1.简介
它是带有生产者-消费者模式实现的并发容器,同样用来解决高并发场景下多线程之间数据共享的问题。Arra不支持扩缩容,其容量大小在初始化时就已经确定好了,尽管字面意义上来看它属于阻塞队列的一种,但它同时还提供了一些非阻塞式的API。
与之相类似的还有LinkedBlockQueue,二者主要的区别在于:
- ABQ的底层数据结构是数组,LBQ则为单向链表。
- ABQ是有界的,LBQ可有界可无界(也不完全是无界,只不过规定最大元素数为
Integer.MAX_VALUE,但这近乎无穷大)。
2.实现原理
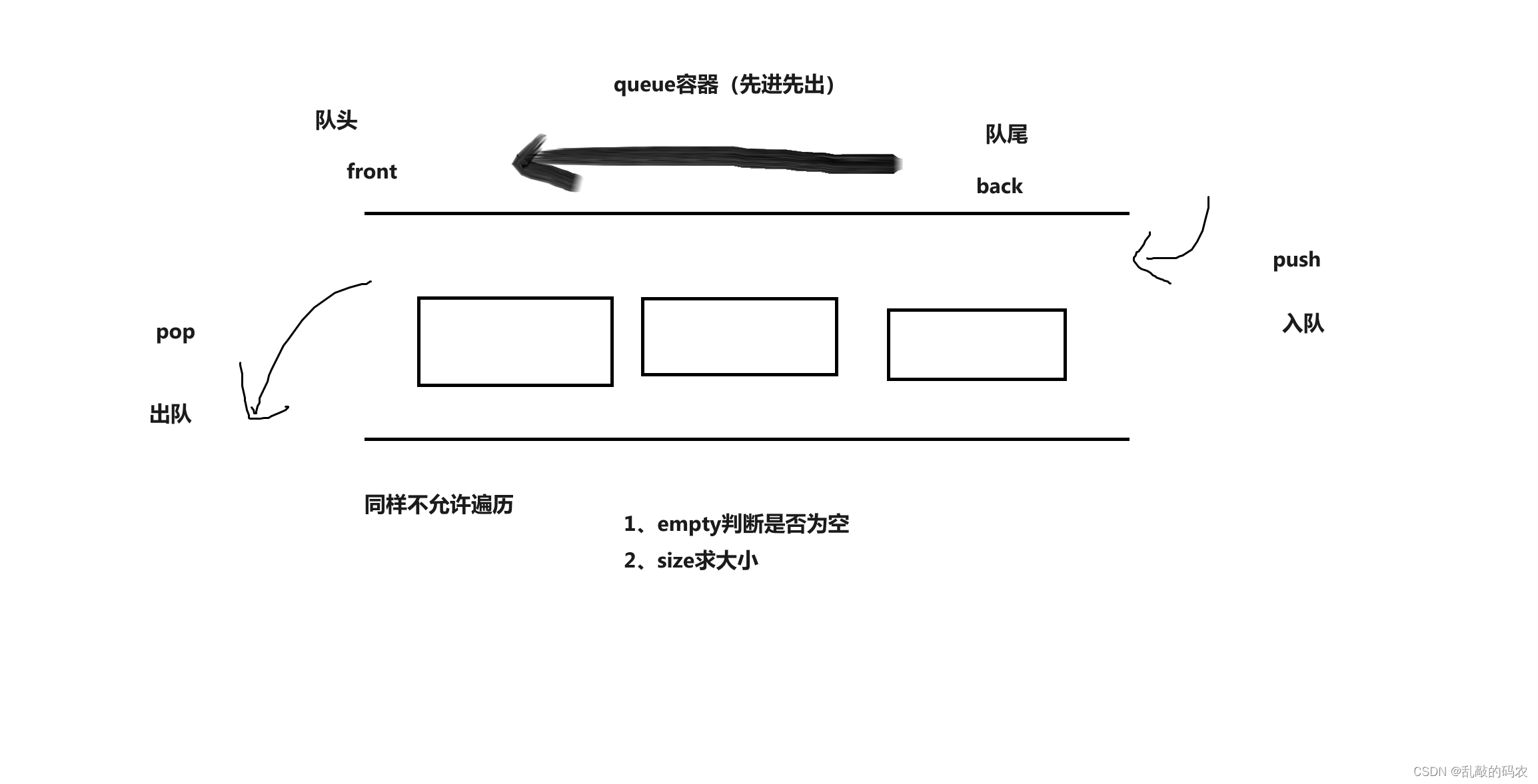
生产者-消费者模型。
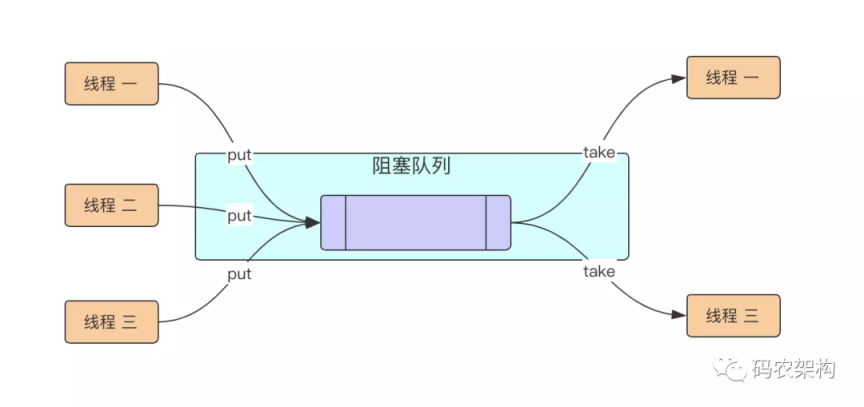
底层以数组作为阻塞队列。
全部读写查操作均由内部的ReentrantLock锁来负责实现同步。
