文章目录
- 1. 内置模型层
- 1.1 基础层
- 1.2 卷积网络相关层
- 1.3 循环网络相关层
- 1.4 Transformer相关层
- 2. 自定义模型层
深度学习模型一般由各种模型层组合而成。
torch.nn中内置了非常丰富的各种模型层。它们都属于nn.Module的子类,具备参数管理功能。
注:这里的“具备参数管理功能”主要是指nn.Module及其子类能够
自动地处理与模型参数相关的各种操作,包括但不限于参数的注册、存储、梯度计算、优化、保存和加载等。)
例如:
- nn.Linear, nn.Flatten, nn.Dropout, nn.BatchNorm2d
- nn.Conv2d,nn.AvgPool2d,nn.Conv1d,nn.ConvTranspose2d
- nn.Embedding,nn.GRU,nn.LSTM
- nn.Transformer
如果这些内置模型层不能够满足需求时,我们也可以通过继承nn.Module基类构建自定义的模型层。
实际上,pytorch不区分模型和模型层,都是通过继承nn.Module进行构建。
因此,我们只要继承nn.Module基类并实现forward方法即可自定义模型层。(这句话非常重要!!!)
本章内容主要分为内置模型层和自定义模型层
1. 内置模型层
import numpy as np
import torch
from torch import nn
1.1 基础层
- nn.Linear:全连接层。参数个数 = 输入层特征数× 输出层特征数(weight)+ 输出层特征数(bias)
- nn.Flatten:压平层,用于将多维张量样本压成一维张量样本。
- nn.BatchNorm1d:一维批标准化层。通过线性变换将输入批次缩放平移到稳定的均值和标准差。可以增强模型对输入不同分布的适应性,加快模型训练速度,有轻微正则化效果。一般在激活函数之前使用。可以用afine参数设置该层是否含有可以训练的参数。
- nn.BatchNorm2d:二维批标准化层。
- nn.BatchNorm3d:三维批标准化层。
- nn.Dropout:一维随机丢弃层。一种正则化手段。
- nn.Dropout2d:二维随机丢弃层。
- nn.Dropout3d:三维随机丢弃层。
- nn.Threshold:限幅层。当输入大于或小于阈值范围时,截断之。
- nn.ConstantPad2d: 二维常数填充层。对二维张量样本填充常数扩展长度
- nn.ReplicationPad1d: 一维复制填充层。对一维张量样本通过复制边缘值填充扩展长度。
- nn.ZeroPad2d:二维零值填充层。对二维张量样本在边缘填充0值.
- nn.GroupNorm:组归一化。一种替代批归一化的方法,将通道分成若干组进行归一。不受batch大小限制,据称性能和效果都优于BatchNorm。
- nn.LayerNorm:层归一化。较少使用。
- nn.InstanceNorm2d: 样本归一化。较少使用。
各种归一化技术参考如下知乎文章《FAIR何恺明等人提出组归一化:替代批归一化,不受批量大小限制》,这里不做深究。
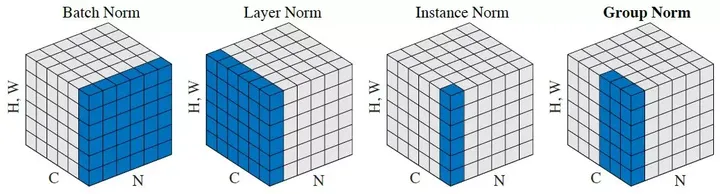 图 2:归一化方法。每个子图展示了一个特征图张量,N 是批坐标轴,C 是通道轴,(H,W)是空间轴。通过计算蓝色像素值的和,这些像素被同样的平均值与方差归一化的
图 2:归一化方法。每个子图展示了一个特征图张量,N 是批坐标轴,C 是通道轴,(H,W)是空间轴。通过计算蓝色像素值的和,这些像素被同样的平均值与方差归一化的
1.2 卷积网络相关层
- nn.Conv1d:普通一维卷积,常用于文本。参数个数 = 输入通道数×卷积核尺寸(如3)×卷积核个数 + 卷积核尺寸(如3)
- nn.Conv2d:普通二维卷积,常用于图像。参数个数 = 输入通道数×卷积核尺寸(如3乘3)×卷积核个数 + 卷积核尺寸(如3乘3) 通过调整dilation参数大于1,可以变成空洞卷积,增大卷积核感受野。 通过调整groups参数不为1,可以变成分组卷积。分组卷积中不同分组使用相同的卷积核,显著减少参数数量。 当groups参数等于通道数时,相当于tensorflow中的二维深度卷积层tf.keras.layers.DepthwiseConv2D。 利用分组卷积和1乘1卷积的组合操作,可以构造相当于Keras中的二维深度可分离卷积层tf.keras.layers.SeparableConv2D。
- nn.Conv3d:普通三维卷积,常用于视频。参数个数 = 输入通道数×卷积核尺寸(如3乘3乘3)×卷积核个数 + 卷积核尺寸(如3乘3乘3) 。
- nn.MaxPool1d: 一维最大池化。
- nn.MaxPool2d:二维最大池化。一种下采样方式。没有需要训练的参数。
- nn.MaxPool3d:三维最大池化。
- nn.AdaptiveMaxPool2d:二维自适应最大池化。无论输入图像的尺寸如何变化,输出的图像尺寸是固定的。 该函数的实现原理,大概是通过输入图像的尺寸和要得到的输出图像的尺寸来反向推算池化算子的padding,stride等参数。
