文章目录
- 1. 各模块解决
- 1.1 输入部分
- 1.2 多头注意力(作者使用8个头)
- 1.3 残差和LayerNorm
- 1.4 Decoder部分
- 2.Transformer经典问题
- 2.1 tranformer为何使用多头注意力机制?
- 2.2 Transformer相比CNN的优缺点
- 2.3 Encoder和decoder的区别?两者感受野是否一致?
Tranformer现如今无论是在CV还是NLP,甚至现在非常或的LLM领域都非常重要!该架构是谷歌在2017年《Attention is all you need》中提出的,下面将分析本人对各个模块的理解+算法面试中的常见问题。
1. 各模块解决
参考如下:
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
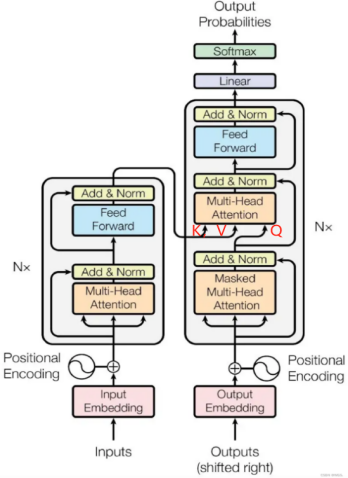
其基本架构如上如所示,图中的N在论文中等于6。
编码器与解码器之间的数据传递如下图所示:
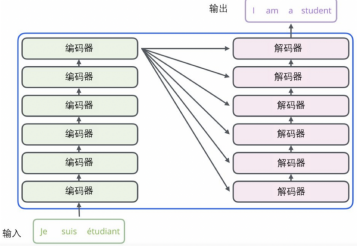
下面将详解各模块:
1.1 输入部分
(1)Embedding

一般是采用Embedding方式对输入进行编码,如上图所示,
即:使用特定维度来表达一个单词,如:
‘我’: 就使用一个512维度的向量来表示,
‘爱’: 也使用一个512维度的向量来表示;
(2)位置编码
详见本人博客:举例理解transformer中的位置编码
1)明白为什么要使用位置编码?
因为Transformer的多头注意力机制是并行化的,所有单词是可以一起处理的。(而不想RNN那种一次输入一个词,输入本身就带有时序关系, 注意RNN中的梯度消失:RNN的梯度是总的梯度和,它的梯度消失不是梯度变为0,而是因为它的梯度被近距离梯度主导,被远距离梯度忽略不计)
Transformer的并行化可以提高速度,但缺少了位置信息,所以需要位置编码!
2)编码过程
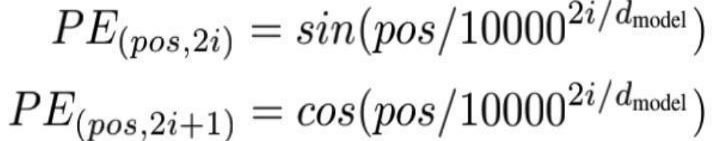
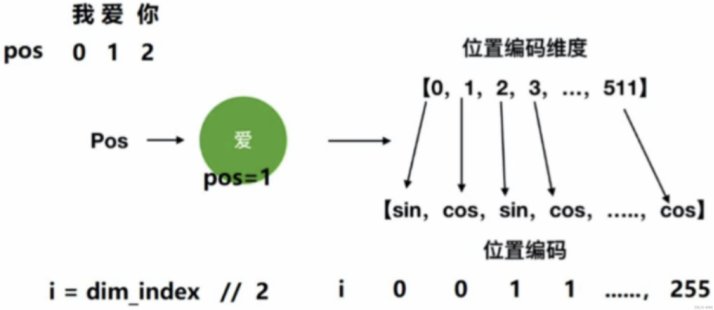
上式中,pos表示单词在句子中的位置,2i和2i+1要整体看,2i表示向量的偶数位置,2i+1表示向量的奇数位置。如图所示:
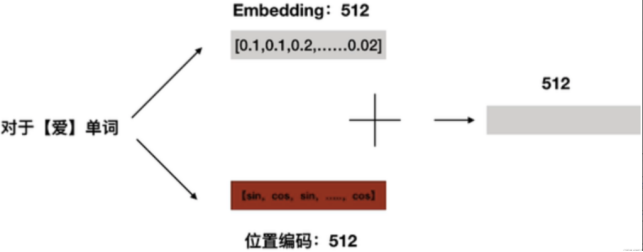
这样,每个单词都能有一个唯一的512维位置编码,然后将其和Embedding相加:
注:单个的位置只能表示绝对位置信息!然后由于三角函数的特性,他们之间还可以表现出相对位置信息,具体分析如下:
3)为什么位置嵌入是有用的?
