一、背景
在涉及全国地址的应用中,地址信息通常被频繁地查询和使用,例如电商平台、物流系统等。为了提高系统性能和减少对数据库的访问压力,可以使用缓存来存储常用的地址信息,其中 Redis 是一个非常流行的选择。
本次在一个企业入驻场场景中,需要选择企业服务区域,用户经常需要查询和使用全国省市地址信息(如下所示)。
如果每次查询都直接访问数据库,会增加数据库的负载,尤其是在高并发情况下。相较于其他数据,地址信息相对稳定,通常不会频繁变动。通过缓存常用的地址信息,可以加快查询速度,提高系统性能。

二、设计
数据库:字段及数据如下(需要sql文件,可私信联系)

Redis:使用List数据类型,把每条地址对象转换为json格式,存到Redis。
避免数据库更新,而缓存是老数据,导致数据不一致。设置过期时间7天,超过7天删除缓存,查询最新库中数据

三、代码
controller

@RestController
@RequestMapping("/pre_cook/client/address")
public class AddressClientController {
@Resource
private AddressClientService addressClientService;
/**
* 全国地址查询
*
* @return
*/
@PostMapping("/list")
public List<AddressVO> addressList() {
return addressClientService.addressList();
}
}
impl实现类

@Override
public List<AddressVO> addressList() {
String addressKey = AddressEnum.Address_PREFIX.getValue();
Boolean exist = redisUtil.hasKey(addressKey);
//1.如果缓存有数据,取缓存数据
if (exist) {
List<String> jsonList = redisUtil.lRange(addressKey, 0, -1);
log.info("缓存查询地址信息-json格式:{}", jsonList);
List<AddressVO> addressVOS = jsonList.stream()
.map(json -> JSON.parseObject(json, AddressVO.class))
.collect(Collectors.toList());
return addressVOS;
}
//2.缓存无数据,查询数据库
List<AddressInfoDO> infoDOList = addressInfoService.lambdaQuery()
.in(AddressInfoDO::getLevel, CompanyConstant.COUNTRY_LEVEL, CompanyConstant.PROVINCE_LEVEL, CompanyConstant.CITY_LEVEL, CompanyConstant.DISTRICT_LEVEL)
.eq(AddressInfoDO::getStatus, CompanyConstant.ADDRESS_ENABLED)
.eq(AddressInfoDO::getEnableFlag, EnableFlagEnum.ENABLE.getCode())
.list();
List<AddressVO> addressVOS = infoDOList.stream().
map(e -> AddressVO.builder()
.id(e.getId())
.addressCode(e.getCode())
.addressName(e.getName())
.level(e.getLevel())
.parentCode(e.getParentCode())
.key(PinYinUtils.getStringFirstName(e.getName()))
.build()
).collect(Collectors.toList());
List<AddressVO> voList = addressVOS.stream()
.sorted(Comparator
.comparingInt(AddressVO::getLevel)
.thenComparing(AddressVO::getKey, (s1, s2) -> s1.compareToIgnoreCase(s2)))
.collect(Collectors.toList());
//2.2存入缓存
List<String> jsonList = voList.stream()
.map(AddressVO -> JSON.toJSONString(AddressVO))
.collect(Collectors.toList());
redisUtil.lRightPushAll(addressKey, jsonList);
redisUtil.expire(addressKey, DigitalConstant.SEVEN, TimeUnit.DAYS);
return voList;
}
RedisUtil工具类方法
/**
* 获取列表指定范围内的元素
*
* @param key key
* @param start 开始位置, 0是开始位置
* @param end 结束位置, -1返回所有
* @return
*/
public List<String> lRange(String key, long start, long end) {
return redisTemplate.opsForList().range(key, start, end);
}
/**
* @param key key
* @param value val
* @return
*/
public Long lRightPushAll(String key, Collection<String> value) {
return redisTemplate.opsForList().rightPushAll(key, value);
}
/**
* 设置过期时间
*
* @param key key
* @param timeout
* @param unit
* @return
*/
public Boolean expire(String key, long timeout, TimeUnit unit) {
return redisTemplate.expire(key, timeout, unit);
}
四、测试
第一次,查数据库,耗时4秒多

