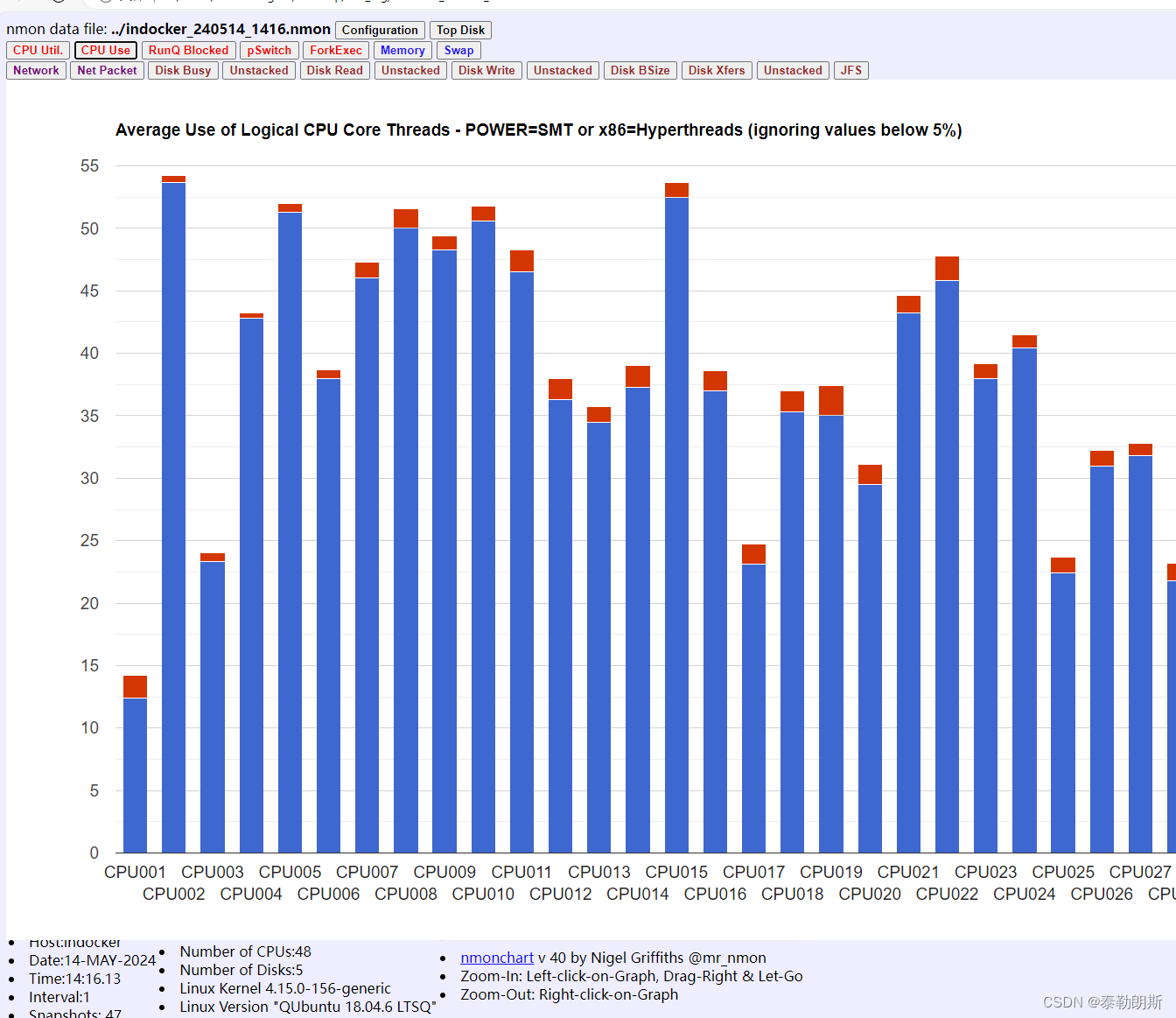
1、etcd单实例部署
对于平常的学习,其实搭建一个单机节点是够了的。接下来就讲讲怎么搭建单机节点。
本次部署是在 centos7 系统,cpu 为amd64 上面进行的。
部署是直接使用官方编译好的二进制文件,大家也可以直接看 ectd-releases 界面选择需要的版本,进行部署。
部署步骤如下:
1、下载官方编译好的 二进制文件。大家可以根据自己的系统和cpu架构进行选择。
cd /opt
wget https://github.com/etcd-io/etcd/releases/download/v3.5.8/etcd-v3.5.8-linux-amd64.tar.gz
2、解压下载好的文件
tar -zxvf etcd-v3.5.8-linux-amd64.tar.gz
3、启动 etcd 服务
cd etcd-v3.5.8-linux-amd64
# 启动方式一:前台启动
./etcd
# 启动方式二:后台启动,日志文件位置可随意选择,有权限读写就可以了
nohup ./etcd > /root/etcd.log 2>&1 &
启动的 etcd 进程默认监听的是 2379端口。我们可以使用 etcdctl 来与 etcd server进行交互。下面展示一个简单的使用案例:
./etcdctl --endpoints=localhost:2379 put foo bar
./etcdctl --endpoints=localhost:2379 get foo
我们也可以将 etcdctl 拷贝到 /usr/local/bin 下面,这样使用 etcdctl 时,就不用想上面这样,必须指定 etcdctl 的位置了。
上面启动 etcd 进程的方式比较简单,大家也可以使用 systemd 来进行管理,这样可以实现开启自启了。
编写 etcd.service 文件:
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target network-online.target
Wants=network-online.target
[Service]
Type=notify
ExecStart=/opt/etcd-v3.5.8-linux-amd64/etcd
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
启动 etcd 服务以及设置为开机自启
# 重载脚本文件
systemctl daemon-reload
# 启动 etcd 服务
systemctl start etcd.service
# 设置 etcd 服务为开机自启
systemctl enable etcd.service
# 停止 etcd 服务
systemctl stop etcd.service
上面就是 etcd 的单实例部署方式了。
2、etcd集群部署
在生产环境中,为了整个集群的高可用,etcd 正常都会集群部署,避免单点故障。接下来我们一起学习如何进行 etcd 集群部署。引导 etcd 集群的启动有以下三种机制:
- 静态启动
预先已知etcd集群中有哪些节点,在启动时通过–initial-cluster参数直接指定好etcd的各个节点地址 - etcd 动态发现
静态配置前提是在搭建集群之前已经提前知道各节点的信息,而实际应用中可能存在预 先并不知道各节点ip的情况,这时可通过已经搭建的etcd来辅助搭建新的etcd集群。通过 已有的etcd集群作为数据交互点,然后在扩展新的集群时,实现通过已有集群进行服务发 现的机制。比如官方提供的:discovery.etcd.io - DNS 发现
通过DNS查询方式获取其他节点地址信息
静态启动 etcd 集群要求每个成员都知道集群中的另一个成员,也就是在配置文件中写死每个集群成员的地址。 在实际情况下,群集成员的 IP 可能会提前未知。在这种情况下,我们可以使用 etcd 官方提供的动态发现功能来帮助引导 etcd 群集。
接下来我们看一看静态启动、etcd 动态发现是如何部署的,DNS 发现的部署方式,大家可以看看文章最后的参考连接,讲解得比较详细。
哈哈,因为 etcd 的部署方式,相对来说还是比较容易的,所以这里偷个懒,大家想看怎么集群部署的话,看文章最后的参考连接。