通过Condition实现线程间的等待与唤醒操作。
采用
Condition来进行线程的唤醒与休眠操作主要是为了达到选择性通知这一目的,因为在整个生产-消费模型中,对于线程的唤醒,我们要么是只唤醒消费者一方、要么只唤醒生产者一方,而不会将生产者消费者全部同时唤醒。
具体执行流程:
- 若阻塞队列为空,则消费者一方阻塞等待,直至生产者一方将元素放到阻塞队列中以使阻塞队列非空。
- 若阻塞队列已满,则生产者一方阻塞等待,直至消费者一方消费了若干个(≥ 1)元素以使阻塞队列不满。
- 消费者消费元素(即从阻塞队列中取走一个元素)时,消费完毕会会唤醒生产者。
- 生产者生产元素(即从阻塞队列中放置一个元素)时,生产完毕后会唤醒消费者。
3.源码分析
3.1 类定义
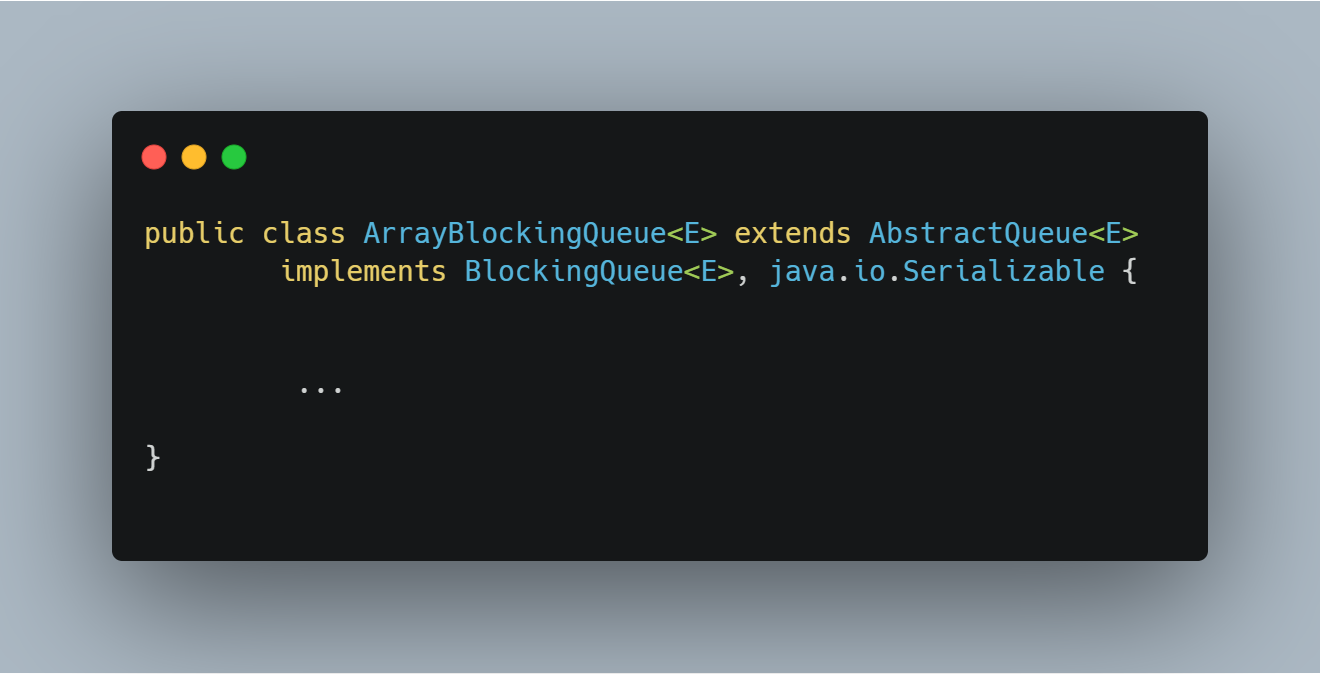 ")
")
