目录
一,RDD,DataFrame和DataSet对比
二,创建DataFrame
本节将介绍SparkSQL编程基本概念和基本用法。
不同于RDD编程的命令式编程范式,SparkSQL编程是一种声明式编程范式,我们可以通过SQL语句或者调用DataFrame的相关API描述我们想要实现的操作。
然后Spark会将我们的描述进行语法解析,找到相应的执行计划并对其进行流程优化,然后调用相应基础命令进行执行。
我们使用pyspark进行RDD编程时,在Excutor上跑的很多时候就是Python代码,当然,少数时候也会跑java字节码。
但我们使用pyspark进行SparkSQL编程时,在Excutor上跑的全部是java字节码,pyspark在Driver端就将相应的Python代码转换成了java任务然后放到Excutor上执行。
因此,使用SparkSQL的编程范式进行编程,我们能够取得几乎和直接使用scala/java进行编程相当的效率(忽略语法解析时间差异)。此外SparkSQL提供了非常方便的数据读写API,我们可以用它和Hive表,HDFS,mysql表,Cassandra,Hbase等各种存储媒介进行数据交换。
美中不足的是,SparkSQL的灵活性会稍差一些,其默认支持的数据类型通常只有Int,Long,Float,Double,String,Boolean 等这些标准SQL数据类型, 类型扩展相对繁琐。对于一些较为SQL中不直接支持的功能,通常可以借助于用户自定义函数(UDF)来实现,如果功能更加复杂,则可以转成RDD来进行实现。
#SparkSQL的许多功能封装在SparkSession的方法接口中
spark = SparkSession.builder \
.appName("test") \
.config("master","local[4]") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext一,RDD,DataFrame和DataSet对比
DataFrame参照了Pandas的思想,在RDD基础上增加了schma,能够获取列名信息。
DataSet在DataFrame基础上进一步增加了数据类型信息,可以在编译时发现类型错误。
DataFrame可以看成DataSet[Row],两者的API接口完全相同。
DataFrame和DataSet都支持SQL交互式查询,可以和 Hive无缝衔接。
DataSet只有Scala语言和Java语言接口中才支持,在Python和R语言接口只支持DataFrame。
DataFrame数据结构本质上是通过RDD来实现的,但是RDD是一种行存储的数据结构,而DataFrame是一种列存储的数据结构。
二,创建DataFrame
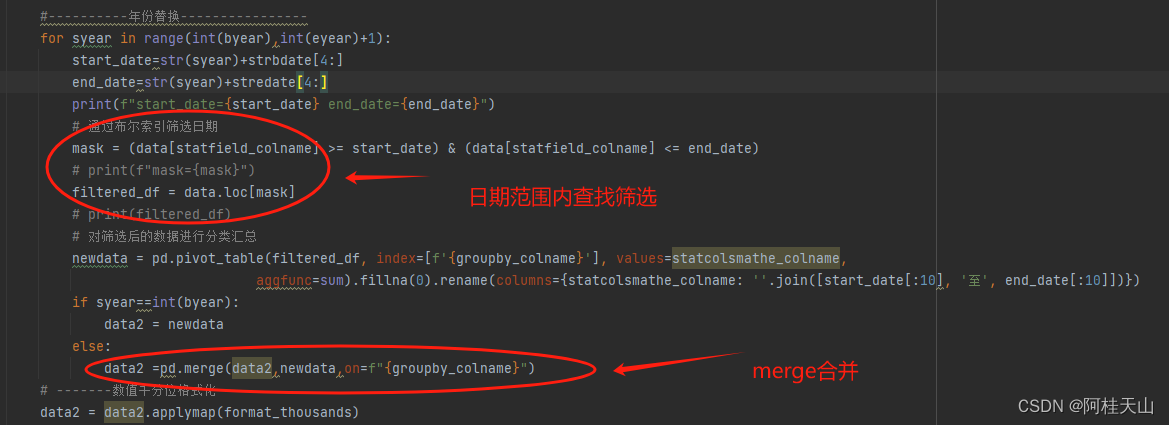
1,通过toDF方法转换成DataFrame
可以将RDD用toDF方法转换成DataFrame
#将RDD转换成DataFrame
rdd = sc.parallelize([("LiLei",15,88),("HanMeiMei",16,90),("DaChui",17,60)])
df = rdd.toDF(["name","age","score"])
df.show()
df.printSchema()
+---------+---+-----+
| name|age|score|
+---------+---+-----+
| LiLei| 15| 88|
|HanMeiMei| 16| 90|
| DaChui| 17| 60|
+---------+---+-----+
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- score: long (nullable = true)2, 通过createDataFrame方法将Pandas.DataFrame转换成pyspark中的DataFrame
import pandas as pd
pdf = pd.DataFrame([("LiLei",18),("HanMeiMei",17)],columns = ["name","age"])
df = spark.createDataFrame(pdf)
df.show()
+---------+---+
| name|age|
+---------+---+
| LiLei| 18|
|HanMeiMei| 17|
+---------+---+
# 也可以对列表直接转换
values = [("LiLei",18),("HanMeiMei",17)]
df = spark.createDataFrame(values,["name","age"])
df.show()
+---------+---+
| name|age|
+---------+---+
| LiLei| 18|
|HanMeiMei| 17|
+---------+---+3, 通过createDataFrame方法指定schema动态创建DataFrame
可以通过createDataFrame的方法指定rdd和schema创建DataFrame。
这种方法比较繁琐,但是可以在预先不知道schema和数据类型的情况下在代码中动态创建DataFrame.
