Pytest测试框架是动态语言Python专用的测试框架,使用起来非常的简单,这主要得易于它的设计,Pytest测试框架具备强大的功能,丰富的第三方插件,以及可扩展性好,可以很好的和unittest测试框架能够结合起来在项目中使用。本文章主要介绍Pytest测试框架中参数化的详细信息。
参数化的本质是对列表中的对象进行循环,然后把循环的对象进行一一的赋值,它的应用场景主要是基于相同的业务场景,但是需要不同的测试数据来测试从而达到最大化的覆盖更多的业务场景和测试的覆盖率。理解了这样的一个思想之后,我们就以两个数想加作为案例,来演示Pytest测试框架的参数化实际应用,另外一点需要特别说的是在Pytest测试框架中参数化使用的方式是通过装饰器的方式来进行。刚才也说到它的本质是对列表中的对象进行循环和赋值,那么这个对象可以是列表,也可以是元组以及和字典数据类型,见如下的实战案例,把测试的数据分离到不同的对象中(列表,元组,字典),源码如下:
#!/usr/bin/env python
#!coding:utf-8
import pytest
def add(a,b):
return a+b
@pytest.mark.parametrize('a,b,expect',[
[1,1,2],
[2,2,4],
[3,3,6],
[4,4,8],
[5,5,10]
])
def test_add_list(a,b,expect):
assert add(a,b)==expect
@pytest.mark.parametrize('a,b,expect',[
(1,1,2),
(2,2,4),
(3,3,6),
(4,4,8),
(5,5,10)
])
def test_add_tuple(a,b,expect):
assert add(a,b)==expect
@pytest.mark.parametrize('data',[
{'a':1,'b':1,'expect':2},
{'a':5,'b':5,'expect':10}
])
def test_add_dict(data):
assert add(data['a'],data['b'])==data['expect']
if __name__ == '__main__':
pytest.main(["-s","-v","test_one.py"])执行后的结果信息如下: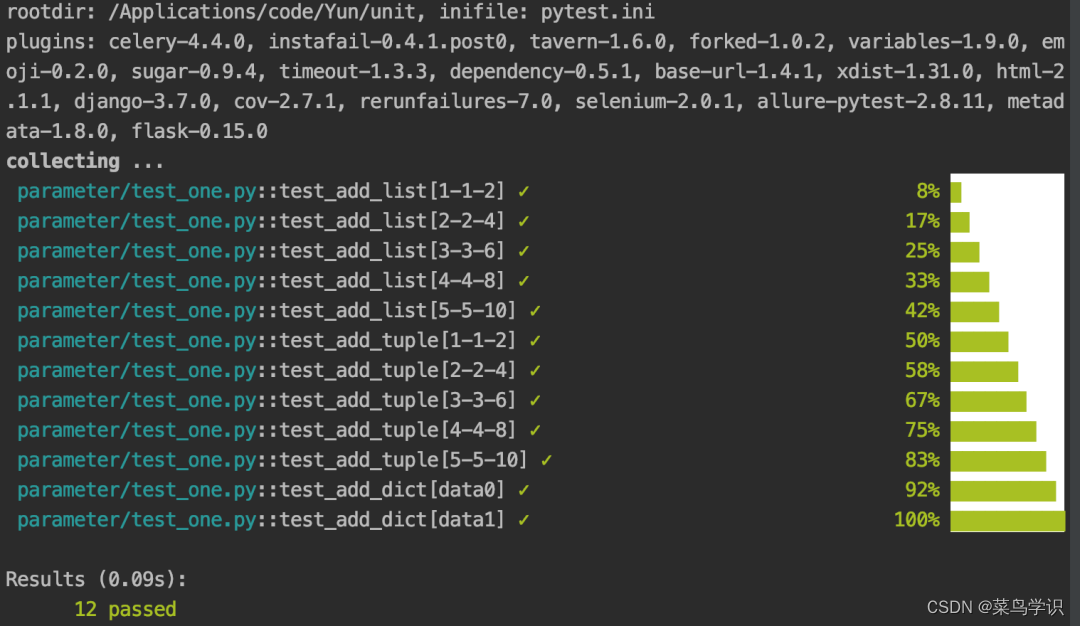
在如上的结果信息中,可以看到真正实现测试用例的代码是很少的,而且把参数化使用到的数据分离到不同的数据类型中。
下面结合API的测试场景来考虑,被测试的API的代码如下:
#!/usr/bin/env python
#!coding:utf-8
from flask import Flask,jsonify
from flask_restful import Api,Resource,reqparse
app=Flask(__name__)
api=Api(app)
class LoginView(Resource):
def get(self):
return {'status':0,'msg':'ok','data':'this is a login page'}
def post(self):
parser=reqparse.RequestParser()
parser.add_argument('username', type=str, required=True, help='用户名不能为空')
parser.add_argument('password',type=str,required=True,help='账户密码不能为空')
parser.add_argument('age',type=int,help='年龄必须为正正数')
parser.add_argument('sex',type=str,help='性别只能是男或者女',choices=['女','男'])
args=parser.parse_args()
return jsonify(args)
api.add_resource(LoginView,'/login',endpoint='login')
if __name__ == '__main__':
app.run(debug=True)在基于API测试维度的思想,针对该接口测试我们不考虑接口的安全性,高并发以及它的稳定性方面,单纯的只是从功能层面来考虑进行测试,那么需要针对每个参数是否缺少都得需要进行验证,就会涉及到五个测试用例的设计,我们把数据分别分离到主流的文件中,文件的格式主要为JSON,Yaml,Excel和CSV的文件,先来看分离到JSON的文件内容:
{
"item":
[
{
"request":
{
"url": "http://localhost:5000/login",
"body":
{
"password":"admin",
"sex":"男",
"age":18
}
},
"response":
[
{
"message":
{
"username": "用户名不能为空"
}
}
]
},
{
"request":
{
"url": "http://localhost:5000/login",
"body":
{
"username":"wuya",
"sex":"男",
"age":18
}
},
"response":
[
{
"message":
{
"password": "账户密码不能为空"
}
}
]
},
{
"request":
{
"url": "http://localhost:5000/login",
"body":
{
"username":"wuya",
"password":"admin",
"sex":"asdf",
"age":18
}
},
"response":
[
{
"message":
{
"sex": "性别只能是男或者女"
}
}
