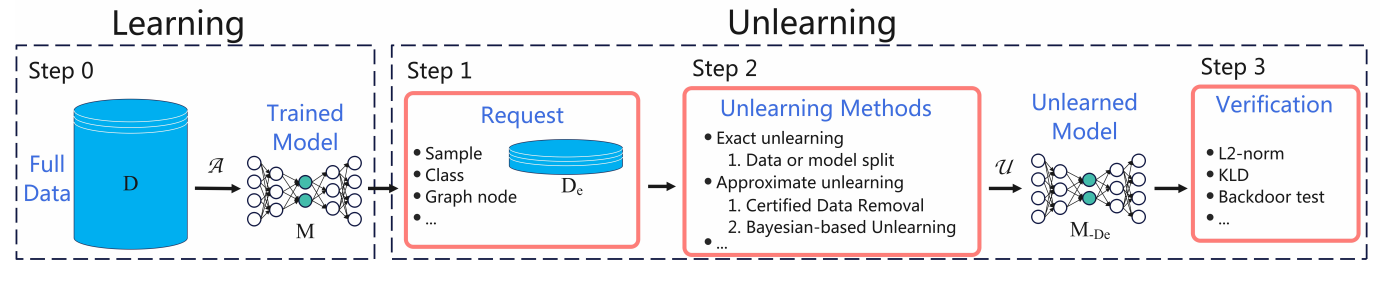
在信息时代,我们常常希望人工智能能够学到更多的知识,变得更加智能。但你是否想过,有时候让机器"忘记"一些它学到的东西,也是一件很重要的事?
随着用户隐私保护意识的提高和相关法律法规的出台,用户有权要求企业或机构删除其个人数据。对于使用机器学习方法的应用来说,这就意味着需要让训练好的模型"忘掉"某些用户的数据,让模型"机器遗忘"。但是,对已经训练好的模型进行"减法"远比"加法"困难。因为在机器学习的过程中,每个样本对模型的影响是交织在一起的,很难精准地"剔除"某个数据的影响。
除了保护隐私,机器遗忘在修正有偏见的模型、提高模型鲁棒性等方面也有重要作用。本文将带您全面了解"机器遗忘"这一崭新的研究方向,介绍其主要挑战和代表性的技术方法。让我们一起探索这一有趣而又充满潜力的领域,了解"忘记"也是人工智能需要学习的一门学问。
论文标题:
Machine Unlearning: A Comprehensive Survey
论文链接:
https://arxiv.org/pdf/2405.07406
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
在信息爆炸的时代,机器学习模型变得越来越强大,但也面临着新的挑战——如何"忘记"不再需要的数据和知识。本文将带你探索"机器遗忘"这一前沿研究方向。
让机器学会"忘记"有多难?
传统的机器学习模型就像一个"海绵",不断吸收数据,但却不知道如何"挤压"出不需要的部分。当用户要求删除个人数据时,简单地从训练集中移除这些数据是不够的,因为模型已经从这些数据中学到了知识,形成了某种"记忆"。

要让模型真正"忘记"某些数据,面临三大挑战:
-
训练过程的随机性(Stochasticity of training):模型训练过程中引入的随机性(如随机初始化、数据采样、mini-batch梯度下降等),导致每次训练的结果都不完全相同,给"遗忘"某些数据带来困难。即便使用相同的训练数据,重新训练得到的模型也可能与之前的模型有差异。
-
训练过程的增量性(Incrementality of training):模型通过增量方式不断学习新数据,每个数据对模型的影响相互交织。前面学习的数据会影响后续数据对模型的作用。当要"遗忘"某些数据时,很难准确估计和剥离这些数据对模型的影响,因为它们已经间接地影响了其他数据的学习过程。
-
灾难性遗忘(Catastrophic forgetting):当要"遗忘"的数据量较大时,通过各种机器遗忘技术得到的新模型性能可能大幅下降,其效果远逊于重新训练的模型。这种令人惊讶的性能下降被称为"灾难性遗忘"。如何在避免隐私泄露的同时,尽量减轻机器遗忘带来的副作用也是一大挑战。

