文章目录
图的遍历
考纲内容
复习提示
1.广度优先搜索
1.1BFS算法的性能分析
1.2BFS算法求解单源最短路径问题
1.3广度优先生成树
2.深度优先搜索
2.1DFS算法的性能分析
2.2深度优先的生成树和生成森林
3.图的遍历与图的连通性
4.知识回顾
图的遍历
考纲内容
(一)图的基本概念
(二)图的存储及基本操作
邻接矩阵;邻接表;邻接多重表;十字链表
(三)图的遍历
深度优先搜索;广度优先搜索
(四)图的基本应用
最小(代价)生成树;最短路径;拓扑排序;关键路径
复习提示
图算法的难度较大,主要掌握深度优先搜索与广度优先搜索。掌握图的基本概念及基本性质、图的存储结构(邻接矩阵、邻接表、邻接多重表和十字链表)及特性、存储结构之间的转化、基于存储结构上的各种遍历操作和各种应用(拓扑排序、最小生成树、最短路径和关键路径)等。
图的相关算法较多,通常只需掌握其基本思想和实现步骤,而实现代码不是重点。
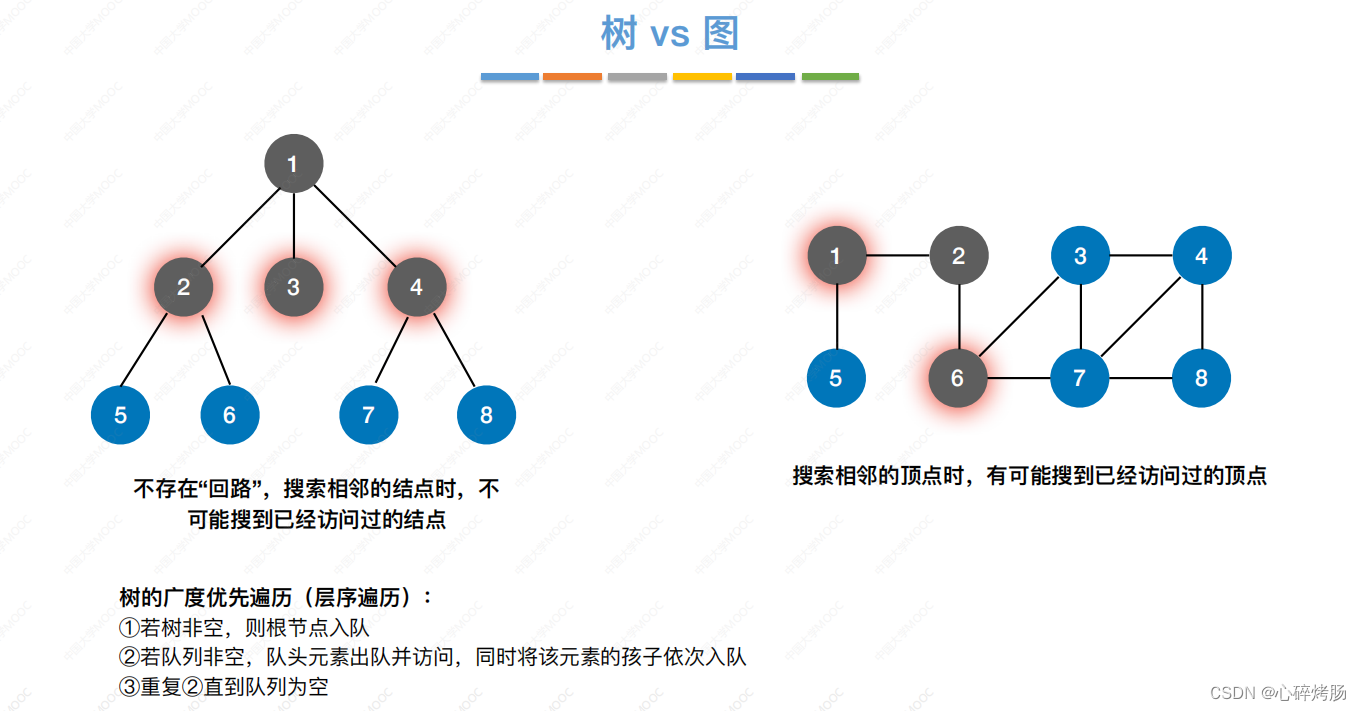
图的遍历是指从图中的某一顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点访问一次,且仅访问一次。
注意到树是一种特殊的图,所以树的遍历实际上也可视为一种特殊的图的遍历。
图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础。
图的遍历比树的遍历要复杂得多,因为图的任意一个顶点都可能和其余的顶点相邻接,所以在访问某个顶点后,可能沿着某条路径搜索又回到该顶点。
为避免同一顶点被访问多次,在遍历图的过程中,必须记下每个已访问过的顶点,为此可以设一个辅助数组 visited[ ]来标记顶点是否被访问过。
图的遍历算法主要有两种:广度优先搜索和深度优先搜索。
1.广度优先搜索
广度优先搜索(Breadth-First-Search,BFS)类似于二叉树的层序遍历算法。
基本思想是:
首先访问起始顶点v,接着由v出发,依次访问v的各个未访问过的邻接顶点,然后依次访问
的所有未被访问过的邻接顶点;
再从这些访问过的顶点出发,访问它们所有未被访问过的邻接顶点,直至图中所有顶点都被访问过为止。
若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作为始点,重复上述过程,直至图中所有顶点都被访问到为止。
Dijkstra 单源最短路径算法和 Prim 最小生成树算法也应用了类似的思想。
换句话说,广度优先搜索遍历图的过程是以v为起始点,由近至远依次访问和v有路径相通且路径长度为 1,2,.…的顶点。
广度优先搜索是一种分层的査找过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有往回退的情况,因此它不是一个递归的算法。