]
},
{
"request":
{
"url": "http://localhost:5000/login",
"body":
{
"username":"wuya",
"password":"admin",
"sex":"男",
"age":"rrest"
}
},
"response":
[
{
"message":
{
"age": "年龄必须为正正数"
}
}
]
},
{
"request":
{
"url": "http://localhost:5000/login",
"body":
{
"username":"wuya",
"password":"admin",
"sex":"男",
"age":"18"
}
},
"response":
[
{
"age": 18,
"password": "admin",
"sex": "男",
"username": "wuya"
}
]
}
]
}涉及到的测试代码为:
#!/usr/bin/env python
#!coding:utf-8
import pytest
import requests
import json
def readJson():
return json.load(open('login.json','r'))['item']
@pytest.mark.parametrize('data',readJson())
def test_json_login(data):
r=requests.post(
url=data['request']['url'],
json=data['request']['body'])
assert r.json()==data['response'][0]
if __name__ == '__main__':
pytest.main(["-s","-v","test_json_login.py"])再来看分离到Yaml文件的数据:
---
#用户名请求为空
"url": "http://localhost:5000/login"
"body": '{
"password":"admin",
"sex":"男",
"age":18
}'
"expect": '{
"message": {
"username": "用户名不能为空"
}
}'
---
#密码参数为空
"url": "http://localhost:5000/login"
"body": '{
"username":"admin",
"sex":"男",
"age":18
}'
"expect": '{
"message": {
"password": "账户密码不能为空"
}
}'
---
#校验性别参数的验证
"url": "http://localhost:5000/login"
"body": '{
"username":"wuya",
"password":"admin",
"sex":"asdf",
"age":18
}'
expect: '{
"message": {
"sex": "性别只能是男或者女"
}
}'
---
#校验年龄是否是正整数
"url": "http://localhost:5000/login"
"body": '{
"username":"wuya",
"password":"admin",
"sex":"男",
"age":"rrest"
}'
"expect": '{
"message": {
"age": "年龄必须为正正数"
}
}'
---
#登录成功
"url": "http://localhost:5000/login"
"body": '{
"username":"wuya",
"password":"admin",
"sex":"男",
"age":"18"
}'
"expect": '{
"age": 18,
"password": "admin",
"sex": "男",
"username": "wuya"
}'涉及到的测试代码为:
#!/usr/bin/env python
#!coding:utf-8
import pytest
import requests
import yaml
def readYaml():
with open('login.yaml','r') as f:
return list(yaml.safe_load_all(f))
@pytest.mark.parametrize('data',readYaml())
def test_login(data):
r=requests.post(
url=data['url'],
json=json.loads(data['body']))
assert r.json()==json.loads(data['expect'])
分离到CSV的文件内容为:

涉及到的测试代码为:
#!/usr/bin/env python
#!coding:utf-8
import pytest
import requests
import csv
def readCsv():
data=list()
with open('login.csv','r') as f:
reader=csv.reader(f)
next(reader)
for item in reader:
data.append(item)
return data
@pytest.mark.parametrize('data',readCsv())
def test_csv_login(data):
r=requests.post(
url=data[0],
json=json.loads(data[1]))
assert r.json()==json.loads(data[2])最后来看分离到Excel的文件内容:
涉及到的测试代码为:
#!/usr/bin/env python
#!coding:utf-8
import pytest
import requests
import xlrd
def readExcel():
data=list()
book=xlrd.open_workbook('login.xls')
sheet=book.sheet_by_index(0)
for item in range(1,sheet.nrows):
data.append(sheet.row_values(item))
return data
@pytest.mark.parametrize('data',readExcel())
def test_excel_login(data):
r=requests.post(
url=data[0],
json=json.loads(data[1]))
assert r.json()==json.loads(data[2])其实我们发现套路都是一样的,不管把数据分离到什么样的数据格式下,都得符合它的本质思想,也就是参数化的本质是对列表中的对象进行循环赋值,把握住这样的一个思想就可以了。整合上面的所有代码,完整代码为:
#!/usr/bin/env python
#!coding:utf-8
import pytest
import requests
import json
import yaml
import csv
import xlrd
def readJson():
return json.load(open('login.json','r'))['item']
def readYaml():
with open('login.yaml','r') as f:
return list(yaml.safe_load_all(f))
def readCsv():
data=list()
with open('login.csv','r') as f:
reader=csv.reader(f)
next(reader)
for item in reader:
data.append(item)
return data
def readExcel():
data=list()
book=xlrd.open_workbook('login.xls')
sheet=book.sheet_by_index(0)
for item in range(1,sheet.nrows):
data.append(sheet.row_values(item))
return data
@pytest.mark.parametrize('data',readJson())
def test_json_login(data):
r=requests.post(
url=data['request']['url'],
json=data['request']['body'])
assert r.json()==data['response'][0]
@pytest.mark.parametrize('data',readYaml())
def test_yaml_login(data):
r=requests.post(
url=data['url'],
json=json.loads(data['body']))
assert r.json()==json.loads(data['expect'])
@pytest.mark.parametrize('data',readCsv())
def test_csv_login(data):
r=requests.post(
url=data[0],
json=json.loads(data[1]))
assert r.json()==json.loads(data[2])
@pytest.mark.parametrize('data',readExcel())
def test_excel_login(data):
r=requests.post(
url=data[0],
json=json.loads(data[1]))
assert r.json()==json.loads(data[2])执行后的结果信息为: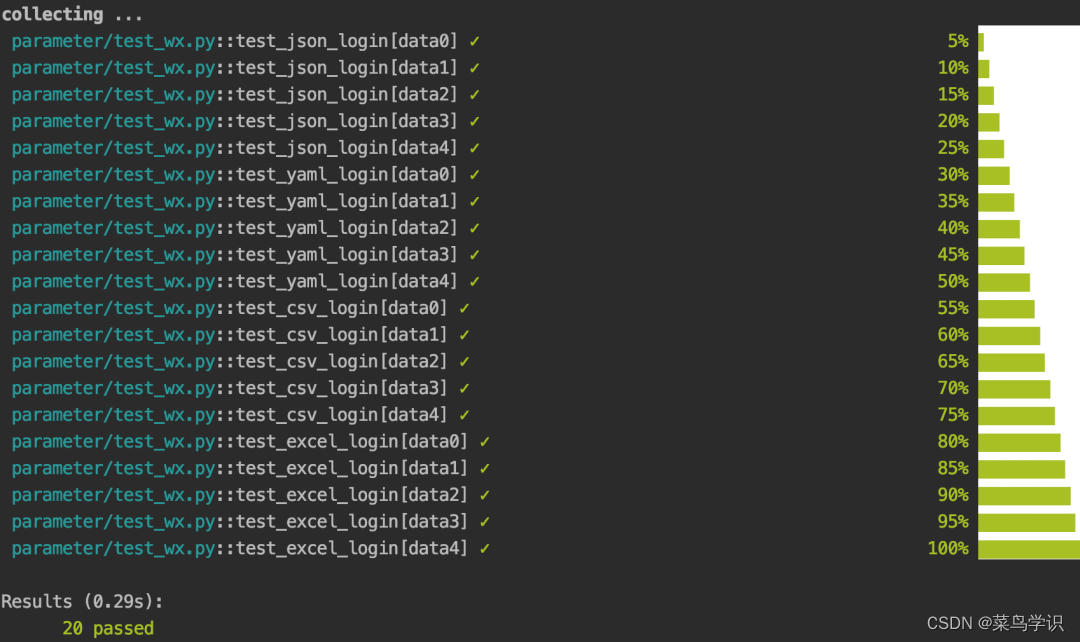
Pytest测试框架最强大的功能除了丰富的第三方插件外,还有就是它的Fixture和共享Fixture的conftest.py,下面具体来看被测试的接口代码:
from flask import Flask,make_response,jsonify,abort,request
from flask_restful import Api,Resource
from flask_httpauth import HTTPBasicAuth
from flask import Flask
from flask_jwt import JWT, jwt_required, current_identity
from werkzeug.security import safe_str_cmp
app=Flask(__name__)
app.debug = True
app.config['SECRET_KEY'] = 'super-secret'
api=Api(app=app)
auth=HTTPBasicAuth()
@auth.get_password
def get_password(name):
if name=='admin':
return 'admin'
@auth.error_handler
def authoorized():
return make_response(jsonify({'msg':"请认证"}),403)
books=[
{'id':1,'author':'wuya','name':'Python接口自动化测试实战','done':True},
{'id':2,'author':'无涯','name':'Selenium3自动化测试实战','done':False}
]
class User(object):
