课程总目录
文章目录
- 一、进程的虚拟地址空间内存划分和布局
- 二、函数的调用堆栈详细过程
- 三、程序编译链接原理
- 1. 编译过程
- 2. 链接过程
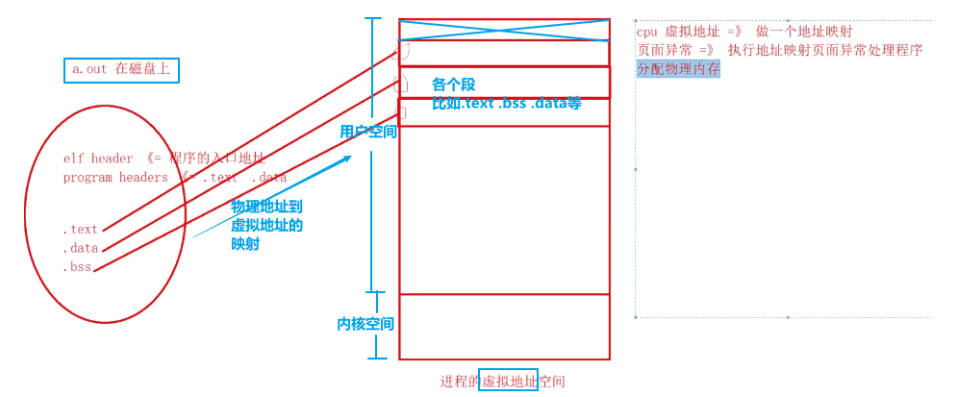
一、进程的虚拟地址空间内存划分和布局
任何的编程语言 → \to → 产生两种东西:指令和数据
编译链接完成之后会产生一个可执行文件xxx.exe,会把程序从磁盘加载到内存中,不可能直接加载到物理内存!!!
环境: x86 32位linux环境
程序:
int gdata1 = 10;
int gdata2 = 0;
int gdata3;
static int gdata4 = 11;
static int gdata5 = 0;
static int gdata6;
int main()
{
int a = 12;
int b = 0;
int c;
static int e = 13;
static int f = 0;
static int g;
return 0;
}
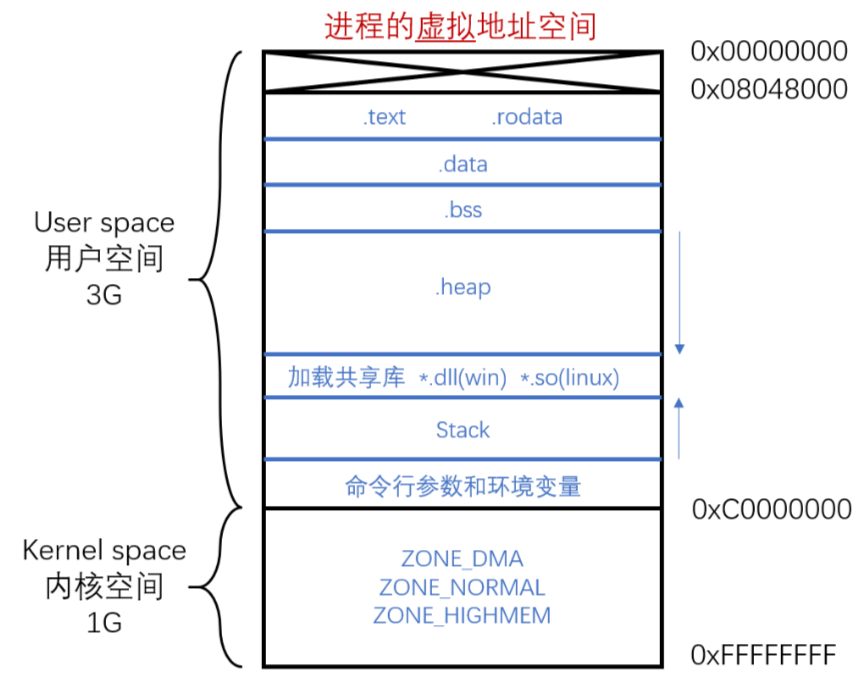
linux系统会给当前进程分配一个 232(4G)大小的一块空间(进程的虚拟地址空间),大小和环境的位数相关,如果是64位,则为8G
注意区分虚拟内存和虚拟地址空间,这是两个不同的概念
-
0x00000000 ~ 0x08048000
这段无法被访问,如果运行char *p = nullptr;strlen(p);则会报错,因为空指针在这段区域,char *src = nullptr;strcpy(dest, src);也会报错 -
0x08048000 ~ 0xC0000000
- .text(代码段): 放指令(只读)。main函数中的三个初始化 a, b, c 语句,都会转化为一条mov指令,如
mov dword ptr[a], 0xCH,如果cout << c,此时的c是什么不确定(参考文章),它是栈上的无效值;int main(){}以及cout << c << g << endl;都是指令,都存放在 .text中
int a = 12;这条语句不产生符号,只产生对应的汇编指令,对应指令存放在 .text上,但是当指令运行的时候,指令做的是在栈上开辟4字节的空间将12放进去- .rodata: 只读数据read only。
char *p = "hello world";其中p在栈上,常量字符串"hello world"就存储在 .rodata段,但是如果*p = 'a';,通过指针让常量字符串的第一个字符修改为a,可以编译但不能运行,因为这一部分是只读的 - .data(数据段): 用于存储已经初始化并且不为0的全局变量和静态变量,这些变量在程序运行之初就有了确定的初始值,在程序执行之前就会被初始化,因此需要分配实际的存储空间。