为了实现逐层的访问,算法必须借助一个辅助队列,以记忆正在访问的顶点的下一层顶点。
广度优先搜索算法的伪代码如下:
bool visited[MAX_VERTEX_NUM]; //访问标记数组
void BFSTraverse(Graph G){ //对图 G进行广度优先遍历
for(i=0;i<G.vexnum;++i)
visited[i]=FALSE; //访问标记数组初始化
InitQueue(Q); //初始化辅助队列 Q
for(i=0;i<G.vexnum;++i) //从0号顶点开始遍历
if(!visited[i]) //对每个连通分量调用一次 BES()
BFS(G,i); //若v未访问过,从v开始调用 BFS()
}用邻接表实现广度优先搜索的算法如下:
void BFS(ALGraph G,int i){
visit(i); //访问初始顶点i
visited[i]=TRUE; //对i做已访问标记
EnQueue(Q,i); //顶点i入队
while(!IsEmpty(Q)){
DeQueue(Q,v); //队首顶点v出队
for (p=G.vertices[v].firstarc;p;p=p->nextarc){ //检测v的所有邻接点
w=p->adjvex;
if(visited[w]==FALSE){
visit(w); //w为v的尚未访问的邻接点,访问w
visited[w]=TRUE; //对w做已访问标记
EnQueue(Q,w); //顶点w入队
}
}
}
}用邻接矩阵实现广度优先搜索的算法如下:
void BFS(MGraph G,int i){
visit(i); //访问初始顶点i
visited[i]=TRUE; //对i做已访问标记
EnQueue(Q,i); //顶点i入队
while(!IsEmpty(Q)){
DeQueue(Q,v); //队首顶点v出队
for(w=0;w<G.vexnum;w++) //检测v的所有邻接点
if(visited[w]==FALSE&&G.edge[v][w]==1){
visit(w); //w为v的尚未访问的邻接点,访问w
visited[w]=TRUE; //对w做已访问标记
EnQueue(Q,w); //顶点w入队
}
}
}辅助数组 visited[ ]标志顶点是否被访问过,其初始状态为FALSE。在图的遍历过程中,一旦某个顶点被访问,就立即置 visited[i]为TRUE,防止它被多次访问。
【命题追踪——广度优先遍历的过程】
下面通过实例演示广度优先搜索的过程,给定图G如图6.11所示。
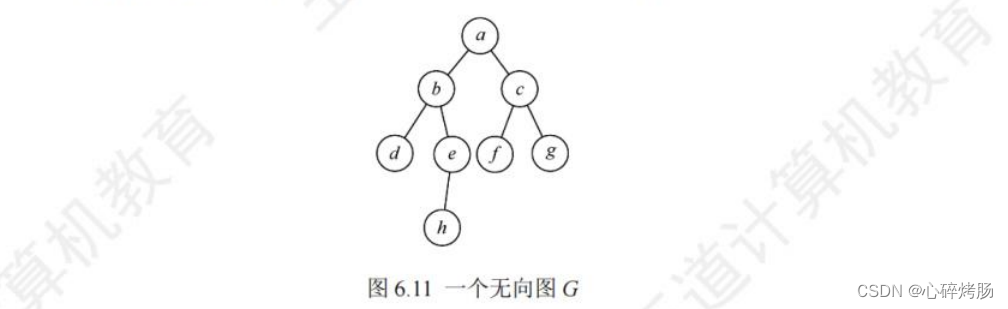
