文章目录
- @[toc]
- Word Count
- Mapper
- Reducer
- run.sh
- 本地调试
- 基于白名单的Word Count
- Mapper
- Reducer
- run.sh
- 本地调试
- 文件分发
- -file
- Mapper
- Reducer
- run.sh
- -cacheFile
- Mapper
- Reducer
- run.sh
- -cacheArchive
- Mapper
- Reducer
- run.sh
- 杀死MapReduce Job
- 排序
- 压缩文件
- mr_ip_lib_python本地调试
文章目录
- @[toc]
- Word Count
- Mapper
- Reducer
- run.sh
- 本地调试
- 基于白名单的Word Count
- Mapper
- Reducer
- run.sh
- 本地调试
- 文件分发
- -file
- Mapper
- Reducer
- run.sh
- -cacheFile
- Mapper
- Reducer
- run.sh
- -cacheArchive
- Mapper
- Reducer
- run.sh
- 杀死MapReduce Job
- 排序
- 压缩文件
- mr_ip_lib_python本地调试

个人主页:丷从心·
系列专栏:大数据

Word Count

Mapper
import re
import sys
p = re.compile(r'\w+')
for line in sys.stdin:
word_list = line.strip().split(' ')
for word in word_list:
if len(p.findall(word)) < 1:
continue
word = p.findall(word)[0].lower()
print('\t'.join([word, '1']))
Reducer
import sys
cur_word = None
cur_cnt = 0
for line in sys.stdin:
word, val = line.strip().split('\t')
if cur_word == None:
cur_word = word
if cur_word != word:
print('\t'.join([cur_word, str(cur_cnt)]))
cur_word = word
cur_cnt = 0
cur_cnt += int(val)
print('\t'.join([cur_word, str(cur_cnt)]))
run.sh
HADOOP_CMD="/usr/local/src/hadoop_2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop_2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_PATH="/the_man_of_property.txt"
OUTPUT_PATH="/output_mr_wordcount"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py
本地调试
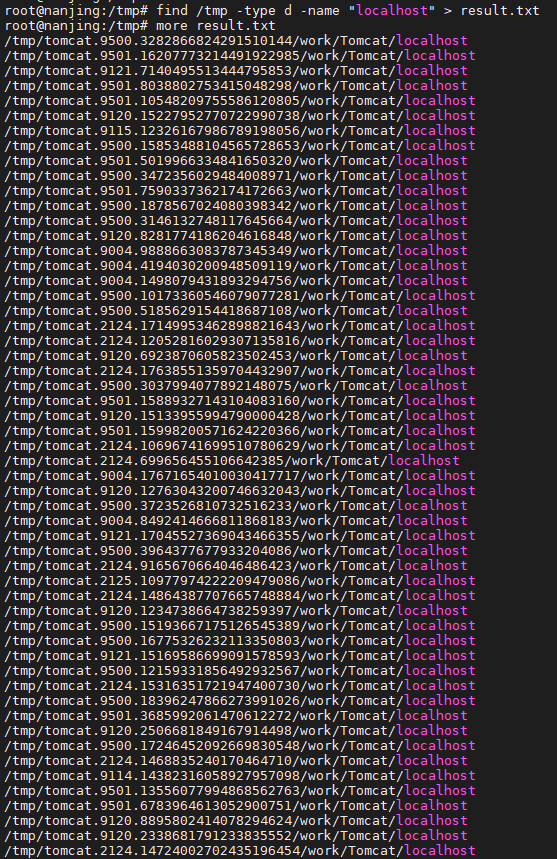
cat the_man_of_property.txt | python map.py | sort -k1 | python red.py > result.txt
cat result.txt | sort -k2 -rn | head
基于白名单的Word Count
Mapper
import sys
def get_white_list_word(white_list_file):
white_list_file = open(white_list_file, 'r')
white_list_word = set()
for word in white_list_file:
word = word.strip()
if word != '':
white_list_word.add(word)
return white_list_word
def mapper_func(white_list_file):
white_list_word = get_white_list_word(white_list_file)
for line in sys.stdin:
word_list = line.strip().split(' ')
for word in word_list:
word = word.strip()
if word != '' and word in white_list_word:
print('\t'.join([word, '1']))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
Reducer
import sys
def reducer_func():
cur_word = None
cur_cnt = 0
for line in sys.stdin:
word, val = line.strip().split('\t')
if cur_word == None:
cur_word = word
if cur_word != word:
print('\t'.join([cur_word, str(cur_cnt)]))
cur_word = word
cur_cnt = 0
cur_cnt += int(val)
print('\t'.join([cur_word, str(cur_cnt)]))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
run.sh
HADOOP_CMD="/usr/local/src/hadoop_2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop_2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_PATH="/the_man_of_property.txt"
OUTPUT_PATH="/output_mr_white_list_word_count"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func white_list" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=3" \
-jobconf "stream.non.zero.exit.is.failure=false" \
-file ./map.py \
-file ./red.py \
-file ./white_list
本地调试
cat the_man_of_property.txt | python map.py mapper_func white_list | sort -k1 | python red.py reducer_func > result.txt
cat the_man_of_property.txt | grep -o 'against' | wc -l
文件分发
-file
Mapper
import sys
def get_white_list_word(white_list_file):
white_list_file = open(white_list_file, 'r')
white_list_word = set()
for word in white_list_file:
word = word.strip()
if word != '':
white_list_word.add(word)
return white_list_word
def mapper_func(white_list_file):
white_list_word = get_white_list_word(white_list_file)
for line in sys.stdin:
word_list = line.strip().split(' ')
for word in word_list:
word = word.strip()
if word != '' and word in white_list_word:
print('\t'.join([word, '1']))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
Reducer
import sys
def reducer_func():
cur_word = None
cur_cnt = 0
for line in sys.stdin:
word, val = line.strip().split('\t')
if cur_word == None:
cur_word = word
if cur_word != word:
print('\t'.join([cur_word, str(cur_cnt)]))
cur_word = word
cur_cnt = 0
cur_cnt += int(val)
print('\t'.join([cur_word, str(cur_cnt)]))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