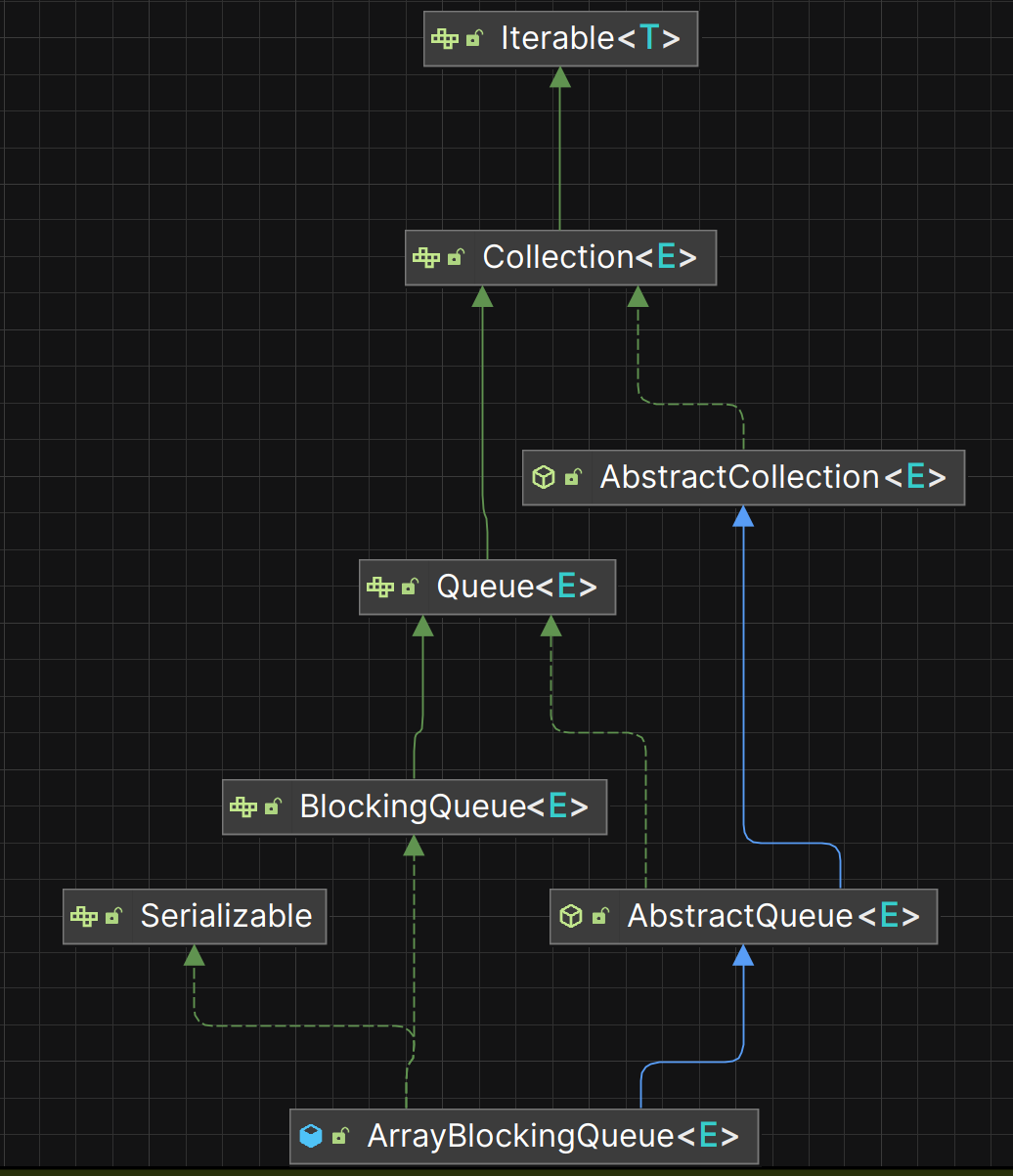
ArrayBlockQueue继承自AbstractQueue,而AbstractQueue实现了基本的增删改查操作,因此通过继承AbstractQueue,使得ArrayBlockQueue具有了队列的一些常见的基本操作。
此外,ArrayBlockQueue还实现了以下接口:
- BlockingQueue:ABQ将具备阻塞队列的一些特性。
- Serializable:可序列化,即可将该对象转换为字节流以实现持久化存储或网络传输。
 ")
")
可以看出,AbstractQueue为ArrayBlockQueue提供了基本的方法执行流程(执行模板),但部分子流程的执行细节(模板中的方法)并没有给出,并通过BlockQueue接口强制ArrayBlockQueue给出具体的实现。听上去,是不是有点模板方法模式的味道?
