概述
本案例是基于之前的岭回归的案例的。之前案例的完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, LinearRegression
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.model_selection import learning_curve, KFold
def plot_learning_curve(est, X, y):
# 将数据拆分20次用来对模型进行评分
training_set_size, train_scores, test_scores = learning_curve(
est,
X,
y,
train_sizes=np.linspace(.1, 1, 20),
cv=KFold(20, shuffle=True, random_state=1)
)
# 获取模型名称
estimator_name = est.__class__.__name__
# 绘制模型评分
line = plt.plot(training_set_size, train_scores.mean(axis=1), "--", label="training " + estimator_name)
plt.plot(training_set_size, test_scores.mean(axis=1), "-", label="test " + estimator_name, c=line[0].get_color())
plt.xlabel("Training set size")
plt.ylabel("Score")
plt.ylim(0, 1.1)
# 加载数据
data = load_diabetes()
X, y = data.data, data.target
# 绘制图形
plot_learning_curve(Ridge(alpha=1), X, y)
plot_learning_curve(LinearRegression(), X, y)
plt.legend(loc=(0, 1.05), ncol=2, fontsize=11)
plt.show()
输出结果如下:

套索回归的基本用法
引入套索回归,还是基于糖尿病数据,进行模型的训练。
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np
# 加载数据
data = load_diabetes()
X, y = data.data, data.target
# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)
# 使用套索回归拟合数据
reg = Lasso().fit(X_train, y_train)
# 查看结果
print(reg.score(X_train, y_train))
print(reg.score(X_test, y_test))
print(np.sum(reg.coef_ != 0))
输出结果如下:
0.3624222204154225
0.36561940472905163
3
调整套索回归的参数
上面的案例中,评分只有0.3,很低,我们可以试试调低alpha的值试试。
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np
# 加载数据
data = load_diabetes()
X, y = data.data, data.target
# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)
# 使用套索回归拟合数据
reg = Lasso(alpha=0.1, max_iter=100000).fit(X_train, y_train)
# 查看结果
print(reg.score(X_train, y_train))
print(reg.score(X_test, y_test))
print(np.sum(reg.coef_ != 0))
输出如下:
0.5194790915052719
0.4799480078849704
7
可以发现,评分有所增长,10个特征中,这里用到了7个特征。
过拟合问题
如果我们把alpha的值设置得太低,就相当于把正则化的效果去除了,模型就会出现过拟合问题。
比如,我们将alpha设置为0.0001:
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np
# 加载数据
data = load_diabetes()
X, y = data.data, data.target
# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)
# 使用套索回归拟合数据
reg = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)
# 查看结果
print(reg.score(X_train, y_train))
print(reg.score(X_test, y_test))
print(np.sum(reg.coef_ != 0))
输出如下:
0.5303797950529495
0.4594491492143349
10
从结果来看,我们用到了全部特征,而且模型在测试集上的分数要稍微低于alpha等于0.1的时候的得分,说明降低alpha的数值会让模型倾向于出现过拟合的现象。
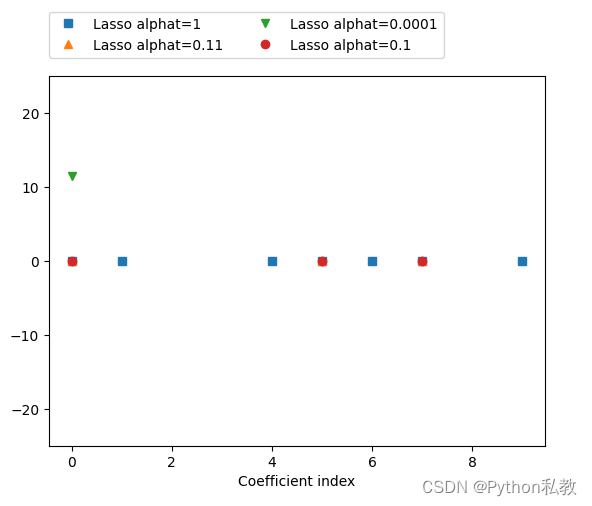
套索回归和岭回归的对比
我们采用图像的形式,来对比不同alpha的值的时候,套索回归和岭回归的系数。
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np
# 加载数据
data = load_diabetes()
X, y = data.data, data.target
# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)
# 使用套索回归拟合数据并绘图
reg = Lasso(alpha=1, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "s", label="Lasso alphat=1")
reg = Lasso(alpha=0.11, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "^", label="Lasso alphat=0.11")
reg = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "v", label="Lasso alphat=0.0001")
reg = Lasso(alpha=0.1, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "o", label="Lasso alphat=0.1")
plt.legend(ncol=2,loc=(0,1.05))
plt.ylim(-25,25)
plt.xlabel("Coefficient index")
plt.show()
输出: