标题:用于自然驾驶行为识别的多注意力Transformer
标题:用于自然驾驶行为识别的多注意力Transformer
源文链接:https://openaccess.thecvf.com/content/CVPR2023W/AICity/papers/Dong_Multi-Attention_Transformer_for_Naturalistic_Driving_Action_Recognition_CVPRW_2023_paper.pdf![]() https://openaccess.thecvf.com/content/CVPR2023W/AICity/papers/Dong_Multi-Attention_Transformer_for_Naturalistic_Driving_Action_Recognition_CVPRW_2023_paper.pdf
https://openaccess.thecvf.com/content/CVPR2023W/AICity/papers/Dong_Multi-Attention_Transformer_for_Naturalistic_Driving_Action_Recognition_CVPRW_2023_paper.pdf
源码链接:https://github.com/wolfworld6/Aicity2023-Track3![]() https://github.com/wolfworld6/Aicity2023-Track3
https://github.com/wolfworld6/Aicity2023-Track3
发表:CVPR-2023
目录
摘要
1. 简介
2. 方法
2.1 数据预处理
2.2 特征提取
2.3 时间动作定位
2.4 时间校正
3. 实验
3.1 训练
3.1.1 特征提取模型
3.1.2 时间动作定位模型
3.2 结果
3.2.1 数据预处理结果
3.2.2 多视角模型结果
3.2.3 后视图模型结果
4. 结论
读后总结
摘要
为了检测AI City Challenge Track 3中未剪辑视频中每个动作的开始时间和结束时间,本文提出了一种强大的网络架构——多注意力Transformer。之前的方法通过设置固定滑动窗口来提取特征,这意味着一个固定的时间间隔,并预测动作的开始和结束时间。我们认为,采用一系列固定窗口会破坏包含上下文信息的视频特征。因此,我们提出了一种多注意力Transformer模块,该模块结合了局部窗口注意力和全局注意力来解决这个问题。采用VideoMAE提供的特征的方法在验证集A2上取得了66.34的得分。然后使用时间校正模块将得分提高到67.23。最终,我们在AI City Challenge 2023的Track 3 A2数据集上获得了第三名。我们的代码可在以下地址获取:https://github.com/wolfworld6/Aicity2023-Track3。
