2024电工杯B题保姆级分析完整思路+代码+数据教学
B题题目:大学生平衡膳食食谱的优化设计及评价
接下来我们将按照题目总体分析-背景分析-各小问分析的形式来
总体分析:
题目要求对两份一日膳食食谱进行营养分析和调整,然后设计优化的平衡膳食食谱,并进行评价。具体步骤如下:
问题 1:膳食食谱的营养分析评价及调整
1.1 膳食营养评价
首先我们需要对附件1和附件2中的男、女大学生的膳食进行全面的营养评价。根据附件4的标准,评价内容包括能量、主要营养素含量(蛋白质、脂肪、碳水化合物等)、非产能营养素(钙、铁、锌、维生素等)及氨基酸评分等。
1.2 调整改进
基于附件3提供的食堂主要食物信息,对男、女大学生的膳食进行适当调整,使其更符合营养需求,然后再进行营养评价。
问题 2:基于附件3的日平衡膳食食谱的优化设计
2.1 目标一:蛋白质氨基酸评分最大化
建立优化模型,设计男、女大学生的日食谱,并进行膳食营养评价。
2.2 目标二:用餐费用最经济
建立优化模型,设计男、女大学生的日食谱,并进行膳食营养评价。
2.3 目标三:兼顾蛋白质氨基酸评分及经济性
建立综合优化模型,设计男、女大学生的日食谱,并进行膳食营养评价。
2.4 比较分析
对上述三种优化方案进行比较分析,找出最优方案。
问题 3:基于附件3的周平衡膳食食谱的优化设计
在问题2的基础上,分别以蛋白质氨基酸评分最大、用餐费用最经济、兼顾蛋白质氨基酸评分及经济性为目标,设计男、女大学生的周食谱,并进行评价及比较分析。
问题 4:健康饮食、平衡膳食的倡议书
基于以上分析和设计,针对大学生饮食结构及习惯,写一份健康饮食、平衡膳食的倡议书。
背景分析:
大学时代是学知识、长身体的重要阶段,这一时期的年轻人需要充足的能量和营养素来支持身体发育、脑力劳动和体育锻炼。然而,目前大学生饮食结构不合理、不良饮食习惯突出,如不吃早餐、经常食用外卖快餐等,导致营养不良或过度肥胖。解决这些问题对于大学生的生长发育和健康至关重要。
可以看到研究的对象是一名男大学生和一名女大学生,他们分别记录了一日三餐的食物摄入情况。并且还有某高校学生食堂提供的一日三餐主要食物信息。
数据文件包括3个数据集,在拆解后,我们的目标主要有以下几个:
-
营养分析和评价:
-
对男、女大学生的膳食进行全面的营养分析和评价。
-
基于高校食堂的食物信息,对膳食进行调整改进,并重新进行评价。
-
优化设计:
-
建立优化模型,设计男、女大学生的日食谱,目标分别为蛋白质氨基酸评分最大、用餐费用最经济、兼顾评分和经济性。
-
在日食谱基础上,设计周食谱,并进行评价和比较分析。
-
健康倡议书:
-
针对大学生的饮食结构及习惯,撰写一份健康饮食、平衡膳食的倡议书。
现在就先对数据集进行预处理分析,我们以附件1为例,做数据预处理和探索性数据分析(EDA)
数据读取和展示:
import pandas as pd
# 读取数据
male_diet = pd.read_excel('/mnt/data/附件1:1名男大学生的一日食谱.xlsx')
# 展示前10行数据
male_diet_head = male_diet.head(10)
male_diet_head
数据预处理
预处理步骤包括:
-
检查数据的完整性,处理缺失值。
-
转换数据类型,确保所有数据类型正确。
-
计算每种食物的总量及其对应的营养素含量。
代码:
# 检查数据的基本信息
male_diet.info()
# 检查数据的描述性统计
male_diet.describe()
# 检查是否有缺失值
missing_values = male_diet.isnull().sum()
missing_values
数据处理和计算
根据每种食物的量和其营养成分表,计算总的营养素含量。
假设数据表中包括以下列:食物名称、数量(g)、蛋白质含量(g/100g)、脂肪含量(g/100g)、碳水化合物含量(g/100g)等。