2.1 单机多实例部署
平常大家自己搭建着玩的话,可以使用此方式来部署一个单机多实例的 etcd 集群,这样管理维护都比较方便。
想要在一台机器上部署 etcd 集群,我们可以借助 goreman 这个工具,goreman 是一个 Go 语言编写的多进程管理工具,是对 Ruby 下广泛使用的 foreman 的重写(foreman 原作者也实现了一个 Go 版本:forego,不过没有 goreman 好用)。
使用goreman 部署集群,需要我们先按照 go的环境,按照好 go 的环境后,执行下面的命令:
go install github.com/mattn/goreman@latest
注意,上面执行的命令,会将 goreman 按照在 $GOPATH 下面,GOPATH 可以通过 go env 查看。如果执行上面命令后,使用 goreman 命令提示找不到命令,多半是没有将 GOPATH 加入到环境变量中去。
简单的方式 vi /etc/profile。加入下面两句话,然后报错即可。
export GOPATH= 自己的实际路径
export PATH=$PATH:$GOPATH/bin

执行下面步骤之前,需要先将 官方文档 编译好的 etcd 二进制文件下载解压到本机,然后将etcd、etcdctl这两个可执行文件拷贝到 /usr/local/bin/下面去。
etcd_cluster_procfile 脚本如下:
etcd1: etcd --name infra1 --listen-client-urls http://127.0.0.1:12379 --advertise-client-urls http://127.0.0.1:12379 --listen-peer-urls http://127.0.0.1:12380 --initial-advertise-peer-urls http://127.0.0.1:12380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
etcd2: etcd --name infra2 --listen-client-urls http://127.0.0.1:22379 --advertise-client-urls http://127.0.0.1:22379 --listen-peer-urls http://127.0.0.1:22380 --initial-advertise-peer-urls http://127.0.0.1:22380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
etcd3: etcd --name infra3 --listen-client-urls http://127.0.0.1:32379 --advertise-client-urls http://127.0.0.1:32379 --listen-peer-urls http://127.0.0.1:32380 --initial-advertise-peer-urls http://127.0.0.1:32380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
配置项说明:
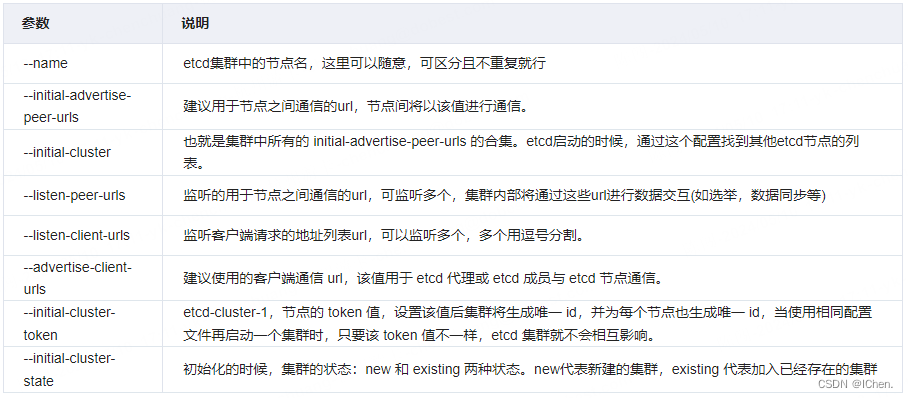
注意上面的脚本,etcd 命令执行时需要根据本地实际的安装地址进行配置。使用下面的命令启动 etcd 集群。
goreman -f /opt/etcd_cluster_procfile start
使用如上的命令启动启动 etcd 集群,启动完成之后查看集群内的成员。
$ etcdctl --endpoints=http://localhost:22379 member list
8211f1d0f64f3269, started, infra1, http://127.0.0.1:12380, http://127.0.0.1:12379, false
91bc3c398fb3c146, started, infra2, http://127.0.0.1:22380, http://127.0.0.1:22379, false