1. 简介
分心驾驶可能非常危险。如今,自然驾驶研究和计算机视觉技术的发展为消除和减少分心驾驶行为的发生提供了急需的解决方案。自然驾驶研究对于研究驾驶员行为至关重要。它们可以帮助我们捕捉交通环境中的驾驶员行为,并分析驾驶员在驾驶时的分心情况,这是减少分心驾驶的关键之一。AI City Challenge的Track 3提供了车内驾驶员的视频片段,这些片段覆盖了三个不同的视角,并包含了16种不同类型的驾驶员动作。在这一赛道中,参与者需要实现一个算法来标注视频中的各种动作,并识别它们的开始和结束时间。
这个任务可以看作是视频理解领域的时间动作定位(TAL)任务。这项任务中的视频通常是较长的未编辑视频,但每个单独动作的时间间隔相对较短。在时间动作定位算法中,一个直观的想法是预定义一组不同时间长度的滑动窗口,并将它们在视频上滑动,如S-CNN [17]、TURN [6] 和 CBR [5]。然后,逐一判断每个滑动窗口内的时间间隔内的动作类别。受两阶段目标检测算法的启发,基于候选时间间隔的算法首先从视频中生成一些可能包含动作的候选时间间隔,然后判断每个候选时间间隔内的动作类别并校正间隔边界,如R-C3D [19] 和 TAL-Net [3]。此外,单阶段目标检测的理念也可以应用于时间动作定位,如SSAD [12] 和 GTAN [15]。目前,Transformer模型在计算机视觉的各个领域中表现出了卓越的性能,如目标检测 [2],[21],[10],[9],图像分类 [4],[13],和视频理解 [7],[14]。然而,当在长时间视频中使用Transformer模型时,视频帧数量的增加将导致计算量显著增加。Gedas Bertasius等人 [1] 进行了广泛的实验,发现了一种可分离的时空注意力方法,为Transformer模型在长视频理解中的应用打开了大门。其次,由于不同动作的持续时间可能差异很大,在Transformer模型中设置固定的窗口和块大小来提取适当的特征是具有挑战性的。Kai Han等人 [8] 提出了Transformer中的Transformer (TNT) 模型,该模型融合了外部块和内部块的特征,丰富了特征信息,提高了特征表达。
受上述观察的启发,我们提出了一个多注意力Transformer模块,该模块不仅用于建模不同剪辑窗口之间的关系,还用于建模全局窗口内的关系。此外,我们设计了一个时间校正模块,以融合和校正高置信度的预测结果,从而获得更准确的结果。
2. 方法
2.1 数据预处理
