常见的优化算法可分为一阶优化算法和二阶优化算法。经典的一阶优化算法如SGD等,计算量小、计算速度快,但是收敛的速度慢,所需的迭代次数多。而二阶优化算法使用目标函数的二阶导数来加速收敛,能更快地收敛到模型最优值,所需要的迭代次数少,但由于二阶优化算法过高的计算成本,导致其总体执行时间仍然慢于一阶,故目前在深度神经网络训练中二阶优化算法的应用并不普遍。二阶优化算法的主要计算成本在于二阶信息矩阵(Hessian矩阵、FIM矩阵等)的求逆运算,时间复杂度约为𝑂(𝑛3)。
MindSpore开发团队在现有的自然梯度算法的基础上,对FIM矩阵采用近似、切分等优化加速手段,极大的降低了逆矩阵的计算复杂度,开发出了可用的二阶优化器THOR。使用8块Atlas训练系列产品,THOR可以在72min内完成ResNet50-v1.5网络和ImageNet数据集的训练,相比于SGD+Momentum速度提升了近一倍。
本篇教程将主要介绍如何在Atlas训练系列产品以及GPU上,使用MindSpore提供的二阶优化器THOR训练ResNet50-v1.5网络和ImageNet数据集。
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
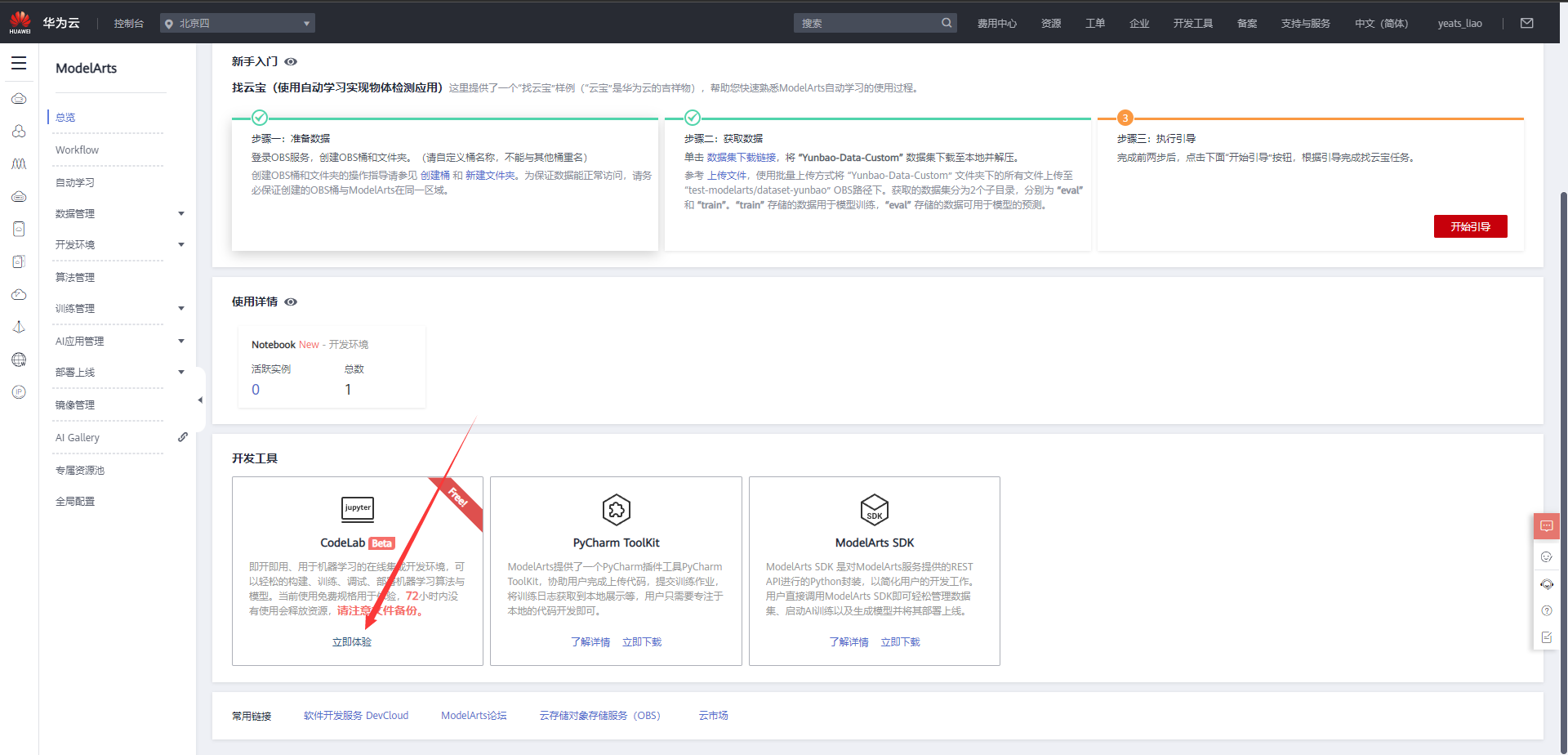
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网
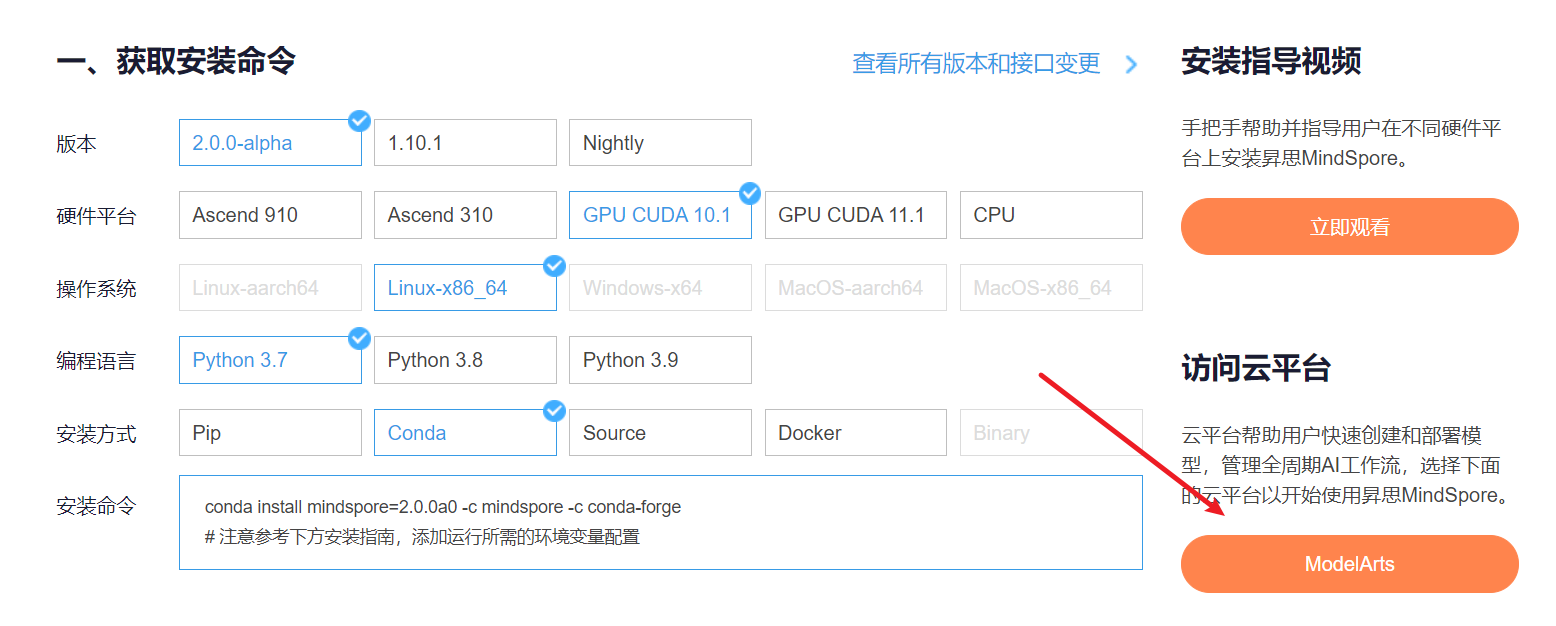
选择下方CodeLab立即体验
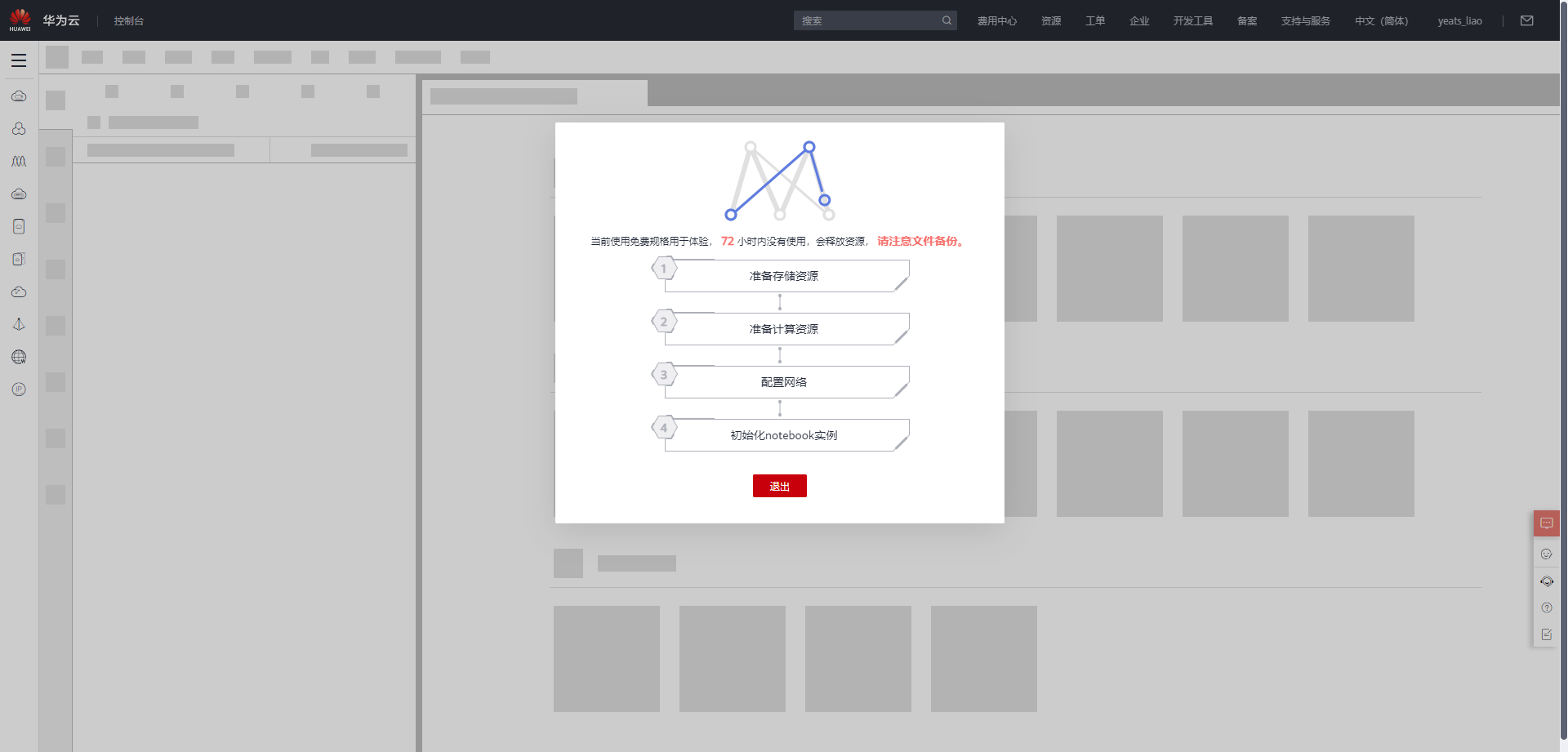
等待环境搭建完成
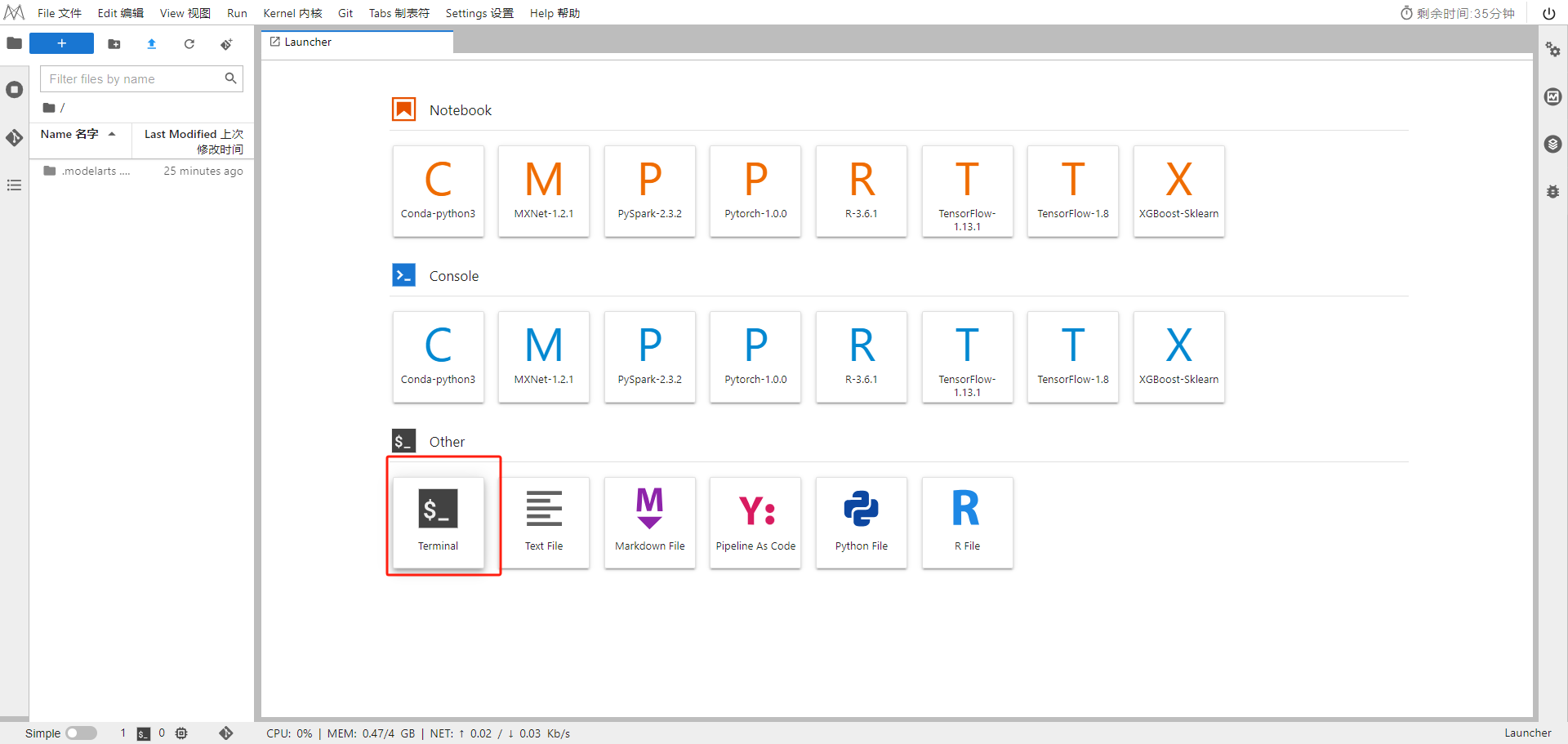
2.使用CodeLab体验Notebook实例
下载NoteBook样例代码
git clone https://gitee.com/mindspore/models.git
选择ModelArts terminal
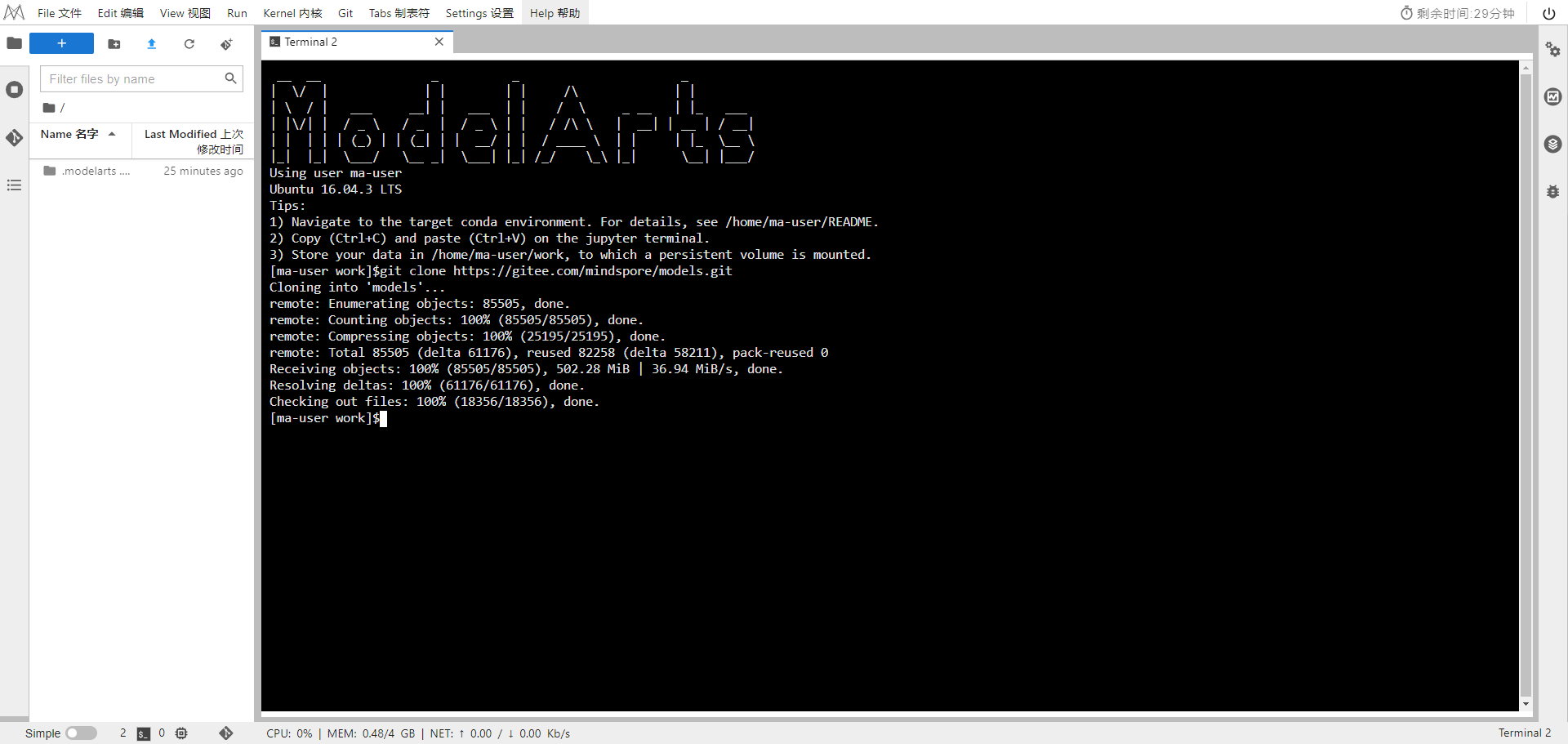
在official/cv/ResNet目录下
选择Kernel环境
切换至GPU环境,切换成第一个限时免费
进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令
conda update -n base -c defaults conda
