pod(容器组)
术语中英文对照:
| 英文全称 | 英文缩写 | 中文翻译 |
|---|---|---|
| Pod | Pod | 容器组 |
| Container | Container | 容器 |
| Controller | Controller | 控制器 |
什么是 Pod 容器组?
Pod(容器组)是 Kubernetes 中最小的可部署单元。一个 Pod(容器组)包含了一个应用程序容器(某些情况下是多个容器)、存储资源、一个唯一的网络 IP 地址、以及一些确定容器该如何运行的选项。Pod 容器组代表了 Kubernetes 中一个独立的应用程序运行实例,该实例可能由单个容器或者几个紧耦合在一起的容器组成。
Docker 是 Kubernetes Pod 中使用最广泛的容器引擎;Kubernetes Pod 同时也支持其他类型的容器引擎。
Kubernetes 集群中的 Pod 存在如下两种使用途径:
- 一个 Pod 中只运行一个容器。“one-container-per-pod” 是 Kubernetes 中最常见的使用方式。此时,您可以认为 Pod 容器组是该容器的 wrapper,Kubernetes 通过 Pod 管理容器,而不是直接管理容器。
- 一个 Pod 中运行多个需要互相协作的容器。您可以将多个紧密耦合、共享资源且始终在一起运行的容器编排在同一个 Pod 中,可能的情况有:
- Content management systems, file and data loaders, local cache managers 等
- log and checkpoint backup, compression, rotation, snapshotting 等
- data change watchers, log tailers, logging and monitoring adapters, event publishers 等
- proxies, bridges, adapters 等
- controllers, managers, configurators, and updaters
每一个 Pod 容器组都是用来运行某一特定应用程序的一个实例。如果您想要水平扩展您的应用程序(运行多个实例),您运行多个 Pod 容器组,每一个代表应用程序的一个实例。Kubernetes 中,称其为 replication(复制副本)。Kubernetes 中 Controller(控制器)负责为应用程序创建和管理这些复制的副本。
Pod 怎样管理多个容器
Pod 被设计成支持形成内聚服务单元的多个协作过程(形式为容器)。 Pod 中的容器被自动安排到集群中的同一物理机或虚拟机上,并可以一起进行调度。 容器之间可以共享资源和依赖、彼此通信、协调何时以及何种方式终止自身。
例如,你可能有一个容器,为共享卷中的文件提供 Web 服务器支持,以及一个单独的 “边车 (sidercar)” 容器负责从远端更新这些文件,如下图所示:
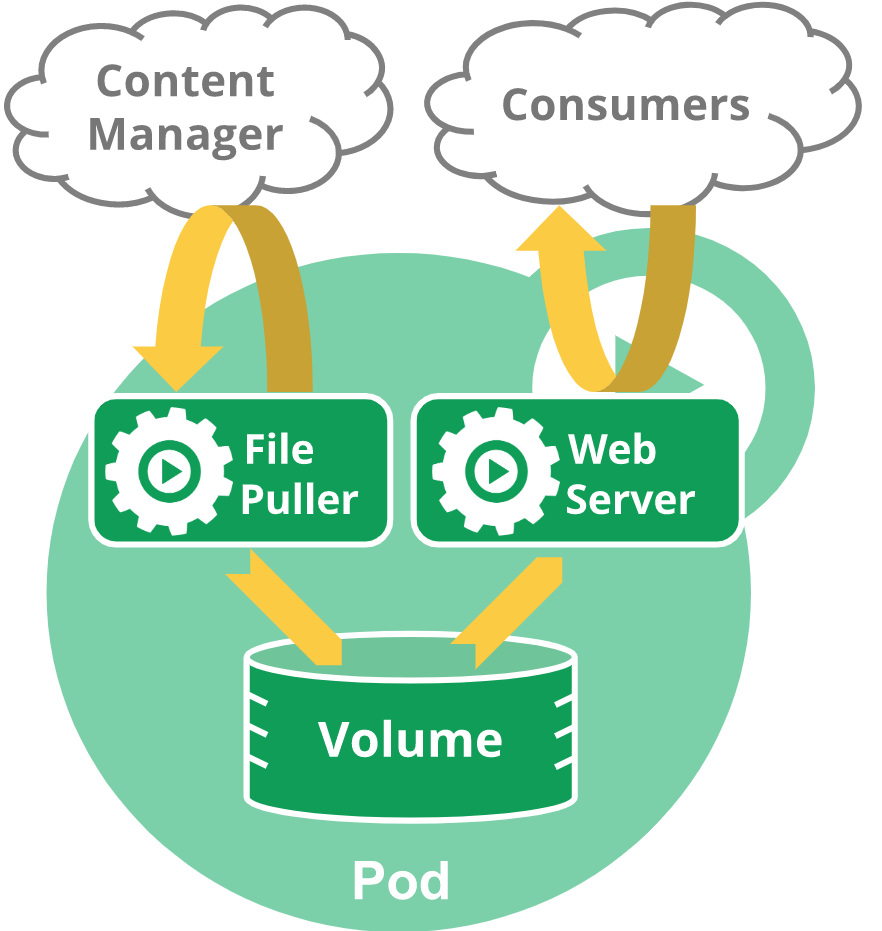
某些 Pod 除了使用 app container (工作容器)以外,还会使用 init container (初始化容器),初始化容器运行并结束后,工作容器才开始启动。
Pod 为其成员容器提供了两种类型的共享资源:网络和存储
-
网络 Networking
每一个 Pod 被分配一个独立的 IP 地址。Pod 中的所有容器共享一个网络名称空间:
- 同一个 Pod 中的所有容器 IP 地址都相同
- 同一个 Pod 中的不同容器不能使用相同的端口,否则会导致端口冲突
- 同一个 Pod 中的不同容器可以通过 localhost:port 进行通信
- 同一个 Pod 中的不同容器可以通过使用常规的进程间通信手段,例如 SystemV semaphores 或者 POSIX 共享内存
ps:
不同 Pod 上的两个容器如果要通信,必须使用对方 Pod 的 IP 地址 + 对方容器的端口号 进行网络通信
- 存储 Storage
Pod 中可以定义一组共享的数据卷。Pod 中所有的容器都可以访问这些共享数据卷,以便共享数据。Pod 中数据卷的数据也可以存储持久化的数据,使得容器在重启后仍然可以访问到之前存入到数据卷中的数据。
用于管理 pod 的工作负载资源
通常你不需要直接创建 Pod,甚至单实例 Pod。 相反,你会使用诸如 Deployment 或 Job这类工作负载资源来创建 Pod。 如果 Pod 需要跟踪状态,可以考虑 StatefulSet资源。
Kubernetes 集群中的 Pod 主要有两种用法:
- 运行单个容器的 Pod。“每个 Pod 一个容器” 模型是最常见的 Kubernetes 用例; 在这种情况下,可以将 Pod 看作单个容器的包装器,并且 Kubernetes 直接管理 Pod,而不是容器。
- 运行多个协同工作的容器的 Pod。 Pod 可能封装由多个紧密耦合且需要共享资源的共处容器组成的应用程序。 这些位于同一位置的容器可能形成单个内聚的服务单元 —— 一个容器将文件从共享卷提供给公众, 而另一个单独的 “边车”(sidecar)容器则刷新或更新这些文件。 Pod 将这些容器和存储资源打包为一个可管理的实体。
每个 Pod 都旨在运行给定应用程序的单个实例。如果希望横向扩展应用程序 (例如,运行多个实例以提供更多的资源),则应该使用多个 Pod,每个实例使用一个 Pod。 在 Kubernetes 中,这通常被称为副本(Replication)。 通常使用一种工作负载资源及其控制器来创建和管理一组 Pod 副本。
使用 Pod
在使用k8s需要避免直接创建pod 。这是因为pod被设计成相对临时,且可以随时抛弃的实体。在 Pod 被创建后(您直接创建,或者间接通过 Controller 创建),将被调度到集群中的一个节点上运行。Pod 将一直保留在该节点上,直到 Pod 以下情况发生:
- Pod 中的容器全部结束运行
- Pod 被删除
- 由于节点资源不够,Pod 被驱逐
- 节点出现故障(例如死机)
ps: 重启 Pod 中的容器不应与重启 Pod 混淆。 Pod 不是进程,而是容器运行的环境。 在被删除之前,Pod 会一直存在。
Pod 的名称必须是一个合法的 DNS 子域值, 但这可能对 Pod 的主机名产生意外的结果。为获得最佳兼容性,名称应遵循更严格的 DNS 标签规则。
pod操作系统
特征状态:Kubernetes v1.25 [stable]
.spec.os.name 字段设置为 windows 或 linux 以表示你希望 Pod 运行在哪个操作系统之上。 这两个是 Kubernetes 目前支持的操作系统。将来,这个列表可能会被扩充。
在 Kubernetes v1.26 中,为此字段设置的值对 Pod 的调度没有影响。 设置 . spec.os.name 有助于确定性地标识 Pod 的操作系统并用于验证。 如果你指定的 Pod 操作系统与运行 kubelet 所在节点的操作系统不同, 那么 kubelet 将会拒绝运行该 Pod。 Pod 安全标准也使用这个字段来避免强制执行与该操作系统无关的策略。
Pod 和控制器
你可以使用工作负载资源来创建和管理多个pod。而不是直接创建pod 控制器可以提供如下特性:
-
水平扩展(运行 Pod 的多个副本)
-
rollout(版本更新)
-
elf-healing(故障恢复)
如:当一个节点出现故障,控制器可以自动地在另一个节点调度一个配置完全一样的 Pod,以替换故障节点上的 Pod
在kubernetes中,广泛使用的控制器有:
- Deployment
- StatefulSet
- DaemonSet
控制器通过其中配置的 Pod Template 信息来创建 Pod。
pod模板(pod Template)