3.2 初始化
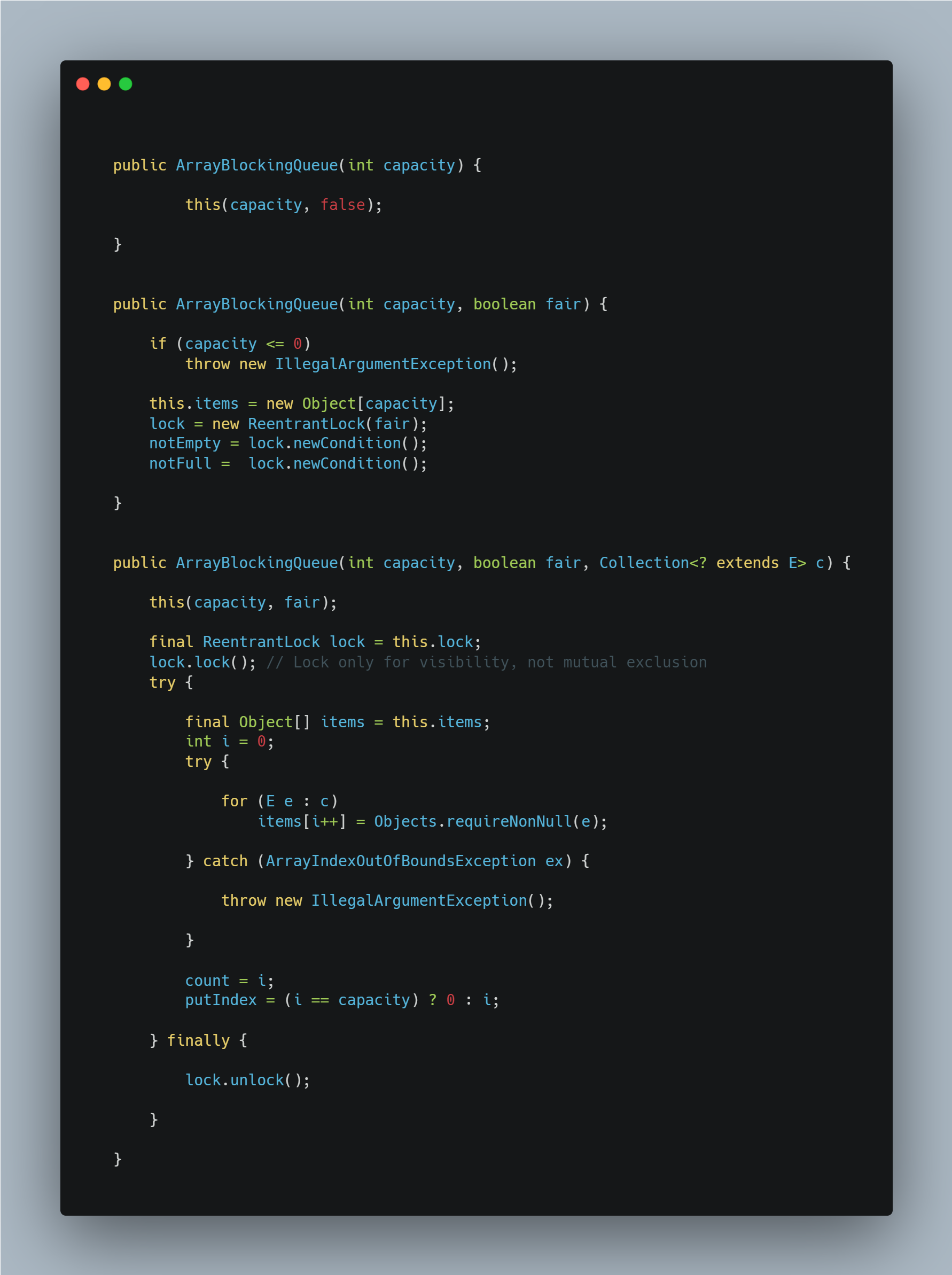 ")
")
可以看到,上下两个构造方法都调用了中间的那个构造方法,而且下面的那个构造方法仅仅就是在中间的构造方法基础上增加了挨个赋值给items数组的过程,因此,我们着重研究中间的那个构造方法。
执行流程
- 检查输入的
capacity参数是否合法,不合法则抛出IAE异常。 - 初始化
items为capacity大小的Object数组。 - 初始化
lock,根据输入的fair参数来决定初始化为公平的还是非公平的ReentrantLock。 - 然后接着上面的
lock,去分别初始化 队列非空、队列不满 这两个Condition。
3.3 add
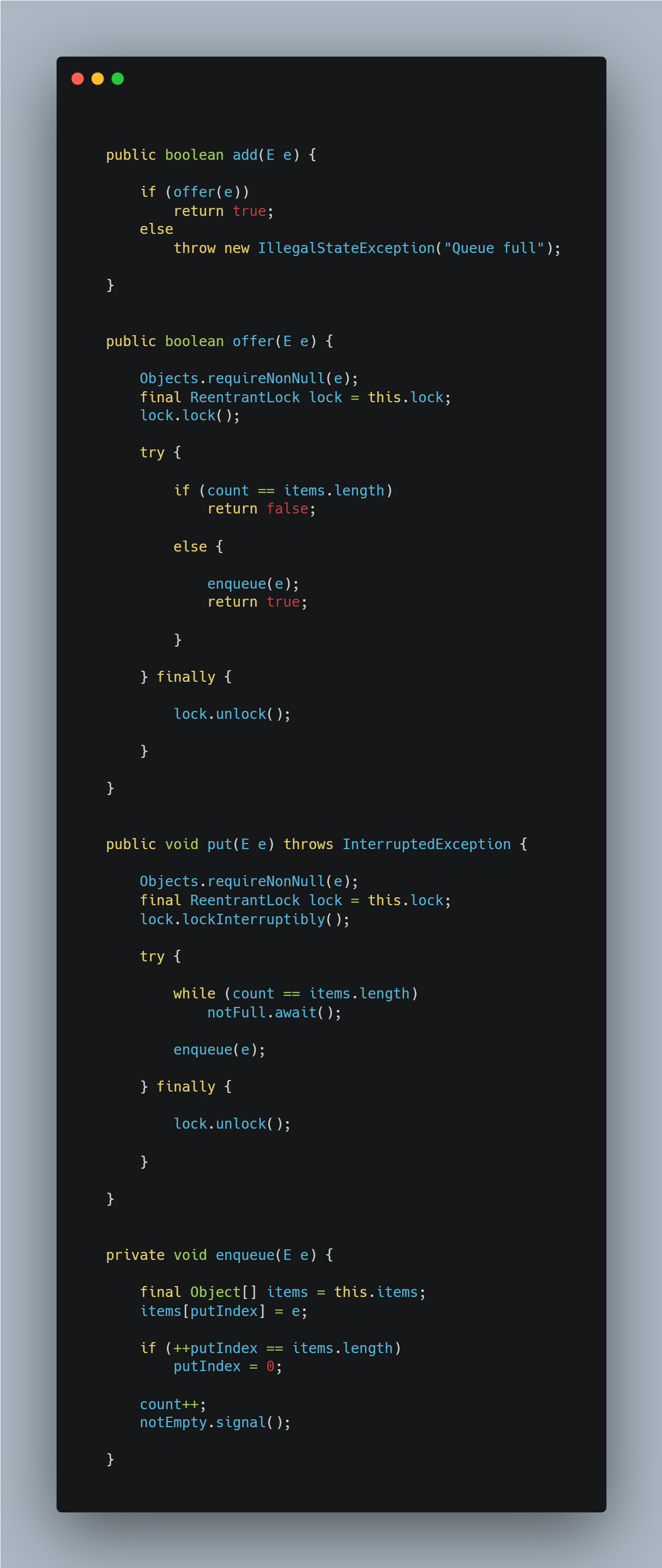 元素的方法(JDK17)")
元素的方法(JDK17)")
通过源码,我们发现add、offer、put方法的主要区别:
- add:内部调用
offer,不会发生阻塞,添加元素失败后(队列已满)抛异常。 - offer:非阻塞式加锁添加元素,添加失败(发现元素个数 = 数组长度)则立刻返回
false。 - put:阻塞式加锁添加元素,添加失败则一直会在
notFull的condition上无限等待,直到被消费者唤醒或被外界打断(interrupt)。
这里的