安装MindSpore 2.0 GPU版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge
安装mindvision
pip install mindvision
安装下载download
pip install download
二、案例实现
下载完整示例代码:Resnet。
示例代码目录结构
├── resnet
├── README.md
├── scripts
├── run_distribute_train.sh # launch distributed training for Atlas training series
├── run_eval.sh # launch inference for Atlas training series
├── run_distribute_train_gpu.sh # launch distributed training for GPU
├── run_eval_gpu.sh # launch inference for GPU
├── src
├── dataset.py # data preprocessing
├── CrossEntropySmooth.py # CrossEntropy loss function
├── lr_generator.py # generate learning rate for every step
├── resnet.py # ResNet50 backbone
├── model_utils
├── config.py # parameter configuration
├── eval.py # infer script
├── train.py # train script
整体执行流程如下:
-
准备ImageNet数据集,处理需要的数据集;
-
定义ResNet50网络;
-
定义损失函数和THOR优化器;
-
加载数据集并进行训练,训练完成后,查看结果及保存模型文件;
-
加载保存的模型,进行推理。
准备环节
实践前,确保已经正确安装MindSpore。如果没有,可以通过MindSpore安装页面安装MindSpore。
准备数据集
下载完整的ImageNet2012数据集,将数据集解压分别存放到本地工作区的ImageNet2012/ilsvrc、ImageNet2012/ilsvrc_eval路径下。
目录结构如下:
└─ImageNet2012
├─ilsvrc
│ n03676483
│ n04067472
│ n01622779
│ ......
└─ilsvrc_eval
│ n03018349
│ n02504013
│ n07871810
│ ......
配置分布式环境变量
Atlas训练系列产品
Atlas训练系列产品的分布式环境变量配置参考rank table启动方式。
GPU
GPU的分布式环境配置参考mpirun启动方式。
加载处理数据集
分布式训练时,通过并行的方式加载数据集,同时通过MindSpore提供的数据增强接口对数据集进行处理。加载处理数据集的脚本在源码的src/dataset.py脚本中。
import os
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore.communication import init, get_rank, get_group_size
def create_dataset2(dataset_path, do_train, repeat_num=1, batch_size=32, target="Ascend", distribute=False,
enable_cache=False, cache_session_id=None):
"""
Create a training or evaluation ImageNet2012 dataset for ResNet50.
