1.测试环境
一台Linux服务器电脑(可联网)
NVIDIA显卡
注意:仅仅测试浮点运算性能和内存带宽
2.安装测试软件
2.1检查驱动版本
输入指令nvidia-smi,主要是判断显卡驱动有没有安装。如果指令存在可显示如下:
lu@host:/usr/local$ nvidia-smi
Fri Nov 3 00:26:46 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.113.01 Driver Version: 535.113.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1660 ... Off | 00000000:01:00.0 Off | N/A |
| 29% 34C P8 N/A / N/A | 348MiB / 6144MiB | 33% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 890 G /usr/lib/xorg/Xorg 45MiB |
| 0 N/A N/A 1432 G /usr/lib/xorg/Xorg 129MiB |
| 0 N/A N/A 1667 G /usr/bin/gnome-shell 30MiB |
| 0 N/A N/A 2352 G ...3584735,16244303988823860755,262144 131MiB |
+---------------------------------------------------------------------------------------+
lu@host:/usr/local$ 可以看到535最高支持cuda-12.2版本,我这里安装cuda-11.8显然满足要求(驱动版本可以高于对应cuda版本)。此时可直接跳过显卡驱动安装过程,直接按装cuda,否则指令不存在或者最高支持的版本小于11.8则需要安装或者更新驱动。
2.2安装显卡驱动
如果有安装过旧的驱动,需要先删除旧的驱动:
sudo apt-get purge nvidia*确认显卡型号
查明你的NVIDIA显卡型号,以确保下载驱动程序的版本:
lspci | grep -i vga root@Computer:~# lspci | grep VGA
00:02.0 VGA compatible controller: Intel Corporation HD Graphics 630 (rev 04)
01:00.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti 8GB] (rev a1)
root@Computer:~#
下载NVIDIA驱动
前往官方网站:NVIDIA官网
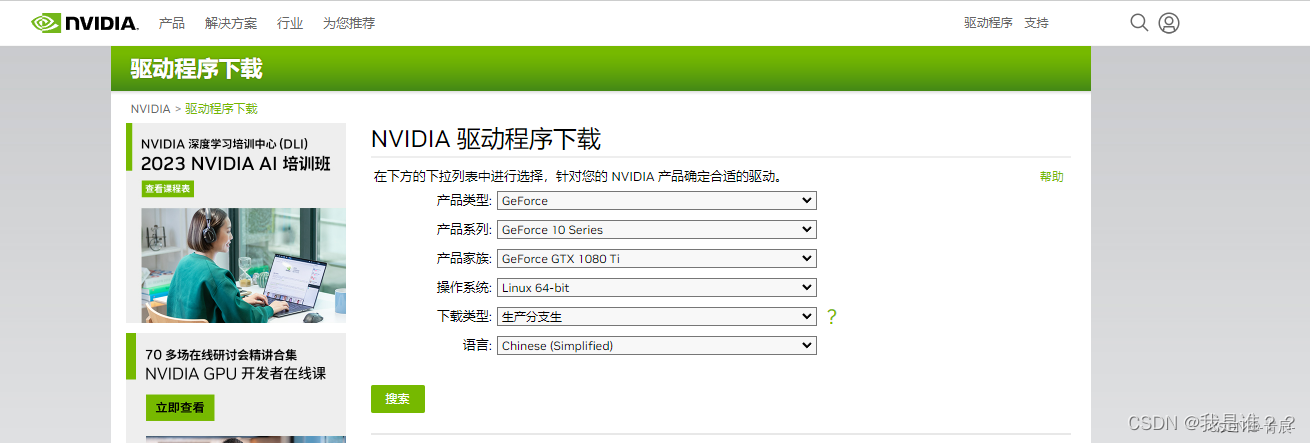
禁用显卡驱动源-nouveau
查看nouveau是否在运行,先输入指令
lsmod | grep nouveau如果不出现以下的情况则已经禁用,可跳过该步骤。

打开文件blacklist文件
sudo vim /etc/modprobe.d/blacklist-nouveau.conf在文件的最后加入这两行指令
blacklist nouveau
options nouveau modeset=0更新一下
sudo update-initramfs -u输入这个指令,查看是否禁用nouveau(如果没有,重启)
lsmod | grep nouveau
安装驱动
将驱动传到服务器,打开终端
#先更改文件的权限
sudo chmod a+x 下载的文件名.run
#使用指令进行安装
sudo ./下载的文件名.run -no-x-check -no-nouveau-check -no-opengl-files
-no-x-check:安装驱动时关闭X服务
-no-nouveau-check:安装驱动时禁用nouveau
-no-opengl-files:只安装驱动文件,不安装OpenGL文件
进入后,选择continue installation
接下里会进入图形化界面,一路选择 yes / ok 就好
检验是否安装成功
重启电脑,查看nvidia驱动:
nvidia-smi2.3安装CUDA
下载cuda:
链接:CUDA Toolkit Archive | NVIDIA Developer
CUDA推荐下载.run可以根据提示安装,执行如下命令:
sudo bash cuda_10.0.130_410.48_linux.run
压住回车键,直到服务条款显示到100%。接着按下面的步骤选择:
accept
n(不要安装driver)
y
y
y安装完成后,设置环境变量
打开主目录下的 .bashrc文件添加如下路径,例如我的.bashrc文件在/home/lu/下。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.0/lib64
export PATH=$PATH:/usr/local/cuda-10.0/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-10.0
终端运行:source ~/.bashrc
检查:nvcc --version2.4cudnn的安装
下载安装文件
按需求下载cudnn的安装文件:cuDNN Archive | NVIDIA Developer
安装cudnn
解压下载的文件,可以看到cuda文件夹,在当前目录打开终端,执行如下命令:
sudo cp cuda/include/cudnn* /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn*
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*查看cudnn版本
在终端输入
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 23.性能测试及结果分析
进入到/usr/local/cuda/samples目录
root@Computer:/usr/local/cuda/samples# ll
总用量 108
drwxr-xr-x 11 root root 4096 5月 14 16:59 ./
drwxr-xr-x 16 root root 4096 10月 27 2021 ../
drwxr-xr-x 52 root root 4096 10月 27 2021 0_Simple/