因为借助三角函数的性质,可以表现出单词与单词之间的相对位置信息。

如上图所示,位置为:pos+k的单词可以分别用位置为pos和k的来计算出来,这样就表现出相对位置信息了。
4)为什么使用sin 和 cos?
1.sin cos 函数是无限延长的,适合单词序列的长短变化
2.sin cos 是具有周期性的,pos + k的单词可以分别用位置为pos和k的来计算出来
1.2 多头注意力(作者使用8个头)
以下是注意力机制的公式:
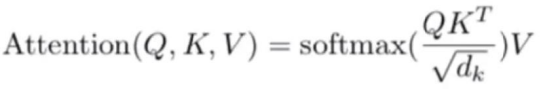 其中Q,K,V分别是有输入词向量和初始化生成的三个矩阵相乘得来的,dk表示词向量维度,如上面的512。计算过程如下所示:
其中Q,K,V分别是有输入词向量和初始化生成的三个矩阵相乘得来的,dk表示词向量维度,如上面的512。计算过程如下所示:
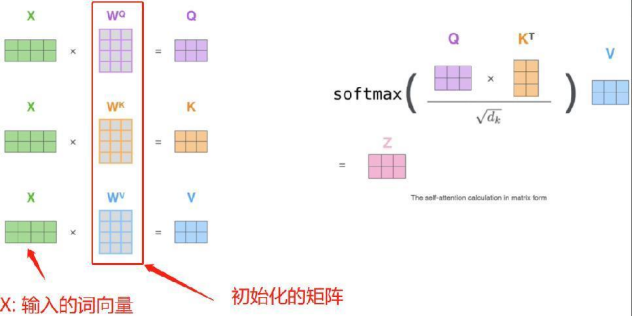
多头注意力机制,则表示使用多套不同的WQ,WK,WV去求注意力,如下图所示:
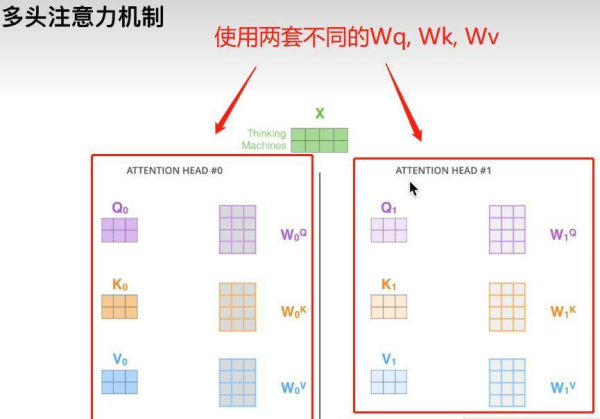
每个头最后经公式都会得出一个注意力Z矩阵,将其合起来,即可得到多头注意的输出。
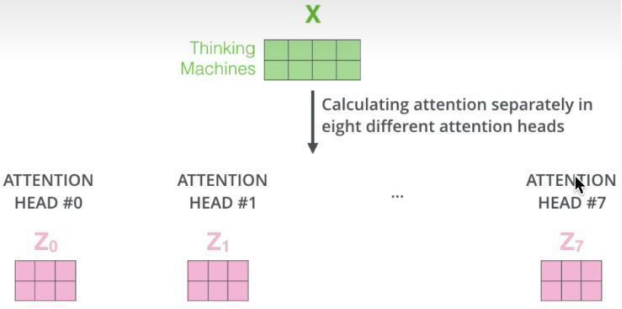
使用多头注意力机制的目的在于:将原始信息映射到不同空间,保证可以捕捉到更多信息。
(1)为什么要除以根号dk?
