- demo page
- Detai Xin, tanxu
- 微软 & 东大 & 浙大
abstract
- 使用CoT的思路,和Valle的框架,先实现LLM预测音素级别pitch/duration,然后预测speech token。
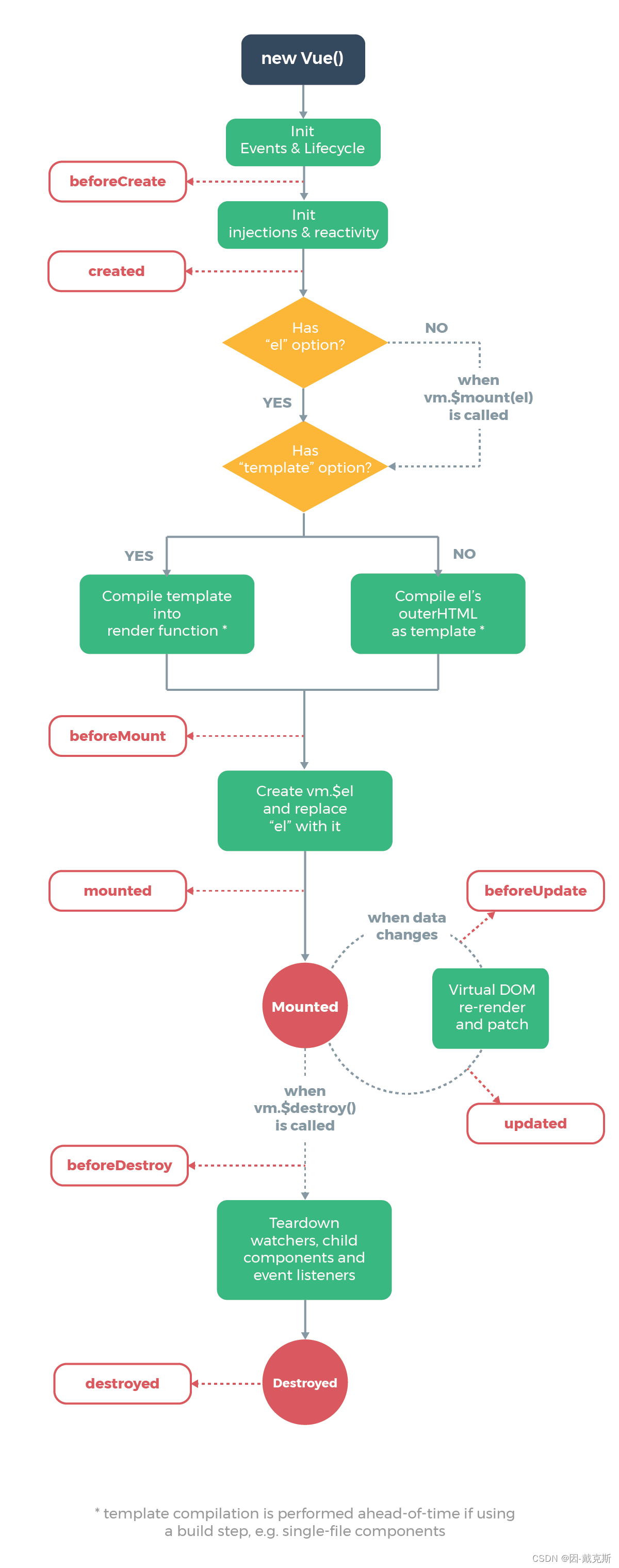
methods
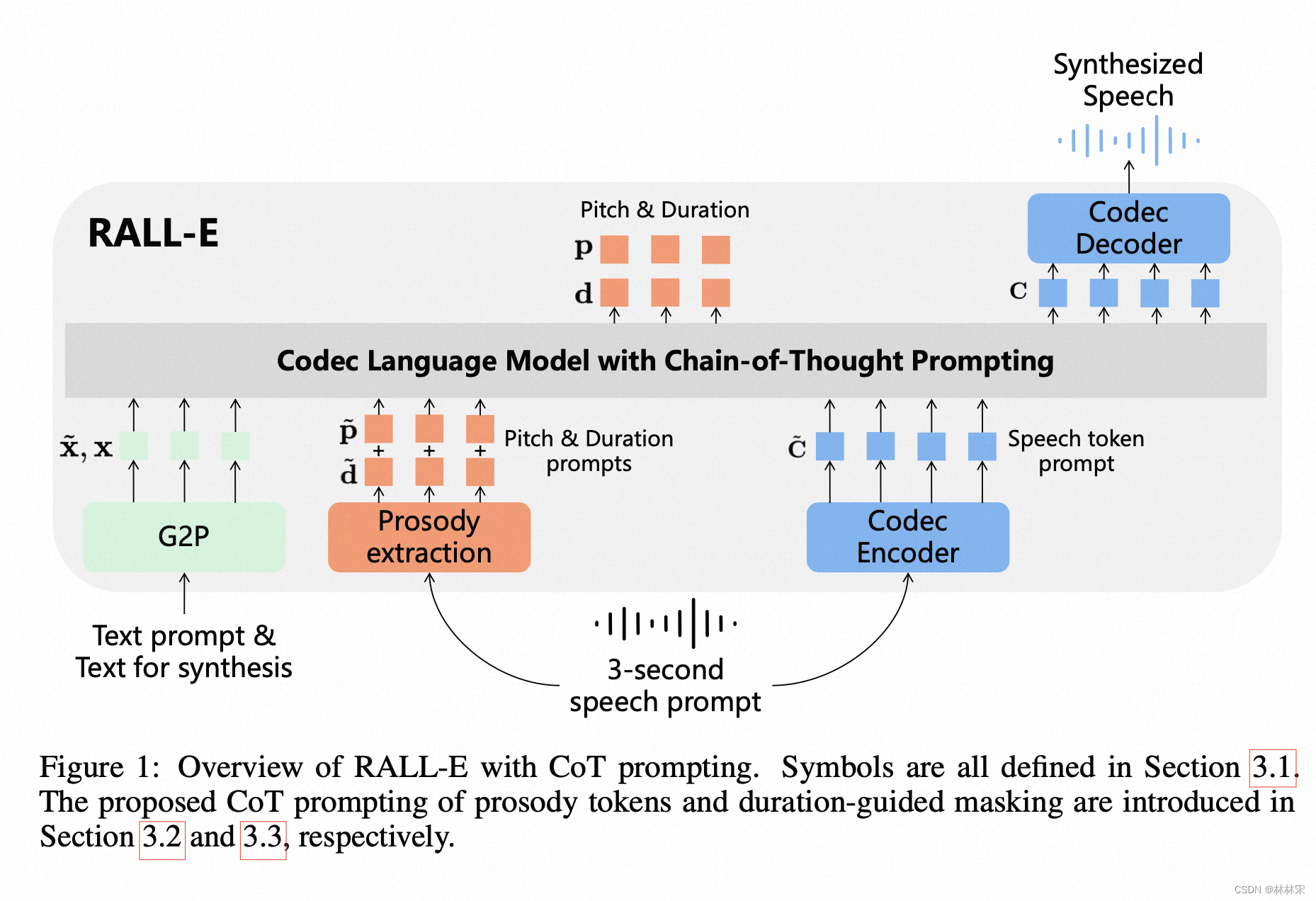
Prosody tokens as chain-of-thought prompts
- 和Valle一样,仍然是AR+NAR结构
- AR先预测pitch/duration,在预测speech token,因为L<<T,所以作者认为对效率影响不大;