Pod Template 是关于 Pod 的定义,但是被包含在其他的 Kubernetes 对象中(例如 Deployment、StatefulSet、DaemonSet 等控制器)。控制器通过 Pod Template 信息来创建 Pod。正是由于 Pod Template 的存在,Kuboard 可以使用一个工作负载编辑器来处理不同类型的控制器。
示例:
一个简单的 Job 的清单,其中的 template 指示启动一个容器。 该 Pod 中的容器会打印一条消息之后暂停。
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# 这里是 Pod 模板
spec:
containers:
- name: hello
image: busybox:1.28
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# 以上为 Pod 模板
修改 Pod 模板或者切换到新的 Pod 模板都不会对已经存在的 Pod 直接起作用。 如果改变工作负载资源的 Pod 模板,工作负载资源需要使用更新后的模板来创建 Pod, 并使用新创建的 Pod 替换旧的 Pod。
例如,StatefulSet 控制器针对每个 StatefulSet 对象确保运行中的 Pod 与当前的 Pod 模板匹配。如果编辑 StatefulSet 以更改其 Pod 模板, StatefulSet 将开始基于更新后的模板创建新的 Pod。
Termination of Pods
Pod 代表了运行在集群节点上的进程,而进程的终止有两种方式:
- gracefully terminate (优雅地终止)
- 直接 kill,此时进程没有机会执行清理动作
当用户发起删除 Pod 的指令时,Kubernetes 需要:
- 让用户知道 Pod 何时被删除
- 确保删除 Pod 的指令最终能够完成
Kubernetes 收到用户删除 Pod 的指令后:
- 记录强制终止前的等待时长(grace period)
- 向 Pod 中所有容器的主进程发送 TERM 信号
- 一旦等待超时,向超时的容器主进程发送 KILL 信号
- 删除 Pod 在 API Server 中的记录
举个例子:
-
用户通过 Kuboard 或者 kubectl 发起删除 Pod 的指令,默认 grace period (等待时长)为30秒
-
Pod 的最大存活时间被更新,超过此存活时间,将被认为是“dead”
-
Pod 的状态变更为 “Terminating”
-
(与步骤 3 同时)Kubelet 识别出 Pod 的状态是 “Terminating”并立刻开始关闭 Pod 的过程
-
如果 Pod 中的某个容器定义了 preStop hook,该钩子程序将被在容器内执行,如果 preStop hook 的执行超过了 grace period (等待时长),步骤二将被执行(并拥有额外的 2 秒等待时长)
-
向容器的主进程发送 TERM 信号
容器组的每一个容器并不是同一时间接受到 TERM 信号,如果容器的关闭顺序很重要,您可能需要为每一个容器都定义一个 preStop hook
-
-
(与步骤 3 同时)将 Pod 从 Service 的 endpoint 列表中移除(Service 不再将请求路由到该 Pod)。
-
一旦超过 grace period(等待时长),向 Pod 中的任何仍在运行的进程发送 KILL 信号
-
Kubelet 将 Pod 从 API Server 中删除,Kuboard / kubectl 上不再显示该 Pod
默认情况下,删除 Pod 的 grace period(等待时长)是 30 秒。用户可以通过 kubectl delete 命令的选项 --grace-period=<seconds> 自己指定 grace period(等待时长)。如果您要强制删除 Pod,您必须为 kubectl delete 命令同时指定两个选项 --grace-period=0 和 --force