①控制梯度大小:除以根号d可以控制注意力分数的大小,防止梯度爆炸问题。在内积操作中,两个向量之间的相似度随着向量维度的增加而增大,这可能导致梯度变得非常大,外面有还有Softmax,如果某一点太大,softmax会让那一点更趋近于1,而其他点则更趋近于0,从而影响训练的稳定性。通过除以根号d,可以使注意力分数的范围相对稳定,从而减轻梯度爆炸的问题。
②平衡不同维度的注意力权重:在注意力机制中,注意力分数的大小会影响不同键的重要性。通过除以根号d,可以确保不同维度的注意力权重在计算时有更平衡的影响,避免某些维度过大而影响模型的性能。
(2)为什么除以的数值是根号下dk,而不是其他数值?
因为q和k是两个独立(而非相同)的随机变量, 假设两个输入向量 q 和 k 的每一维都具有零均值和单位方差、并且假设每一维都互相独立,那么这个除 sqrt(dk)的操作可以使得运算结果仍然保持零均值和单位方差,因而有利于模型训练的稳定性。
1.3 残差和LayerNorm
多头注意力后就会进行残差连接和LayerNorm,如下图所示:
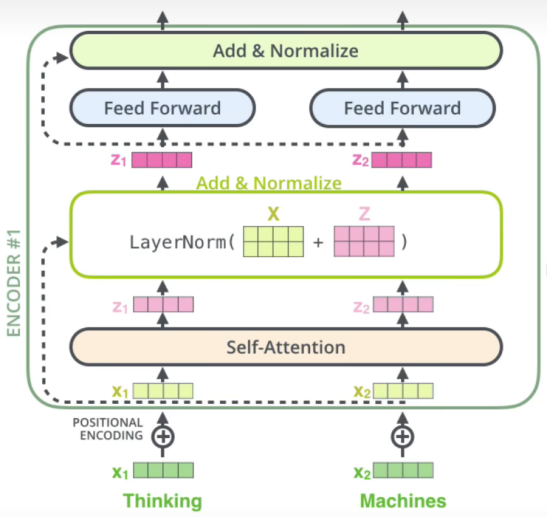
(1)残差连接为什么有用?
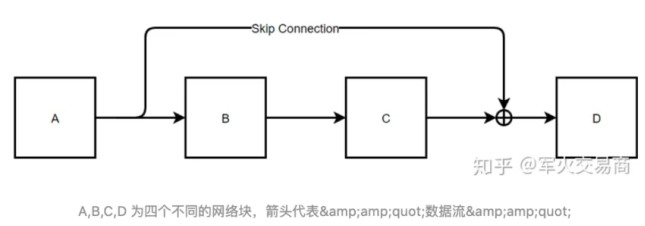
如上图,表示一个残差网络结构图,在进行反向传播时,有如下推导:
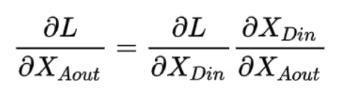
而有:
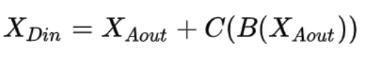
所以:
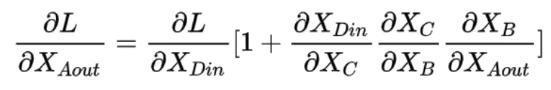
由式子可知,即使后面的连乘接近0,由于前面有个1,所以导数不会为0,这就是残差网络能很深的原因,因为残差网络缓解了梯度消失。
(2)BatchNorm的优缺点和使用场景
BatchNorm的计算可以参考:pytorch中对BatchNorm2d()函数的理解
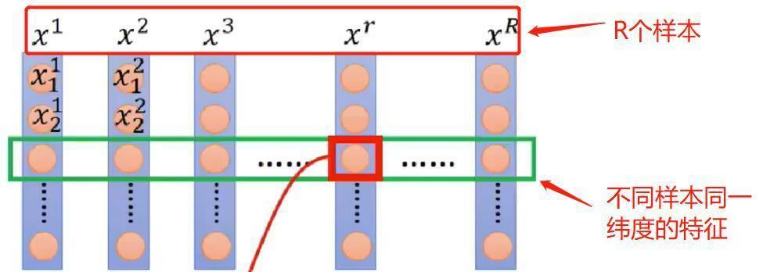
BN的理解重点在于它是针对整个Batch中的样本在同一维度特征做处理!!!如下图所示:
x
1
、
x
2
,
⋅
⋅
⋅
,
x
R