此外,机器遗忘还面临如何衡量遗忘效果的问题。传统的模型评估指标(如准确率)无法直接度量隐私泄露风险。需要新的评估指标来权衡模型性能和隐私保护强度,这也是一个亟待探索的方向。
综上,让机器学会"忘记"绝非易事。研究者们需要攻克随机性、增量性、灾难性遗忘等难题,并设计出科学的评估指标,才能实现高质量的机器遗忘。这需要机器学习、隐私保护、安全等多个领域的交叉探索和创新。
机器遗忘技术大比拼
面对机器遗忘的重重挑战,研究者们提出了多种解决方案。总的来说,主流的机器遗忘技术可分为两大类:精准遗忘和近似遗忘。
精准遗忘:给记忆"做减法"
精准遗忘的核心思想是:与其在完整模型上直接"遗忘",不如先把模型"分解"成多个部分,再在局部进行遗忘,最后再把它们"组装"起来。这样可以在一定程度上规避随机性和增量性带来的影响。
以SISA(Sharded, Isolated, Sliced, and Aggregated)训练方法为例,它将训练数据分成多个独立的"碎片",并在每个碎片上训练一个独立的子模型。当需要遗忘某些数据时,只需找到对应的碎片,重新训练该碎片上的子模型,而其他子模型不受影响。最后,再将各个子模型聚合起来,得到完整的"遗忘后"模型。

类似地,一些研究将模型划分为多个独立的模块,每个模块只学习一部分数据的特征。遗忘时只需重新训练相应的模块即可。还有一些工作利用决策树、随机森林等易于分解的模型结构,实现高效的机器遗忘。
近似遗忘:估计并抵消"记忆"影响
近似遗忘则试图直接从已训练好的完整模型入手,估计要遗忘的数据对模型的影响,并从模型中"减去"这种影响。由于这种方法只需操作一个完整模型,因此往往更简单和高效。但另一方面,由于很难准确估计出某些数据对模型的精确影响,遗忘的效果可能没有精准遗忘那么"干净利落"。
下图展示了在分类模型中添加或移除一个数据点时的变化情况。当一个有影响力的数据点出现时,它通常会推动分类线向前移动,以识别该数据点,如图(b)所示。当需要移除这个有影响力的数据点时,机器遗忘机制必须将模型恢复到未训练该特定数据点的原始状态,如图(c)所示。然而,当仅遗忘一个几乎没有影响力的数据点时,该数据点可能对模型几乎没有影响,在这种情况下,遗忘后的模型可能与原始训练的模型相比没有变化,如图(d)所示。

常见的近似遗忘方法包括:基于影响函数的方法,它们估计每个训练数据对模型的贡献,并在遗忘时对这些贡献进行反向操作;基于梯度的方法,它们将遗忘目标表示为一个约束优化问题,通过特定的梯度更新策略来不断"消除"某些数据的影响;还有一些工作利用黑塞矩阵或Fisher信息矩阵来近似每个数据的影响。
近似遗忘要解决的核心问题是:如何在高效地遗忘的同时,尽量控制遗忘导致的性能损失。一些改进方法包括:调节遗忘力度的平衡因子、设定遗忘数据比例的上限、通过特殊的正则化项限制遗忘过程中的模型"跳变"等。这有点类似"调药方",即根据病情和副作用来动态调整药量。
差分隐私:从"源头"上防止隐私泄露
除了在事后通过机器遗忘来"擦除"模型中的隐私数据,另一种思路是从一开始就训练出"隐私保护友好"的模型。差分隐私(Differential Privacy)正是这样一种理念,它通过在模型训练时引入随机噪声,使得模型输出对于有无某条数据变得不敏感,从而从源头上防止隐私泄露。

差分隐私的核心思想是,如果一个模型在训练时满足差分隐私,那么攻击者通过观察模型的输出,将无法判断某个特定的数据点是否在训练集中。形式化地说,一个机器学习算法𝑀满足(𝜖,𝛿)-差分隐私,当且仅当对于任意两个相邻数据集𝐷和𝐷′(即只相差一条数据),它们的输出分布𝑀(𝐷)和𝑀(𝐷′)是𝜖-相似的,且这种相似性以至少1−𝛿的概率成立。直观地说,𝜖越小隐私保护强度越大。
为了实现差分隐私,常用的方法是在训练过程中加入Laplace噪声或高斯噪声,以掩盖个体数据点的影响。还有一些工作利用梯度裁剪、模型压缩等技术,在保证隐私的同时尽量降低噪声对模型性能的影响。
一些研究尝试将差分隐私与机器遗忘相结合,用差分隐私的随机噪声取代需要遗忘的数据,从而避免了复杂的遗忘步骤。例如可以在模型训练时对梯度引入差分隐私噪声,这样训练得到的模型对于某些数据天然具有"遗忘性"。还可以利用差分隐私的思想来指导遗忘过程,通过隐私预算来控制遗忘对模型的影响。总的来说,差分隐私为机器遗忘提供了新的视角和方法。

当然,在引入噪声的同时保证模型的效用仍然是一个挑战。如何权衡隐私保护强度和模型性能,如何设计更加智能、自适应的噪声机制,如何在联邦学习、在线学习等复杂场景下实现差分隐私,都是值得进一步探索的问题。此外,差分隐私虽然提供了强大的隐私保护,但并非对所有攻击都是"免疫"的。研究者们仍在不断探索差分隐私的边界,并设计更加安全、鲁棒的机器学习框架。
"机器遗忘"实验室
为了验证机器遗忘的有效性,研究者们在多个基准数据集和实际任务上进行了广泛的实验。
在图像分类任务上,研究者们使用了MNIST手写数字数据集、CIFAR-10/100小型图像数据集、ImageNet大型图像数据集等。通过随机选取一部分训练样本作为需要遗忘的数据,然后对比原始模型、重新训练的模型和机器遗忘的模型在测试集上的准确率,可以评估机器遗忘的有效性。一般来说,重新训练的模型可以视为"完美遗忘"的参照。实验结果表明,许多机器遗忘方法都能在保持较高准确率的同时,有效地"忘记"指定的训练数据,其性能接近重新训练的模型。

在自然语言处理任务上,研究者们使用了情感分析、文本分类、问答系统等数据集。对于一些涉及用户隐私的文本数据,机器遗忘可以在保护隐私的同时,避免模型"忘记"过多有用的语言知识。通过精心设计的实验,研究者们验证了机器遗忘在文本领域的适用性和有效性。
除了这些经典的基准数据集,研究者们还在一些实际应用中测试了机器遗忘的效果。例如,在推荐系统中,当用户删除某些历史记录时,需要同时从推荐模型中"遗忘"这些记录对用户画像的影响。在异常检测任务中,当发现某些数据点可能是噪声或对抗样本时,需要动态地从模型中"遗忘"这些异常点的影响,以保证模型的鲁棒性。实验结果表明,机器遗忘可以在这些场景中发挥重要作用,在提升系统性能的同时satisfying隐私和安全需求。

当然,不同的机器遗忘技术在实验中的表现也有一定差异。一些方法可能在特定数据集或任务上表现得更好,而另一些方法可能具有更好的通用性。此外,机器遗忘的效果也依赖于多种因素,如遗忘数据的规模、模型的复杂度、超参数的选择等。因此,在实践中应用机器遗忘时,需要根据具体情况进行适当的选择和调优。
通过大量实验,研究者们证明了机器遗忘技术在各种数据集和任务上的有效性。这些实验结果不仅验证了已有方法的可行性,也为未来的研究指明了方向。随着机器遗忘在更多实际场景中的应用,其潜力和价值必将得到进一步的发掘和印证。
忘记,才能更好地前行
在本文中我们探讨了机器遗忘这一崭新的研究领域。从技术挑战到解决方案,从理论探索到实践应用,机器遗忘展现出了广阔的前景和无限的可能。
遗忘是智慧的一种体现。正如人类需要遗忘琐事以专注于重要的事情,机器也需要学会遗忘,以适应日新月异的环境和需求。通过选择性地遗忘过时、无用或有害的信息,机器学习模型可以保持灵活、高效、健壮,并不断进化以应对新的挑战。
同时,机器遗忘也是实现可信AI的重要一环。随着隐私保护和数据安全愈发受到重视,赋予用户"被遗忘权"已成为大势所趋。机器遗忘技术为数据管理和隐私合规提供了新的解决思路,有助于构建更加安全、透明、可控的人工智能生态。
展望未来,机器遗忘必将在人工智能的发展历程中扮演越来越重要的角色。它不仅是一种技术,更是一种智慧;不仅是一种手段,更是一种哲学。遗忘不是对过去的否定,而是为了更好地前行。唯有卸下包袱,方能走得更远!