fd422379fda50e48, started, infra3, http://127.0.0.1:32380, http://127.0.0.1:32379, false
上面我们使用单机部署了多个etcd实例,模拟一个etcd集群。我们在启动集群的时候,已经知道了各个实例的地址,但是在实际环境中,集群成员的 ip 可能不会提前知道。这时候就需要采用动态发现的机制。
2.2 动态发现启动 etcd 集群
下面的内容全部来自 文章最后的参考连接,如有侵权,请联系删除,谢谢。
参考连接还有 docker 部署以及 dns 部署,大家感兴趣可以去看看。
如前面所述,在实际环境中,集群成员的 ip 可能不会提前知道。在这种情况下,需要使用自动发现来引导 etcd 集群,而不是指定静态配置,这个过程被称为发现。我们启动三个 etcd,具体对应如下:

2.2.1 协议的原理
Discovery service protocol 帮助新的 etcd 成员使用共享 URL 在集群引导阶段发现所有其他成员。
该协议使用新的发现令牌来引导一个唯一的 etcd 集群。一个发现令牌只能代表一个 etcd 集群。只要此令牌上的发现协议启动,即使它中途失败,也不能用于引导另一个 etcd 集群。
2.2.2 协议的工作流程
Discovery protocol 使用内部 etcd 集群来协调新集群的引导程序。首先,所有新成员都与发现服务交互,并帮助生成预期的成员列表。之后,每个新成员使用此列表引导其服务器,该列表执行与 --initial-cluster 标志相同的功能,即设置所有集群的成员信息。
注意:
Discovery service protocol仅用于集群引导阶段,不能用于运行时重新配置或集群 监视。
2.2.3 使用公共发现服务部署集群
当我们本地没有可用的 etcd 集群,etcd 官网提供了一个可以公网访问的 etcd 存储地址。我们可以通过如下命令得到 etcd 服务的目录,并把它作为 --discovery 参数使用。
公共发现服务 discovery.etcd.io 以相同的方式工作,并提供针对过多请求的保护。公共发现服务在其上仍然使用 etcd 群集作为数据存储。
1、创建集群发现
# 使用公共etcd发现服务
$ curl http://discovery.etcd.io/new?size=3
# 生成的url
http://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
2、部署前准备工作
所有节点均需要安装etcd。以及创建需要的目录。
#创建单独的etcd数据目录
mkdir ‐p /opt/etcd/data
3、以动态发现方式启动集群
每个成员必须指定不同的名称标志,否则发现将因重复的名称而失败
etcd 发现模式下,启动 etcd 的命令如下:
# etcd1 启动
$ /opt/etcd/bin/etcd --name etcd1 --initial-advertise-peer-urls http://192.168.202.128:2380 \
--listen-peer-urls http://192.168.202.128:2380 \
--data-dir /opt/etcd/data \
--listen-client-urls http://192.168.202.128:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://192.168.202.128:2379 \
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
# etcd2 启动
/opt/etcd/bin/etcd --name etcd2 --initial-advertise-peer-urls http://192.168.202.129:2380 \
--listen-peer-urls http://192.168.202.129:2380 \
--data-dir /opt/etcd/data \
--listen-client-urls http://192.168.202.129:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://192.168.202.129:2379 \