第二次,通过第一次查询,redis已存有数据,只需要200多毫秒

第三次,耗时200多毫秒

第四次,删除缓存,再次查库,耗时700多毫秒
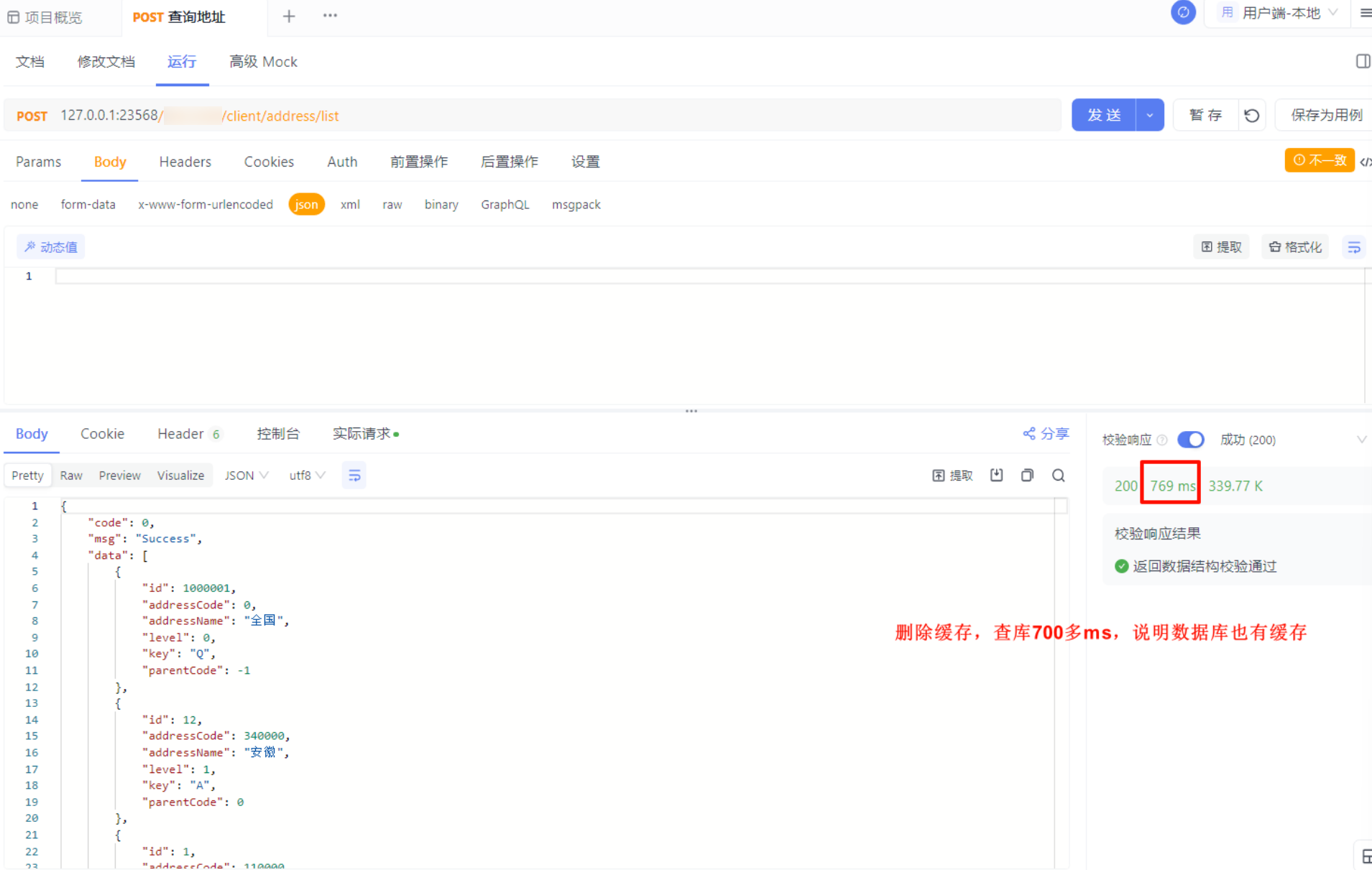
通过上述测试,第一次查询Mysql数据库,耗时4秒多,后续查询耗时700多毫秒,说明MySQL 也有自身的缓存机制,其中包括查询缓存。
由于查询缓存的存在,第一次执行某个查询时可能会比较慢,因为需要执行实际的查询操作并将结果存入缓存中。但是,当相同的查询再次执行时,如果查询的条件和数据没有发生变化,就可以直接从查询缓存中获取结果,因此查询时间会明显减少。
这里使用Redis缓存,在首次从Mysql查询后,存入Redis。通过Redis查询,耗时只需200多毫秒,明显少于Mysql耗时,减轻了数据库压力,也可以支持更高的并发。