add方法实际上是父类AbstractQueue的,ArrayBlockQueue的add方法实际上是直接调用的父类的add方法,这里省略了。
如果符合添加元素的条件,则它们最终都会去调用enqueue方法:
- 根据下一个元素存放索引
putIndex,将元素保存到items数组的putIndex下标处。 putIndex + 1,然后判断下次待添加元素的位置是否到达数组末端,若是,则重置为0(始端);否则,不做处理。元素计数 + 1。- 唤醒阻塞在
notEmpty的condition的消费者。
这里之所以我们没在数组赋值之前进行下标合法性校验,是因为,在这个方法被调用之前,我们已经确保了各种条件均已符合预期,即,当前的各种参数如
putIndex、count、items均是合法的,反过来说,正是在确保了这些参数的合法性之后,我们才可以去调用enqueue方法。
3.4 remove
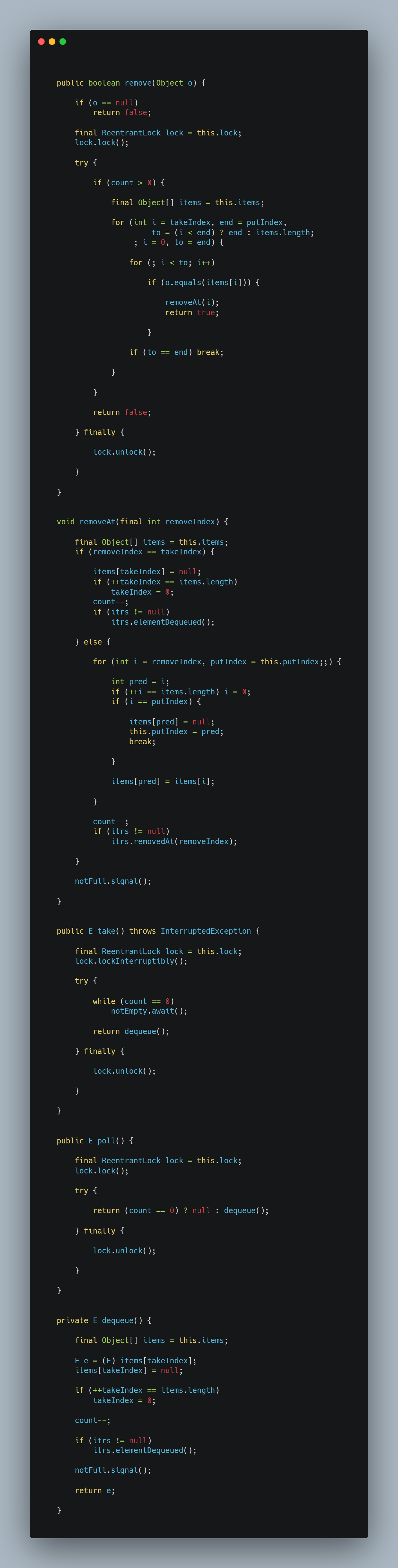 元素的方法(JDK17)")
元素的方法(JDK17)")
先分析一下take和poll这两个方法:
- take:阻塞式加锁移除元素,移除失败则一直会在
notEmpty的condition上无限等待,直到被生产者唤醒或被外界打断(interrupt)。 - poll:非阻塞式加锁移除元素,移除失败(发现元素个数 = 数组长度)则立刻返回
null。
如果符合消费条件(即队列中还有元素可取),则均进入dequeue方法:
- 获取到
