24年5月北理工、Nvidia和华中科大的论文“OmniDrive:A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception Reasoning and Planning”。
多模态大语言模型(MLLMs)的进展导致了对基于LLM的自动驾驶的兴趣不断增长,以利用它们强大的推理能力。然而,利用MLLMs强大的推理能力来改进规划行为是具有挑战性的,因为它需要超越2D推理的完整3D觉察。为了解决这一挑战,本工作提出OmniDrive,一个关于智体模型与3D驾驶任务之间强大对齐的全面框架。框架从一个3D MLLM架构开始,用稀疏查询将视觉表示提升和压缩到3D,然后将其输入LLM。这种基于查询的表示联合编码动态目标和静态地图元素(例如车道),为3D的感知-行动对齐提供了一个简洁的世界模型。进一步提出一个新的基准,其中包括全面的视觉问答(VQA)任务,即场景描述、交通规则、3D基础、反事实推理、决策制定和规划。广泛的研究表明,OmniDrive在复杂的3D场景中具有出色的推理和规划能力。
如图所示OmniDrive,大语言模型 (LLM) 智体的端到端自动驾驶框架。主要贡献涉及模型(OmniDrive-Agent)和基准(OmniDrive-nuScenes)中的解决方案。前者采用3D 视觉-语言模型设计,而后者则由用于推理和规划的综合 VQA 任务组成。
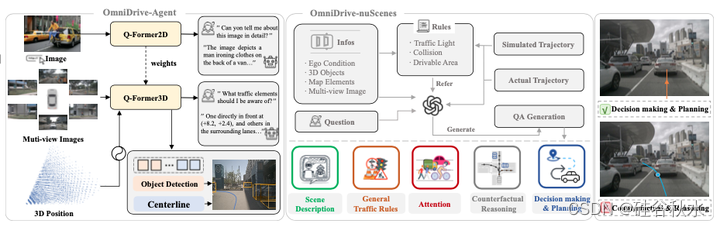
如图是OmniDrive-Agent 的整体流程。左图展示模型的整体框架。用 3D 感知任务来指导 Q-Former 的学习。右图描绘Q-Former3D的具体结构,由六个Transformer解码器层组成。注意力权重是从 2D 预训练中初始化的。输入是多视图图像特征。此外,在注意操作中添加 3D 位置编码。此外,通过记忆库引入时间建模。
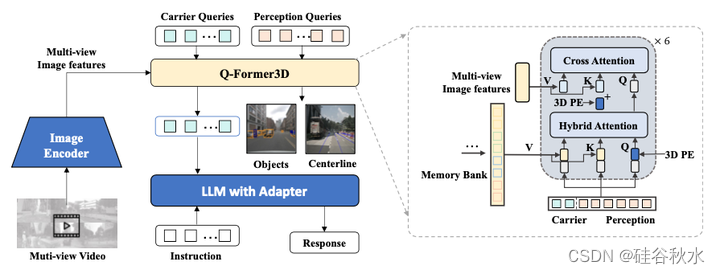
在Q-Former3D中,初始化检测查询和载体查询并执行自注意来交换它们的信息。之后,感知查询用于预测前景元素的类别和坐标。载体查询被发送到单层 MLP 以与 LLM token维度(例如 LLaMA 中的 4096 维)对齐,并进一步用于 LLaVA [31] 之后的文本生成。
在模型中,载体查询起着视觉语言对齐的作用。此外,这种设计使载体查询能够利用 3D 位置编码提供的几何先验,同时还允许它们利用通过 3D 感知任务获取的基于查询的表示。
该方法受益于多任务学习和时间建模[25,33]。在多任务学习中,可以为每个感知任务集成特定于任务的 Q-Former3D 模块,采用统一的初始化策略。在不同的任务中,载体查询可以收集不同交通元素的信息。在实现中,涵盖中心线构建和 3D目标检测等任务。在训练和推理阶段,两个头共享相同的 3D 位置编码。关于时间建模,将具有 top-k 分类分数的感知查询存储到记忆库中,并逐帧传播 [28, 59]。传播的查询通过交叉注意与当前帧的感知和载体查询交互,扩展了模型有效处理视频输入的能力。
OmniDrive-agent 的训练包括两个阶段:2D-预训练 和 3D-微调。在初始化阶段,在 2D 图像任务上对 MLLM 进行预训练,初始化 Q-Former 和载体查询。此后,模型针对 3D 相关驾驶任务(例如运动规划、3D落地等)进行微调。在这两个阶段中,计算文本生成损失,不考虑 BLIP-2 [24] 中的对比学习和匹配损失。
- 2D 预训练。 该阶段旨在预训练载体查询和Q-Former,并实现图像特征和大语言模型之间更好的对齐。当删除检测查询时,OmniDrive模型可以被视为标准视觉语言模型,能够生成以图像为条件的文本。因此,采用 LLaVA v1.5 [30] 中的训练方法和数据在 2D图像上预训练 OmniDrive。 MLLM 首先在 558K 个图像文本对上进行训练,在此期间,除了 Q-Former之外的所有参数都被冻结。随后,使用 LLaVA v1.5 的指令调整数据集对 MLLM进行微调。在此微调步骤中,只有图像编码器被冻结,而所有其他参数都是可训练的。