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
# etcd3 启动
/opt/etcd/bin/etcd --name etcd3 --initial-advertise-peer-urls http://192.168.202.130:2380 \
--listen-peer-urls http://192.168.202.130:2380 \
--data-dir /opt/etcd/data \
--listen-client-urls http://192.168.202.130:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://192.168.202.130:2379 \
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
需要注意的是,在我们完成了集群的初始化后,这些信息就失去了作用。当需要增加节点时,需要使用 etcdctl 进行操作。为了安全,每次启动新 etcd 集群时,都使用新的 discovery token 进行注册。另外,如果初始化时启动的节点超过了指定的数量,多余的节点会自动转化为 Proxy 模式的 etcd。
4、结果验证
集群启动好之后,进行验证,我们看一下集群的成员:
$ /opt/etcd/bin/etcdctl member list
40e2ac06ca1674a7, started, etcd3, http://192.168.202.130:2380, http://192.168.202.130:2379, false
c532c5cedfe84d3c, started, etcd1, http://192.168.202.128:2380, http://192.168.202.128:2379, false
db75d3022049742a, started, etcd2, http://192.168.202.129:2380, http://192.168.202.129:2379, false
结果符合预期,再看下节点的健康状态:
$ /opt/etcd/bin/etcdctl --endpoints="http://192.168.202.128:2379,http://192.168.202.129:2379,http://192.168.202.130:2379" endpoint health
# 结果如下
http://192.168.202.128:2379 is healthy: successfully committed proposal: took = 3.157068ms
http://192.168.202.130:2379 is healthy: successfully committed proposal: took = 3.300984ms
http://192.168.202.129:2379 is healthy: successfully committed proposal: took = 3.263923ms
可以看到,集群中的三个节点都是健康的正常状态。以动态发现方式启动集群成功。
上面是使用公共服务来做服务发现的,如果我们有自己搭建好的etcd,可以使用自建的etcd作为服务发现,搭建集群:
获取令牌时,必须指定群集大小。 发现服务使用该大小来了解何时发现了最初将组成集群的所有成员。
curl -X PUT http://10.0.10.10:2379/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83/_config/size -d value=3
我们需要把该 url 地址 http://10.0.10.10:2379/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83 作为 --discovery 参数来启动 etcd。
节点会自动使用 http://10.0.10.10:2379/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83 目录进行 etcd 的注册和发现服务。