def __init__(self, id, username, password):
self.id = id
self.username = username
self.password = password
def __str__(self):
return "User(id='%s')" % self.id
users = [
User(1, 'wuya', 'asd888'),
User(2, 'admin', 'admin'),
]
username_table = {u.username: u for u in users}
userid_table = {u.id: u for u in users}
def authenticate(username, password):
user = username_table.get(username, None)
if user and safe_str_cmp(user.password.encode('utf-8'), password.encode('utf-8')):
return user
def identity(payload):
user_id = payload['identity']
return userid_table.get(user_id, None)
jwt = JWT(app, authenticate, identity)
class Books(Resource):
# decorators = [auth.login_required]
decorators=[jwt_required()]
def get(self):
return jsonify({'status':0,'msg':'ok','datas':books})
def post(self):
if not request.json:
return jsonify({'status':1001,'msg':'请求参数不是JSON的数据,请检查,谢谢!'})
else:
book = {
'id': books[-1]['id'] + 1,
'author': request.json.get('author'),
'name': request.json.get('name'),
'done': True
}
books.append(book)
return jsonify({'status':1002,'msg': '添加书籍成功','datas':book}, 201)
class Book(Resource):
# decorators = [auth.login_required]
# decorators = [jwt_required()]
def get(self,book_id):
book = list(filter(lambda t: t['id'] == book_id, books))
if len(book) == 0:
return jsonify({'status': 1003, 'msg': '很抱歉,您查询的书的信息不存在'})
else:
return jsonify({'status': 0, 'msg': 'ok', 'datas': book})
def put(self,book_id):
book = list(filter(lambda t: t['id'] == book_id, books))
if len(book) == 0:
return jsonify({'status': 1003, 'msg': '很抱歉,您查询的书的信息不存在'})
elif not request.json:
return jsonify({'status': 1001, 'msg': '请求参数不是JSON的数据,请检查,谢谢!'})
elif 'author' not in request.json:
return jsonify({'status': 1004, 'msg': '请求参数author不能为空'})
elif 'name' not in request.json:
return jsonify({'status': 1005, 'msg': '请求参数name不能为空'})
elif 'done' not in request.json:
return jsonify({'status': 1006, 'msg': '请求参数done不能为空'})
elif type(request.json['done'])!=bool:
return jsonify({'status': 1007, 'msg': '请求参数done为bool类型'})
else:
book[0]['author'] = request.json.get('author', book[0]['author'])
book[0]['name'] = request.json.get('name', book[0]['name'])
book[0]['done'] = request.json.get('done', book[0]['done'])
return jsonify({'status': 1008, 'msg': '更新书的信息成功', 'datas': book})
def delete(self,book_id):
book = list(filter(lambda t: t['id'] == book_id, books))
if len(book) == 0:
return jsonify({'status': 1003, 'msg': '很抱歉,您查询的书的信息不存在'})
else:
books.remove(book[0])
return jsonify({'status': 1009, 'msg': '删除书籍成功'})
api.add_resource(Books,'/v1/api/books')
api.add_resource(Book,'/v1/api/book/<int:book_id>')
if __name__ == '__main__':
app.run(debug=True)我们通过token的方式,首先需要授权,授权成功后才可以针对书籍这些接口进行操作,如添加删除以及查看所有的书籍信息,那么获取token这部分的代码完全可以放在conftest.py里面,具体源码为:
#!/usr/bin/env python
#!coding:utf-8
import requests
import pytest
@pytest.fixture()
def getToken():
'''获取token'''
r=requests.post(
url='http://localhost:5000/auth',
json={"username":"wuya","password":"asd888"})
return r.json()['access_token']Fixture一点需要考虑的是初始化与清理,也就是说在一个完整的测试用例中,都必须都得有初始化与清理的部分,这样才是一个完整的测试用例的。Fixture可以很轻松的来解决这部分,还有一点需要说的是Fixture的函数也可以和返回值整合起来,如添加书籍成功后,把数据ID返回来,下面就以查看书籍为案例,那么查看书籍前提是需要添加书籍,这样可以查看,最后把添加的书籍删除,这样一个测试用例执行完成后才符合它的完整流程,具体测试代码如下:
#!/usr/bin/env python
#!coding:utf-8
import pytest
import requests
def writeBookID(bookID):
with open('bookID','w') as f:
f.write(str(bookID))
@pytest.fixture()
def getBookID():
with open('bookID','r') as f:
return f.read()
def addBook(getToken):
r=requests.post(
url='http://localhost:5000/v1/api/books',
json={"author": "wuya","done": False,"name": "Selenium3自动化测试实战"},
headers={'Authorization':'JWT {0}'.format(getToken)})
print('添加书籍:\n',r.json())
writeBookID(r.json()[0]['datas']['id'])
def delBook(getToken,getBookID):
r=requests.delete(
url='http://localhost:5000/v1/api/book/{0}'.format(getBookID),
headers={'Authorization':'JWT {0}'.format(getToken)})
print('删除书籍:\n',r.json())
@pytest.fixture()
def init(getToken,getBookID):
addBook(getToken)
yield
delBook(getToken,getBookID)
def test_get_book(init,getToken,getBookID):
r=requests.get(
url='http://localhost:5000/v1/api/book/{0}'.format(getBookID),
headers={'Authorization':'JWT {0}'.format(getToken)})
print('查看书籍:\n',r.json())在如上的代码中可以看到,我们刻意了写了init的Fixture函数,就是使用了它的初始化与清理的思想,当然还可以结合内置的Fixture把代码改造为如下的部分:
#!/usr/bin/env python
#!coding:utf-8
import pytest
import requests
import allure
@allure.step
def addBook(getToken):
r=requests.post(
url='http://localhost:5000/v1/api/books',
json={"author": "无涯","done": False,"name": "Selenium3自动化测试实战"},
headers={'Authorization':'JWT {0}'.format(getToken)})
print('添加书籍:\n',r.json())
return r.json()[0]['datas']['id']
@allure.step
def delBook(getToken,bookID):
r=requests.delete(
url='http://localhost:5000/v1/api/book/{0}'.format(bookID),
headers={'Authorization':'JWT {0}'.format(getToken)})
print('删除书籍:\n',r.json())
def test_get_book(getToken,tmpdir):
f=tmpdir.join('bookid.txt')
f.write(addBook(getToken))
r=requests.get(
url='http://localhost:5000/v1/api/book/{0}'.format(f.read()),
headers={'Authorization':'JWT {0}'.format(getToken)})
delBook(getToken=getToken,bookID=f.read())
print('查看书籍:\n',r.json())