items数组takeIndex上对应的元素,然后将该位置的元素置为null。 takeIndex + 1,判断是否到达items末端,若是,则重置为0(始端);否则,不做处理。元素计数 - 1。- 调用了内部类
Ltr实例的elementDequeued方法,该方法的执行逻辑如下:- 若此时元素计数为
0,则意味着队列为空,清理容器内的全部引用和迭代器。 - 若
takeIndex为0,即发生了索引绕回,则清理发生takeIndex绕回或者其迭代器为null的Node节点上的引用,同时分离掉该节点,以避免内存泄漏。
- 若此时元素计数为
- 唤醒阻塞在
notFull的condition的生产者。
最后我们再来看一下remove方法:
- 待移除的对象为
null或元素个数为0的情况下,直接返回false。 - 根据takeIndex和putIndex的大小分两种情况进行遍历比较并移除:
- 若
takeIndex < putIndex(正常情况,前人栽树后人乘凉),则直接一次性由takeIndex遍历至putIndex,比较并移除即可。 - 若
takeIndex > putIndex(发生索引绕回的情况),则需要分两次遍历,第一次是由takeIndex遍历至length - 1,第二次是由0遍历至putIndex,然后比较并移除即可。
- 若
上面的过程同样需要加锁,同时最终移除元素所调用的
removeAt方法中将唤醒阻塞在notFull的condition的生产者。