[gdata1 & gdata4 & e] - .bss: 用于存储未初始化和已经初始化为0的全局变量和静态变量。
[gdata2 & gdata3 & gdata5 & gdata6 & f & g]
此时
cout << gdata3 << endl;输出为0,因为gdata3存放在 .bss段。操作系统会把没初始化的变量全部置为0- .heap:堆
- 加载共享库:在window系统中是
*.dll,在linux中是*.so - stack:栈,函数运行或产生线程时,产生的栈空间,从下往上(高地址向地地址)进行增长
- 命令行参数和环境变量
- .text(代码段): 放指令(只读)。main函数中的三个初始化 a, b, c 语句,都会转化为一条mov指令,如
在 Linux 中,进程在内存中一般会分为五个段,包含了从磁盘载入的程序代码以及其他数据。即代码段、数据段、BSS段、堆、栈
- 0xC0000000 ~ 0xFFFFFFFF
- 内核空间
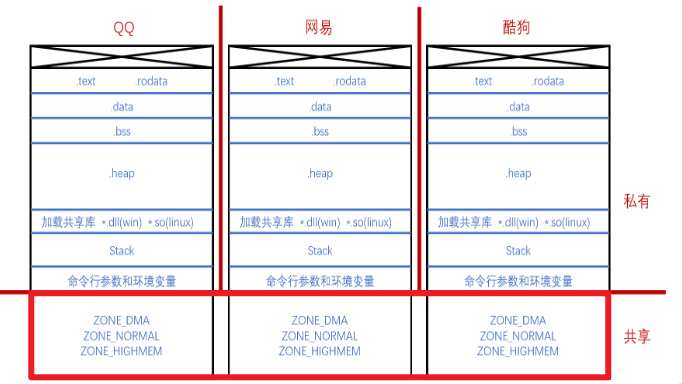
每一个进程的用户空间是私有的,但是内核空间是共享的。例如匿名管道通信,就是在内核空间中分配出一部分内存,进程1往里写内容,进程2和3都能看见。
二、函数的调用堆栈详细过程
int sum(int a, int b)
{
int temp = 0;
temp = a + b;
return temp;
}
int main()
{
int a = 10;
int b = 20;
int ret = sum(a, b);
cout << "ret:" << ret <<endl;
return 0;
}
问题一:main函数调用sum,sum执行完后,怎么知道回到哪个函数
问题二:sum函数执行完,回到main函数后,怎么知道从哪一行指令继续运行
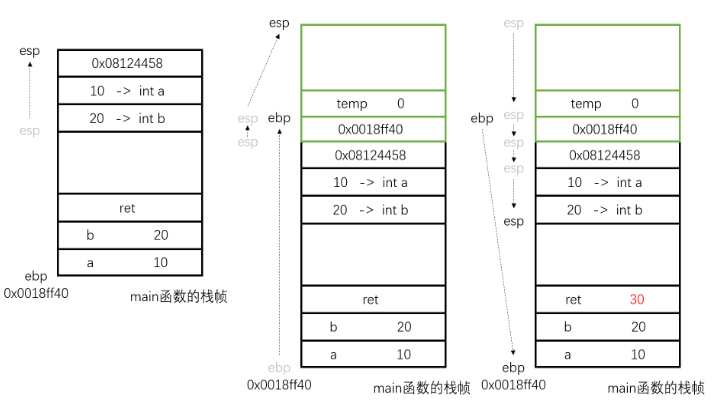
程序分析:
int a = 10;
→
\to
→ mov dword ptr[ebp-04H], 0AH
int b = 20;
→
\to
→ mov dword ptr[ebp-08H], 14H
int ret = sum(a, b);编译后会将位置为ptr[ebp-0Ch]命名为ret,之后是调用函数,先从右向左向栈顶压入形式参数a和b,同时esp也会随之移到栈顶,即
mov eax, dword ptr[ebp-08H]
push eax
mov eax, dword ptr[ebp-04H]
push eax
call sum // 函数调用指令,会做两件事,将下一条命令的地址(0x08124458)压栈,进入sum
// sum函数返回后
add esp, 8 // 本条指令地址(假如地址为0x08124458)将给形参分配的地址交还给系统