- 假设从顶点a开始访问,a先入队。此时队列非空,取出队头元素a,因为b,c与a邻接且未被访问过,于是依次访问bc,并将b,c依次入队。
- 队列非空,取出队头元素b,依次访问与b邻接且未被访问的顶点d,e,并将d,e入队(注意:a与b也邻接,但a已置访问标记,所以不再重复访问)。
- 此时队列非空,取出队头元素c,访问与c邻接且未被访问的顶点f,g,并将f,g入队。
- 此时,取出队头元素 d,但与d邻接且未被访问的顶点为空,所以不进行任何操作。
- 继续取出队头元素e,将h入队列……最终取出队头元素h后,队列为空,从而循环自动跳出。
- 遍历结果为 abcdefgh。
从上例不难看出,图的广度优先搜索的过程与二叉树的层序遍历是完全一致的,这也说明了图的广度优先搜索遍历算法是二叉树的层次遍历算法的扩展。
1.1BFS算法的性能分析
无论是邻接表还是邻接矩阵的存储方式,BFS算法都需要借助一个辅助队列Q,n个顶点均需入队一次,在最坏的情况下,空间复杂度为O(|V|)。
【命题追踪——基于邻接表存储的BFS的效率】
遍历图的过程实质上是对每个顶点查找其邻接点的过程,耗费的时间取决于所采用的存储结构。
采用邻接表存储时,每个顶点均需搜索(或入队)一次,时间复杂度为 O(|V|),
在搜索每个顶点的邻接点时,每条边至少访问一次,时间复杂度为 O(|E|),总的时间复杂度为 O(|V|+|E|)。
采用邻接矩阵存储时,查找每个顶点的邻接点所需的时间为 O(|V|),总时间复杂度为 O(|V|²)。
1.2BFS算法求解单源最短路径问题
若图 G=(V,E)为非带权图,定义从顶点u到顶点v的最短路径 d(u,v)为从u到v的任何路径中最少的边数;
若从u到v没有通路,则d(u,v)=∞。
使用 BFS,我们可以求解一个满足上述定义的非带权图的单源最短路径问题,这是由广度优先搜索总是按照距离由近到远来遍历图中每个顶点的性质决定的。
BFS算法求解单源最短路径问题的算法如下:
void BFS_MIN_Distance(Graph G,int u){
//d[i]表示从u到i结点的最短路径
for(i=0;i<G.vexnum;++i)
d [i]=∞; //初始化路径长度
visited[u]=TRUE;d[u]=0;
EnQueue(Q,u);
while(!isEmpty(Q)){ //BFS 算法主过程
DeQueue(Q,u); //队头元素u出队
for(w=FirstNeighbor(G,u);w>=0;w=NextNeighbor(G,u,w))
if(!visited[w]){ //w为u的尚未访问的邻接顶点
visited[w]=TRUE ; //设已访问标记
d[w]=d[u]+1; //路径长度加1
EnQueue(Q,w); //顶点w入队
}
}