# 假设有以下列
# 食物名称、数量(g)、蛋白质含量(g/100g)、脂肪含量(g/100g)、碳水化合物含量(g/100g)
# 添加总蛋白质、总脂肪、总碳水化合物列
male_diet['总蛋白质 (g)'] = male_diet['数量 (g)'] * male_diet['蛋白质含量 (g/100g)'] / 100
male_diet['总脂肪 (g)'] = male_diet['数量 (g)'] * male_diet['脂肪含量 (g/100g)'] / 100
male_diet['总碳水化合物 (g)'] = male_diet['数量 (g)'] * male_diet['碳水化合物含量 (g/100g)'] / 100
# 计算总的营养素含量
total_protein = male_diet['总蛋白质 (g)'].sum()
total_fat = male_diet['总脂肪 (g)'].sum()
total_carbs = male_diet['总碳水化合物 (g)'].sum()
# 展示总营养素含量
total_nutrients = {
'总蛋白质 (g)': total_protein,
'总脂肪 (g)': total_fat,
'总碳水化合物 (g)': total_carbs
}
total_nutrients
探索性数据分析(EDA)
-
食物种类和数量分布:
-
统计不同类别食物的数量分布情况。
-
营养素分布:
-
分析蛋白质、脂肪、碳水化合物在整个食谱中的分布。
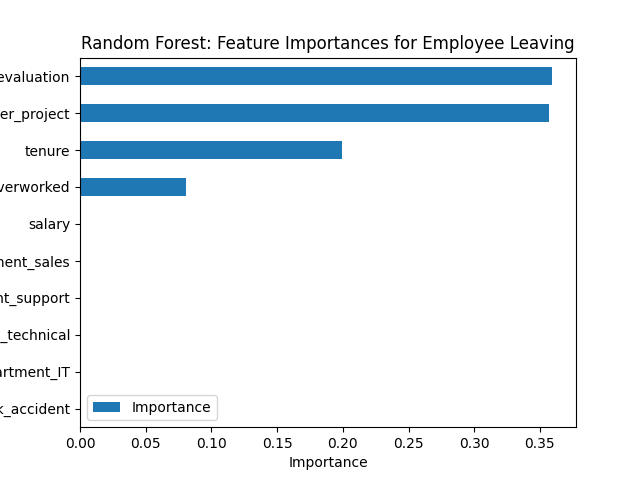
import matplotlib.pyplot as plt
# 食物种类和数量分布
food_types = male_diet['食物名称'].value_counts()
food_types.plot(kind='bar', title='食物种类分布')
plt.xlabel('食物名称')
plt.ylabel('数量')
plt.show()
# 营养素分布
nutrients = male_diet[['总蛋白质 (g)', '总脂肪 (g)', '总碳水化合物 (g)']]
nutrients.sum().plot(kind='bar', title='营养素分布')
plt.xlabel('营养素')
plt.ylabel('总量 (g)')
plt.show()
通过以上步骤,我们可以获得男大学生一日食谱的基本情况及其营养素分布,为后续的营养评价和优化设计打下基础。附件2类似方法可以做。下面来看问题1的分析过程
问题一分析:
针对问题一,它分为两个小问,包括对两份食谱做出全面的膳食营养评价,以及加上附件3后的调整。首先,先来解决第一小问。
膳食营养评价
我们需要对男大学生的一日膳食进行全面的营养分析评价,评价内容包括:
l 食物结构分析:检查食物种类是否齐全,是否多样化。
l 能量和主要营养素计算:计算总能量及蛋白质、脂肪、碳水化合物的摄入量。
l 非产能营养素计算:计算钙、铁、锌、维生素A、维生素B1、维生素B2、维生素C的摄入量。
l 营养素供能比分析:评价蛋白质、脂肪、碳水化合物的供能占比。
l 氨基酸评分分析:计算食谱中蛋白质的氨基酸评分。
数据预处理
首先读取数据,并检查数据的完整性和类型:
Python代码:
import pandas as pd
# 读取数据
male_diet = pd.read_excel('/mnt/data/附件1:1名男大学生的一日食谱.xlsx')
# 展示前10行数据
male_diet_head = male_diet.head(10)
print(male_diet_head)
# 检查数据的基本信息
male_diet.info()
# 检查数据的描述性统计
male_diet.describe()
# 检查是否有缺失值
missing_values = male_diet.isnull().sum()
