摘要
本研究提出了一种微调预训练模型ATST(音频师生转换模型)的方法,用于声音事件检测(SED)。通过引入ATST-Frame模型,该方法在DCASE挑战任务4数据集上取得了新的SOTA结果,有效解决了预训练模型在声音事件检测中过拟合的问题。
主要内容
1.背景介绍
- 声音事件检测(SED)旨在检测音频流中的声音事件并标注其发生时间。
- 由于数据标注成本高,SED系统常面临数据不足的问题。
- 现有的SED系统引入了自监督学习(SelfSL)模型以缓解这一问题,但大多数系统将预训练模型视为冻结的特征提取器,微调预训练模型的研究较少。
2.研究目标
研究和提出一种微调预训练模型的方法,用于提高SED性能。
3.方法介绍
- 基线系统:DCASE2023挑战任务4的基线系统采用了预训练的BEATs模型与CRNN(卷积循环神经网络)结合,提供了全局频谱特征。
- 新模型:提出了ATST-Frame模型,专为学习音频信号的帧级表示设计,并在多个下游任务中获得了SOTA性能。
- 微调策略:提出了一种两阶段的微调方法:
第一阶段:冻结ATST-Frame模型,训练CRNN。
第二阶段:联合微调ATST-Frame和CRNN,主要依赖无监督损失以避免过拟合。
4.实验结果
- 数据集:使用DESED数据集进行实验,包含弱标注、强标注和未标注数据。
- 结果比较:提出的ATST-SED模型在DCASE2023挑战任务4数据集上取得了新的SOTA结果,超过了现有的SED系统。
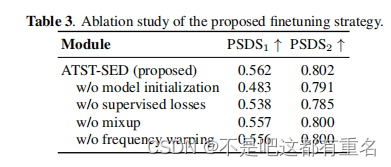
- 消融研究:各个模块对模型性能均有积极影响,且相互兼容。 结论
提出的方法显著提高了SED性能,并可能适用于其他预训练模型,形成一种新的自监督学习模型训练范式。
5.个人理解
- 参考基线系统:作者参考了DCASE2023挑战任务4的基线系统,该系统使用了预训练的BEATs模型与CRNN结合,用于声音事件检测(SED)。基线系统中的预训练模型(BEATs)作为特征提取器使用,在SED任务中提供了全局频谱特征。
- 提出新模型ATST-SED:作者提出了一种新的自监督学习(SelfSL)模型,名为ATST-Frame,并将其应用于SED系统,构建了ATST-SED模型。与BEATs相比,ATST-Frame在帧级表示上具有更高的时间分辨率和更好的性能。
- 从下表中可以看出微调的提升效果更显著。同时也可以看出使用额外的数据也有一定的提升,但主要的贡献还是微调策略的影响。
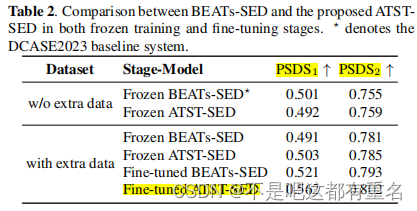
下表可以看出微调策略对效果的影响。