文献:Hao Wang, Junfu Cheng, Chang Liu, Yuanyuan Zhang, Shunfang Hu, Liangyin Chen,Multi-objective reinforcement learning framework for dynamic flexible job shop scheduling problem with uncertain events,Applied Soft Computing,Volume 131,2022,109717,ISSN 1568-4946,https://doi.org/10.1016/j.asoc.2022.109717.
源码可见此处:Multi-Objective Reinforcement Learning Framework for Dynamic Flexible Job Shop Scheduling Problem with Uncertain Events | Code Ocean
1 文献简述
问题:动态多目标柔性作业车间调度问题,涉及工件插入、取消、工件的工序修改;机器增加、更换、故障6个动态事件。
目标:最小化最大完工时间(makespan)、平均机器利用率和平均工件加工延迟率。
解决方式:两个DQN网络和实时处理框架来处理每个动态事件和生成完整的调度方案,此外,采用局部搜索算法进一步优化调度结果。
2 求解框架
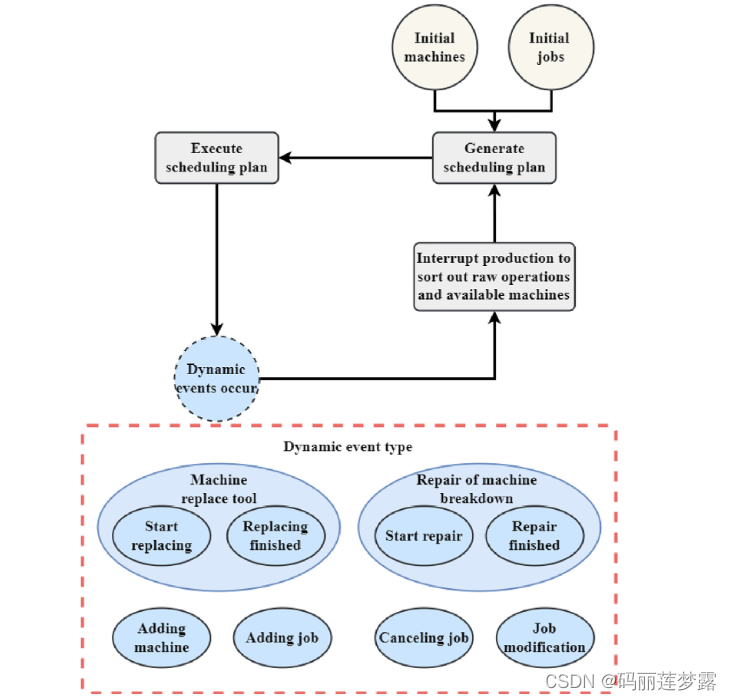
实时动态事件处理框架如下图所示,这篇文章采用的是重调度的框架,即首先生成一个初始解,在出现扰动事件后,针对扰动事件将剩余未加工工件进行重排的方式。对各动态事件的处理如可见原文。
注:本人觉得这种方式其实在使用DRL求解静态调度,作者只是通过他的实时动态事件处理框架来营造了一个动态的氛围,未发挥出DRL求解动态调度问题的优势。
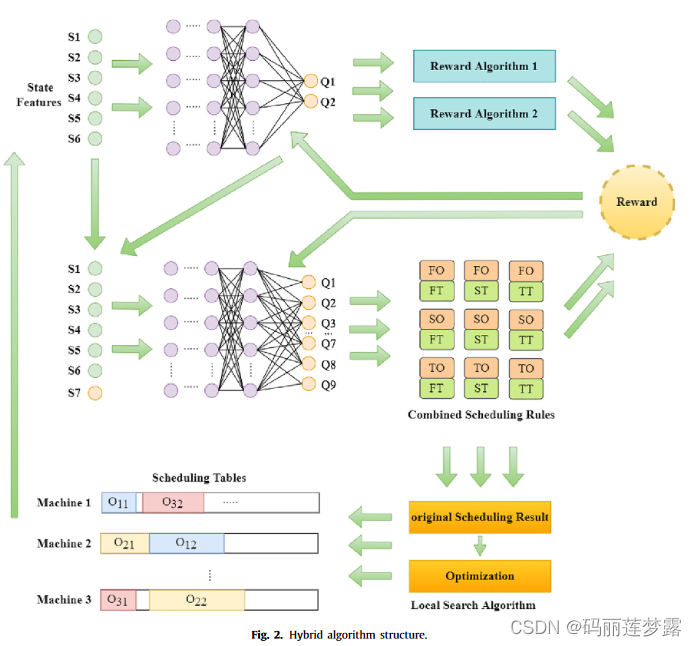
多目标深度强化学习的框架。
这篇文章的状态、动作和奖励函数多与清华大学Shu Luo的相似甚至相同。
3 动作状态奖励函数
如状态设计如下,显而易见,有这篇文献状态设计的影子《Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning》(2020/Applied soft computing Journal/Tsinghua University/Shu Luo)

《Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning》原文内容如下:

动作设计为组合规则(FO+FT, FO+ST, FO+TT, SO+FT, SO+ST, SO+TT, TO+FT, TO+ST and TO+TT),其中,各规则的具体描述如下:
(1)工件选择规则(FO,SO,TO):
FO:优先选择工作完成率较低但交货期早的(文中描述为工件紧急度高的,文中对工件的紧急度进行了分级,根据交货期的早晚分为1、2、3三个不同的紧急度等级)
SO:优先考虑逾期时间长和高度的紧迫感的工件
TO:随机
(2)机器选择规则(FT,TT,ST):
FT:选择最早可加工工序的机器
ST:选择最早完成该工序加工的机器
TT:随机
其动作是其相关研究的换一种描述。
论文的创新点主要在于,实时动态事件处理框架和多目标深度强化学习的框架,其多目标深度强化学习的框架,但文中对其DRL的算法框架的理论描述相对较少,其框架的具体描述如下:
第一个DQN网络输出值表示目标奖励函数的选择,第二个DQN网络输出值表示具体的调度安排。
文中试图通过第一个DQN网络输出用于指导第二个DQN网络,以得到能到达对应目标。
4 疑惑与质疑
(1) 对于整个DRL网络框架的收敛性证明无,第一个DQN网络的输出传入第二个网络作为输入,可见两个DQN网络具有一定的相关性,然而在两个网络损失函数的计算时,分别对两个网络使用均方误差(MSE),网络间无关联。
(2)所设计的奖励函数对三个目标的指导意义是否存在。文中以三个目标为优化目标,而奖励函数为两个,是否可认为也就是优化的两个目标?以两个奖励函数随机选择的方式来优化三个目标,其优化方向是怎样的,是否会造成发散?
(3)规则中采用了随机的方式,是否会使训练具有不确定性,导致最终收敛的结果震荡很大?
(4)局部搜索的加入虽然能进一步提升解的质量,是否浪费了DRL响应优势?