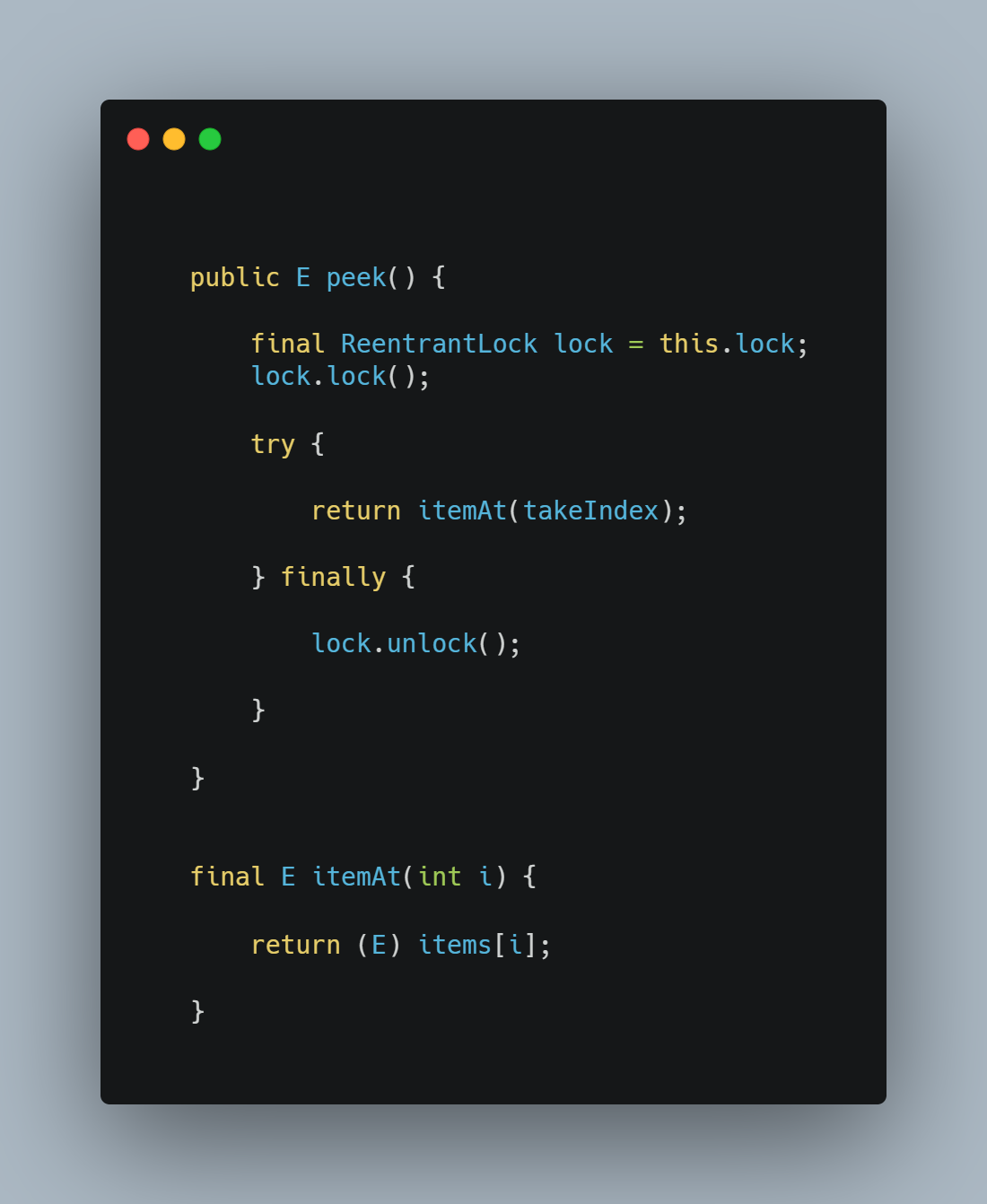
3.5 get
 ")
")
执行流程很简单,先加锁,然后直接返回items数组takeIndex对应位置上的元素,再释放锁。
3.6 超时add/remove
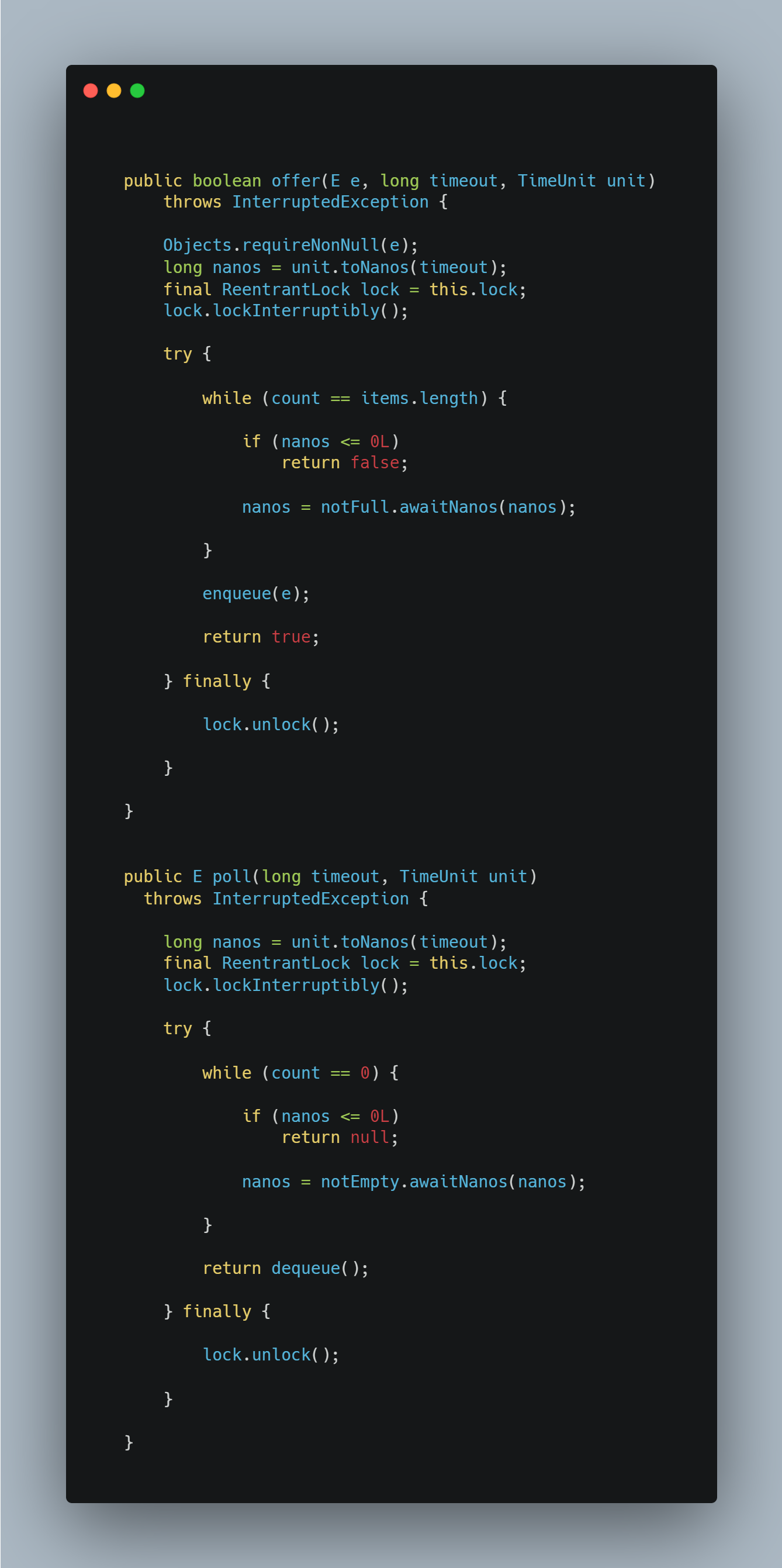
你会发现,超时增删操作与普通增删操作逻辑上基本一致,仅有两处不同:
- 出现了
while循环,只要增删条件不满足,将继续循环下去。 condition上的无限等待调整为有限等待。
第二点好理解,毕竟有限等待的根本就是要保证锁的条件等待那里不能再像之前一样无限等待下去,可是为什么还要加一个while循环呢?
- 可能会出现暂时性死锁。不加
while循环的情况下,意味着不管元素个数如何,生产者(举例)总会先进入有限等待状态,而消费者拿到锁后,却发现元素个数为0,同样也进入有限等待状态。也就是说,不加while循环得情况下,将会放大锁等待的条件范围,进而增加了暂时性死锁的风险。 - 你会发现,当我们被正常唤醒后,还会走一遍while循环进行元素个数的判断,这是因为可能存在虚假唤醒的情况,即生产者/消费者在没有收到明确通知的情况下就被唤醒了,如果此时不进行条件判断,那么生产者/消费者将错误地继续执行下去,从而产生不可预知的影响。
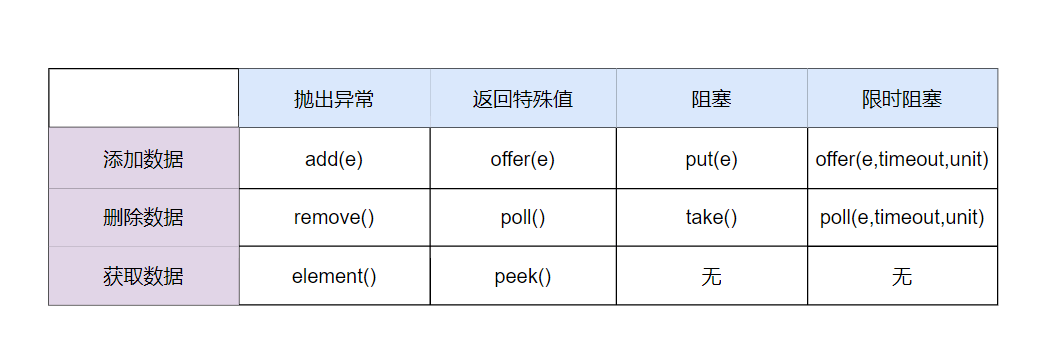