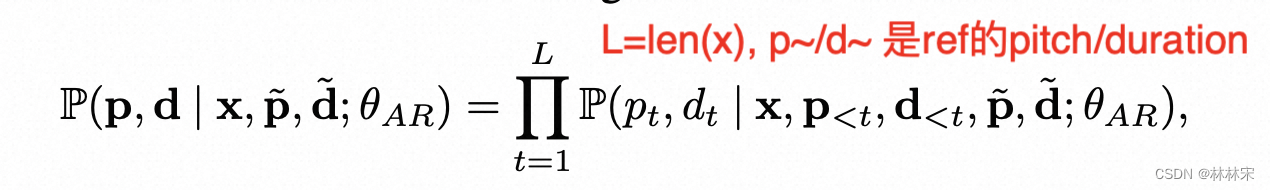
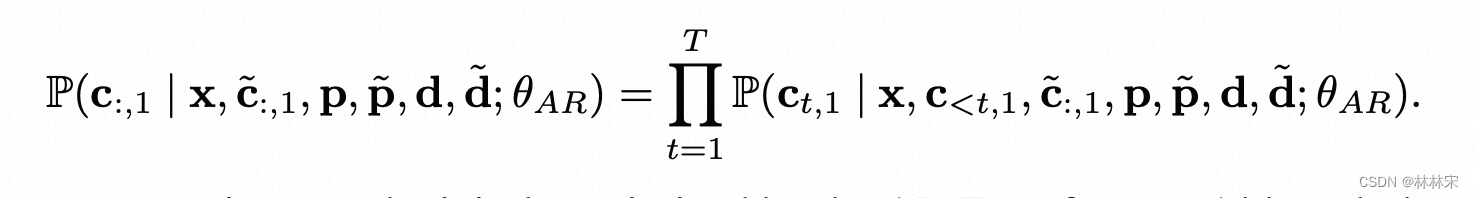
- NAR结构:sum(pitch, duration, phone)
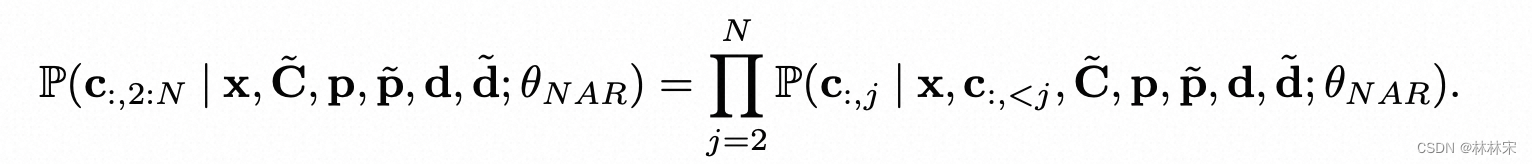
Enhancing alignment with duration-guided masking
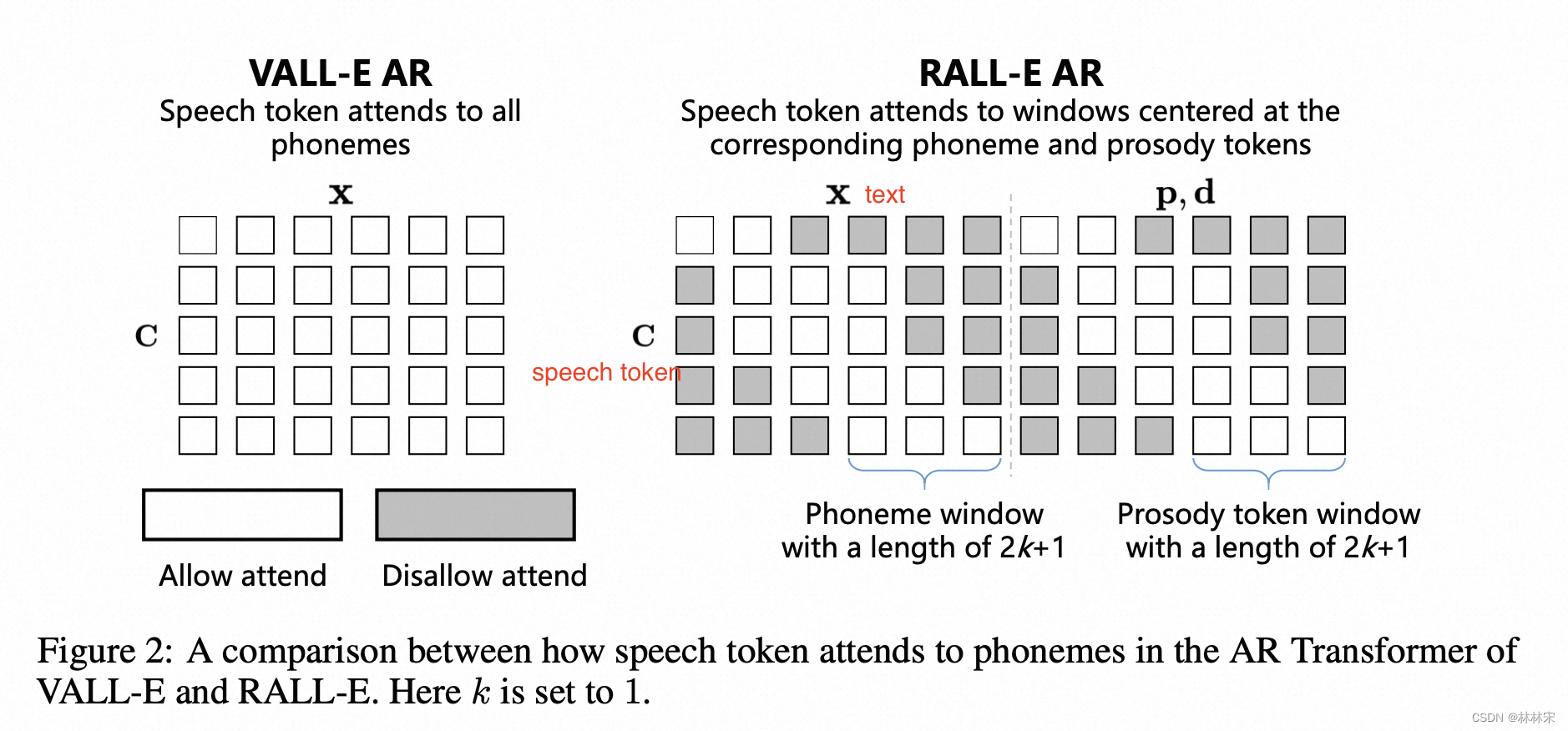
- Valle中,transformer attention 可以计算所有的phone和speech token,因此align不稳定;
- Ralle限制当前phone只能在对应的mel window内计算;相对应,也只能在window 内和pitch token计算;AR加入此mask策略之后稳定性提升显著;NAR 中加入此mask策略没有明显效果;
- 因为inference的时候,先知道duration,所以判断模型是否停止不是看 < E O S > <EOS> <EOS>,而是看推理长度是否是 s u m ( d u r ) sum(dur) sum(dur),以减少skip/repeat error。








![903. 昂贵的聘礼[dijsktra堆优化版]](https://img-blog.csdnimg.cn/direct/2ed23cf181e14cc7ab2afc03b9887beb.png#pic_center)