print(missing_values)
食物结构分析
根据《中国居民膳食指南》的要求,检查食物种类是否多样化:
python
# 统计食物种类
food_types = male_diet['食物名称'].nunique()
print(f"食物种类数量: {food_types}")
# 分析食物类别是否齐全
food_categories = ['谷类', '蔬菜', '水果', '肉类', '奶类', '豆类', '油脂']
food_categories_count = male_diet['类别'].value_counts()
print(food_categories_count)
下面给大家如何用灰色综合评价法来做的示例,推荐大家使用此算法:
灰色综合评价法步骤
-
确定评价指标体系:
-
选择评价膳食营养的关键指标,如总能量、蛋白质、脂肪、碳水化合物、钙、铁、锌、维生素A、维生素B1、维生素B2、维生素C等。
-
数据标准化:
-
对各指标数据进行无量纲化处理(标准化),以消除不同指标间量纲的影响。
-
计算灰关联度:
-
计算每个评价对象(食谱)与理想参考值之间的灰色关联度。
-
计算综合关联度:
-
根据各指标的权重,计算各评价对象的综合关联度。
-
综合评价:
-
根据综合关联度对各评价对象进行排序,得出综合评价结果。
实现步骤 1. 确定评价指标体系 选择男大学生膳食的关键评价指标如下:
-
总能量 (kcal)
-
总蛋白质 (g)
-
总脂肪 (g)
-
总碳水化合物 (g)
-
钙 (mg)
-
铁 (mg)
-
锌 (mg)
-
维生素A (μg)
-
维生素B1 (mg)
-
维生素B2 (mg)
-
维生素C (mg)
2. 数据标准化 标准化处理可以采用极差标准化方法:

添加图片注释,不超过 140 字(可选)
假设数据已经在前面的步骤中计算完成,以下代码将实现数据标准化:
python
复制代码
import numpy as np
# 假设 total_nutrients 和 total_non_energy_nutrients 是已计算的营养素总量
data = {
'总能量 (kcal)': total_energy,
'总蛋白质 (g)': total_protein,
'总脂肪 (g)': total_fat,
'总碳水化合物 (g)': total_carbs,
'钙 (mg)': total_calcium,
'铁 (mg)': total_iron,
'锌 (mg)': total_zinc,
'维生素A (μg)': total_vitamin_a,
'维生素B1 (mg)': total_vitamin_b1,
'维生素B2 (mg)': total_vitamin_b2,
'维生素C (mg)': total_vitamin_c
}
# 转换为DataFrame
df = pd.DataFrame([data])
# 定义理想参考值,可以参考膳食指南的推荐摄入量
ideal_values = {
'总能量 (kcal)': 2400,
'总蛋白质 (g)': 90,
'总脂肪 (g)': 80,
'总碳水化合物 (g)': 300,
'钙 (mg)': 800,
'铁 (mg)': 12,
'锌 (mg)': 12.5,
'维生素A (μg)': 800,
'维生素B1 (mg)': 1.4,
'维生素B2 (mg)': 1.4,
'维生素C (mg)': 100
}
# 标准化处理
df_normalized = (df - df.min()) / (df.max() - df.min())
ideal_normalized = (pd.DataFrame([ideal_values]) - df.min()) / (df.max() - df.min())
print(df_normalized)
print(ideal_normalized)