4.对比
| 项目 | ArrayBlockQueue | LinkedBlockQueue |
|---|---|---|
| 底层实现 | 数组 | 单向链表 |
| 是否有界 | 有界 | (伪)无界 |
| 锁分离情况 | 生产消费操作共用同一把锁 | 消费操作用takeLock锁,生产操作用putLock锁 |
| 内存占用 | 需要提前进行预分配,可能存在申请的内存空间比实际用到的内存空间大的情况 | 无需预分配,但每个节点因存放指向下一节点的指针而占用了部分内存空间 |
| 项目 | ArrayBlockQueue | ConcurrentLinkedQueue |
|---|---|---|
| 底层实现 | 数组 | 单向链表 |
| 是否有界 | 有界 | (伪)无界 |
| 是否阻塞 | 支持阻塞式和非阻塞式两种元素操作方式 | 仅支持非阻塞式元素操作方式 |
参考文档
ArrayBlockingQueue 源码分析




![【Linux】-Linux文件的上传和下载、压缩和解压[9]](https://img-blog.csdnimg.cn/direct/03c78febd2cb4a85ad6be37bba1944ce.png)



![[4]CUDA中的向量计算与并行通信模式](https://img-blog.csdnimg.cn/direct/dff63c6c4d94438ab7209c9984dd0860.png)