Args:
dataset_path(string): the path of dataset.
do_train(bool): whether the dataset is used for training or evaluation.
repeat_num(int): the repeat times of dataset. Default: 1
batch_size(int): the batch size of dataset. Default: 32
target(str): the device target. Default: Ascend
distribute(bool): data for distribute or not. Default: False
enable_cache(bool): whether tensor caching service is used for evaluation. Default: False
cache_session_id(int): if enable_cache is set, cache session_id need to be provided. Default: None
Returns:
dataset
"""
if target == "Ascend":
device_num, rank_id = _get_rank_info()
else:
if distribute:
init()
rank_id = get_rank()
device_num = get_group_size()
else:
device_num = 1
if device_num == 1:
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=8, shuffle=True)
else:
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=8, shuffle=True,
num_shards=device_num, shard_id=rank_id)
image_size = 224
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
# define map operations
if do_train:
trans = [
vision.RandomCropDecodeResize(image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
else:
trans = [
vision.Decode(),
vision.Resize(256),
vision.CenterCrop(image_size),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
type_cast_op = transforms.TypeCast(ms.int32)
data_set = data_set.map(operations=trans, input_columns="image", num_parallel_workers=8)
# only enable cache for eval
if do_train:
enable_cache = False
if enable_cache:
if not cache_session_id:
raise ValueError("A cache session_id must be provided to use cache.")
eval_cache = ds.DatasetCache(session_id=int(cache_session_id), size=0)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=8,
cache=eval_cache)
else:
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=8)
# apply batch operations
data_set = data_set.batch(batch_size, drop_remainder=True)
# apply dataset repeat operation
data_set = data_set.repeat(repeat_num)
return data_setMindSpore支持进行多种数据处理和增强的操作,各种操作往往组合使用,具体可以参考数据处理和数据增强章节。
定义网络
本示例中使用的网络模型为ResNet50-v1.5,定义ResNet50网络。
网络构建完成以后,在__main__函数中调用定义好的ResNet50:
...
from src.resnet import resnet50 as resnet
...
if __name__ == "__main__":
...
# define net
net = resnet(class_num=config.class_num)
...定义损失函数及THOR优化器
定义损失函数
MindSpore支持的损失函数有SoftmaxCrossEntropyWithLogits、L1Loss、MSELoss等。THOR优化器需要使用SoftmaxCrossEntropyWithLogits损失函数。
损失函数的实现步骤在src/CrossEntropySmooth.py脚本中。这里使用了深度网络模型训练中的一个常用trick:label smoothing,通过对真实标签做平滑处理,提高模型对分类错误标签的容忍度,从而可以增加模型的泛化能力。
class CrossEntropySmooth(LossBase):
"""CrossEntropy"""
def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):
super(CrossEntropySmooth, self).__init__()
self.onehot = ops.OneHot()
self.sparse = sparse
self.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)
self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)
self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)
def construct(self, logit, label):
if self.sparse:
label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)
loss = self.ce(logit, label)
return loss
在__main__函数中调用定义好的损失函数:
...
from src.CrossEntropySmooth import CrossEntropySmooth
...
if __name__ == "__main__":
...
# define the loss function
if not config.use_label_smooth:
config.label_smooth_factor = 0.0
loss = CrossEntropySmooth(sparse=True, reduction="mean",
smooth_factor=config.label_smooth_factor, num_classes=config.class_num)
...定义优化器
THOR优化器的参数更新公式如下:
𝜃𝑡+1=𝜃𝑡+𝛼𝐹−1∇𝐸
参数更新公式中各参数的含义如下:
-
𝜃:网络中的可训参数;
-
𝑡:迭代次数;
-
𝛼:学习率值,参数的更新步长;
-
𝐹−1:FIM矩阵,在网络中计算获得;
-
∇𝐸:一阶梯度值。
从参数更新公式中可以看出,THOR优化器需要额外计算的是每一层的FIM矩阵。FIM矩阵可以对每一层参数更新的步长和方向进行自适应的调整,加速收敛的同时可以降低调参的复杂度。
在调用MindSpore封装的二阶优化器THOR时,优化器会自动调用转换接口,把之前定义好的ResNet50网络中的Conv2d层和Dense层分别转换成对应的Conv2dThor和DenseThor。 而在Conv2dThor和DenseThor中可以完成二阶信息矩阵的计算和存储。
THOR优化器转换前后的网络backbone一致,网络参数保持不变。
在训练主脚本中调用THOR优化器:
...
from mindspore.nn import thor
...
if __name__ == "__main__":
...
