正则表达式是一个描述一组字符串的模式
是由普通字符和元字符组成的字符集,而这个字符集匹配(或指定)一个模式。
正则表达式的操作实例
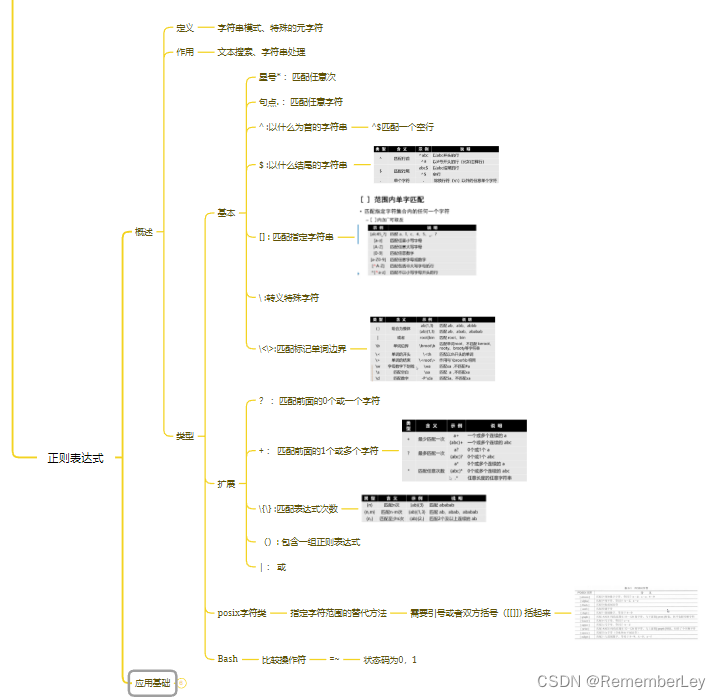
- (一)概述
- 1.定义
- 2.作用
- 3.类型
- (二)字符串匹配实例
- (三)文本搜索实例
(一)概述
1.定义
- 正则表达式是一个描述一组字符串的模式
是由普通字符和元字符组成的字符集,而这个字符集匹配(或指定)一个模式。
2.作用
- 正则表达式的主要作用是文本搜索和字符串处理。一个正则表达式匹配单个字符或一个字符串,或字符串的一部分。
3.类型
- 基本正则表达式
| 元字符 | 使用语法 |
|---|---|
| 星号* | 匹配它前面的字符串或正则表达式任意次 |
| 句点. | 匹配除换行符外的任意一个字符 |
| 插入字符^ | 匹配一行的开始 |
| 美元符$ | 匹配一行的末尾 |
| 方括号[] | 匹配方括号内指定的字符集中的一个字符 |
| 反斜线符号\ | 转义一个特殊字符 |
| 转义尖括号 \ <\ > | 用于标记单词边界,尖括号必须转义 |
- 扩展正则表达式
| 元字符 | 使用语法 |
|---|---|
| 问号? | 匹配0个或1个前面的字符 |
| 加号+ | 匹配1个或多个前面的字符 |
| 转义波形括号{} | 匹配前面正则表达式的次数 |
| 圆括号() | 包含一组正则表达式 |
| 竖线 | “或”操作符 |
- POSIX字符类

注意:POSIX字符类通常需要引用或双方括号([[]])括起来。
(二)字符串匹配实例
实例1:
- 测试digit的值是否为一个十进制数
#!/bin/bash
#######################################################
#
# FILE:checknumeric.sh
# USAGE: ./checknumeric.sh
#
# DESCRTPTION:
# OPTIONS: --
# REPUIREMENTS: --
# BUGS: --
# NOTES: --
# AUTHOR: LEY
# ORGANIZATION:
# CREATED: 05/8/2024 16:23
# REVISION: --
#####################################################
read -p "Input a number ,Please: " num
//^[0-9]+$开头到结尾都是数字重复至少一次
if [[ $num =~ ^[0-9]+$ ]]; then
echo "It's a number"
else
echo "It's not a number"
fi
- 使用POSIX字符类
read -p "Input a number ,Please: " num
if [[ $num =~ [[:digit:]]+$ ]]; then
echo "It's a number"
else
echo "It's not a number"
fi
实例2:
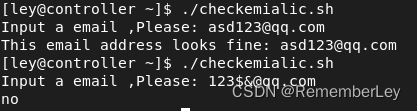
- 检测是否是email地址
#!/bin/bash
#######################################################
#
# FILE:checkemailic.sh
# USAGE: ./checkemailic.sh
#
# DESCRTPTION:
# OPTIONS: --
# REPUIREMENTS: --
# BUGS: --
# NOTES: --
# AUTHOR: LEY
# ORGANIZATION:
# CREATED: 05/8/2024 16:35
# REVISION: --
#####################################################
