1.c/c++内存分布
首先看一段代码
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
char char2[] = "abcd";
const char* pChar3 = "abcd";
//这里不加const会导致权限的放大,因为指向的内容是不能改的
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}
选项
:
A
.
栈
B
.
堆
C
.
数据段
(
静态区
)
D
.
代码段
(
常量区
)
staticGlobalVar
在哪里?
__C_
_localVar
在哪里?
__A__ globalVar在哪里?
__C_
_staticVar
在哪里?
__C __num1 在哪里?__A__
char2
在哪里?
_A___
*
char2
在哪里?
_A__
pChar3
在哪里?
__A__
*
pChar3
在哪里?
_D___
ptr1
在哪里?
__A__
*
ptr1
在哪里?
___B_
(全局变量和静态变量都放在全局区(静态区)
常量放在常量区,全局变量和全局静态变量在主函数之前就创建好了,生命周期在整个程序运行期间都在,局部的静态变量在第一次调用的时候才会创建,数组也在栈上
char2和num1一样是一个数组,char2就是首元素的地址,*char2就是a
const char* pchar3 = "abcd";//这里const修饰的是指向的内容不能修改,但是pchar3可以改变,所以pchar3在栈上,pchar3是一个指针变量,存的常量区字符串abcd\0的地址,指向的常量区,所以*pchar3在常量区,即常量区的a, 如下图所示。

c/c++中程序内存区域划分如下:
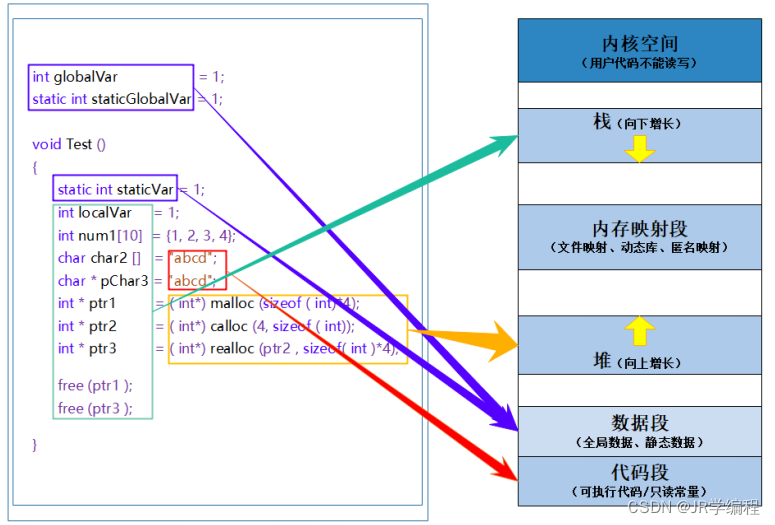
①
栈
又叫堆栈
--
非静态局部变量
/
函数参数
/
返回值等等,栈是向下增长的。
②
内存映射段
是高效的
I/O
映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共 享内存,做进程间通信。
③
堆
用于程序运行时动态内存分配,堆是可以上增长的。
④
数据段
--
存储全局数据和静态数据。
⑤
代码段
--
可执行的代码
/
只读常量。
2.c++内存管理方式
通过new/delete操作内置类型
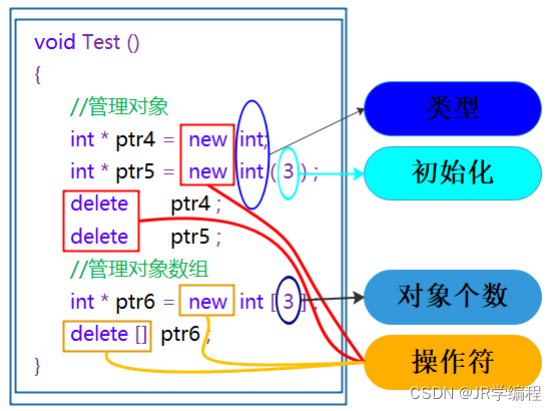
注意:申请和释放单个元素的空间,使用
new
和
delete
操作符,申请和释放连续的空间,使用
new[]
和
delete[]
,注意:匹配起来使用。
int main()
{
// 内置类型
// 除了用法方便,c malloc没什么区别
/*int* p1 = new int;
int* p2 = new int[10];*/ //前后类型最好匹配
// 默认不初始化,但是可以初始化
int* p1 = new int(10);//单个对象初始化
int* p2 = new int[10]{1,2,3,4};//多个对象初始化
//()是初始化 []是个数 再要初始化加{}
delete p1;//释放空间,delete是一个操作符
delete[] p2;//释放多个对象
return 0;
}
new/delete
和
malloc/free
最大区别是
new/delete
对于【自定义类型】除了开空间还会调用构
造函数和析构函数
