2.实战
1.加载数据
#加载数据
import pandas as pd
import numpy as np
data = pd.read_csv('data_class_raw.csv')
data.head()

2.data.loc得到样本属性,并进行样本数据可视化
#可视化数据
%matplotlib inline
from matplotlib import pyplot as plt
#define X and y
X = data.drop(['y'],axis=1)
y = data.loc[:,'y']
fig1 = plt.figure(figsize=(10,10))
bad = plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
plt.legend((good,bad),('good','bad'))
plt.title('raw data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()

3.建立模型进行异常检测(设置污染系数contamination=0.02)
#异常检测
from sklearn.covariance import EllipticEnvelope
ad_model = EllipticEnvelope(contamination=0.02)#可以自己试着改变此处的值看看有什么变化
ad_model.fit(X[y==0]) # 拟合bad样本
y_predict_bad = ad_model.predict(X[y==0]) # 根据bad样本进行预测
print(y_predict_bad)

这里并不把X全给到模型进行训练,这是因为好的数据点和坏的数据点实际上距离是很短的,如果全给就很难找到异常点,所以要将好的数据点和坏的数据点分开来给到模型进而来寻找异常点。(这里的-1就是异常点)
4.根据预测结果画出异常点
#可视化异常点
fig2 = plt.figure(figsize=(5,5))
bad = plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0]) # 画出数据点
good = plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
plt.scatter(X.loc[:,'x1'][y==0][y_predict_bad==-1],X.loc[:,'x2'][y==0][y_predict_bad==-1],marker='x',s=150) # 根据训练集的模型进行预测,画出预测的bad点
plt.legend((good,bad),('good','bad'))
plt.title('raw data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()

如图,绿叉处就是寻找出的异常点. 至此,任务第一步完成,下面进行第二步。
第二步:进行PCA主分析
1.读取数据然后得到样本属性
data = pd.read_csv('data_class_processed.csv')
data.head()
#define X and y
X = data.drop(['y'],axis=1)
y = data.loc[:,'y']
2.进行PCA主分析,对样本特征进行降维
特征方差比例实际上指的就是:线性无关的特征向量的无关程度,目的就是衡量每个主成分所解释的比例,这些特征会根据方差大小进行降序排序,方差比例可以帮助我们理解每个主成分对总方差的贡献程度,进而确定保留多少主成分以达到对数据集信息的有效压缩,进而确定保留多少主成分以达到对数据集信息的有效压缩。
# 导入所需的库
from sklearn.preprocessing import StandardScaler # 导入数据标准化模块
from sklearn.decomposition import PCA # 导入主成分分析(PCA)模块
import matplotlib.pyplot as plt # 导入绘图模块
# 对特征数据进行标准化处理
X_norm = StandardScaler().fit_transform(X) # 使用StandardScaler对特征数据进行标准化处理
# 创建PCA对象并进行降维
pca = PCA(n_components=2) # 创建PCA对象,指定降维后的维度为2
X_reduced = pca.fit_transform(X_norm) # 对标准化后的特征数据进行PCA降维
# 获取主成分解释的方差比例
var_ratio = pca.explained_variance_ratio_ # 获取每个主成分解释的方差比例
print(var_ratio) # 打印主成分解释的方差比例
# 绘制方差比例条形图
fig4 = plt.figure(figsize=(5, 5)) # 创建绘图窗口
plt.bar([1, 2], var_ratio) # 绘制方差比例的条形图
plt.show() # 显示图形

第三步:进行数据隔离
# 导入所需的库
from sklearn.model_selection import train_test_split # 导入数据分割模块
# 使用train_test_split函数将数据集分割为训练集和测试集
# 参数解释:
# X: 特征数据
# y: 目标数据
# random_state: 随机数种子,用于确保每次分割结果一致
# test_size: 测试集所占比例,这里设置为0.4,即测试集占总数据集的40%
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4, test_size=0.4)
# 打印分割后的数据集形状
print(X_train.shape, X_test.shape, X.shape)

第四步:建立KNN模型
利用KNN模型进行训练,然后计算训练集和测试集的评分
#knn 模型
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
knn_10=KNeighborsClassifier(n_neighbors=10)
knn_10.fit(X_train,y_train)
y_train_predict=knn_10.predict(X_train)
y_test_predict=knn_10.predict(X_test)
#计算准确率
accuracy_train=accuracy_score(y_train,y_train_predict)
accuracy_test=accuracy_score(y_test,y_test_predict)
print("training accuracy:",accuracy_train)
print("testing accuracy:",accuracy_test)