我们在视频中检测人体并裁剪每一帧。为了确保视频的稳定性,我们对视频的每一帧进行人体检测,并将检测区域最大的帧保存为整个视频的裁剪标准,以避免由于不同帧中的检测尺寸不同而导致的背景抖动。裁剪操作保留了与人体相关的信息,去除了冗余信息。一方面,它减少了其他噪音对动作特征的干扰。另一方面,它使模型更容易学习人体动作。
2.2 特征提取
我们在不同的视频表示模型和A1视频的三个视角上进行了多次实验。由于VideoMAE [18] 在表1中显示了更好的性能,因此在本文中采用它对后视和仪表盘视角进行特征提取。我们使用了在不同数据集上预训练的公共权重,并在A1数据上进行了微调。本文中使用的权重如表 2所示。我们分别对后视和仪表盘视角的视频进行了微调,并提取了A2数据集的特征。


2.3 时间动作定位
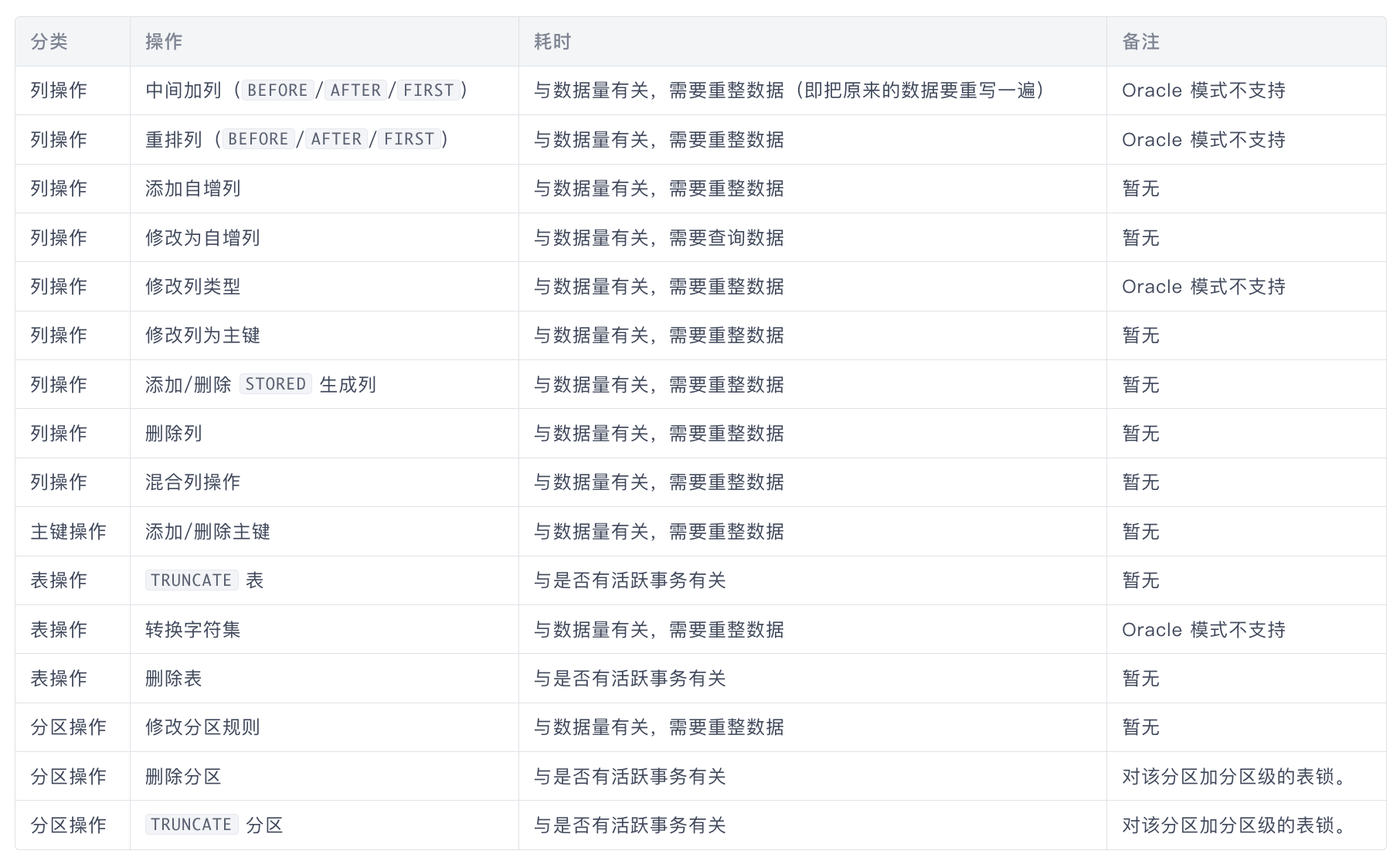
Actionformer [20] 结合了多尺度特征表示和局部自注意力,并使用轻量级解码器对每个时刻进行分类并估计相应的动作边界。如图1所示,在Actionformer的基础上,我们提出了一个多注意力Transformer,不仅用于建模不同剪辑窗口之间的关系,还用于建模全局窗口内的关系。
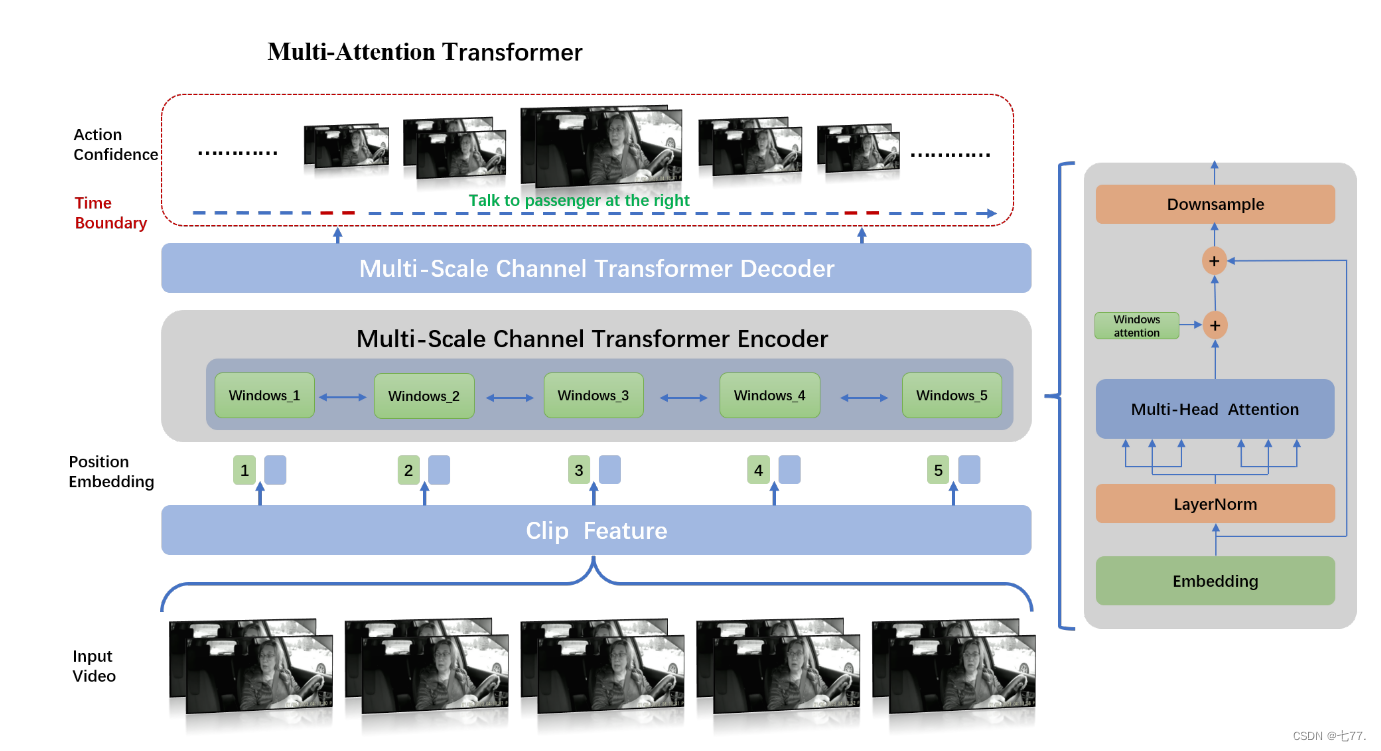
图1. 我们模型架构的概述。我们的方法构建了一个基于Transformer的模型,用于动作分类并估计每个时刻的动作边界。在特征提取阶段,我们通过VideoMAE提取一系列视频剪辑特征,然后对这些特征进行嵌入。嵌入的特征将通过窗口注意力和全局注意力模块进行编码。在每个时间步,通过使用分类头预测动作类别和回归头预测动作时间边界,生成候选动作。
多注意力:如图1右侧所示,在多尺度通道Transformer编码器中,从视频片段中提取的特征 输入到LayerNorm、多头注意力和窗口注意力模块,然后进行下采样以获得特征
。特征
重新输入编码器,经过LayerNorm、多头注意力、窗口注意力和下采样后,获得特征
。这种操作重复N-1次,以获得
。之后,
输入到多尺度通道Transformer解码器进行解码,通过不同的全连接层回归动作的类别信息和相应的时间信息。
在多头注意力模块中,所有输入特征之间进行特征融合;由于输入特征是按照视频时间段排列的,多头注意力模块将利用时间轴上的信息。在窗口注意力模块中,特征融合既针对相邻位置的视频片段特征,也针对所有特征进行,但不同之处在于,特征融合仅在通道维度上进行。
我们的模型有N层Transformer层,采用多尺度来捕捉不同时间尺度上的动作。每一层由局部多头自注意力(MSA)和全局多头自注意力(GMSA)组成。为了在不同的注意力下捕捉动作,这个操作被公式化为:
其中, 指的是第i层的MSA,
指的是第i层的GMSA。一个标准的Transformer块结构包括多头自注意力(MSA)和多层感知器(MLP)。为了提高效率,我们采用了一个多注意力模块,该模块由剪辑窗口注意力模块和全局注意力模块组成,可以从不同区域的不同表示子空间中学习信息。具体来说,每个剪辑窗口通道的嵌入进行平均,然后通过头对头Transformer获得相同数量的注意力值。注意力值将相应地乘或加在通道上。该模块通过维度级别的注意力实现特征增强,仅增加少量参数。
2.4 时间校正
时间动作定位模型的输出包含大量低分数的预测结果,这些结果在时间上有大量重叠的区域。评分标准要求每个正确的结果尽可能只匹配一个预测,并且该预测的时间范围与正确的结果差异尽量小。这意味着需要过滤大量的结果,只保留置信度高的结果。因此,我们设计了时间校正模块,以融合和校正置信度高的预测结果,并获得时间更准确的最终结果。
时间校正操作包括三个主要步骤,分别是:
1. 对于每个视频ID的所有预测结果,仅保留具有相同标签结果中得分最高的一个,丢弃其他项目。
2. 分别对几个不同模型执行步骤1,并拼接得到的结果;
3. 对于步骤2中获得的结果,根据时间交集并集(tIoU)融合相同标签和相同视频ID的结果;具体的融合操作包括:
(1)移除所有时间长度小于1秒的结果;移除所有时间长度大于30秒的结果;
(2)对于具有相同视频ID和相同标签的所有结果,将结果分成不同的集合,使得每个集合中所有时间区域的tIoU大于集合阈值;
(3)移除长度为1的集合;
(4)对步骤(3)中获得的所有集合,计算每个集合中所有时间点的平均值;由于每个集合中的所有结果具有相同的视频ID和相同的标签,将集合中所有开始时间的平均值计算为该视频ID和该标签的开始时间;将集合中所有结束时间的平均值计算为该视频ID和该标签的结束时间。第i个视频ID和第j个标签的动作的开始时间和结束时间可以通过以下公式计算:
其中,是第i个视频ID和第j个标签的动作的开始时间,
是第i个视频ID和第j个标签的动作的结束时间。
表示视频ID为i且标签为j的预测集合。N是
的长度。
表示
中第p个预测的开始时间,
表示
中第p个预测的结束时间。
此外,在融合相同视频ID和相同标签的结果时,除了描述的第四步中取所有时间点的平均值的方法外,我们还尝试另一种方法:根据它们的分数对时间节点的融合进行加权,公式如下:
其中, 表示
中第p个预测的分数。
3. 实验
3.1 训练
3.1.1 特征提取模型