from pyspark.sql.types import *
from pyspark.sql import Row
from datetime import datetime
schema = StructType([StructField("name", StringType(), nullable = False),
StructField("score", IntegerType(), nullable = True),
StructField("birthday", DateType(), nullable = True)])
rdd = sc.parallelize([Row("LiLei",87,datetime(2010,1,5)),
Row("HanMeiMei",90,datetime(2009,3,1)),
Row("DaChui",None,datetime(2008,7,2))])
dfstudent = spark.createDataFrame(rdd, schema)
dfstudent.show()
+---------+-----+----------+
| name|score| birthday|
+---------+-----+----------+
| LiLei| 87|2010-01-05|
|HanMeiMei| 90|2009-03-01|
| DaChui| null|2008-07-02|
+---------+-----+----------+4,通过读取文件创建
可以读取json文件,csv文件,hive数据表或者mysql数据表得到DataFrame。
#读取json文件生成DataFrame
df = spark.read.json("data/people.json")
df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
#读取csv文件
df = spark.read.option("header","true") \
.option("inferSchema","true") \
.option("delimiter", ",") \
.csv("data/iris.csv")
df.show(5)
df.printSchema()
+-----------+----------+-----------+----------+-----+
|sepallength|sepalwidth|petallength|petalwidth|label|
+-----------+----------+-----------+----------+-----+
| 5.1| 3.5| 1.4| 0.2| 0|
| 4.9| 3.0| 1.4| 0.2| 0|
| 4.7| 3.2| 1.3| 0.2| 0|
| 4.6| 3.1| 1.5| 0.2| 0|
| 5.0| 3.6| 1.4| 0.2| 0|
+-----------+----------+-----------+----------+-----+
only showing top 5 rows
root
|-- sepallength: double (nullable = true)
|-- sepalwidth: double (nullable = true)
|-- petallength: double (nullable = true)
|-- petalwidth: double (nullable = true)
|-- label: integer (nullable = true)
#读取csv文件
df = spark.read.format("com.databricks.spark.csv") \
.option("header","true") \
.option("inferSchema","true") \
.option("delimiter", ",") \
.load("data/iris.csv")
df.show(5)
df.printSchema()
+-----------+----------+-----------+----------+-----+
|sepallength|sepalwidth|petallength|petalwidth|label|
+-----------+----------+-----------+----------+-----+
| 5.1| 3.5| 1.4| 0.2| 0|
| 4.9| 3.0| 1.4| 0.2| 0|
| 4.7| 3.2| 1.3| 0.2| 0|
| 4.6| 3.1| 1.5| 0.2| 0|
| 5.0| 3.6| 1.4| 0.2| 0|
+-----------+----------+-----------+----------+-----+
only showing top 5 rows
root
|-- sepallength: double (nullable = true)
|-- sepalwidth: double (nullable = true)
|-- petallength: double (nullable = true)
|-- petalwidth: double (nullable = true)
|-- label: integer (nullable = true)
#读取parquet文件
df = spark.read.parquet("data/users.parquet")
df.show()
#读取hive数据表生成DataFrame
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
spark.sql("LOAD DATA LOCAL INPATH 'data/kv1.txt' INTO TABLE src")
df = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
df.show(5)
#读取mysql数据表生成DataFrame
"""
url = "jdbc:mysql://localhost:3306/test"
df = spark.read.format("jdbc") \
.option("url", url) \
.option("dbtable", "runoob_tbl") \
.option("user", "root") \
.option("password", "0845") \
.load()\
df.show()
"""