欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 二、功能
- 三、系统
- 四. 总结
一项目简介
手写数字识别是机器学习领域的一个基础问题,也是许多实际应用的基石,如邮政编码识别、银行表单处理、手写笔记识别等。通过训练一个KNN模型来识别手写数字,我们可以了解如何应用基本的机器学习算法来解决实际问题,并为更复杂的图像识别任务打下基础。
项目目标
本项目的目标是:
使用MNIST数据集,一个包含大量手写数字图片的大型公开数据集。
使用KNN算法对这些图片进行分类,以识别图片中的数字。
评估模型的性能,并尝试通过调整参数来优化性能。
数据集
MNIST是一个大型的手写数字数据库,通常用于训练和测试图像处理系统的性能。它由美国国家标准与技术研究所(NIST)发起,由Yann LeCun、Corinna Cortes和Chris Burges维护。该数据集包含60,000个训练样本和10,000个测试样本,每个样本都是28x28像素的灰度图像,表示一个0到9之间的手写数字。
技术实现
数据预处理:首先,加载MNIST数据集并将其拆分为特征(图像的像素值)和标签(数字)。然后,可能需要将像素值归一化到0到1之间,以便更好地适应KNN算法。
特征提取:对于KNN,我们通常将整个图像作为特征向量。在这个例子中,每个图像将被展平为一个784维的向量(28x28像素)。
模型训练:KNN是一种惰性学习方法,这意味着它不会在训练阶段进行任何计算或学习。相反,它会将所有训练数据存储在内存中,并在分类新样本时执行计算。在Python中,我们可以使用scikit-learn库中的KNeighborsClassifier类来实现KNN。
模型评估:使用测试集来评估模型的性能。常见的评估指标包括准确率、精确率、召回率和F1分数。由于这是一个多类分类问题,我们通常会关注准确率。
参数优化:尝试不同的K值(邻居的数量)来查看哪个值能给出最好的性能。K值的选择对KNN算法的性能有很大影响。
二、功能
基于Python+KNN神经网络手写数字识别
三、系统
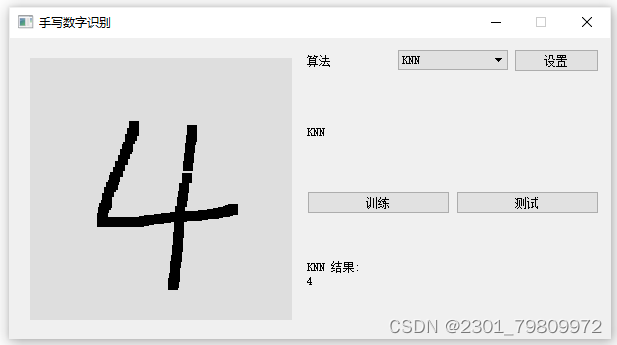
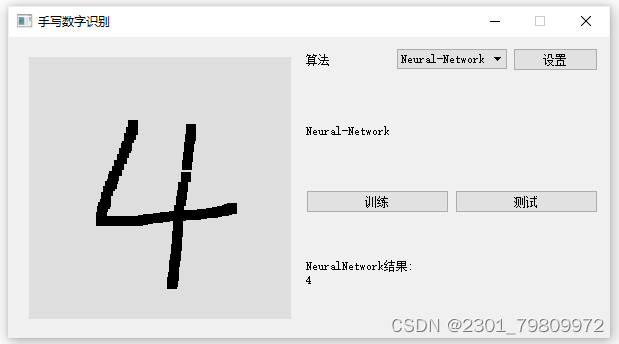
四. 总结
虽然KNN算法在手写数字识别任务中可能不是最先进的方法(更复杂的深度学习模型通常会取得更好的性能),但它提供了一种直观且易于理解的方法来解决这类问题。通过这个项目,你可以为更复杂的机器学习项目打下坚实的基础,并探索其他可能的改进方向,如使用更复杂的特征提取方法或集成多个模型来提高性能。