使用了 VideoMAE-L 和 VideoMAE-H 在 A1 数据集上进行微调,训练裁剪大小为 224。初始学习率为 2e-3。帧数为 16,采样率为 4。实验在 8 个 Nvidia V100 GPU 上以批量大小 2 运行。VideoMAE-L 训练了 35 个 epoch,而 VideoMAE-H 训练了 40 个 epoch。
3.1.2 时间动作定位模型
我们在 A1 数据集上进行实验,将数据划分为训练集和测试集,比例为 7:3。实验后,我们使用所有 A1 数据作为训练集。首先,我们将 32 个连续帧作为输入提供给预训练模型 UniFormerV2,使用步幅为 16 的滑动窗口,并从原始视频中提取了覆盖左、中、右三部分的 3072-D 特征,以优化网络结构。使用 mAP@[0.1:0.5:5] 来评估我们的模型。其次,我们还对提取的 1024D 特征进行了一些消融实验。我们的 TAL 模型训练了 40 个 epoch,线性预热了 5 个 epoch。初始学习率为 1e-3,采用余弦学习率衰减,权重衰减为 5e-2。最后,我们使用预训练的 VideoMAE 提取 1028-D 特征和 1024-D 特征。该方法可适用于不同的特征,并测试模型在多视角、单视角和多特征上的性能。
3.2 结果
3.2.1 数据预处理结果
针对裁剪操作是否增强了模型效果,我们进行了消融实验来验证。实验结果表明,裁剪操作确实起到了作用。如表3所示,使用具有 FH(k400)(1280) 特征的 Multi-Attention 模型,裁剪操作可将后视和仪表盘视图上的 mAP 从 83.67 提升到 87.79。
3.2.2 多视角模型结果
我们开始进行实验,并在 A1 数据集上使用预训练模型 UniFormerV2 提取所有视角视频的 3072-D 特征,我们使用验证集进行训练。窗口大小的超参数设定为 9,小批量大小为 4,最大段数设定为 2304。表4总结了结果,我们的方法在平均 mAP 上达到了 67.33%,在 tIoU=0.5 时的 mAP 为 59.02%。通过简单设计和强大的多注意力Transformer模型的结合,模型性能得到了提升。此外,我们尝试了各种超参数,包括使用具有8个头的FPN架构,将窗口大小增加到13,并将中心样本半径设定为2.5。结果,mAP 从 67.33% 提高到了 70.69%。
考虑到不同区域包含屏幕目标的不同信息,我们尽可能地进行了大量实验,以便对具有不同裁剪部分和不同调整大小模式的视频特征进行公平比较。结果如表5所示。与表4中的结果(mAP 67.33%)相比,差别不大,因此我们在后续实验中删除了裁剪模式。
3.2.3 后视图模型结果
通过实验发现,使用后视图的分类模型的准确性更高,如表1所示。我们测试了使用不同的VideoMAE背景模型提取的后视图和仪表盘视图特征的模型性能。如表6所示,不同的特征在时间动作定位上具有不同的性能。