- nn.FractionalMaxPool2d:二维分数最大池化。普通最大池化通常输入尺寸是输出的整数倍。而分数最大池化则可以不必是整数。分数最大池化使用了一些随机采样策略,有一定的正则效果,可以用它来代替普通最大池化和Dropout层。
- nn.AvgPool2d:二维平均池化。
- nn.AdaptiveAvgPool2d:二维自适应平均池化。无论输入的维度如何变化,输出的维度是固定的。
- nn.ConvTranspose2d:二维卷积转置层,俗称反卷积层。并非卷积的逆操作,但在卷积核相同的情况下,当其输入尺寸是卷积操作输出尺寸的情况下,卷积转置的输出尺寸恰好是卷积操作的输入尺寸。在语义分割中可用于上采样。
- nn.Upsample:上采样层,操作效果和池化相反。可以通过mode参数控制上采样策略为"nearest"最邻近策略或"linear"线性插值策略。
- nn.Unfold:滑动窗口提取层。其参数和卷积操作nn.Conv2d相同。实际上,卷积操作可以等价于nn.Unfold和nn.Linear以及nn.Fold的一个组合。 其中nn.Unfold操作可以从输入中提取各个滑动窗口的数值矩阵,并将其压平成一维。利用nn.Linear将nn.Unfold的输出和卷积核做乘法后,再使用 nn.Fold操作将结果转换成输出图片形状。
- nn.Fold:逆滑动窗口提取层。
1.3 循环网络相关层
-
nn.Embedding:嵌入层。一种比Onehot更加有效的对离散特征进行编码的方法。一般用于将输入中的单词映射为稠密向量。嵌入层的参数需要学习。
-
nn.LSTM:长短记忆循环网络层【支持多层】。最普遍使用的循环网络层。具有携带轨道,遗忘门,更新门,输出门。可以较为有效地缓解梯度消失问题,从而能够适用长期依赖问题。设置bidirectional = True时可以得到双向LSTM。需要注意的时,默认的输入和输出形状是(seq,batch,feature), 如果需要将batch维度放在第0维,则要设置batch_first参数设置为True。
-
nn.GRU:门控循环网络层【支持多层】。LSTM的低配版,不具有携带轨道,参数数量少于LSTM,训练速度更快。
-
nn.RNN:简单循环网络层【支持多层】。容易存在梯度消失,不能够适用长期依赖问题。一般较少使用。
-
nn.LSTMCell:长短记忆循环网络单元。和nn.LSTM在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。
-
nn.GRUCell:门控循环网络单元。和nn.GRU在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。
-
nn.RNNCell:简单循环网络单元。和nn.RNN在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用
1.4 Transformer相关层
-
nn.Transformer:Transformer网络结构。Transformer网络结构是替代循环网络的一种结构,解决了循环网络难以并行,难以捕捉长期依赖的缺陷。它是目前NLP任务的主流模型的主要构成部分。Transformer网络结构由TransformerEncoder编码器和TransformerDecoder解码器组成。编码器和解码器的核心是MultiheadAttention多头注意力层。
-
nn.TransformerEncoder:Transformer编码器结构。由多个 nn.TransformerEncoderLayer编码器层组成。
-
nn.TransformerDecoder:Transformer解码器结构。由多个 nn.TransformerDecoderLayer解码器层组成。
-
nn.TransformerEncoderLayer:Transformer的编码器层。
-
nn.TransformerDecoderLayer:Transformer的解码器层。
-
nn.MultiheadAttention:多头注意力层。
Transformer原理介绍可以参考如下知乎文章《详解Transformer(Attention Is All You Need)》

2. 自定义模型层
如果Pytorch的内置模型层不能够满足需求,我们也可以通过继承nn.Module基类构建自定义的模型层。
实际上,pytorch不区分模型和模型层,都是通过继承nn.Module进行构建。
因此,我们只要继承nn.Module基类并实现forward方法即可自定义模型层。
下面是Pytorch的nn.Linear层的源码,我们可以仿照它来自定义模型层。
import torch
from torch import nn
import torch.nn.functional as F
import math
class Linear(nn.Module):