mov dword ptr[ebp-0CH], eax // 将结果放到ret中
由此也可见,在函数调用过程中,形参的内存开辟是在调用函数时就分配好的
进入sum函数,在int temp = 0;执行之前,即左括号{和int temp = 0;之间,会执行下面的汇编代码
push ebp // 此时ebp指向main函数栈帧的栈底,把此地址记录下来
mov ebp, esp // 把esp赋给ebp,此时ebp指向sum函数栈帧的栈底
sub esp, 4CH // 给sum函数开辟栈帧空间
int temp = 0;
→
\to
→ mov dword ptr[ebp-04H], 0
temp = a + b;
mov eax, dword ptr[ebp+0CH] // 取形参b的值存到eax
add eax, dword ptr[ebp+08H] // 取形参a的值,和b相加,存到eax
mov dword ptr[ebp-04H], eax // a+b结果存到temp
return temp;
→
\to
→ mov eax, dword ptr[ebp-04H]
右括号},回退栈帧
mov esp, ebp // 把ebp赋给esp,把栈空间归还给系统,但并未清空栈中内容
pop ebp // 出栈,并把栈里的数值给ebp,即退回main函数栈帧的栈底,同时esp+4
ret // 出栈,把出栈内容(0x08124458)放在CPU的PC寄存器中,同时esp+4
返回main函数中
// sum函数返回后
add esp, 8 // 本条指令地址(假如地址为0x08124458)将给形参分配的地址交还给系统
mov dword ptr[ebp-0CH], eax // 将结果放到ret中
之后再打印,return,结束程序
注:
数值 ≤ 4B,通过eax寄存器带出
4B < 数值 <= 8B,通过eax和edx两个寄存器带出
数值 > 8B,函数调用之前产生临时量,再把临时量地址入栈,被调用函数return处通过偏移ebp访问临时量。
三、程序编译链接原理
编译过程: 预编译 → \to → 编译 → \to → 汇编 → \to → 二进制可重定位的目标文件(*.obj / *.o)
链接过程: 编译完成的所有.o文件 + 静态库文件(Linux下是*.a,Windows下是*.lib)
两个核心步骤:(1)所有.o文件段的合并;符号表合并后,进行符号解析
(2)符号的重定位(重定向)【链接的核心】
最终在工程目录下
→
\to
→ win下得到xxx.exe,Linux下得到a.out
我们需要关注的点:
*.o文件的格式组成是什么样子的?- 可执行文件的组成格式是什么样子的?
- 链接的两步做的是什么事情?
- 符号表的输出 → \to → 符号,符号怎么理解?
- 符号什么时候分配虚拟地址(在用户空间上)?