然后需要计算灰色关联度:

添加图片注释,不超过 140 字(可选)
代码:
# 定义分辨系数
rho = 0.5
# 计算差异
diff = np.abs(df_normalized - ideal_normalized)
delta_min = diff.min().min()
delta_max = diff.max().max()
# 计算灰关联度
gray_relation = (delta_min + rho * delta_max) / (diff + rho * delta_max)
gray_relation_scores = gray_relation.mean(axis=1)
print(gray_relation_scores)
4. 计算综合关联度
综合关联度可以根据各指标的权重进行计算,这里假设所有指标权重相等:
# 假设所有指标权重相等
weights = np.ones(len(data.keys())) / len(data.keys())
# 计算综合关联度
comprehensive_relation_score = (gray_relation * weights).sum(axis=1)
print(comprehensive_relation_score)
5. 综合评价
根据综合关联度对膳食进行排序,得出综合评价结果:‘
# 综合评价
evaluation_result = comprehensive_relation_score.sort_values(ascending=False)
print(evaluation_result)
下面就是第一问的第二小问分析过程:
根据第一小问的营养评价结果,确定哪些营养素不足或过剩,具体包括:
-
总能量:是否满足推荐的每日能量摄入标准。
-
宏量营养素:蛋白质、脂肪、碳水化合物的供能占比是否合理。
-
非产能营养素:钙、铁、锌、维生素A、维生素B1、维生素B2、维生素C的摄入量是否达标。
-
氨基酸评分:蛋白质的氨基酸组成是否合理。
然后调整方案,可以通过以下方式进行调整:
-
增加或减少食物种类:
-
增加:对于不足的营养素,通过增加相应食物种类来补充。例如,钙不足可以增加奶制品,维生素C不足可以增加水果。
-
减少:对于过剩的营养素,通过减少相应食物种类来控制。例如,脂肪过多可以减少油脂和高脂食物的摄入。
-
优化食物搭配:
-
多样化:确保每天摄入的食物种类大于12种,每周摄入的食物种类大于25种,覆盖五大类食物(谷类、蔬菜、水果、肉类、奶类、豆类、油脂)。
-
合理搭配:合理搭配不同种类的食物,以提高膳食的整体营养价值。例如,谷类和豆类搭配可以提高蛋白质的氨基酸评分。
-
调整餐次比:
-
能量分配:合理分配早餐、中餐和晚餐的能量摄入,推荐早餐占30%,中餐和晚餐各占35%。
具体可以用以下方式进行调整:
-
总能量调整:
-
如果总能量不足:增加能量密集型食物,如全谷类、坚果、油脂等。
-
如果总能量过多:减少高能量食物的摄入,增加低能量密度的蔬菜和水果。
-
宏量营养素调整:
-
蛋白质不足:增加富含蛋白质的食物,如鱼类、禽肉、豆制品。
-
脂肪过多:减少油炸食品、肥肉,增加鱼类、坚果等优质脂肪来源。
-
碳水化合物不足:增加全谷类食品,如燕麦、糙米。
-
非产能营养素调整:
-
钙不足:增加奶制品、豆制品、绿叶蔬菜。
-
铁不足:增加红肉、肝脏、深色绿叶蔬菜,搭配维生素C丰富的食物以促进铁吸收。
-
锌不足:增加海产品、肉类、坚果。
-
维生素不足:增加水果、蔬菜,特别是富含维生素A、B、C的食物。
最后,通过调整食谱,重新进行膳食营养评价,确认各项营养素是否达到推荐摄入量,能量供给是否合理,氨基酸评分是否提高。
2-4问后续更新

添加图片注释,不超过 140 字(可选)

其中更详细的思路、各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方名片获取哦!