read -p "Input a number ,Please: " email
//[A-Za-z0-9._%+-$]中的一个字符重复至少一次;@加[A-Za-z0-9.-]中的一个字符重复至少一次;\.转义一个.;[A-Za-z]{2,4}$重复2到4次结束
if [[ "$email" =~ ^[A-Za-z0-9._%+-$]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}$ ]]; then
echo "This email address looks fine: $email"
else
echo "no"
fi
实例3:
- 判断IP地址格式是否正确
#!/bin/bash
#######################################################
#
# FILE:checkIPaddress.sh
# USAGE: ./checkIPaddress.sh
#
# DESCRTPTION:
# OPTIONS: --
# REPUIREMENTS: --
# BUGS: --
# NOTES: --
# AUTHOR: LEY
# ORGANIZATION:
# CREATED: 05/8/2024 16:35
# REVISION: --
#####################################################
if [ $# != 1 ]; then
echo "Usage: $0 address"
exit 1
else
ip=$1
fi
//IP
if [[ "$ip" =~ ^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$ ]]; then
echo "Looks like an IPv4 IP address."
elif [[ $ip =~ ^[A-Fa-f0-9:]+$ ]]; then
echo " Cloud be an IPv6 IP address."
else
echo 'Oops!'
fi
25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?:这部分用于匹配一个0-255之间的数字。
- 25[0-5]:匹配250-255。
- 2[0-4][0-9]:匹配200-249。
- [01]?[0-9][0-9]?:
[01]?:匹配0或1(可选),用于匹配0-199的前两位。
[0-9]:匹配任何一位数字。
[0-9]?:匹配任何一位数字(可选),用于匹配0-99的最后一位(当它是两位数时)。
((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}:这部分用于匹配IPv4地址的前三个数字,并确保它们后面都有一个点(.)。
- {3}:表示前面的捕获组需要重复三次。
- (25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) :这部分用于匹配 I P v 4 地址的最后一个数字,并确保它是字符串的结尾(由 :这部分用于匹配IPv4地址的最后一个数字,并确保它是字符串的结尾(由 :这部分用于匹配IPv4地址的最后一个数字,并确保它是字符串的结尾(由表示)。
(三)文本搜索实例
- 实例1:使用句点.匹配单字符
$ cat list.txt
1122
112
11222
2211
22111
abdde
abede
bbcde
bbdde
$ grep "112." list.txt
1122
11222
$ grep "d.e" list.txt
abdde
bbdde
$ grep "2.." list.txt
11222
2211
22111
- 实例2:使用插入符号^匹配
$ grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
$ grep ^root /etc/passwd
root:x:0:0:root:/root:/bin/bash
$ grep "^Nov 1" /etc/passwd
- 实例3:使用美元$匹配
$ grep 'bash$' /etc/passwd //以bash结尾
root:x:0:0:root:/root:/bin/bash
ley:x:1000:1000:ley:/home/ley:/bin/bash
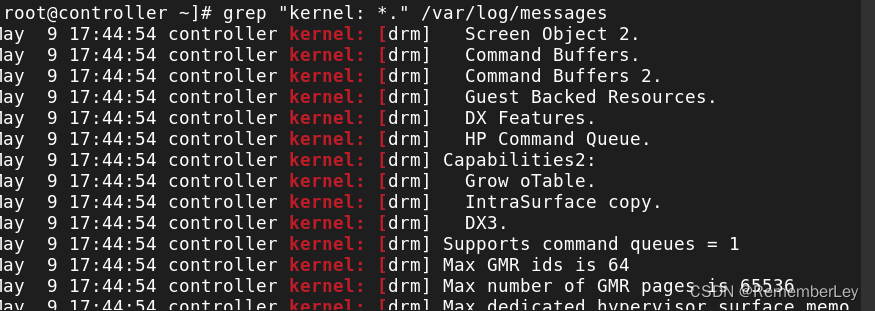
- 实例4:使用星号*匹配
]# grep "kernel: *." /var/log/messages
//匹配kernel后面的冒号“:”,还有紧跟其后的0个或多个空格,最后一个句点匹配任意一个字符
//以i开头,以字符l结尾的行
# egrep "\<i.*l\>" /etc/passwd --color
gnome-initial-setup:x:987:982::/run/gnome-initial-setup/:/sbin/nologin
# grep "\<i.*l\>" /etc/passwd --color
gnome-initial-setup:x:987:982::/run/gnome-initial-setup/:/sbin/nologin
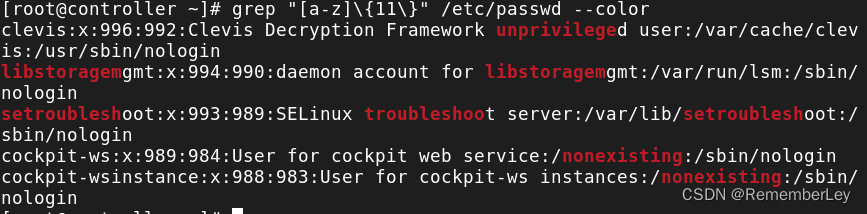
- 实例5:使用方括号[ ]匹配
# grep "[a-z]\{11\}" /etc/passwd --color
//找出文件中含有11个连续小写字符的行
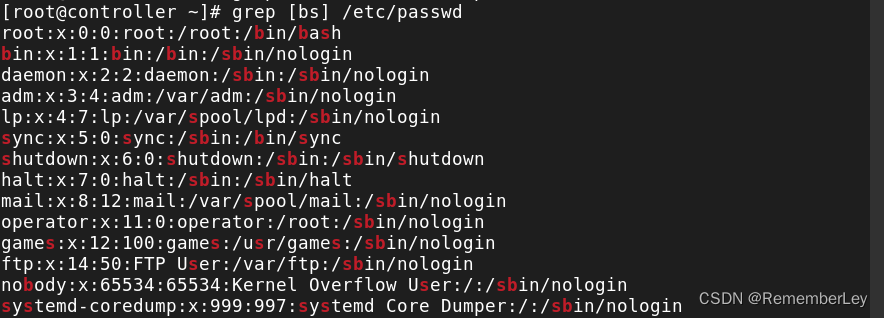
# grep [bs] /etc/passwd
//包含字符b或字母s
//查看系统日志文件中包含“数字+空格+times” 的行
# grep "[0-9]\+ times" /var/log/messages --color
# egrep "[0-9]\+ times" /var/log/messages --color
- 实例6:使用问号?匹配
# cat regeExamp.txt
hi hello
hi hello how are you
hihello
# egrep "hi ?hello" regeExamp.txt
hi hello
hi hello how are you
hihello
//或
# grep "hi \?hello" regeExamp.txt
hi hello
hi hello how are you
hihello
- 实例7:使用加号+匹配
# egrep "hi +hello" regeExamp.txt
hi hello
hi hello how are you
# grep "hi \+hello" regeExamp.txt
hi hello
hi hello how are you
总结:
正则表达式是一个描述一组字符串的模式。
正则表达式是由普通字符和元字符组成的字符集,而这个字符集匹配(或指定)一个模式。
正则表达式的主要作用是文本搜索和字符串处理。一个正则表达式匹配单个字符或一个字符串,或字符串的一部分。
正则表达式有两种类型,分别是基本正则表达式和扩展正则表达式。基本正则表达式的元字符有:*、.、^、$、[]、\和<>。
扩展正则表达式在基本正则表达式的元字符的基础上,增加以下元字符:?、+、{}、(和|。
POSIX字符类通常需用引号或双方括号([[])括起来。
从Bash的3.0版本开始,Bash有了内部的正则表达式比较操作符,使用“=~”表示。 Shell 脚本中大部分使用grep或sed命令的正则表达式编写的代码,现在可以由带有“=~”操作符的Bash表达式处理,并且Bash表达式可能使你的脚本更容易阅读和维护。