程序:
main.cpp:
//引用sum.cpp文件里面定义的全局变量以及函数
extern int gdata;
int sum(int, int);
int data = 20;
int main()
{
int a = gdata;
int b = data;
int ret = sum(a, b);
return 0;
}
sum.cpp:
int gdata = 10;
int sum(int a, int b)
{
return a+b;
}
1. 编译过程
| C++文件 | 预编译 | 编译 | 汇编 | 二进制可重定位的目标文件(*.obj / *.o) |
|---|---|---|---|---|
| main.cpp sum.cpp | 处理#开头的命令 | 语法分析、语义分析、词法分析、代码优化 用 g++ -O 0/1/2/3 指定优化等级 | 编译完成之后生成特定架构下的汇编代码 | main.o sum.o |
预编译阶段:#pragma lib 和 #pragma link 例外,不是在预编译阶段完成的,而是在链接阶段完成的,这俩是用于处理链接阶段的外部库文件
现在来看我们的程序
首先进行编译g++ -c xxx.cpp
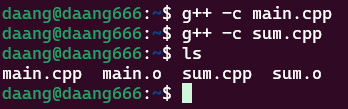
符号表:汇编器在把汇编码转成最终的.o文件时就会生成一个符号表
看一下符号表objdump -t xxx.o
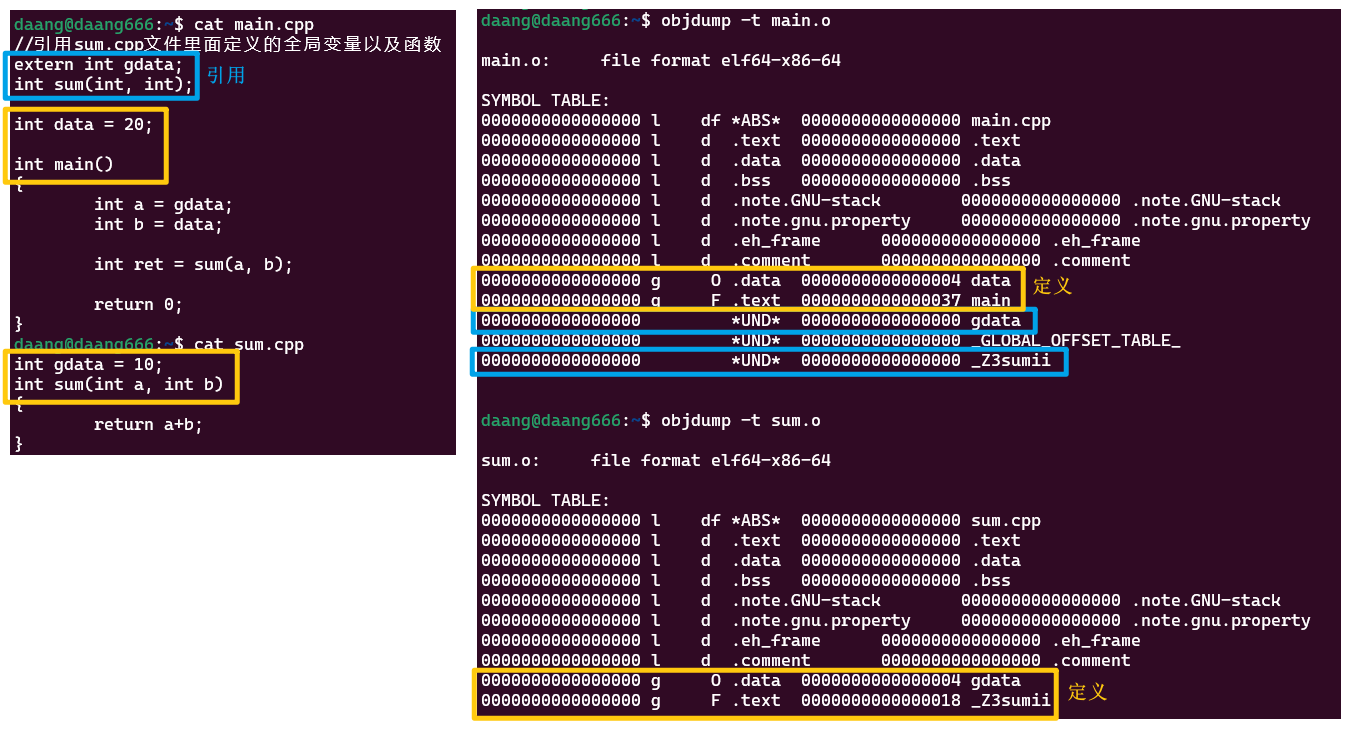
可以看到左边全为0,即编译过程中符号不分配虚拟地址,在链接过程中分配虚拟地址
分析:

如果引用了外部文件,也会将外部文件中的符号产生在自己的符号表中。如果定义了main函数,则在符号表中函数的符号就是函数名,放在.text(代码段);定义了全局变量data且值为20不等于0,因此放在.data(数据段);引用的gdata也产生了符号gdata,sum也产生了符号_z3sumii,但他们都是*UND*,这是符号的引用,而不是符号的定义。
在sum.o文件的符号表中中,需要由函数名字和形参列表一起产生符号,例如这里的sumii解释为sum_int_int
符号表的第二列,l表示local,local的符号只能在当前文件中看见;g表示global,global的符号在其他文件也看得见。因此在链接时,所有.obj文件在一起链接,链接器可以看见所有global的符号,但看不见local符号。
.o文件的组成,可以用readelf -S main.o打印段表,用readelf -h main.o打印文件头(节头部表):

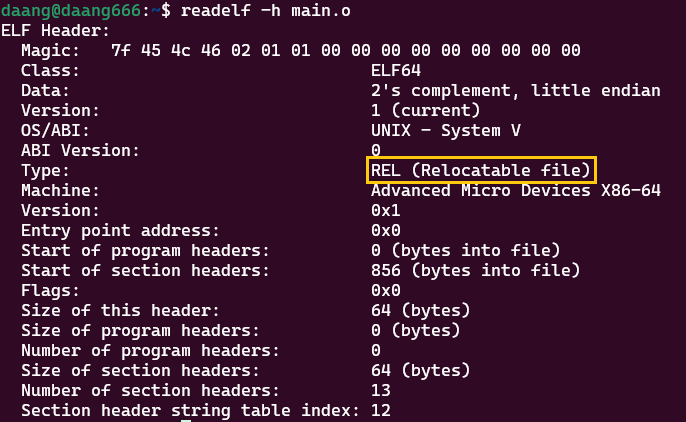
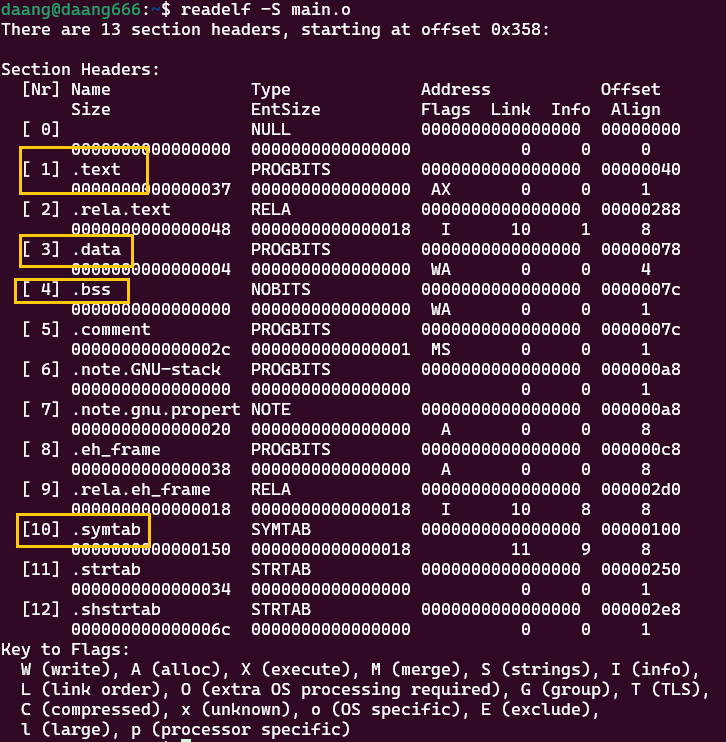
回答问题1:*.o 文件的格式组成是什么样子的?
