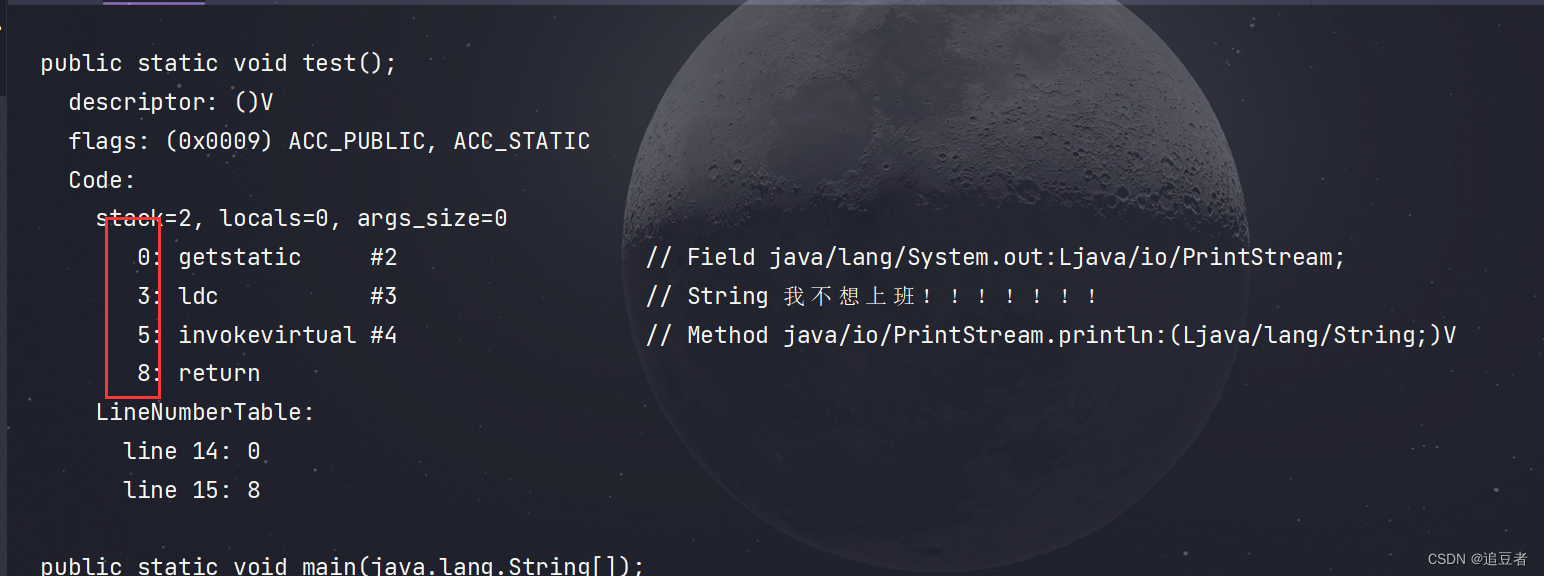
2.算法设计题
1.合并递增链表
![]()
1.算法分析:
两个链表合并,由于限定不能用额外的存储空间,所以链表比较合适。
算法步骤:
第一步:取出b表中的第一个结点;
第二步:和a表中的结点依次比较,找到第一个大于b表的结点的位置,并记下位置;
如果直到表尾都没有遇到大于b结点的值, 记下表尾位置。
第三步: 在第二步中的位置前面插入该b表结点,或者插入表尾后面。
第四步:返回到第一步,循环执行,直到b表的结点取完为止。
代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype *elem;
int length;
}sqlsit;
// status init(sqlsit *L);
typedef struct
{
elemtype data;
struct lnode *next;
}lnode, *linklist;
status init(linklist list);
void create(linklist list, elemtype data[]);
void print(linklist list);
void destroy(linklist list);
linklist merge(linklist alist, linklist blist);
void main() {
// sqlsit a, b;
// init(&a);
// init(&b);
lnode a_list,b_list;
init(&a_list);
init(&b_list);
int a[10] = {1,3,5,7,9,11,13,15,17,19};
int b[10] = {2,4,6,8,10,12,14,16,18,20};
create(&a_list, a);
create(&b_list, b);
print(&a_list);
print(&b_list);
printf("\n");
merge(&a_list, &b_list);
print(&a_list);
//destroy(&a_list);
//destroy(&b_list);
}
// status init(sqlsit *L) {
// L->length = MAXSIZE;
// L = (elemtype *) malloc(MAXSIZE*sizeof(elemtype));
// if(!L->elem) exit(ERROR);
// return OK;
// }
status init(linklist list) {
list = (linklist) malloc (sizeof(lnode));
list->next = NULL;
list->data = 10;
return OK;
}
void create(linklist list, elemtype data[10]) {
lnode *tail = list;
for(int i = 0; i < 10; i++) {
linklist p = (lnode *) malloc(sizeof(elemtype));
p->data = data[i];
tail->next = p;
p->next = NULL;
tail = p;
}
}
void print(linklist list) {
linklist tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(linklist list) {
linklist tail = list->next;
for(int i = 0; i <= 10; i++) {
list->next = NULL;
free(list);
list = tail;
tail = tail->next;
}
}
linklist merge(linklist alist, linklist blist) {
lnode *a_head = alist;
lnode *a_tail = alist->next;
lnode *b_head = blist;
lnode *b_tail = blist->next;
while(b_tail) {
b_head->next = b_tail->next;
b_tail->next = NULL;
while(a_tail) {
if(a_tail->data > b_tail->data) {
a_head->next = b_tail;//insert a node
b_tail->next = a_tail;
a_head = b_tail;//update a head node
b_tail = b_head->next;
break;
} else if(!a_tail->next) {
a_tail->next = b_tail;
a_tail = b_tail;
a_head = a_head->next;
b_tail = b_head->next;
break;
}
a_tail = a_tail->next;
a_head = a_head->next;
}
}
return alist;
}
输出结果:

2. 合并非递减链表
![]()
代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype *elem;
int length;
}sqlsit;
typedef struct
{
elemtype data;
struct lnode *next;
}lnode, *linklist;
status init(linklist list);
void create(linklist list, elemtype data[]);
void print(linklist list);
void destroy(linklist list);
void merge(linklist alist, linklist blist, linklist clist);
void main() {
lnode a_list,b_list;
init(&a_list);
init(&b_list);
int a[10] = {1,3,5,5,9,11,13,15,15,19};
int b[10] = {2,4,6,8,10,10,14,16,16,20};
create(&a_list, a);
create(&b_list, b);
print(&a_list);
print(&b_list);
printf("\n");
lnode c_list;
init(&c_list);
merge(&a_list, &b_list, &c_list);
print(&c_list);
//destroy(&a_list);
//destroy(&b_list);
}
status init(linklist list) {
list = (linklist) malloc (sizeof(lnode));
list->next = NULL;
list->data = 10;
return OK;
}
void create(linklist list, elemtype data[10]) {
lnode *tail = list;
for(int i = 0; i < 10; i++) {
linklist p = (lnode *) malloc(sizeof(elemtype));
p->data = data[i];
tail->next = p;
p->next = NULL;
tail = p;
}
}
void print(linklist list) {
linklist tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(linklist list) {
linklist tail = list->next;
for(int i = 0; i <= 10; i++) {
list->next = NULL;
free(list);
list = tail;
tail = tail->next;
}
}
void merge(linklist alist, linklist blist, linklist clist) {
lnode *a_node = alist->next;
lnode *b_node = blist->next;
while(a_node && b_node) {
if(a_node->data > b_node->data) {
blist->next = b_node->next;
b_node->next = NULL;
clist->next = b_node;
clist = b_node;
b_node = blist->next;
} else {
alist->next = a_node->next;
a_node->next = NULL;
clist->next = a_node;
clist = a_node;
a_node = alist->next;
}
}
clist->next = a_node ? a_node : b_node;
free(a_node);
free(b_node);
}
输出结果:

3.求A表和B表的交集

代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype data;
struct lnode *next;
}lnode, *linklist;
status init(lnode *list);
void create(lnode *list, elemtype data[]);
void print(lnode *list);
void destroy(lnode *list);
void common(lnode *alist, lnode *blist, lnode *clist);
void main() {
lnode a_list,b_list;
init(&a_list);
init(&b_list);
int a[10] = {1,3,5,7,9,10,13,15,17,19};
int b[10] = {2,4,6,8,10,12,15,16,18,20};
create(&a_list, a);
create(&b_list, b);
print(&a_list);
print(&b_list);
lnode c_list;
init(&c_list);
common(&a_list, &b_list, &c_list);
printf("\nThe common elem between A and B is:");
print(&c_list);
destroy(&a_list);
destroy(&b_list);
destroy(&c_list);
}
status init(lnode *list) {
list = (lnode *) malloc (sizeof(lnode *));
list->next = NULL;
list->data = 10;
return OK;
}
void create(lnode * list, elemtype data[10]) {
lnode *tail = list;
for(int i = 0; i < 10; i++) {
lnode * p = (lnode *) malloc(sizeof(elemtype));
p->data = data[i];
tail->next = p;
p->next = NULL;
tail = p;
}
}
void print(lnode * list) {
lnode *tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(lnode *list) {
while(list) {
lnode *temp = list;
list = list->next;
temp = NULL;
if(temp)free(temp);
}
}
void common(lnode *alist, lnode *blist, lnode *clist) {
lnode *a_head = alist;
lnode *a_tail = alist->next;
lnode *b_tail = blist->next;
lnode *c_tail = clist;
while(b_tail) {
while(a_tail) {
if(a_tail->data == b_tail->data) {
a_head->next = a_tail->next;//delete a node
a_tail->next = NULL;
c_tail->next = a_tail;
c_tail = a_tail;
break;
}
a_head = a_head->next;
a_tail = a_tail->next;
}
b_tail = b_tail->next;
a_head = alist;
a_tail = alist->next;
}
}
输出结果:

4. 求集合A和集合B的差集

算法分析:
依次判断A的元素不在B中,就输出这些元素到C集合中。
代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype data;
struct lnode *next;
}lnode, *linklist;
status init(lnode *list);
void create(lnode *list, elemtype data[]);
void print(lnode *list);
void destroy(lnode *list);
void minus(lnode *alist, lnode *blist, lnode *clist);
void main() {
lnode a_list,b_list;
init(&a_list);
init(&b_list);
int a[10] = {1,3,5,7,9,10,13,15,17,19};
int b[10] = {2,4,6,8,10,12,15,16,18,20};
create(&a_list, a);
create(&b_list, b);
print(&a_list);
print(&b_list);
lnode c_list;
init(&c_list);
minus(&a_list, &b_list, &c_list);
printf("\nThe common elem between A and B is:");
print(&c_list);
destroy(&a_list);
destroy(&b_list);
destroy(&c_list);
}
status init(lnode *list) {
list = (lnode *) malloc (sizeof(lnode *));
list->next = NULL;
list->data = 10;
return OK;
}
void create(lnode * list, elemtype data[10]) {
lnode *tail = list;
for(int i = 0; i < 10; i++) {
lnode * p = (lnode *) malloc(sizeof(elemtype));
p->data = data[i];
tail->next = p;
p->next = NULL;
tail = p;
}
}
void print(lnode * list) {
lnode *tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(lnode *list) {
while(list) {
lnode *temp = list;
list = list->next;
temp = NULL;
if(temp)free(temp);
}
}
void minus(lnode *alist, lnode *blist, lnode *clist) {
lnode *a_head = alist;
lnode *a_tail = alist->next;
lnode *b_tail = blist->next;
lnode *c_tail = clist;
while(a_tail) {
while(b_tail) {
if(a_tail->data == b_tail->data) {
break;
}
b_tail = b_tail->next;
}
if(!b_tail) {
a_head->next = a_tail->next;
a_tail->next = NULL;
c_tail->next = a_tail;
c_tail = a_tail;
a_tail = a_head->next;
} else {
a_head = a_head->next;
a_tail = a_head->next;
}
b_tail = blist->next;
}
}
输出结果:

5.拆解表A成复数表B和正数表C.