- 3D微调。该阶段目标是增强模型的3D定位能力,同时尽可能保留其2D语义理解。用 3D 位置编码和时间模块增强原始Q-Former。在这个阶段,用较小的学习率对视觉编码器和Lora [16]的大语言模型进行微调,并用相对较大的学习率训练Q-Former3D。
为了对驾驶 LLM 智体进行基准测试,本文提出OmniDrive-nuScenes,这是一种基于 nuScenes [4] 构建的基准,具有覆盖 3D 领域感知、推理和规划的高质量视觉问答(QA)对。
OmniDrive-nuScenes 具有GPT4 的全自动程序 QA 生成流水线。与 LLaVA [31] 类似,所提出的流水线通过提示输入将 3D 感知真值作为上下文信息。交通规则和规划模拟被进一步用作额外的输入,从而缓解 GPT-4V 在理解 3D 环境方面面临的挑战。该基准以注意、反事实推理和开环规划的形式提出长期问题。这些问题挑战3D 空间中真正的空间理解和规划能力,因为它们需要在接下来的几秒钟内进行规划模拟才能获得正确的答案。
除了使用上述流水线来策划 OmniDrive-nuScenes 的离线问答会话外,还提出一个在线生成各种类型落地问题的流水线。这部分也可以被视为某种形式的隐式数据增强,增强模型的 3D 空间理解和推理能力。
下表显示所提出的离线数据生成流水线的示例,其中使用上下文信息在 nuScenes 上生成 QA 对。首先介绍如何获取不同类型提示信息的相关细节:字幕(Caption)。当图像和冗长的场景信息同时输入 GPT-4V 时,GPT-4V 往往会忽略图像中的细节。因此,作者提示 GPT-4V 仅根据多视图输入生成场景描述。如表中顶部所示。 将三个前视图和三个后视图拼接成两个单独的图像,并将它们输入GPT-4V,还提示 GPT-4V 包含以下详细信息: 1)提及天气、一天中的时间、场景类型和其他图像内容; 2)了解每个视图的大致方向(例如,第一个正视图是左前); 3)避免独立提及每个视图的内容,并用相对于自车的位置代替。

- 车道-目标关联。对于GPT-4V来说,理解3D世界中交通元素(如物体、车道线等)的相对空间关系是一项极具挑战性的任务。直接将 3D 目标坐标和车道线的曲线表示输入到 GPT-4V 并不能实现有效的推理。因此,以文件树的形式表示目标和车道线之间的关系,并根据目标的 3D 边框将其信息转换为自然语言描述。
- 模拟轨迹。通过两种方式对轨迹进行采样以进行反事实推理:1)根据三种驾驶意图选择初始车道:车道保持、左变道和右变道。然后用深度优先搜索(DFS)算法链接车道中心线并获得所有可能的车辆轨迹路径。然后为各个车道选择不同的完成率和速度目标(加速、减速和速度维持)以创建模拟轨迹。 2)仅根据车道中心线生成驾驶轨迹很难模拟“无法驾驶”的场景。因此,还对整个 nuScenes 数据集的自车轨迹进行聚类,每次选择代表性的驾驶路径。
在表的底部,描述使用上述上下文信息获得的不同类型QA响应:
场景描述。直接将字幕(表中的提示类型1)作为场景描述的答案。
注意。给定模拟轨迹和专家轨迹,运行模拟来识别近距离目标。同时,还允许GPT4使用自己的常识来识别有威胁得交通元素。
- 反事实推理。给定模拟轨迹,模拟检查轨迹是否违反交通规则,例如闯红灯、碰撞其他目标或道路边界。
- 决策和规划。展示高层决策以及专家轨迹,并使用 GPT-4V 来推理为什么该轨迹是安全的,并以之前的提示和响应信息作为上下文。
- 一般对话。还提示 GPT-4 基于字幕信息和图像内容生成多轮对话,涉及目标计数、颜色、相对位置和 OCR 类型的任务。这种方法有助于提高模型对长尾目标的识别能力。
为了充分利用自动驾驶数据集中的 3D 感知标签,在训练过程中以在线方式生成了大量类落地的任务。具体来说,设计了以下任务,如图所示:
- 2D 到 3D 落地。给定特定相机上的 2D 边框,例如 <FRONT, 0.45, 0.56, 0.72, 0.87 >,模型需要提供相应目标的 3D 属性,包括其 3D 类别、位置、大小、方向和速度。
- 3D 距离。基于随机生成的3D坐标,识别相应位置附近的交通元素并提供交通元素的3D属性。
- 车道到目标。根据随机选择的车道中心线,列出该车道上存在的目标及其 3D 属性。






![[牛客网]——C语言刷题day2](https://img-blog.csdnimg.cn/direct/8f17e456eddd4530956ab09e5246018b.png)