答:由上图可见,是由各种段组成的(elf文件头.text.data.bss.symtab等等)
编译完成后,.o文件代码段放入的指令如下,此时符号的地址位置填充的是0,这也是.o文件无法运行的原因之一,可以用objdump -S main.o打印代码段
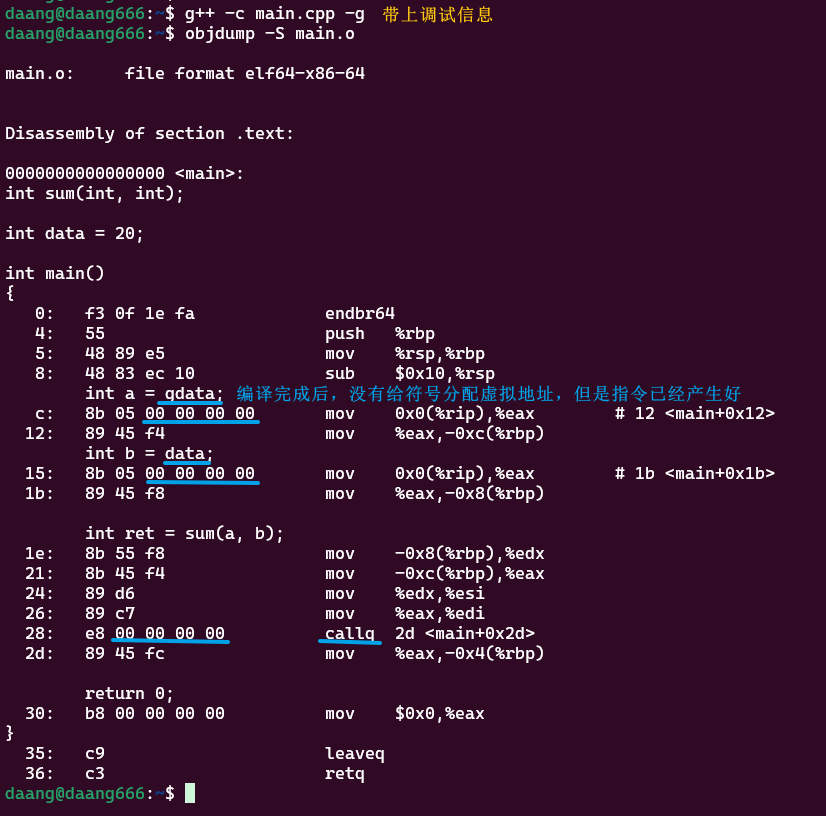
2. 链接过程
步骤一:
- 所有
.o文件段的合并:在链接过程中,就要将main.o和sum.o的各个段进行合并,如.text段和.text段进行合并,.data段和.data段进行合并,.bss段和.bss段进行合并。包括段表和符号表,全部都进行合并。 - 符号表合并后,进行符号解析:所有对符号的引用,都要找到该符号定义的地方。从原本的
*UND*找到对应的在.text和.data上的定义。如果链接器没有找到对引用符号的定义,会报错“符号未定义”;如果找到多个对符号的定义(重定义),会报错“符号重定义”。在符号解析成功后,给所有的符号分配虚拟地址。