x^1、x^2,···,x^R
x1、x2,⋅⋅⋅,xR 表示R个样本,BatchNorm是作用在不同样本同一维度上的。
1)BN的优点
①解决内部协变量偏移
简单来说,在训练过程中,各样本之间可能分布不同,增大了学习难度,BN通过对各样本同一维度进行归一化缓解了这个问题。也有说,BN使损失平面更加更滑,从而加快收敛。
②缓解了梯度饱和问题,加快收敛。
2)BN的缺点
①batch_size较小时,效果较差
BN的过程,使用整个batch中样本的均值和方差来模拟全部数据的均值和方差,在batch_size 较小的时候,效果肯定不好。
②对文本这种输入维度不一致的不友好
如图所示:
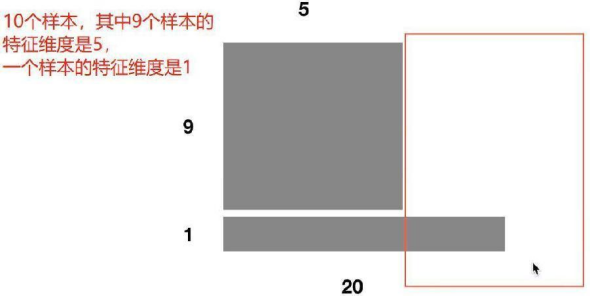
举个最简单的例子,比如 batch_size 为10,也就是我有10个样本,其中9个样本长度为5,第10个样本长度为20。
那么问题来了,前五个单词的均值和方差都可以在这个batch中求出来从而模型真实均值和方差。但是第6个单词到底20个单词怎么办?
只用这一个样本进行模型的话,不就是回到了第一点,batch太小,导致效果很差。
3)BN的使用场景
BN在MLP和CNN上使用的效果较好,在RNN这种动态文本模型上使用的比较差。
为啥BN在NLP中效果差:
BN的使用场景不适合RNN这种动态文本模型,有一个原因是因为batch中的长度不一致,导致有的靠后面的特征的均值和方差不能估算。
这个问题其实不是个大问题,可以缓解。我们可以在数据处理的时候,使句子长度相近的在一个batch,就可以了。所以这不是为啥NLP不用BN的核心原因。
BN在MLP中的应用,BN是对每个特征在batch_size上求的均值和方差。记住,是每个特征。比如说身高,比如说体重等等。这些特征都有明确的含义。
但是我们想象一下,如果BN应用到NLP任务中,对应的是对什么做处理?是对每一个单词!也就是说,我现在的每一个单词是对应到了MLP中的每一个特征。也就是默认了在同一个位置的单词对应的是同一种特征,比如:“我/爱/中国/共产党”和“今天/天气/真/不错”
如何使用BN,代表着认为 "我"和“今天”是对应的同一个维度特征,这样才可以去做BN。
大家想一下,这样做BN,会有效果吗?