class A
{
public:
A(int a = 0)
:_a(a)
{
cout << "A(int a)" << endl;
}
A(int a1, int a2)
{
cout << "A(int a1, int a2)" << endl;
}
A(const A& aa)
:_a(aa._a)
{
cout << "A(const A& aa)" << endl;
}
A& operator=(const A& aa)
{
cout << "A& operator=(const A& aa)" << endl;
if (this != &aa)
{
_a = aa._a;
}
return *this;
}
~A()
{
cout << "~A()" << endl;
}
private:
int _a;
};
int main()
{
自定义类型, new才能调用构造初始化,delete才能调用析构 malloc不再适用
//A* p1 = (A*)malloc(sizeof(A));//自定义类型malloc出来没有初始化
p1->_a = 0;//malloc没有构造
//free(p1);//free不会析构
开空间/释放空间,还会调用构造和析构
//A* p2 = new A;
//A* p3 = new A(2);//new可以对自定义类型初始化,这里A(2)不是匿名对象
//delete p2;//delete会析构
//delete p3;
//cout << endl;
//A* p4 = new A[10];//十个对象调用十次构造函数
A aa1(1);
A aa2(2);
A aa3(3);
A* p4 = new A[10]{aa1, aa2, aa3};//有名对象的方式初始化,三个拷贝,七个默认构造初始化
//分别用aa1,aa2,aa3拷贝构造初始化,剩余只会调用默认构造,如果没有默认构造会报错
//A* p4 = new A[10]{ 1,2,3,4,5,{6,7}};//new的目的是针对每个对象去调用构造,单参数和多参数均可
//1,2,3,4,5,隐式类型转换成A,用1,2,3,4,5生成临时对象,
//临时对象再去拷贝构造,被编译器合二为一,相当于直接调构造
delete[] p4;//释放掉10个对象,并且每个对象调用析构函数
return 0;
}
注意:在申请自定义类型的空间时,
new
会调用构造函数,
delete
会调用析构函数,而
malloc与
free
不会
。
3.operator new与operator delete函数
operator new 和operator delete不是new和delete的重载,这是库里面写好的两个全局函数,实际是malloc和free的封装,
new
在底层调用
operator new
全局函数来申请空间,
delete
在底层通过
operator delete
全局
函数来释放空间
#include<stack>
int main()
{
// operator new->(malloc) + 构造函数
A* p2 = new A;//new开空间还是用malloc去开的
// 析构 + operator delete
delete p2;//operator delete 它delete的是p2指向的空间,析构析构的是A对象上资源的清理
stack<int>* p3 = new stack<int>;
delete p3;
return 0;
}对于
stack<int>p3 =new stack<int>;
delete p3;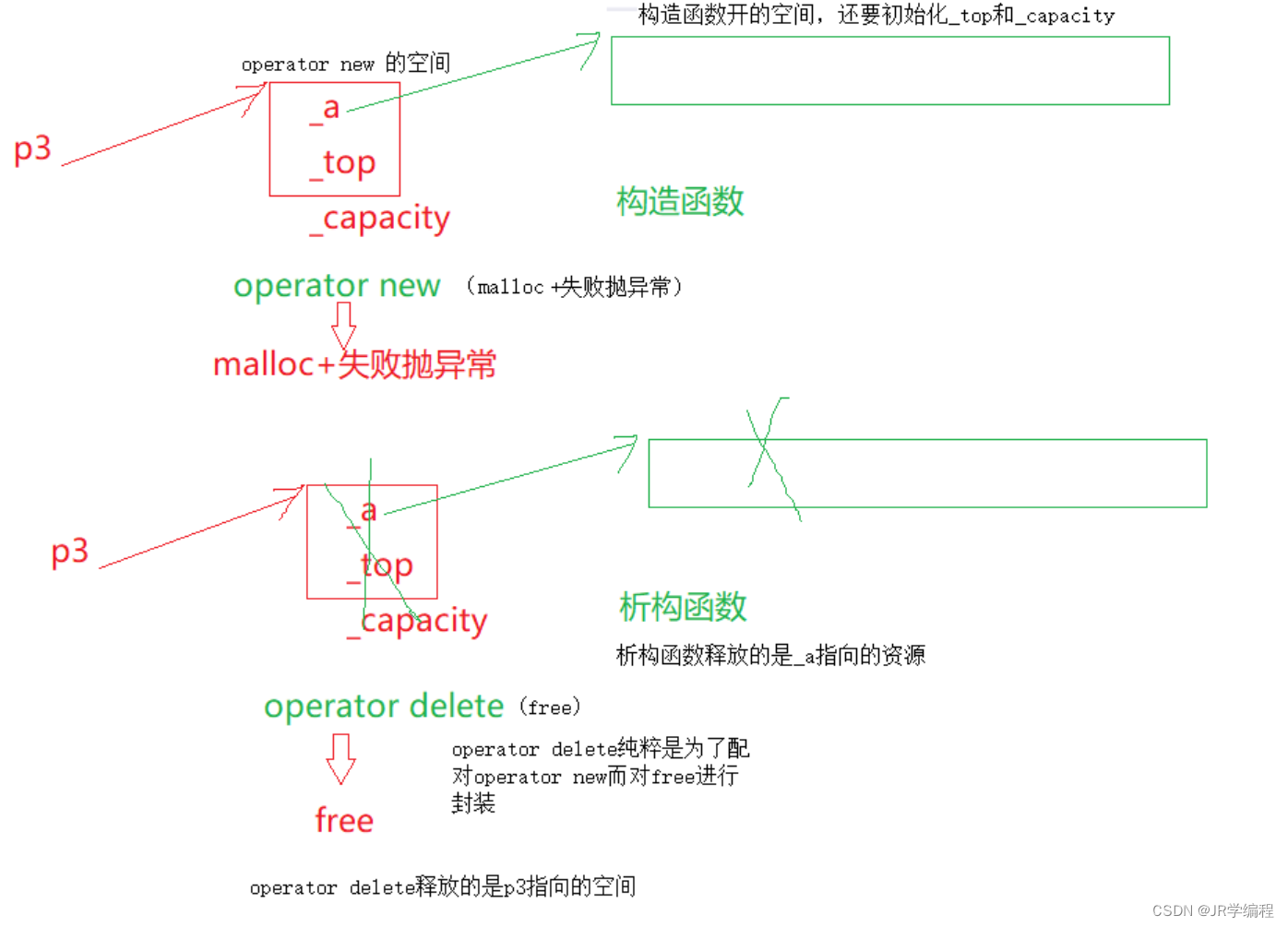
operator new实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete最终是通过free来释放空间的。
throw抛异常,捕获用try,catch
下面是两个抛异常的例子:
double Division(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
throw "Division by zero condition!";
else
return ((double)a / (double)b);
}
void Func()
{
int len, time;
cin >> len >> time;
cout << Division(len, time) << endl;
}
int main()
{
try
{
Func();
}
catch(const char* errmsg)
{
cout << errmsg << endl;
}
catch (...)
{
cout << "unkown exception" << endl;
}
return 0;
}
当输入time为0时

struct ListNode
{
ListNode* _next;
int _val;
ListNode(int val)
:_next(nullptr)
, _val(val)
{}
};
void func()
{
// new失败了,抛异常, 只需要在外层进行捕获就可以,不需要再检查返回值,
// 异常后程序不会继续往下执行程序,会自动跳到catch处
ListNode* n1 = new ListNode(1);//new进行malloc,会调用构造函数进行初始化,不需要写buynewnode函数
ListNode* n2 = new ListNode(2);
ListNode* n3 = new ListNode(3);
int* p1 = new int[100 * 1024 * 1024];
int* p2 = new int[100 * 1024 * 1024];
int* p3 = new int[100 * 1024 * 1024];
int* p4 = new int[100 * 1024 * 1024];
int* p5 = new int[100 * 1024 * 1024];
int* p6 = new int[100 * 1024 * 1024];
n1->_next = n2;
n2->_next = n3;
delete n1;
delete n2;
delete n3;
}
int main()
{
try
{
func();
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
}
4.new和delete的实现原理
①内置类型
如果申请的是内置类型的空间,
new
和
malloc
,
delete
和
free
基本类似,不同的地方是:
new/delete
申请和释放的是单个元素的空间,new[]
和
delete[]
申请的是连续空间,而且
new
在申请空间失败时会抛异常, malloc会返回
NULL
。
②自定义类型
new
的原理
1.
调用
operator new
函数申请空间(malloc)
2.
在申请的空间上执行构造函数,完成对象的构造
delete
的原理
1.
在空间上执行析构函数,完成对象中资源的清理工作
2.
调用
operator delete
函数释放对象的空间
new T[N]
的原理
1.
调用
operator new[]
函数,在
operator new[]
中实际调用
operator new
函数完成
N
个对象空间的申请(只调用一次operator new)
2.
在申请的空间上执行
N
次构造函数
delete[]
的原理
1.
在释放的对象空间上执行
N
次析构函数,完成
N
个对象中资源的清理
2.
调用
operator delete[]
释放空间,实际在
operator delete[]
中调用
operator delete
来释放空间
注意:new/delete,malloc/free,new[]/delete[]一定要匹配使用
#include<iostream>
using namespace std;
class A
{
public:
A(int a = 0)
: _a(a)
{
cout << "A():" << this << endl;
}
~A()
{
cout << "~A():" << this << endl;
}
private:
int _a;
};
//结论:不要错配使用,一定匹配使用,否则结果是不确定
int main()
{
A* p1 = new A;
A* p2 = new A[10];
//44 or 40 多开的四个字节用来存对象个数,方便析构的时候知道调用多少次析构函数
// 显示写析构就要多开四个字节,没有显示写就不需要
//free(p2);//释放的位置不对,free不会往前推移
delete[] p2;//把p2前面的四个字节取出来得到析构的次数,然后取p2后面的对象依次去调用析构
//先调析构,再调用operator delete[],operator delete[]调operator delete,operator delete最终调free
//free的位置为p2前面的四个字节处,这里free会往前推移是因为delete多开了四个字节
//delete p2;//这是也是因为释放的位置不对(应该为p2前面的四个字节处),delete不会往前推移
//free(p2);//这里也是释放的位置不对
//int* p3 = new int[10]; //40
//free(p3);//内置类型交错使用没什么问题
return 0;
}显示写A的析构时,new A[10]开的空间如下:

5.定位new表达式(placement-new)
定位
new
表达式是在
已分配的原始内存空间中调用构造函数初始化一个对象
。
使用格式:
new (place_address) type
或者
new (place_address) type(initializer-list)
place_address
必须是一个指针,
initializer-list
是类型的初始化列表
使用场景:
定位
new
表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new
的定义表达式进行显示调构造函数进行初始化。
int main()
{
//A* p1 = new A;//这一行等价于 A* p1 = (A*)operator new(sizeof(A)); 和//new(p1)A;//这两行指令
A* p1 = (A*)operator new(sizeof(A));//malloc和operator new开的不会调用构造,operator new 如果开辟失败会抛异常
//p1->A(); // 不支持这样显示调用构造
//new(p1)A; // 对已有空间,显示调用构造
new(p1)A(10); // 对已有空间,显示调用构造,同时初始化
//A* p1 = pool.alloc(sizeof(A));
//new(p1)A(10); // 对已有空间,显示调用构造
// delete p1 等价于下面两行
p1->~A();//可以显示调用析构
operator delete(p1);
// new []
A* p2 = (A*)operator new[](sizeof(A)*10);
//new(p2)A[10]{1,2,3,4}; // 对已有空间,显示调用构造
for (int i = 0; i < 10; ++i)
new(p2 + i)A(i);
// delete[]
for (int i = 0; i < 10; i++)
{
(p2 + i)->~A();
}
operator delete[](p2);
return 0;
}
6.malloc/free
和
new/delete
的区别
malloc/free
和
new/delete
的共同点是:都是从堆上申请空间,并且需要用户手动释放。不同的地方是:
① malloc
和
free
是函数,
new
和
delete
是操作符
② malloc
申请的空间不会初始化,
new
可以初始化
③ malloc
申请空间时,需要手动计算空间大小并传递,
new
只需在其后跟上空间的类型即可, 如果是多个 对象,[]
中指定对象个数即可
④ malloc
的返回值为
void*,
在使用时必须强转,
new
不需要,因为
new
后跟的是空间的类型
⑤ malloc
申请空间失败时,返回的是
NULL
,因此使用时必须判空,
new
不需要,但是
new
需要捕获异常
⑥
申请自定义类型对象时,
malloc/free
只会开辟空间,不会调用构造函数与析构函数,而
new
在申请空间后会调用构造函数完成对象的初始化,delete
在释放空间前会调用析构函数完成空间中资源的清理。
前五点是用法上的不同,第六点是原理上的不同