步骤二:
- 符号的重定位(重定向):将代码段中的对应符号地址修改为为其分配的虚拟地址。
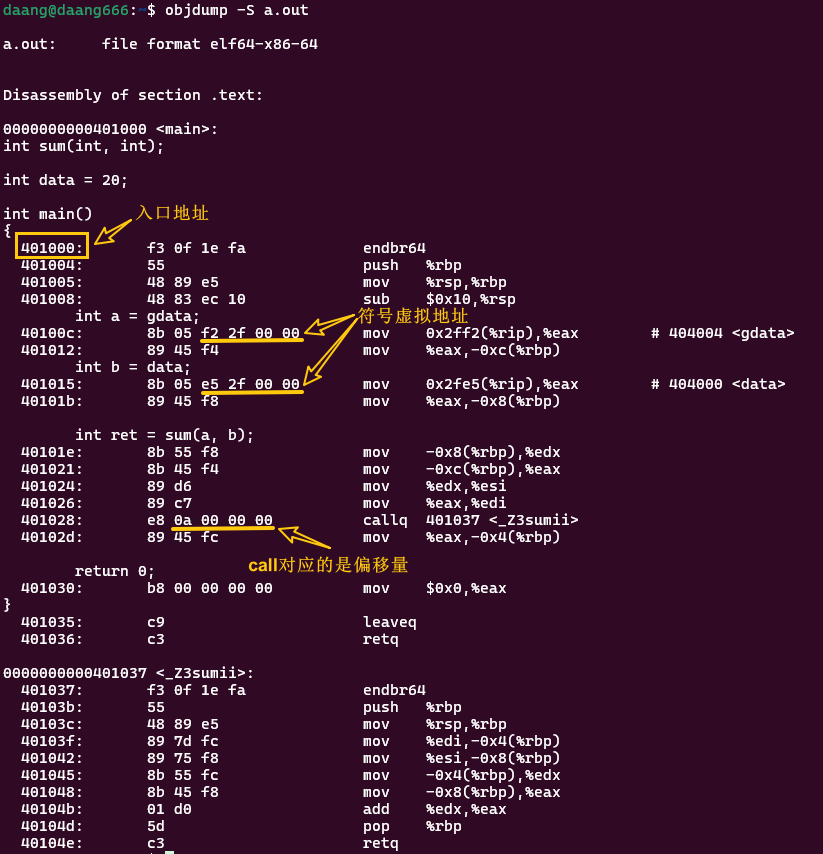
链接器指定入口并进行链接ld -e main *.o,其中-e是指定main作为入口,这样在链接生成的输出文件a.out文件的文件头会将main函数的第一行地址401000作为入口点地址进行记录
objdump -t a.out
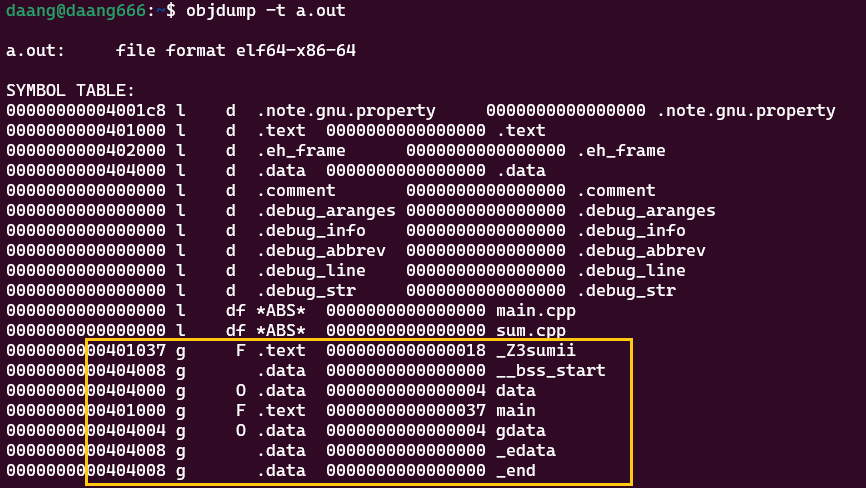
可以看到所有符号都分配地址了,都放到对应的位置了
objdump -S a.out
readelf -S a.out
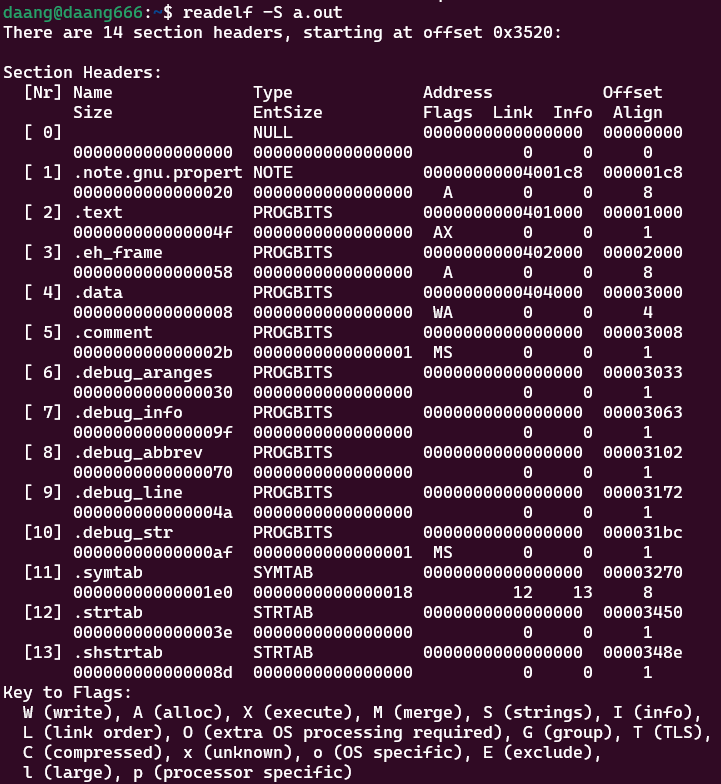
回答问题2:可执行文件的组成格式是什么样子的?