run.sh
HADOOP_CMD="/usr/local/src/hadoop_2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop_2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_PATH="/the_man_of_property.txt"
OUTPUT_PATH="/output_mr_file_broadcast"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func white_list" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=3" \
-jobconf "stream.non.zero.exit.is.failure=false" \
-file ./map.py \
-file ./red.py \
-file ./white_list
-cacheFile
Mapper
import sys
def get_white_list_word(white_list_file):
white_list_file = open(white_list_file, 'r')
white_list_word = set()
for word in white_list_file:
word = word.strip()
if word != '':
white_list_word.add(word)
return white_list_word
def mapper_func(white_list_file):
white_list_word = get_white_list_word(white_list_file)
for line in sys.stdin:
word_list = line.strip().split(' ')
for word in word_list:
word = word.strip()
if word != '' and word in white_list_word:
print('\t'.join([word, '1']))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
Reducer
import sys
def reducer_func():
cur_word = None
cur_cnt = 0
for line in sys.stdin:
word, val = line.strip().split('\t')
if cur_word == None:
cur_word = word
if cur_word != word:
print('\t'.join([cur_word, str(cur_cnt)]))
cur_word = word
cur_cnt = 0
cur_cnt += int(val)
print('\t'.join([cur_word, str(cur_cnt)]))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
run.sh
HADOOP_CMD="/usr/local/src/hadoop_2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop_2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_PATH="/the_man_of_property.txt"
OUTPUT_PATH="/output_mr_cachefile_broadcast"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func WL" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=2" \
-jobconf "mapred.job.name=mr_cachefile_broadcast" \
-jobconf "stream.non.zero.exit.is.failure=false" \
-cacheFile "hdfs://master:9000/white_list#WL" \
-file "./map.py" \
-file "./red.py"
-cacheArchive
Mapper
import os
import sys
def get_cachefile_list(white_list_dir):
cachefile_list = []
if os.path.isdir(white_list_dir):
for cachefile in os.listdir(white_list_dir):
cachefile = open(white_list_dir + '/' + cachefile)
cachefile_list.append(cachefile)
return cachefile_list
def get_white_list_word(white_list_dir):
white_list_word = set()
for cachefile in get_cachefile_list(white_list_dir):
for word in cachefile:
word = word.strip()
white_list_word.add(word)
return white_list_word
def mapper_func(white_list_dir):
white_list_word = get_white_list_word(white_list_dir)
for line in sys.stdin:
word_list = line.strip().split(' ')
for word in word_list:
word = word.strip()
if word != '' and word in white_list_word:
print('\t'.join([word, '1']))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
Reducer
import sys
def reducer_func():
cur_word = None
cur_cnt = 0
for line in sys.stdin:
word, val = line.strip().split('\t')
if cur_word == None:
cur_word = word
if cur_word != word:
print('\t'.join([cur_word, str(cur_cnt)]))
cur_word = word
cur_cnt = 0
cur_cnt += int(val)
print('\t'.join([cur_word, str(cur_cnt)]))
if __name__ == '__main__':
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
run.sh
HADOOP_CMD="/usr/local/src/hadoop_2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop_2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_PATH="/the_man_of_property.txt"
OUTPUT_PATH="/output_mr_cachearchive_broadcast"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func WLD" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=2" \
-jobconf "mapred.job.name=mr_cachearchive_broadcast" \
-jobconf "stream.non.zero.exit.is.failure=false" \
-cacheArchive "hdfs://master:9000/white_list_dir.tgz#WLD" \
-file "./map.py" \
-file "./red.py"
杀死MapReduce Job
hadoop job -kill job_1715841477049_0001
排序
- 按 k e y key key的字符进行排序
压缩文件
- 压缩文件不可切分,一个压缩文件占用一个 M a p Map Map
mr_ip_lib_python本地调试
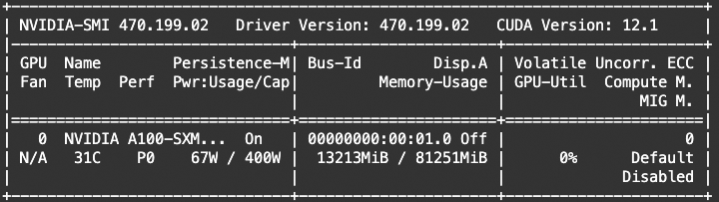
$ head -20 ip_lib.txt | column -t
$ cat ip_lib.txt | awk '{print $1,$NF}' | head | column -t







![[图解]SysML和EA建模住宅安全系统-07 to be块定义图](https://img-blog.csdnimg.cn/direct/d76adea83b95430885319376f57ed17b.png)