不会有效果的,每个单词表达的特征是不一样的,所以按照位置对单词特征进行缩放,是违背直觉的。
(3)LayerNorm在Transformer中的应用
layner-norm 的特点是什么?layner-norm 做的是针对每一个样本,做特征的缩放。换句话讲,保留了N维度,在C/H/W维度上做缩放。
也就是,它认为“我/爱/中国/共产党”这四个词在同一个特征之下,所以基于此而做归一化。
这样做,和BN的区别在于,一句话中的每个单词都可以归到一个名字叫做“语义信息”的一个特征中(我自己瞎起的名字,大家懂就好),也就是说,layner-norm也是在对同一个特征下的元素做归一化,只不过这里不再是对应N(或者说batch size),而是对应的文本长度。
上面这个解释,有一个细节点,就是,为什么每个单词都可以归到“语义信息”这个特征中。大家这么想,如果让你表达一个句子的语义信息,你怎么做?
最简单的方法就是词语向量的加权求和来表示句子向量,这一点没问题吧。(当然你也可以自己基于自己的任务去训练语义向量,这里只是说最直觉的办法)。
1.4 Decoder部分
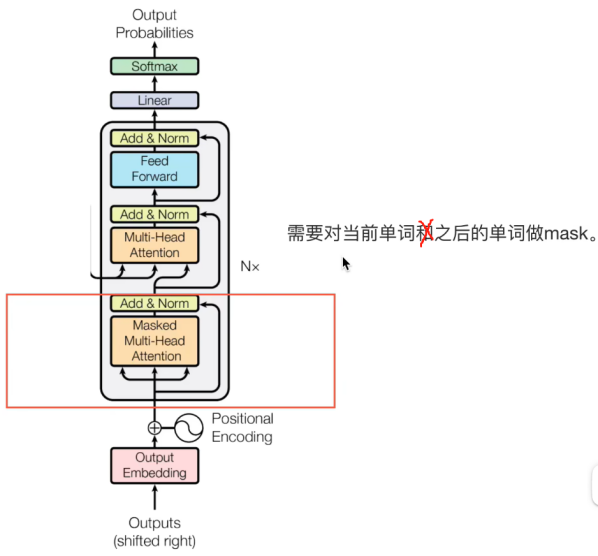
需要对当前时刻之后的信息进行musk,那么为什么需要mask呢?
(1)为什么需要mask?
需要提前知道的是:
在训练过程,Output(Shifted right) 表示的是GroundTruth;
在test过程,Output(Shifted right) 表示之前自己预测的序列。
这里探讨的是训练过程为什么需要Mask?
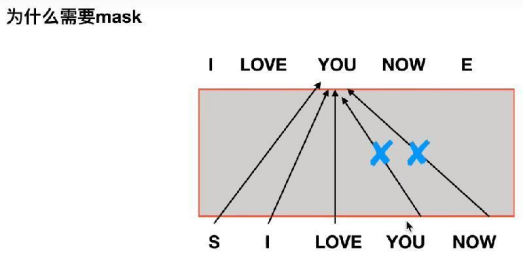
我的理解是,当我们的需要翻译是句子是:
“我现在爱你”,其Label为:“I LOVE YOU NOW”.
当前时刻是已经预测了“I LOVE”, 正在预测“YOU”。此时我们就需要把Label中的“YOU NOW”给mask掉。
其原因就是在推理时,是没有Label的,所以我们要训练和推理过程之间没有gap,才能得到较好的结果。
而mask就是将从代码角度讲,就是把当前时刻之后所有单词mask掉就好了。
(2)decoder部分(和Encoder交互的部分)的输入
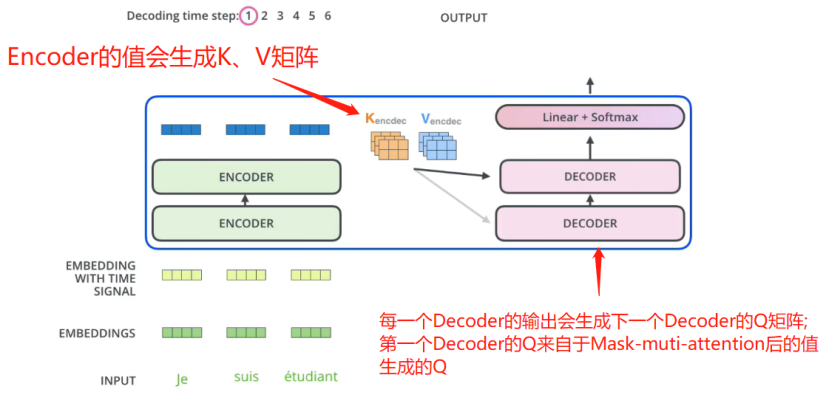
如上图所示,每个Encoder会接受Q,K,V矩阵,其中,K,V来自与Encoder,Q来自与上一个Decoder.
之后就没什么好讲了。但需要明白的是:
在训练过程,Output(Shifted right) 表示的是GroundTruth;
在test过程,Output(Shifted right) 表示之前自己预测的序列。
2.Transformer经典问题
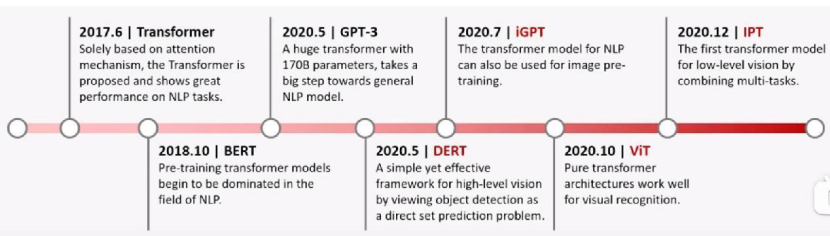
基于Transformer经典模型的发家史:
2.1 tranformer为何使用多头注意力机制?
(1)多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。
(2)每个并行计算注意力权重,提高计算效率(参数总量和总计算量没有减少)
(3)由于多头注意力机制能够从多个角度学习输入数据的特征,它有助于提高模型的泛化能力,使其能够更好地处理未见过的数据或任务。
(4)在自然语言处理中,句子中的词语往往与距离较远的其他词语存在依赖关系。多头注意力机制允许模型在不同的头中关注序列的不同部分,从而更有效地捕获这些长距离依赖。
2.2 Transformer相比CNN的优缺点

CNN感受野相对更小,所以需要搭建很多层CNN,才能注意到全局信息。而transformer的全局感受能力更强。
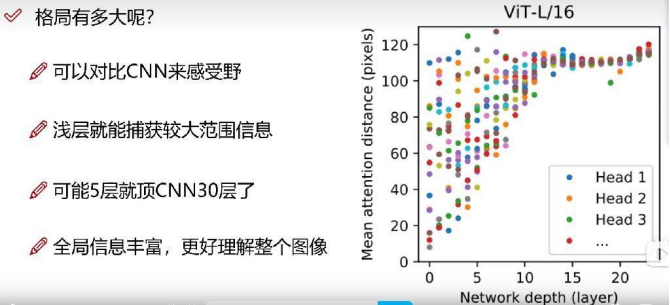
Transformer全局信息更加丰富,仅用几层就能达到很大的感受野。
2.3 Encoder和decoder的区别?两者感受野是否一致?
(1)Encoder只有一个Multi-Head Attention层,而Decoder有两个,且Decoder的第一个Multi-Head Attention采用了mash操作;
(2)decoder第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
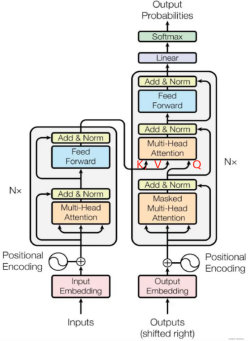
(3)功能性来说:encoder的功能是将输入序列编码成高维表示;而Decoder则将高维表示转化为目标序列,方便下游任务;
(4)感受野: Encoder的感受野是输入序列中某个位置的上下文信息;而Decoder同时关注输入序列和已生成的序列。
本文完结,撒花!
欢迎交流讨论!




![[保姆式教程]使用目标检测模型YOLO V5 OBB进行旋转目标的检测:训练自己的数据集(基于卫星和无人机的农业大棚数据集)](https://img-blog.csdnimg.cn/direct/a870017c22e64d27b9bd95e3c5abe108.jpeg)