Schema与数据类型优化
BLOB和TEXT类型
BLOB和TEXT都是为存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。
实际上它们分别属于两组不同的数据类型家族:字符类型是TINYTEXT,SMALLTEXT,TEXT,MEDIUMTEXT,LONGTEXT;对应的二进制类型是TINYBLOB,SMALLBLOB,BLOB,MEDIUMBLOB,LONGBLOB.BLOB是SMALLBLOB的同义词,TEXT是SMALLTEXT的同义词。
与其他类型不同,MySQL把每个BLOB和TEXT值当作一个独立的对象处理。存储引擎在存储时通常会做特殊处理。当BLOB和TEXT值太大时,InnoDB会使用专门的"外部"存储区域来进行存储,此时每个值在行内需要1~4个字节存储一个指针,然后再外部存储区域存储实际的值。
BLOB和TEXT家族之间仅有的不同时BLOB类型存储的是二进制数据,没有排序规则或字符集,而TEXT类型有字符集和排序规则。
MySQL对BLOB和TEXT列进行排序与其他类型是不同的:它只对每个列的最前max_sort_length字节而不是整个字符串做排序。如果只需要排序前面一小部分字符,则可以减小max_sort_length的配置,或者使用ORDER BY SUBSTRING(column, length).
MySQL不能将BLOB和TEXT列全部长度的字符串进行索引,也不能使用这些索引消除排序
磁盘临时表和文件排序
因为Memory引擎不支持BLOB和TEXT类型,所以,如果查询使用了BLOB或TEXT列并且需要使用隐式临时表,将不得不使用MyISAM磁盘临时表。即使只有几行数据也是如此(Percona Server的Memory引擎支持BLOB和TEXT类型,同样的场景下还是需要使用磁盘临时表)。这会导致严重的性能开销。即使配置MySQL将临时表存储再内存块设备上(RAM Disk),依然需要许多昂贵的系统调用。最好的解决方案是尽量避免使用BLOB和TEXT类型。如果实在无法避免,有一个技巧是在所有用到BLOB字段的地方都使用SUBSTRING(column, length)将列值转换为字符串(在ORDER BY 子句中也适用),这样就可以使用内存临时表了。但是要确保截取的子字符串足够短,不会使临时表的大小超过max_heap_table_size或tmp_table_size,超过以后MySQL会将内存临时表转换为MyISAM磁盘临时表。
最坏情况下的长度分配对于排序的时候也是一样的,所以这一招对于内存中创建大临时表和文件排序,以及在磁盘上创建大临时表和文件排序这两种情况都很有帮助。
例如,假设有一个1000万行的表,占用几个GB的磁盘空间。其中有一个uft8字符集的VARCHAR(1000)的列,每个字符最多使用3个字节,最坏情况下需要3000字节的空间。如果在ORDER BY 中用到这个列,并且查询扫描整个表,为了排序就需要超过30GB的临时表。
如果EXPLAIN执行计划的Extra列包含了"Using temporary",则说明这个查询使用了隐式临时表
使用枚举类型(ENUM)代替字符串类型
有时候可以使用枚举列代替常用的字符串类型。枚举列可以把一些不重复的字符串存储成一个预定义的集合。MySQL在存储枚举时非常紧凑,会根据列表值得数量压缩到一个或者两个字节中。MySQL会在内部将每个值在列表中得为止保存为整数,并且在表的.frm文件中保存"数字-字符串"映射关系的"查找表",
例如,
mysql> CREATE TABLE enum_test(e ENUM('fish', 'apple', 'dog') NOT NULL);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO enum_test(e) VALUES('fish'), ('dog'),('apple');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
这三行数据实际存储为整数,而不是字符串。可以通过在数字上下问环境检索看到这个双重属性:
mysql> SELECT e+0 FROM enum_test;
+-----+
| e+0 |
+-----+
| 1 |
| 3 |
| 2 |
+-----+
3 rows in set (0.05 sec)
如果使用数字作为ENUM枚举常量,这种双重性很容易导致混乱,例如ENUM(‘1’,‘2’,‘3’).建议尽量避免这么做。另外一个让人吃惊的地方时,枚举字段是按照内部存储的整数而不是定义的字符串进行排序的:
mysql> SELECT e FROM enum_test ORDER BY e;
+-------+
| e |
+-------+
| fish |
| apple |
| dog |
+-------+
3 rows in set (0.05 sec)
一种绕过这种限制的方式是按照需要的顺序来定义枚举列。另外也可以在查询中使用FIELD()函数显式地指定排序顺序,但这会导致MySQL无法利用索引消除排序。
mysql> SELECT e FROM enum_test ORDER BY FIELD(e, 'apple', 'dog','fish');
+-------+
| e |
+-------+
| apple |
| dog |
| fish |
+-------+
3 rows in set (0.07 sec)
如果在定义时就是按照字母的顺序,就没有必要这么做了。枚举最不好的地方是,字符串列表是固定的,添加或删除字符串必须使用ALTER TABLE,因此,对于一系列未来可能会改变的字符串,使用枚举不是一个好主意,除非能接受只在列表末尾添加元素,这样在MySQL5.1中就可以不用重建整个表来完成修改。
由于MySQL把每个枚举值保存为整数,并且必须进行查找才能转换为字符串,所以枚举列有一些开销。通常枚举的列表都比较小,所以开销还可以控制,但也不能保证一直如此。在特定情况下,把CHAR/VARCHAR列与枚举列进行关联可能会比直接关联(CHAR/VARCHAR)列更慢。
为了说明这个情况,读一个应用中的一张表进行了基准测试,看看在MySQL中执行上面说的关联的速度如何。该表有一个很大的主键:
CREATE TABLE webservicecalls(
day date NOT NULL,
account smallint NOT NULL,
service varchar(10) NOT NULL,
method varchar(50) NOT NULL,
calls int NOT NULL,
items int NOT NULL,
time float NOT NULL,
cost decimal(9,5) NOT NULL,
updated datetime,
PRIMARY KEY(day,account, service, method)
) ENGINE=InnoDB;
这个表有11万行数据,只有10MB大小,所以可以完全载入内存。service列包含了5个不同的值,平均长度为4个字符,method列包含了71个值,平均产犊为20个字符。
复制一下这个表,但是把service和method字段换成枚举类型,表结构如下:
CREATE TABLE webservicecalls_enum(
...omitted...
service ENUM(... VALUES omitted ...) NOT NULL,
method ENUM(... VALUES omitted ...) NOT NULL,
...omitted...
) ENGINE=InnoDB;
然后我们用主键列关联这两个表,下面是所使用的查询语句:
mysql> SELECT SQL_NO_CACHE COUNT(*) FROM webservicecalls JOIN webservicecalls USING(day, account,service,method);
用VARCHAR和ENUM分别测试了这个语句,结果如表所示
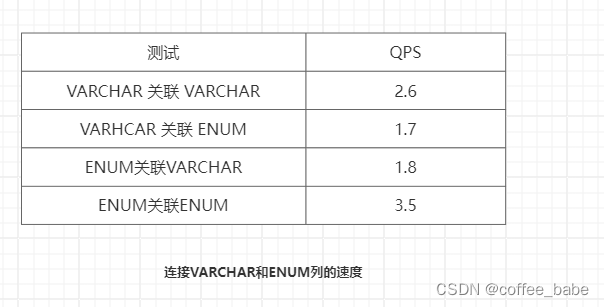
从上面的结果可以看到,当把列都转换成ENUM以后,关联变得很快。但是当VARCHAR列和ENUM列进行关联时则慢很多。在本例中,如果不是必须和VARCHAR列进行关联,那么转换这些列为ENUM就是个好主意。这是一个通用的设计时间,在"查找表"时采用整数主键而避免采用基于字符串的值进行关联。然而,转换列为枚举型还有另外一个好处。根据SHOW TABLE STATUS命令输出结果中Data_length列的值,把这两列转换为ENUM可以让表的大小缩小1/3.在某些情况下,即使可能出现ENUM和VARCHAR进行关联的情况,这也是值得的(这很可能可以节省IO)。同样,转换后主键也只有原来的一半大小了,因为这是InnoDB表,如果表上有其他索引,减小主键大小会使得非主键索引也变得更小。

(该图只是查询Data_length,与上面的例子无关)


![[算法] 优先算法(二): 双指针算法(下)](https://img-blog.csdnimg.cn/direct/faa2316641af4e9abcb5e476dc352d2f.jpeg)