drwxr-xr-x 8 root root 4096 10月 27 2021 1_Utilities/
drwxr-xr-x 13 root root 4096 10月 27 2021 2_Graphics/
drwxr-xr-x 22 root root 4096 10月 27 2021 3_Imaging/
drwxr-xr-x 10 root root 4096 10月 27 2021 4_Finance/
drwxr-xr-x 10 root root 4096 10月 27 2021 5_Simulations/
drwxr-xr-x 34 root root 4096 10月 27 2021 6_Advanced/
drwxr-xr-x 40 root root 4096 10月 27 2021 7_CUDALibraries/
drwxr-xr-x 6 root root 4096 10月 27 2021 common/
-rw-r--r-- 1 root root 59776 10月 27 2021 EULA.txt
-rw-r--r-- 1 root root 2606 10月 27 2021 Makefile
3.1GPU 的详细规格和特性
首先,进入 CUDA Samples 的 1_Utilities/deviceQuery 目录,编译 deviceQuery 工具:
cd 1_Utilities/deviceQuery
make运行 deviceQuery 工具:
root@Computer:/usr/local/cuda/samples/1_Utilities/deviceQuery# ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1060 6GB"
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 6078 MBytes (6373572608 bytes)
(10) Multiprocessors, (128) CUDA Cores/MP: 1280 CUDA Cores
GPU Max Clock rate: 1785 MHz (1.78 GHz)
Memory Clock rate: 4004 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.1, NumDevs = 1
Result = PASS
这将显示关于 CUDA 设备的详细信息,包括计算能力(Compute Capability)、核心数量、内存信息等。
3.2浮点运算性能
首先,进入 CUDA Samples 的 0_Simple/matrixMul/ 目录,编译 matrixMul工具:
cd 0_Simple/matrixMul/
make运行 matrixMul工具:
root@Computer:/usr/local/cuda/samples/0_Simple/matrixMul# ./matrixMul
[Matrix Multiply Using CUDA] - Starting...
GPU Device 0: "GeForce GTX 1060 6GB" with compute capability 6.1
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 531.11 GFlop/s, Time= 0.247 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performancemeasurements. Results may vary when GPU Boost is enabled.
root@Computer:/usr/local/cuda/samples/0_Simple/matrixMul#执行矩阵乘法测试GPU浮点运算性能:
- GPU是"NVIDIA GeForce GTX 1060 6GB",具有6.1的计算能力。
- 示例中矩阵A的规模是320x320,矩阵B的规模是640x320。
- 示例使用CUDA内核计算矩阵乘法的结果。
- 计算完成后,示例报告了性能指标:531.11 GFlop/s(每秒十亿次浮点运算),计算时间为0.247毫秒,操作数量为131072000次,每个工作组有1024个线程。
- 显示"Result = PASS",这意味着计算结果是正确的。
3.3内存带宽评估
进入 CUDA Samples 的 1_Utilities/bandwidthTest 目录, 编译bandwidthTest:
cd 1_Utilities/bandwidthTest
make运行 bandwidthTest 工具:
root@Computer:/usr/local/cuda/samples/1_Utilities/bandwidthTest# ./bandwidthTest
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: GeForce GTX 1060 6GB
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.2
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.0
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 149.8
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
具体的结果如下:
- Host to Device Bandwidth:对于 32,000,000 字节的数据,带宽为 6.2 GB/s。
- Device to Host Bandwidth:对于 32,000,000 字节的数据,带宽为 6.0 GB/s。
- Device to Device Bandwidth:对于 32,000,000 字节的数据,带宽为 149.8 GB/s。
最后,程序显示 “Result = PASS”,这意味着带宽测试成功完成,没有检测到错误。
这将显示 GPU 的内存带宽信息,包括主机到设备的带宽、设备到主机的带宽等。
![[Fork.dev] 增加用idea打开](https://img-blog.csdnimg.cn/direct/cd796d2b2b114342be6fc31fff44f312.png)