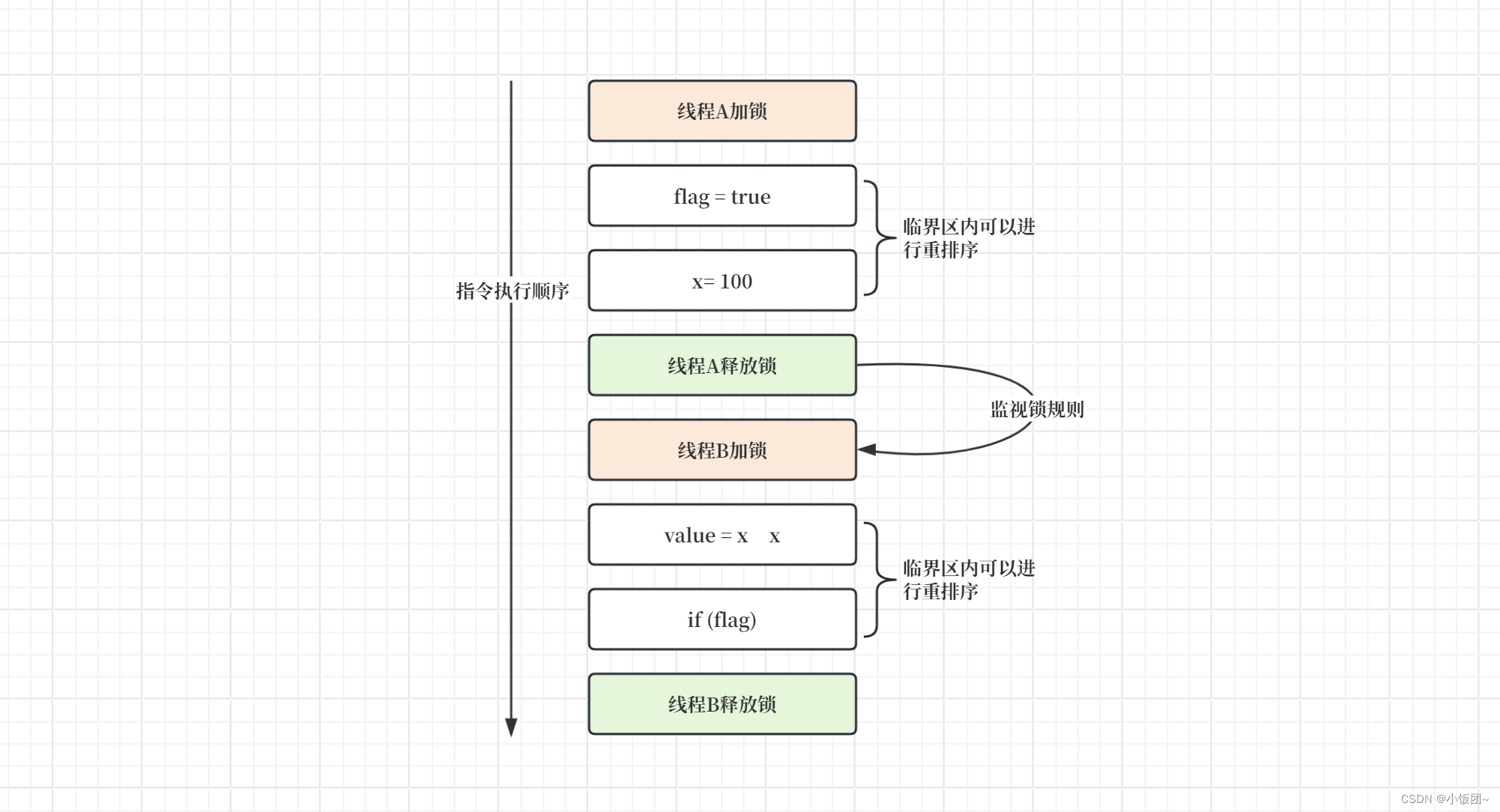
2.4.监视锁规则
对于一个监视锁的解锁操作先行发生 于 后续对这个监视锁的加锁操作。(同一个线程,解锁操作,必须先于加锁操作之前执行)
在Java内存模型中,监视锁规则规定了对于同一个监视器(Monitor,通常指由synchronized关键字实现的同步块或方法)的解锁操作,必须先行发生于后续针对该监视器的加锁操作。这意味着,如果线程A解锁了一个监视器(即退出了同步代码块或方法),那么这个解锁操作将发生在任何其他线程B(包括线程A自身)随后成功获取这个监视器锁的操作之前。这一规则确保了以下几点:
- 线程间的操作顺序性:锁的解锁和加锁操作为线程间的操作提供了一种全局的顺序关系,帮助维护操作的执行顺序性,这对于理解并发程序的行为至关重要。
- 内存可见性:解锁操作之前的所有内存写操作对随后的加锁操作后的线程都是可见的,确保了数据的正确同步。
- 互斥性:保证了在任何时刻只有一个线程可以持有监视器的锁,从而防止数据竞争条件和不一致状态的读取。
public class VolatileRecorderDemo2 {
int x = 10;
int value = 0;
boolean flag = false;
public synchronized void update() {
value = 100; // 代码1
flag = true; // 代码2
}
public synchronized void add() {
if (flag) { // 代码3
value = x + x; // 代码4
System.out.println("x = " + x);
}
}
}
先获取锁的线程,读 value 赋值之后,释放锁,那么另外一个线程 再去获取锁的时候,一定能看到对 value赋值的改动。
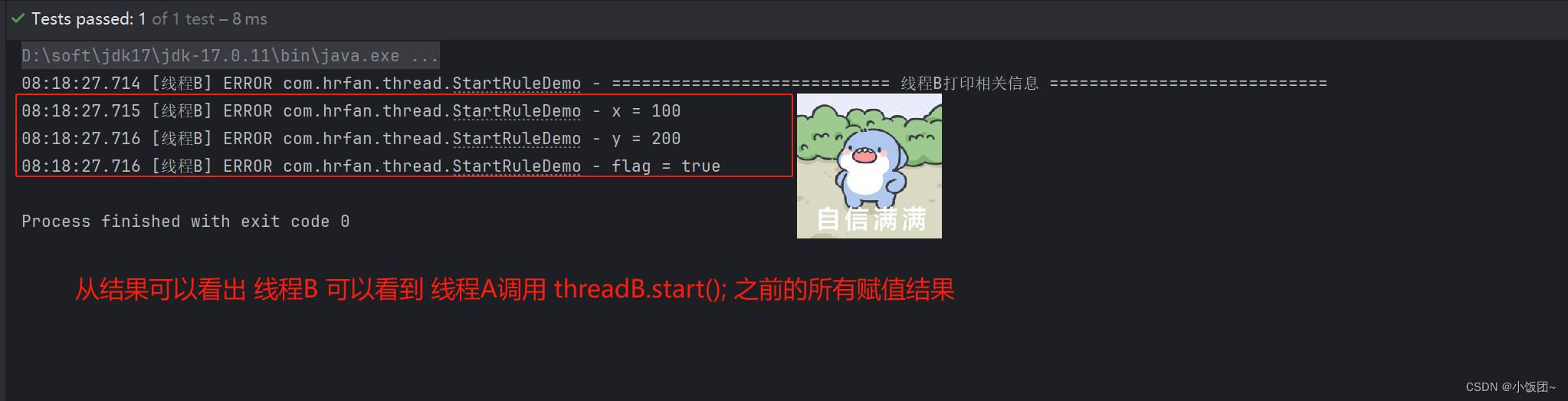
2.5.start规则
对于线程的
start操作先行发生于这个线程内部的其他任何操作。具体来说,如果线程A执行线程B的start()方法,那么线程A 启动线程 B 的 start()方法,先于发生线程B中的任意操作。简单来说,就是
主线程A启动子线程B后,线程B能看到线程A在启动操作前的任何操作
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class StartRuleDemo {
private static final Logger log = LoggerFactory.getLogger(StartRuleDemo.class);
private int x = 0;
private int y = 0;
private Boolean flag = false;
@Test
@DisplayName("测试start()规则")
public void testStartRule() throws InterruptedException {
// 创建线程B 先不启动
Thread threadB = new Thread(this::printInfo, "线程B");
// 线程A 先 对数据进行赋值操作
Thread threadA = new Thread(() -> {
x = 100;
y = 200;
flag = true;
// 启动线程B
threadB.start();
}, "线程A");