然后可视化分类边界,0~10,以0.05为间隔设置200个间隔(目的是弄非常多的数据填充两个分类)
xx,yy=np.meshgrid(np.arange(0,10,0.05),np.arange(0,10,0.05)) #生成对应的数据组合
print(yy.shape)
x_range = np.c_[xx.ravel(),yy.ravel()] #转换成两列
print(x_range.shape)
y_range_predict=knn_10.predict(x_range)

KNN进行预测并绘图(根据x_range和y_range_predict绘制分界图)
y_range_predict=knn_10.predict(x_range)
fig4 = plt.figure(figsize=(10,10))
knn_bad = plt.scatter(x_range[:,0][y_range_predict==0],x_range[:,1][y_range_predict==0])
knn_good = plt.scatter(x_range[:,0][y_range_predict==1],x_range[:,1][y_range_predict==1])
bad = plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
plt.legend((good,bad,knn_good,knn_bad),('good','bad','knn_good','knn_bad'))
plt.title('prediction result')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()

第五步:计算混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_test_predict)
print(cm)


这四个指标的取值参考上图
TP = cm[1,1]
TN = cm[0,0]
FP = cm[0,1]
FN = cm[1,0]
print(TP,TN,FP,FN)
1.计算准确率:

accuracy = (TP + TN)/(TP + TN + FP + FN)
print(accuracy)
可以看到通过混淆矩阵计算出来的准确率和我们之前建立knn模型计算出的准确率是一样的
2.计算召回率(灵敏度):

recall = TP/(TP + FN)
print(recall)

3.计算特异度:

specificity = TN/(TN + FP)
print(specificity)

4.计算精确率:

precision = TP/(TP + FP)
print(precision)
5.计算f1分数:

F1 = 2*precision*recall/(precision+recall)
print(F1)

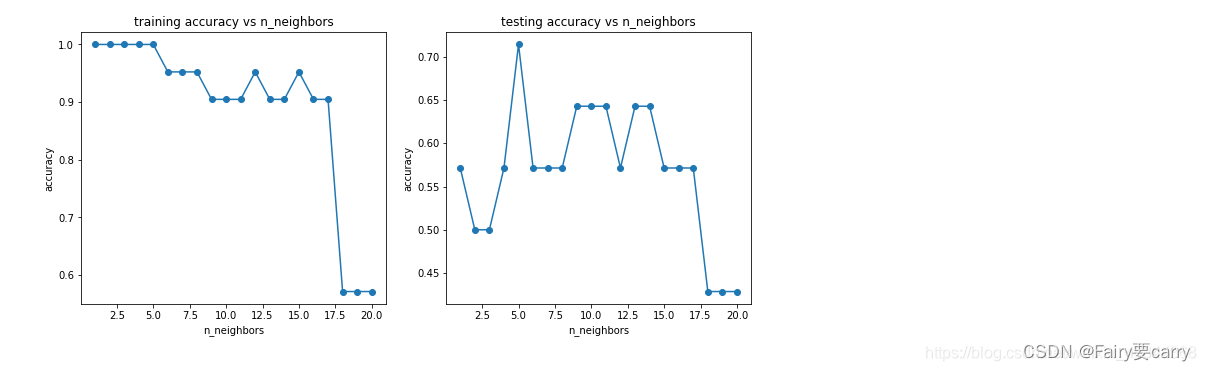
执行最后一个任务:为KNN算法选取一个合适的neighbor
#尝试不同的n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率并作图
n = [i for i in range(1,21)]
accuracy_train = []
accuracy_test = []
for i in n:
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train,y_train)
y_train_predict = knn.predict(X_train)
y_test_predict = knn.predict(X_test)
accuracy_train_i = accuracy_score(y_train,y_train_predict)
accuracy_test_i = accuracy_score(y_test,y_test_predict)
accuracy_train.append(accuracy_train_i)
accuracy_test.append(accuracy_test_i)
print(accuracy_train,accuracy_test)

fig5 = plt.figure(figsize=(12,5))
plt.subplot(121)
plt.plot(n,accuracy_train,marker='o')
plt.title('training accuracy vs n_neighbors')
plt.xlabel('n_neighbors')
plt.ylabel('accuracy')
plt.subplot(122)
plt.plot(n,accuracy_test,marker='o')
plt.title('testing accuracy vs n_neighbors')
plt.xlabel('n_neighbors')
plt.ylabel('accuracy')
plt.show()