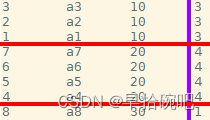
-- 窗口范围是整个表-- 按照age排序,每阶段的age数据进行统计求和.select id,name,age,count()over(orderby age)as n from wt1;
相同字段分区、排序
-- 窗口范围是表下按照age进行分区-- 在分区里面,再按照age进行排序select id,name,age,count()over(partitionby age orderby age)as n from wt1;-- 若分区和排序是同一字段时,可以省略order by语句.
不同字段分区、排序
-- 窗口范围是表下按照age进行分区-- 在分区里面,再按照id进行排序select id,name,age,count()over(partitionby age orderby id)as n from wt1;-- 可以根据需要对order by进行asc,desc
序列函数
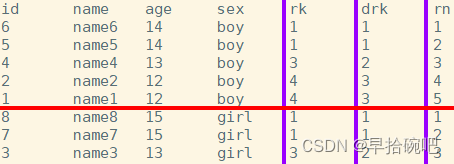
rank
会对相同数值,输出相同的序号,而且下一个序号间断, 如:1、1、3、3、5. rank(等级)
dense_rank
会对相同数值,输出相同的序号,而且下一个序号不间断,如:1、1、2、2、3. dense(稠密的)
row_number
会对所有数值,输出不同的序号,序号唯一且连续,如:1、2、3、4、5.
select id,name,age,sex,
rank()over(partitionby sex orderby age desc)as rk,
dense_rank()over(partitionby sex orderby age desc)as drk,
row_number()over(partitionby sex orderby age desc)as rn
from stu;
行选择函数
-- 语法over(rowsbetween num 函数 and 函数)-- 关键词释义
:'
following
在后N行; following--(时间上)接着的,下述的,下列的.
preceding
在前N行; preceding--在…之前发生(或出现),先于,走在…前面.
unbounded
不限行数; unbounded--无穷的,无尽的,无限的.
current row
当前行; current--现时发生的,当前的,现在的,通用的,流通的,流行的.
'-- 窗口中的整个范围rowsbetweenunboundedprecedingand unbouned following-- 从窗口的前无限行到当前行rowsbetweenunboundedprecedingandcurrentrow-- 从窗口的当前行的前2行到当前行rowsbetween2precedingandcurrentrow-- 从窗口的当前行到当前行的后2行rowsbetweencurrentrowand2following
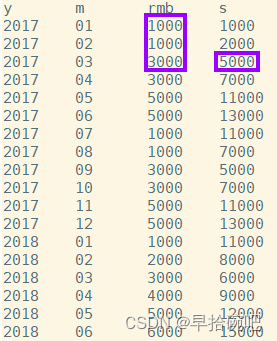
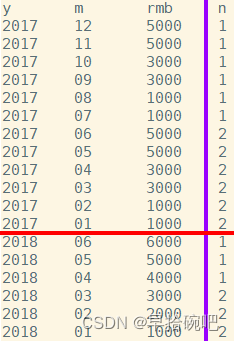
-- 查询当月销售额和近三个月的销售额select y,m,rmb,sum(rmb)over(orderby y,m rowsbetween2precedingandcurrentrow)as s
from sale;-- 从结果可以看出,窗口函数的结果是包括本行在内的前三月的总和.
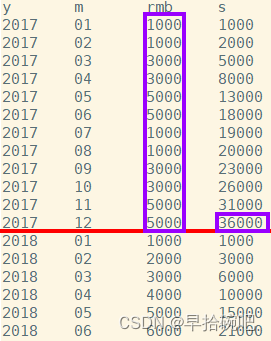
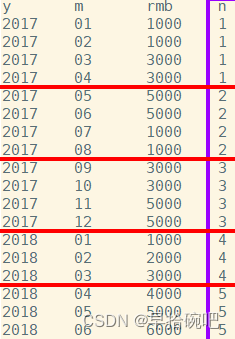
-- 查询当月销售额和今年年初到当月的销售额SELECT y,m,rmb,sum(rmb)over(partitionby y orderby m rowsbetweenunboundedprecedingandcurrentrow)as s
from sale;
值选择函数
-- 上面知道了行选择函数的写法是:sum()over(partitionby xx orderby xx rowsbetween xx and xx)-- 相类似的,值选择函数的写法就是:sum()over(partitionby xx orderby xx range between xx and xx)
• rows是物理窗口,是哪一行就是哪一行,与当前行的值(orderbykey的key的值)无关,只与排序后的行号相关,就是我们常规理解的那样。
• range是逻辑窗口,与当前行的值有关(orderbykey的key的值),在key上操作range范围。
select y,m,rmb,ntile(2)over(partitionby y orderby m desc)as n from sale;
-- 如果切片不均匀,默认增加第一个切片的分布. select y,m,rmb,ntile(5)over(orderby y,m)as n from sale;
lag、lead分析函数
-- lag和lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。-- 这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率,其中over()表示当前查询的结果集对象,括号里面的语句则表示对这个结果集进行处理.-- 函数介绍
LAG
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
参数1为列名,参数2为往上第n行(可选,默认为1),参数3为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
LEAD
与LAG相反
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
参数1为列名,参数2为往下第n行(可选,默认为1),参数3为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL).