__constants__ = ['in_features', 'out_features']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(self.bias, -bound, bound)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
def extra_repr(self):
return 'in_features={}, out_features={}, bias={}'.format(
self.in_features, self.out_features, self.bias is not None
)
linear = nn.Linear(20, 30)
inputs = torch.randn(128, 20)
output = linear(inputs)
print(output.size())
结果
torch.Size([128, 30])
代码注释:
这段代码定义了一个名为Linear的类,该类继承了PyTorch的nn.Module,表示一个线性层(全连接层)。逐行解释这段代码:
import torch
导入PyTorch库。
from torch import nn
从PyTorch库中导入nn模块,它包含了构建神经网络所需的各种层和模块。
import torch.nn.functional as F
导入PyTorch的nn.functional模块,并简写为F。这个模块包含了许多神经网络中常用的函数,如激活函数、卷积操作等。
import math
导入数学库
class Linear(nn.Module):
定义一个名为Linear的类,该类继承了nn.Module。
__constants__ = ['in_features', 'out_features']
类变量__constants__定义了该类的一些常量,这些常量表示输入特征和输出特征的数量。
def __init__(self, in_features, out_features, bias=True):
类的构造函数,接受输入特征数、输出特征数和一个表示是否有偏置项的布尔值。
super(Linear, self).__init__()
调用父类nn.Module的构造函数。
self.in_features = in_features
self.out_features = out_features
设置实例变量来表示输入和输出的特征数量。
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
创建一个表示权重的nn.Parameter对象。这是一个可以被优化的张量,形状为(out_features, in_features)。
if bias:
self.bias = nn.Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
如果bias参数为True,则创建一个表示偏置的nn.Parameter对象,否则在该模块中注册一个名为’bias’的参数,但其值为None。
self.reset_parameters()
调用reset_parameters方法来初始化权重和偏置。
接下来的reset_parameters方法是用来初始化权重和偏置的:
def reset_parameters(self):
定义权重和偏置的初始化方法。
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
使用Kaiming初始化方法来初始化权重。注意,这里使用了math.sqrt(5)作为a的值,这是He初始化的一个变种。
if self.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(self.bias, -bound, bound)
如果偏置不为None,则计算权重张量的扇入(fan-in)和扇出(fan-out),并使用这些值来初始化偏置。偏置被初始化为一个在[-bound, bound]范围内的均匀分布,其中bound是扇入值的平方根的倒数。
接下来的forward方法定义了该层的前向传播:
def forward(self, input):
定义前向传播方法,接受一个输入张量。
return F.linear(input, self.weight, self.bias)
使用F.linear函数来计算线性变换,并返回结果。
最后的extra_repr方法提供了一个额外的字符串表示,当打印该层的字符串表示时会很有用:
def extra_repr(self):
定义一个返回额外字符串表示的方法。
return 'in_features={}, out_features={}, bias={}'.format(
self.in_features, self.out_features, self.bias is not None)
返回一个格式化的字符串,其中包含输入特征数、输出特征数和是否有偏置的信息。
注意:虽然这个Linear类与PyTorch内置的nn.Linear非常相似,但在实际应用中,通常建议直接使用nn.Linear,因为它已经经过了优化和测试。这个自定义的Linear类主要用于教学和理解线性层的内部工作原理。