代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype data;
struct lnode *next;
}lnode, *linklist;
status init(lnode *list);
void create(lnode *list, elemtype data[]);
void print(lnode *list);
void destroy(lnode *list);
void split(lnode *alist, lnode *blist, lnode *clist);
void main() {
lnode a_list;
init(&a_list);
int a[10] = {1,3,5,7,9,10,-1,-3,-5,-10};
create(&a_list, a);
print(&a_list);
lnode b_list,c_list;
init(&b_list);
init(&c_list);
split(&a_list, &b_list, &c_list);
printf("\nThe < 0 elem B from A is:");
print(&b_list);
printf("\nThe > 0 elem C from A is:");
print(&c_list);
destroy(&a_list);
destroy(&b_list);
destroy(&c_list);
}
status init(lnode *list) {
list = (lnode *) malloc (sizeof(lnode*));
list->next = NULL;
list->data = 10;
return OK;
}
void create(lnode * list, elemtype data[10]) {
lnode *tail = list;
for(int i = 0; i < 10; i++) {
lnode * p = (lnode *) malloc(sizeof(elemtype));
p->data = data[i];
tail->next = p;
p->next = NULL;
tail = p;
}
}
void print(lnode * list) {
lnode *tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(lnode *list) {
while(list) {
lnode *temp = list;
list = list->next;
temp = NULL;
if(temp)free(temp);
}
}
void split(lnode *alist, lnode *blist, lnode *clist) {
lnode *a_head = alist;
lnode *a_tail = alist->next;
lnode *b_tail = blist;
lnode *c_tail = clist;
while(a_tail) {
if(a_tail->data < 0) {
a_head->next = a_tail->next;
a_tail->next = NULL;
b_tail->next = a_tail;
b_tail = b_tail->next;
a_tail = a_head->next;
} else if(a_tail->data > 0) {
a_head->next = a_tail->next;
a_tail->next = NULL;
c_tail->next = a_tail;
c_tail = c_tail->next;
a_tail = a_head->next;
} else {
a_head = a_head->next;
a_tail = a_tail->next;
}
}
}
输出结果:

6.求最大值。
![]()
代码:
#include "stdio.h"
#define MAXSIZE 10
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype *elem;
int length;
}sqlsit;
status init(sqlsit *list);
void create(sqlsit *list, elemtype data[]);
void print(sqlsit list);
void destroy(sqlsit *list);
elemtype max(sqlsit list);
void main() {
sqlsit list;
init(&list);
int a[10] = {1,3,5,7,9,11,13,15,17,19};
create(&list, a);
print(list);
elemtype i = max(list);
printf("\nThe %d node of list is max:%d", i, list.elem[i-1]);
destroy(&list);
}
status init(sqlsit *L) {
L->length = MAXSIZE;
L->elem = (elemtype *) malloc(MAXSIZE*sizeof(elemtype));
if(!L->elem) exit(ERROR);
return OK;
}
void create(sqlsit *list, elemtype data[10]) {
for(int i = 0; i < 10; i++) {
list->elem[i] = data[i];
}
}
void print(sqlsit list) {
for(int i = 0; i < list.length; i++) {
printf("%d,", list.elem[i]);
}
}
void destroy(sqlsit *list) {
if(list)free(list->elem);
}
elemtype max(sqlsit list) {
elemtype max = 0;
for(int i = 0; i < list.length; i++) {
if(max < list.elem[i]) max = i+1;
}
return max;
}
输出结果:

7.将链表链接方向逆转。
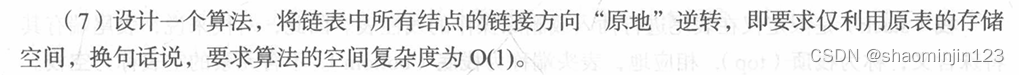
算法分析:
第一步:定义一个操作指针指a向头节点的下一个结点, 再定义一个标记指针b,指向操作指针的下一个元素。
第二步:修改操作指针的转向,同时将标记位b赋给a, 标记指针后移一位。
第三步:重复第一,第二步,直到b移到最后一个指针结束。
代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype data;
struct lnode *next;
}lnode, *linklist;
status init(lnode *list);
void create(lnode *list, elemtype data[]);
void print(lnode *list);
void destroy(lnode *list);
lnode *reverse(lnode *list);
void main() {
lnode a_list;
init(&a_list);
int a[10] = {1,3,5,7,9,10,-1,-3,-5,-10};
create(&a_list, a);
//print(&a_list);
lnode *list = reverse(&a_list);
print(list);
destroy(&a_list);
}
status init(lnode *list) {
list = (lnode *) malloc (sizeof(lnode*));
list->next = NULL;
list->data = 10;
return OK;
}
void create(lnode * list, elemtype data[10]) {
lnode *tail = list;
for(int i = 0; i < 10; i++) {
lnode * p = (lnode *) malloc(sizeof(elemtype));
p->data = data[i];
tail->next = p;
p->next = NULL;
tail = p;
}
}
void print(lnode * list) {
lnode *tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(lnode *list) {
while(list) {
lnode *temp = list;
list = list->next;
temp = NULL;
if(temp)free(temp);
}
}
lnode *reverse(lnode *list) {
lnode *a = list->next;
lnode *b = a->next;
list->next = NULL;
lnode *head = a;
while(a->next) {
a->next = list;
list = a;
a = b;
b = b->next;
}
a->next = list;
list = head->next;
list->next = a;
head->next = NULL;
return list;
}
输出结果:

8. 删除链表中的部分结点

算法分析:
第一步:找到第一个大于mink的位置,然后记下该位置a;
第二步:找到第一个大于maxk的位置,然后记下该位置b。
第三步: 删除a到b之间的结点。
代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype data;
struct lnode *next;
}lnode, *linklist;
status init(lnode *list);
void create(lnode *list, elemtype data[]);
void print(lnode *list);
void destroy(lnode *list);
void delete(lnode *list, int mink, int maxk);
void main() {
lnode a_list;
init(&a_list);
int a[10] = {1,3,5,7,9,11,13,15,17,19};
create(&a_list, a);
print(&a_list);
delete(&a_list, 6, 20);
printf("\n");
print(&a_list);
destroy(&a_list);
}
status init(lnode *list) {
list = (lnode *) malloc (sizeof(lnode*));
list->next = NULL;
list->data = 10;
return OK;
}
void create(lnode * list, elemtype data[10]) {
lnode *tail = list;
for(int i = 0; i < 10; i++) {
lnode * p = (lnode *) malloc(sizeof(elemtype));
p->data = data[i];
tail->next = p;
p->next = NULL;
tail = p;
}
}
void print(lnode * list) {
lnode *tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(lnode *list) {
while(list) {
lnode *temp = list;
list = list->next;
temp = NULL;
if(temp)free(temp);
}
}
void delete(lnode *list, int mink, int maxk) {
lnode *min = list;
lnode *max = list->next;
lnode *node = list->next;
while(node->next) {
min = node->next;
if(min->data > mink) {
min = node;
break;
}
node = node->next;
}
if(!node->next)return;
while(node->next) {
max = node->next;
if(maxk < max->data) {
max = node;
break;
}
node = node->next;
}
node = min->next;
min->next = max->next;
max->next = NULL;
//destroy(&node);
}
输出结果:

9. 双链表的交换结点

算法分析:
第一步:先删除p结点
第二步:在p结点的前驱结点前插入该节点。
代码:
#include "stdio.h"
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype data;
struct dlnode *next;
struct dlnode *prior;
}dlnode, *dlinklist;
status init(dlnode *list);
void create(dlnode *list, elemtype data[]);
void print(dlnode *list);
void destroy(dlnode *list);
void change(dlnode *list, int p);
void main() {
dlnode a_list;
init(&a_list);
int a[10] = {1,3,5,7,9,11,13,15,17,19};
create(&a_list, a);
print(&a_list);
change(&a_list, 7);
printf("\n");
print(&a_list);
//destroy(&a_list);
}
status init(dlnode *list) {
list = (dlnode *) malloc (sizeof(dlnode*));
list->next = NULL;
list->prior = NULL;
return OK;
}
void create(dlnode * list, elemtype data[10]) {
dlnode *tail = list;
for(int i = 0; i < 10; i++) {
dlnode *p = (dlnode *) malloc(sizeof(dlnode));
p->data = data[i];
tail->next = p;
p->next = NULL;
p->prior = tail;
tail = p;
}
}
void print(dlnode * list) {
dlnode *tail = list->next;
while(tail) {
printf("%d,", tail->data);
tail = tail->next;
}
}
void destroy(dlnode *list) {
while(list) {
dlnode *temp = list;
list = list->next;
temp = NULL;
if(temp)free(temp);
}
}
void change(dlnode *list, int p) {
dlnode *pri = list;
while(pri) {
if(pri->data == p) break;
pri = pri->next;
}
if(!pri) return;
dlnode *tail = pri->next;
dlnode *head = pri->prior;
head->next = tail;
tail->prior = head;
head = head->prior;
tail = tail->prior;
head->next = pri;
pri->prior = head;
pri->next = tail;
tail->prior = pri;
}
输出结果:

10.输出指定重复元素

算法分析:
第一步:遍历顺序表找到等于Item的结点i同时用j统计删除结点的个数,同时把最大数赋给删除结点,
第二步:如果A[i]不是输出结点A[i-j]=A[i].
第三步:重复以上步骤,直到遍历完整个顺序表。
代码:
#include "stdio.h"
#define MAXSIZE 10
#define OK 1
#define ERROR 0
typedef int elemtype;
typedef int status;
typedef struct
{
elemtype *elem;
int length;
}sqlsit;
status init(sqlsit *list);
void create(sqlsit *list, elemtype data[]);
void print(sqlsit list);
void destroy(sqlsit *list);
void delete(sqlsit *list, elemtype item);
void main() {
sqlsit list;
init(&list);
int a[10] = {1,3,5,7,9,11,13,15,17,19};
create(&list, a);
print(list);
delete(&list, 3);
print(list);
destroy(&list);
}
status init(sqlsit *L) {
L->length = MAXSIZE;
L->elem = (elemtype *) malloc(MAXSIZE*sizeof(elemtype));
if(!L->elem) exit(ERROR);
return OK;
}
void create(sqlsit *list, elemtype data[10]) {
for(int i = 0; i < 10; i++) {
list->elem[i] = data[i];
}
}
void print(sqlsit list) {
for(int i = 0; i < list.length; i++) {
printf("%d,", list.elem[i]);
}
}
void destroy(sqlsit *list) {
if(list)free(list->elem);
}
void delete(sqlsit *list, elemtype item) {
for(int i = 0; i < list->length; i++) {
if(item == list->elem[i]) {
list->elem[i] = 0xffffffff;
}
}
int j = 0;
for(int i = 0; i < list->length; i++) {
if(list->elem[i] == 0xffffffff) {
j++;
} else {
list->elem[i-j] = list->elem[i];
}
}
elemtype *del = &list->elem[list->length-j];
list->length = list->length - j;
//free(del);
}
输出结果:

1.选择题

- 100 + (5-1) * 2 = 108 选B
- A
- (126+1)/2 = 65 选B
- A
- D

- 11.B
- 12.D
- 13.A
- 14.A
- 15.C






![[通用人工智能] 论文分享:ElasticViT:基于冲突感知超网的快速视觉Transformer](https://img-blog.csdnimg.cn/direct/cd26178d936e468fa0002af1e1809778.png)