}1.3广度优先生成树
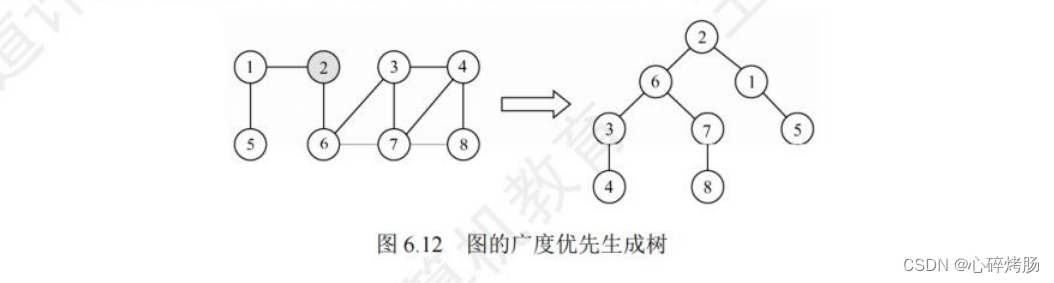
在广度遍历的过程中,我们可以得到一棵遍历树,称为广度优先生成树,如图6.12所示。
需要注意的是:
同一个图的邻接矩阵存储表示是唯一的,所以其广度优先生成树也是唯一的,
但因为邻接表存储表示不唯一,所以其广度优先生成树也是不唯一的。
2.深度优先搜索
与广度优先搜索不同,深度优先搜索(Depth-First-Search,DFS)类似于树的先序遍历。
如其名称中所暗含的意思一样,这种搜索算法所遵循的策略是尽可能“深”地搜索一个图。
它的基本思想如下:
首先访问图中某一起始顶点,然后由v出发,访问与v邻接且未被访问的任意一个顶点,再访问与
邻接且未被访问的任意一个顶点
……重复上述过程。
当不能再继续向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直至图中所有顶点均被访问过为止。
一般情况下,其递归形式的算法十分简洁,算法过程如下:
bool visited[MAX_VERTEX_NUM]; //访问标记数组
void DFSTraverse(Graph G){ //对图G进行深度优先遍历
for(i=0;i<G.vexnum;i++)
visited[i]=FALSE; //初始化已访问标记数组
for(i=0;i<G.vexnum;i++) //本代码中是从开始遍历
if(!visited[i]) //对尚未访问的顶点调用DFS()
DES(G,i);
}用邻接表实现深度优先搜索的算法如下:
void DES(ALGraph G,int i){
visit(i); //访问初始顶点i
visited[i]=TRUE; //对i做已访问标记
for(p=G.vertices[i].firstarc;p;p=p->nextarc){ //检测i的所有邻接点
j=p->adjvex;
if(visited[j]==FALSE)
DFS (G,j); //j为i的尚未访问的邻接点,递归访问
}
}
用邻接矩阵实现深度优先搜索的算法如下:
void DFS (MGraph G,int i){
visit(i); //访问初始顶点i
visited[i]=TRUE; //对i做已访问标记
for(j=0;j<G.vexnum;j++){ //检测i的所有邻接点
if(visited[j]==FALSE && G.edge[i][j]==1)
DFS(G,j); //j为i的尚未访问的邻接点,递归访问了j
}
}【命题追踪——深度优先遍历的过程】
以图 6.11的无向图为例,深度优先搜索的过程:
- 首先访问a,并置a访问标记;
- 然后访问与a邻接且未被访问的顶点b,置b访问标记;