答:由上图可见,可执行文件也是由各种段组成的
readelf -h a.out
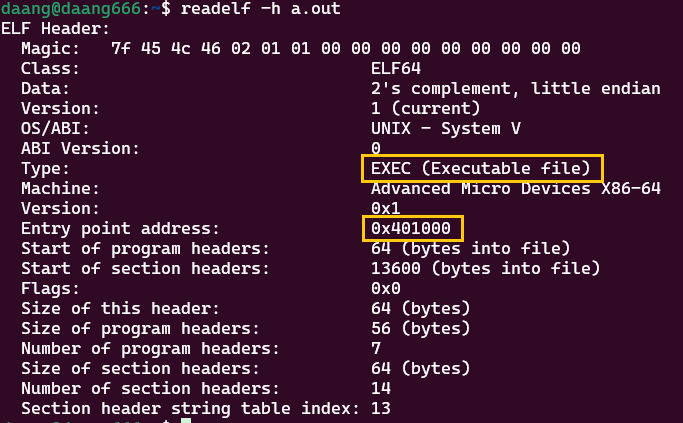
可以看到这是可执行文件,入口是main函数的第一行地址
401000
readelf -l a.out
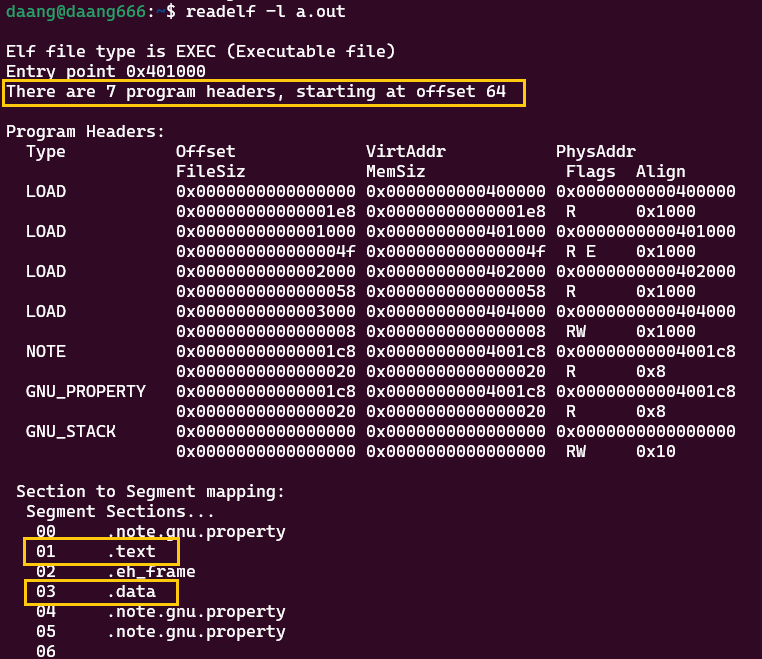
可执行文件的段和重定向文件的段几乎一致,只是多了一个program headers段,可用
readelf -l a.out打印。运行可执行文件的时候,program headers段中LOAD哪些段,就是告诉系统把哪些段加载到内存中,如上图,一般会将.text段和.data段加载到内存中
运行一个可执行文件:
- 加载哪些内容 → \to → 看program headers段
- 从哪里开始运行
→
\to
→ 文件头中的入口地址