# learning rate setting and damping setting
from src.lr_generator import get_thor_lr, get_thor_damping
lr = get_thor_lr(0, config.lr_init, config.lr_decay, config.lr_end_epoch, step_size, decay_epochs=39)
damping = get_thor_damping(0, config.damping_init, config.damping_decay, 70, step_size)
# define the optimizer
split_indices = [26, 53]
opt = thor(net, ms.Tensor(lr), ms.Tensor(damping), config.momentum, config.weight_decay, config.loss_scale,
config.batch_size, split_indices=split_indices, frequency=config.frequency)
...训练网络
配置模型保存
MindSpore提供了callback机制,可以在训练过程中执行自定义逻辑,这里使用框架提供的ModelCheckpoint函数。 ModelCheckpoint可以保存网络模型和参数,以便进行后续的fine-tuning操作。 TimeMonitor、LossMonitor是MindSpore官方提供的callback函数,可以分别用于监控训练过程中单步迭代时间和loss值的变化。
...
import mindspore as ms
from mindspore.train import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor
...
if __name__ == "__main__":
...
# define callbacks
time_cb = TimeMonitor(data_size=step_size)
loss_cb = LossMonitor()
cb = [time_cb, loss_cb]
if config.save_checkpoint:
config_ck = CheckpointConfig(save_checkpoint_steps=config.save_checkpoint_epochs * step_size,
keep_checkpoint_max=config.keep_checkpoint_max)
ckpt_cb = ModelCheckpoint(prefix="resnet", directory=ckpt_save_dir, config=config_ck)
cb += [ckpt_cb]
...配置训练网络
通过MindSpore提供的model.train接口可以方便地进行网络的训练。THOR优化器通过降低二阶矩阵更新频率,来减少计算量,提升计算速度,故重新定义一个ModelThor类,继承MindSpore提供的Model类。在ModelThor类中获取THOR的二阶矩阵更新频率控制参数,用户可以通过调整该参数,优化整体的性能。 MindSpore提供Model类向ModelThor类的一键转换接口。
...
import mindspore as ms
from mindspore import amp
from mindspore.train import Model, ConvertModelUtils
...
if __name__ == "__main__":
...
loss_scale = amp.FixedLossScaleManager(config.loss_scale, drop_overflow_update=False)
model = Model(net, loss_fn=loss, optimizer=opt, loss_scale_manager=loss_scale, metrics=metrics,
amp_level="O2", keep_batchnorm_fp32=False, eval_network=dist_eval_network)
if cfg.optimizer == "Thor":
model = ConvertModelUtils().convert_to_thor_model(model=model, network=net, loss_fn=loss, optimizer=opt,
loss_scale_manager=loss_scale, metrics={'acc'},
amp_level="O2", keep_batchnorm_fp32=False)
...运行脚本
训练脚本定义完成之后,调scripts目录下的shell脚本,启动分布式训练进程。
Atlas训练系列产品
目前MindSpore分布式在Ascend上执行采用单卡单进程运行方式,即每张卡上运行1个进程,进程数量与使用的卡的数量一致。进程均放在后台执行,每个进程创建1个目录,目录名称为train_parallel+ device_id,用来保存日志信息,算子编译信息以及训练的checkpoint文件。下面以使用8张卡的分布式训练脚本为例,演示如何运行脚本。
使用以下命令运行脚本:
bash run_distribute_train.sh <RANK_TABLE_FILE> <DATASET_PATH> [CONFIG_PATH]脚本需要传入变量RANK_TABLE_FILE,DATASET_PATH和CONFIG_PATH,其中:
-
RANK_TABLE_FILE:组网信息文件的路径。(rank table文件的生成,参考HCCL_TOOL) -
DATASET_PATH:训练数据集路径。 -
CONFIG_PATH:配置文件路径。
其余环境变量请参考安装教程中的配置项。
训练过程中loss打印示例如下:
... epoch: 1 step: 5004, loss is 4.4182425 epoch: 2 step: 5004, loss is 3.740064 epoch: 3 step: 5004, loss is 4.0546017 epoch: 4 step: 5004, loss is 3.7598825 epoch: 5 step: 5004, loss is 3.3744206 ... epoch: 40 step: 5004, loss is 1.6907625 epoch: 41 step: 5004, loss is 1.8217756 epoch: 42 step: 5004, loss is 1.6453942 ...
训练完后,每张卡训练产生的checkpoint文件保存在各自训练目录下,device_0产生的checkpoint文件示例如下:
└─train_parallel0
├─ckpt_0
├─resnet-1_5004.ckpt
├─resnet-2_5004.ckpt
│ ......
├─resnet-42_5004.ckpt
│ ......
