文章目录
- 数据压缩概述
- MR支持的压缩编码格式和各自优缺点
- 压缩实操案例
- 1.Map输出端采用压缩
- 2.Reduce输出端采用压缩
数据压缩概述
Hadoop数据压缩是一种通过特定的算法来减小计算机文件大小的机制。这种机制在Hadoop中尤其重要,因为它可以有效减少底层存储系统(如HDFS)的读写字节数,从而提高网络带宽和磁盘空间的效率。在运行MapReduce程序时,尤其是在数据规模很大和工作负载密集的情况下,IO操作、网络数据传输、Shuffle和Merge等过程会花费大量的时间,因此数据压缩显得尤为重要。
在Hadoop中,压缩可以在MapReduce的任意阶段启用。对于运算密集型的job,建议少用压缩以减少CPU开销;而对于IO密集型的job,则建议多用压缩以节省磁盘I/O和网络带宽资源。
压缩文件有好处也有坏处
压缩的优点:以减少磁盘IO、减少磁盘存储空间。
压缩的缺点:增加CPU开销。
MR支持的压缩编码格式和各自优缺点
Gzip压缩
优点:压缩率比较高;
缺点:不支持Split;压缩/解压速度一般;
Bzip2压缩
优点:压缩率高;支持Split;
缺点:压缩/解压速度慢。
Lzo压缩
优点:压缩/解压速度比较快;支持Split;
缺点:压缩率一般;想支持切片需要额外创建索引。
Snappy压缩
优点:压缩和解压缩速度快;
缺点:不支持Split;压缩率一般;
压缩实操案例
以最简单的wordCount案例为例,(案例链接)
1.Map输出端采用压缩
即使MapReduce的输入输出文件都是未压缩的文件,你仍然可以对Map任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,对其压缩可以提高很多性能,这些工作只要设置两个属性即可:
// 开启map端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class,CompressionCodec.class);
其余的代码都不用动,只需增加这两行即可:

运行后的输出文件:
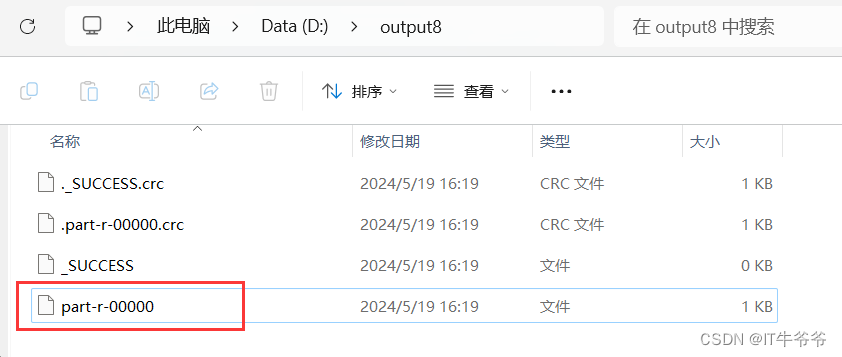

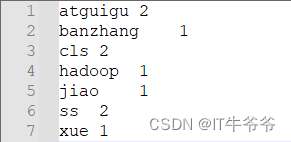
我们可以发现运行结果跟之前的案例没有任何区别,并没有产生压缩文件。这是因为虽然map进行了压缩,但是map输出到reduce之前就已经进行解压缩了。 最终的输出文件是由reduce来控制的,reduce并没有开启压缩,所以输出文件就是一个普通的文本。
2.Reduce输出端采用压缩
依然是设置两个属性即可:
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
依然是其余的代码都不用动,只需增加这两行即可:

然后运行,发现输出的文件发生了变化,变为了压缩包:

压缩包内的文本内容还是原来的内容:






![[手游] 正义对决3](https://img-blog.csdnimg.cn/img_convert/e35ec19029eab7e9d7f765ccd232af96.jpeg)