select y,m,rmb,
lag(rmb,1)over(partitionby y orderby m)as lag_rmb,
lead(rmb,1)over(partitionby y orderby m)as lead_rmb
from sale;
first_value()、last_value()取值函数
-- first_value() 的结果容易理解,直接在结果的所有行记录中输出同一个满足条件的首个记录;-- last_value() 默认统计范围: rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较,如果需要在结果的所有行记录中输出同一个满足条件的最后一个记录,在order by 条件的后面加上语句:rows between unbounded preceding and unbounded following。
select y,m,rmb,
first_value(rmb)over(partitionby y orderby rmb desc)as rmb_first,
last_value(rmb)over(partitionby y orderby rmb descrowsbetweenunboundedprecedingandunboundedfollowing)as rmb_last
from sale;
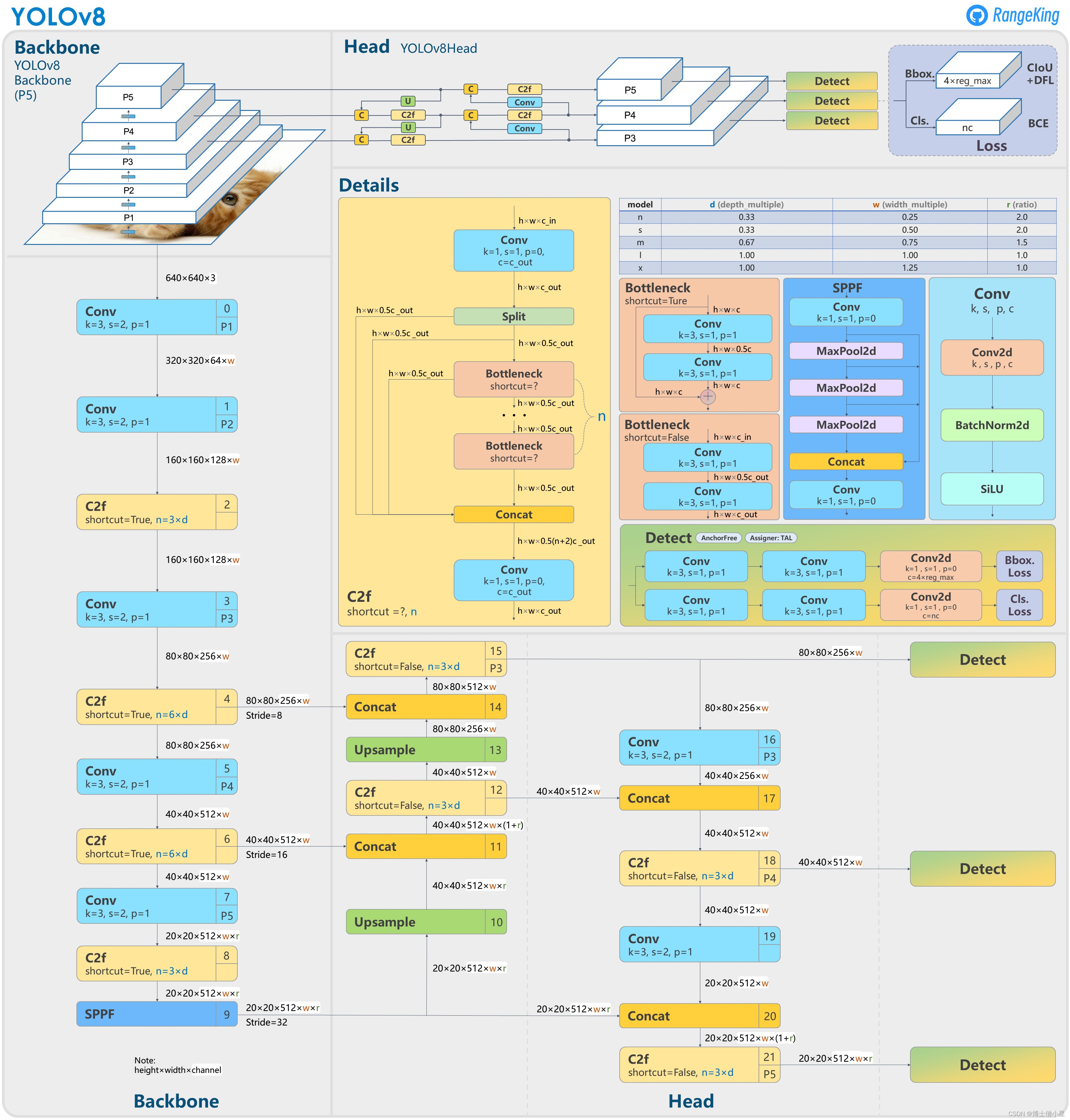
YoloV8相对于YoloV5的改进点: Replace the C3 module with the C2f module.Replace the first 6x6 Conv with 3x3 Conv in the Backbone.Delete two Convs (No.10 and No.14 in the YOLOv5 config).Replace the first 1x1 Conv with 3x3 Conv in the Bottleneck.Use…