- 然后访问与b邻接且未被访问的顶点 d,置 d访问标记。
- 此时d已没有未被访问过的邻接点,所以返回上一个访问的顶点b,访问与其邻接且未被访问的顶点e,置e访问标记,
- 以此类推,直至图中所有顶点都被访问一次。
- 遍历结果为 abdehcfg。
注意:
图的邻接矩阵表示是唯一的,但对邻接表来说,若边的输入次序不同,则生成的邻接表也不同。
因此,对同样一个图,基于邻接矩阵的遍历得到的 DFS序列和 BFS 序列是唯一的,
基于邻接表的遍历得到的 DFS序列和 BFS 序列是不唯一的。
2.1DFS算法的性能分析
DFS 算法是一个递归算法,需要借助一个递归工作栈,所以其空间复杂度为 O(|V|)。
遍历图的过程实质上是通过边查找邻接点的过程,因此两种遍历方式的时间复杂度都相同,不同之处仅在于对顶点访问顺序的不同。
采用邻接矩阵存储时,总时间复杂度为 O(|V|²)。
采用邻接表存储时,总的时间复杂度为 O(|V|+|E|)。
2.2深度优先的生成树和生成森林
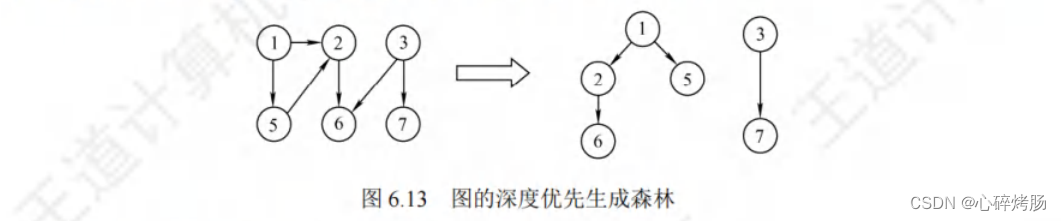
与广度优先搜索一样,深度优先搜索也会产生一棵深度优先生成树。当然,这是有条件的,
即对连通图调用 DFS才能产生深度优先生成树,否则产生的将是深度优先生成森林,如图 6.13 所示。
与 BFS 类似,基于邻接表存储的深度优先生成树是不唯一的。
3.图的遍历与图的连通性
图的遍历算法可以用来判断图的连通性。
- 对于无向图来说,若无向图是连通的,则从任意一个结点出发,仅需一次遍历就能够访问图中的所有顶点;
- 若无向图是非连通的,则从某一个顶点出发,一次遍历只能访问到该顶点所在连通分量的所有顶点,而对于图中其他连通分量的顶点,则无法通过这次遍历访问。
- 对于有向图来说,若从初始顶点到图中的每个顶点都有路径,则能够访问到图中的所有顶点,否则不能访问到所有顶点。
因此,在 BFSTraverse()或 DFSTraverse()中添加了第二个 for 循环,再选取初始点,继续进行遍历,以防止一次无法遍历图的所有顶点。
- 对于无向图,上述两个函数调用 BFS(G,i)或 DFS(G,i)的次数等于该图的连通分量数;
- 而对于有向图则不是这样,因为一个连通的有向图分为强连通的和非强连通的,它的连通子图也分为强连通分量和非强连通分量,非强连通分量一次调用 BFS (G,i)或 DFS (G,i)无法访问到该连通分量的所有顶点,如图 6.14所示。

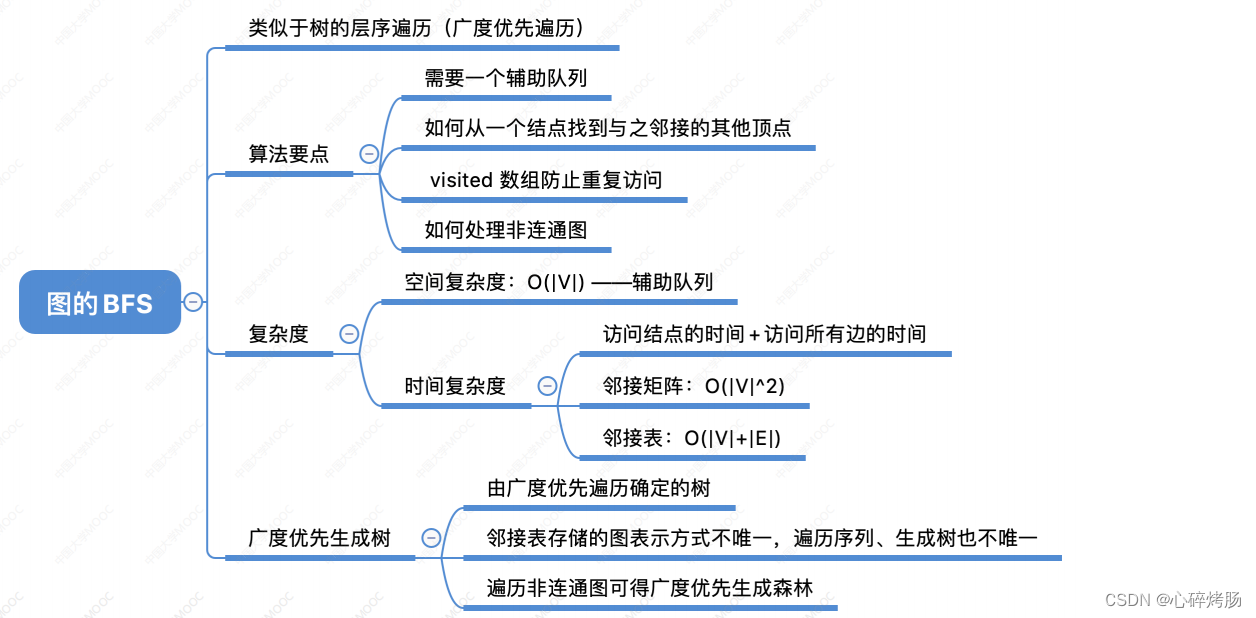
4.知识回顾





![[牛客网]——C语言刷题day4](https://img-blog.csdnimg.cn/direct/f645835f7037497099f6a77ed52cd21d.png)