唠唠嗑 水一水
- 引言
- Python 代码
- 结尾
![![[529.jpg]]](https://img-blog.csdnimg.cn/direct/a95acf6630bd48919289893d4e8ee64e.jpeg)
引言
今天星期六
大小周
一个等了很久的双休
昨天晚上真的是吓到我了
漫天的小飞虫
我一开始还以为是一两只
没想到那些小飞虫
从阳台不断飞进来
在山卡拉下面租房子
也是太恐怖了

来个特写

他们也就一个晚上的时间
成虫
天气合适
长翅
寻光
配偶
寻地交配
正应了那一句
大多见不到明天的太阳
这里为了严谨
查了一下这个大水蚁
真的是很水
Python 代码
# -*- coding: utf-8 -*-
# @Time : 2024/1/25 11:11
# @File : everyDayRequestwx.py
# @Software: vscode
# @author : Zercher
# @Desc : 爬取微信文章热榜前10 网址:https://www.gsdata.cn/rank/wxarc
import requests
from bs4 import BeautifulSoup
import pandas as pd
import tkinter as tk
from tkinter import ttk
import webbrowser
url = 'https://www.gsdata.cn/rank/wxarc'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
articleTitles = []
articleLinks = []
articlePublishs = []
articleLikes = []
for i in range(1, 11):
r = soup.find_all('tr')[i].find_all('td')
articleTitle = r[0].get_text().strip() # 去除首尾空格
articleLink = r[0].a['href']
articlePublish = r[1].get_text()
articleTitles.append(articleTitle)
articleLinks.append(articleLink)
articlePublishs.append(articlePublish)
articleLikes.append(r[4].get_text())
# 创建DataFrame
data = {
'标题': [articleTitle.strip() for articleTitle in articleTitles], # 去除首尾空格和换行符
'链接': articleLinks,
'来源': articlePublishs,
'点赞数': articleLikes
}
df = pd.DataFrame(data)
# 打印标题和来源
print(articleTitles)
print(articlePublishs)
# 保存为CSV文件
df.to_csv('news_data.csv', index=False, encoding='utf_8_sig')
print('爬取完成!')
# 创建主窗口
root = tk.Tk()
root.title("新闻信息")
# 创建Treeview控件,并设置其头部列名
treeview = ttk.Treeview(root, columns=("标题", "链接", "来源", '点赞数'), show="headings")
treeview.column("标题", width=500, anchor=tk.CENTER)
treeview.column("链接", width=300, anchor=tk.CENTER)
treeview.column("来源", width=150, anchor=tk.CENTER)
treeview.column("点赞数", width=150, anchor=tk.CENTER)
treeview.heading("标题", text="标题")
treeview.heading("链接", text="链接")
treeview.heading("来源", text="来源")
treeview.heading("点赞数", text="点赞数")
def open_url(event):
item = treeview.selection()[0] # 获取选中的行
url = treeview.item(item, "values")[1] # 获取该行的链接值
# 指定Edge浏览器打开链接
webbrowser.register('edge', None, webbrowser.BackgroundBrowser(r'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'))
webbrowser.get('edge').open(url)
treeview.bind('<Double-Button-1>', open_url) # 绑定鼠标左键释放事件
# 将数据插入到Treeview中并绑定点击事件
for i, (_title, _link, _publish, _Like) in enumerate(zip(articleTitles, articleLinks, articlePublishs, articleLikes)):
item_id = treeview.insert("", tk.END, values=(_title, _link, _publish, _Like))
# 显示Treeview
treeview.pack(fill=tk.BOTH, expand=True)
# 运行主循环
root.mainloop()
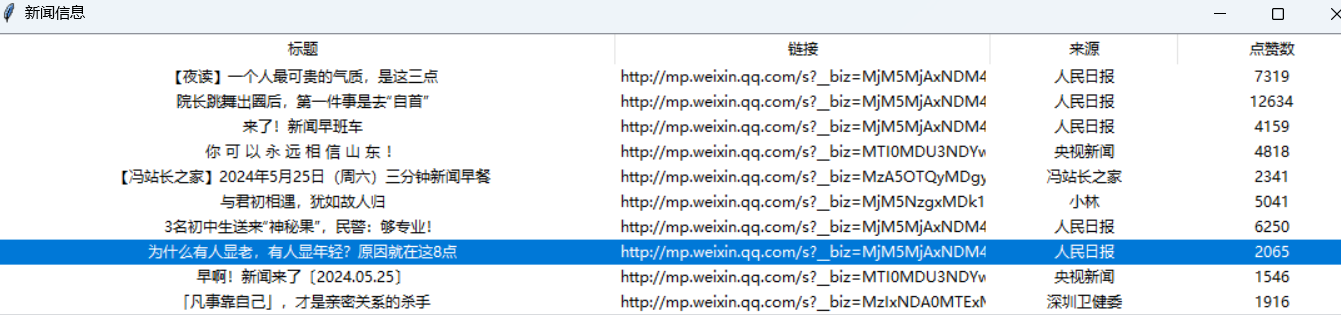
还是早上的好看
结尾
水
今天看足总杯比赛
曼联VS曼城
冲冲冲
关注我 😃
看打工人逆天改命(顺势而为)