threadA.start();
}
public void printInfo() {
log.error("============================ 线程B打印相关信息 ============================");
log.error("x = {}", x);
log.error("y = {}", y);
log.error("flag = {}", flag);
}
}
2.6.join()规则
join()规则的具体内容是:如果
线程A执行threadB.join()操作后,并成功返回。那么线程B中的任意操作,先行发生于线程A的 threadB.Join()。这意味着,通过调用
join(),线程A确保了线程B的所有操作都已经完成了,这包括线程B的执行、修改共享变量、资源释放等,所有这些都完全发生在线程A得以继续其后续代码执行之前。这保证了线程间操作的顺序性和数据的一致性,避免了因并发执行可能产生的数据竞争问题。join() 规则 刚好和 start()规则 相反
在Java中,Thread.join()方法是一个非常重要的同步机制,它允许一个线程等待另一个线程执行完成后再继续执行。
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class StartRuleDemo {
private static final Logger log = LoggerFactory.getLogger(StartRuleDemo.class);
private int x = 0;
private int y = 0;
private Boolean flag = false;
@Test
@DisplayName("测试join()规则")
public void testJoinRule() throws InterruptedException {
// 创建线程B 先不启动
Thread threadB = new Thread(this::updateThreadB, "线程B");
// 线程A 先 对数据进行赋值操作
Thread threadA = new Thread(() -> {
// 启动线程B
threadB.start();
try {
threadB.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
printInfo();
}, "线程A");
threadA.start();
}
public void printInfo() {
log.error("============================ 线程A打印相关信息 ============================");
log.error("x = {}", x);
log.error("y = {}", y);
log.error("flag = {}", flag);
}
public void updateThreadB(){
this.x = 100;
this.y = 200;
this.flag = true;
}
}




![[Algorithm][动态规划][简单多状态DP问题][按摩师][打家劫舍Ⅱ][删除并获得点数][粉刷房子]详细讲解](https://img-blog.csdnimg.cn/direct/8a6fa54fc36e41d0b0427a79e1c28071.png)