其中, *.ckpt:指保存的模型参数文件。checkpoint文件名称具体含义:网络名称-epoch数_step数.ckpt。
GPU
在GPU硬件平台上,MindSpore采用OpenMPI的mpirun进行分布式训练,进程创建1个目录,目录名称为train_parallel,用来保存日志信息和训练的checkpoint文件。下面以使用8张卡的分布式训练脚本为例,演示如何运行脚本。
使用以下命令运行脚本:
bash run_distribute_train_gpu.sh <DATASET_PATH> <CONFIG_PATH>脚本需要传入变量DATASET_PATH和CONFIG_PATH,其中:
-
DATASET_PATH:训练数据集路径。 -
CONFIG_PATH:配置文件路径。
在GPU训练时,无需设置DEVICE_ID环境变量,因此在主训练脚本中不需要调用int(os.getenv('DEVICE_ID'))来获取卡的物理序号,同时context中也无需传入device_id。我们需要将device_target设置为GPU,并需要调用init()来使能NCCL。
训练过程中loss打印示例如下:
... epoch: 1 step: 5004, loss is 4.2546034 epoch: 2 step: 5004, loss is 4.0819564 epoch: 3 step: 5004, loss is 3.7005644 epoch: 4 step: 5004, loss is 3.2668946 epoch: 5 step: 5004, loss is 3.023509 ... epoch: 36 step: 5004, loss is 1.645802 ...
训练完后,保存的模型文件示例如下:
└─train_parallel
├─ckpt_0
├─resnet-1_5004.ckpt
├─resnet-2_5004.ckpt
│ ......
├─resnet-36_5004.ckpt
│ ......
......
├─ckpt_7
├─resnet-1_5004.ckpt
├─resnet-2_5004.ckpt
│ ......
├─resnet-36_5004.ckpt
│ ......
模型推理
使用训练过程中保存的checkpoint文件进行推理,验证模型的泛化能力。首先通过load_checkpoint接口加载模型文件,然后调用Model的eval接口对输入图片类别作出预测,再与输入图片的真实类别做比较,得出最终的预测精度值。
定义推理网络
-
使用
load_checkpoint接口加载模型文件。 -
使用
model.eval接口读入测试数据集,进行推理。 -
计算得出预测精度值。
...
import mindspore as ms
from mindspore.train import Model
...
if __name__ == "__main__":
...
# define net
net = resnet(class_num=config.class_num)
# load checkpoint
param_dict = ms.load_checkpoint(args_opt.checkpoint_path)
ms.load_param_into_net(net, param_dict)
net.set_train(False)
# define loss
if args_opt.dataset == "imagenet2012":
if not config.use_label_smooth:
config.label_smooth_factor = 0.0
loss = CrossEntropySmooth(sparse=True, reduction='mean',
smooth_factor=config.label_smooth_factor, num_classes=config.class_num)
else:
loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# define model
model = Model(net, loss_fn=loss, metrics={'top_1_accuracy', 'top_5_accuracy'})
# eval model
res = model.eval(dataset)
print("result:", res, "ckpt=", args_opt.checkpoint_path)
...执行推理
推理网络定义完成之后,调用scripts目录下的shell脚本,进行推理。
Atlas训练系列产品
在Atlas训练系列产品平台上,推理的执行命令如下:
bash run_eval.sh <DATASET_PATH> <CHECKPOINT_PATH> <CONFIG_PATH>脚本需要传入变量DATASET_PATH,CHECKPOINT_PATH和<CONFIG_PATH>,其中:
-
DATASET_PATH:推理数据集路径。 -
CHECKPOINT_PATH:保存的checkpoint路径。 -
CONFIG_PATH:配置文件路径。
目前推理使用的是单卡(默认device 0)进行推理,推理的结果如下:
result: {'top_5_accuracy': 0.9295574583866837, 'top_1_accuracy': 0.761443661971831} ckpt=train_parallel0/resnet-42_5004.ckpt-
top_5_accuracy:对于一个输入图片,如果预测概率排名前五的标签中包含真实标签,即认为分类正确; -
top_1_accuracy:对于一个输入图片,如果预测概率最大的标签与真实标签相同,即认为分类正确。
GPU
在GPU硬件平台上,推理的执行命令如下:
bash run_eval_gpu.sh <DATASET_PATH> <CHECKPOINT_PATH> <CONFIG_PATH>脚本需要传入变量DATASET_PATH,CHECKPOINT_PATH和CONFIG_PATH,其中:
-
DATASET_PATH:推理数据集路径。 -
CHECKPOINT_PATH:保存的checkpoint路径。 -
CONFIG_PATH:配置文件路径。
推理的结果如下:
result: {'top_5_accuracy': 0.9287972151088348, 'top_1_accuracy': 0.7597031049935979} ckpt=train_parallel/resnet-36_5