3.2.4 时间校正模块结果
时间校正模块的实验结果如表7所示。模型M1到M10的具体信息如表8所示。由于系统提供的评估次数有限,我们无法对每个模型组合遍历所有方法以获得最佳的评估结果。因此,在总结每个比较实验中的模式后,我们直接为更好的模型使用最佳处理方法。我们在第2.4节介绍了时间校正模块。在第二步中,将几个不同模型的结果拼接在一起,与使用单个模型相比,结果更高。单个模型M1的平均重叠分数为0.6382,但在拼接三个模型的结果并采用时间校正后,评估结果的性能提高到了0.6482。此外,四个模型M7 + M8 + M9 + M10的拼接结果比三个模型M7 + M8 + M9的拼接结果将评估分数从0.6634提高到了0.6723。第三步中,移除了长度为1的集合。这个操作也提升了结果。在添加此操作后,与没有此操作的时间校正模块的结果相比,评估分数从0.6325提高到了0.6482。针对A1数据集进行了动作持续时间的统计,发现持续时间都在1-30秒的范围内,因此我们限制了预测结果的持续时间范围。此外,当融合相同视频ID和相同标签的结果时,我们尝试了两种方法:取所有时间点的平均值和根据它们的分数对时间节点进行加权融合。然而,实验结果表明,使用平均值更令人满意。使用相同的模型组合M4 + M5 + M6,加权和平均方法分别得到0.6514和0.6593。赛道的总体排名和得分如表9所示。表7中M7 + M8 + M9 + M10模型组合的结果是我们团队最终的预测结果,在公共排行榜上平均重叠分数为0.6723,排名第三。在这个组合中,M7、M8和M9分别表示使用表2中的特征FL(hybrid)(1024)、FL(ego)(1024)和FH(k400)(1280)训练的时间动作定位模型。而M10代表Tridet模型。毫无疑问,通过将更强大的视频特征背景与目标检测结果相结合,我们方法在AI城市挑战赛的Track 3上的结果可以进一步提高。
4. 结论
本文提出了一种基于多注意力Transformer的时间动作定位方法。该方法的强大之处在于我们的设计选择,特别是将特征与多注意力模块的方法相结合,以对视频中的更长时间范围的上下文进行建模。此外,我们进行了大量实验,比较了不同的视频视角、不同的特征提取网络、不同的预训练数据集,以找到具有更好特征表示能力的视角和网络。此外,我们还提出了一个时间校正模块来提高时间精度。
读后总结
创新点1:在实现时间动作定位部分,提出多注意力Transformer模块,在transformer中加入局部窗口注意力,通过局部窗口注意力和全局窗口注意力的组合来代替固定窗口。
创新点2:提出时间校准模块,对视频段的预测结果进行融合和处理(平均,加权平均)等处理,实现时间定位更加准确。