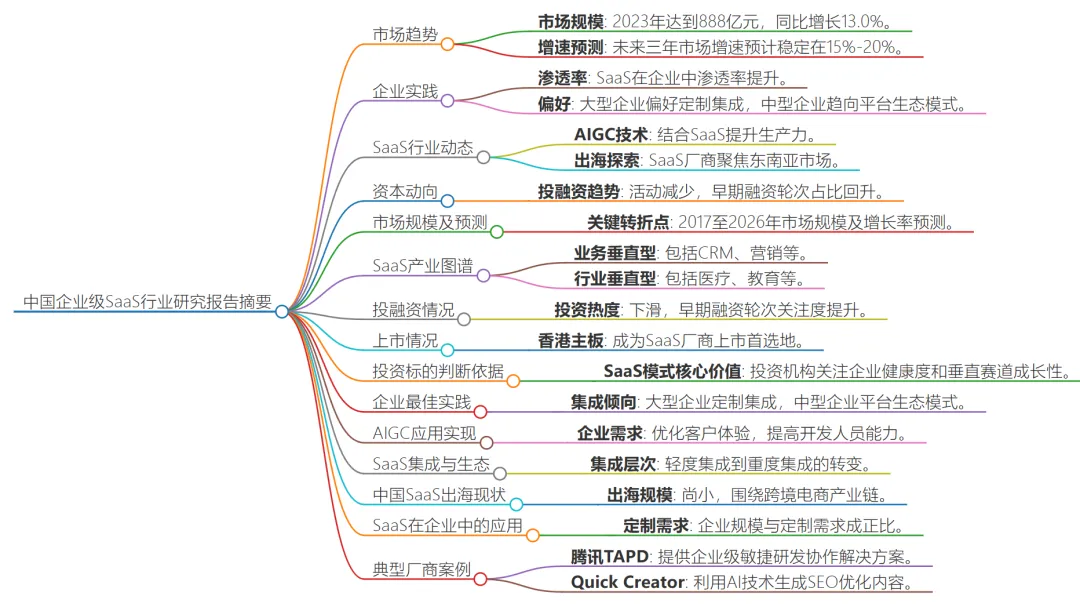
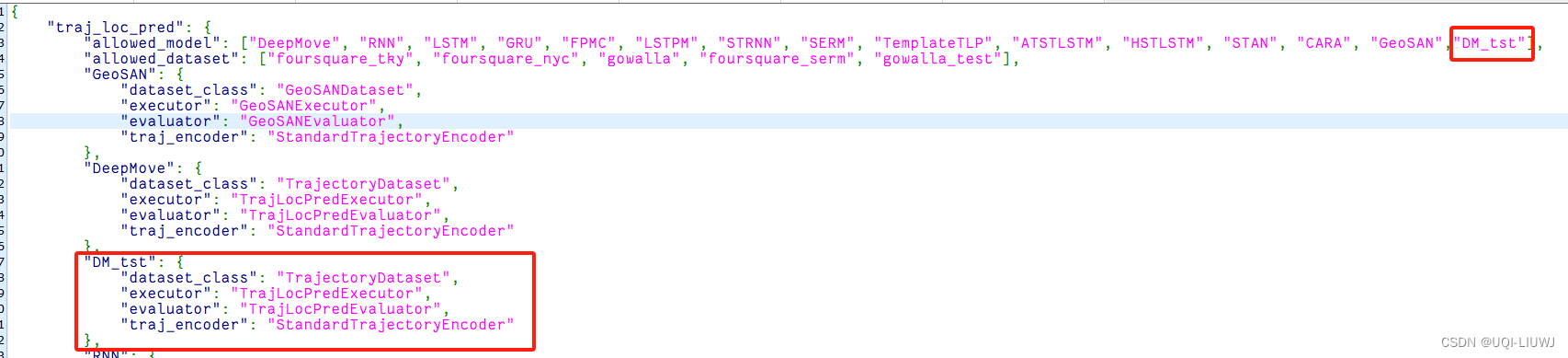
文章目录
- @[toc]
- HDFS 1.0
- NameNode
- 维护文件系统命名空间
- 存储元数据
- 解决NameNode单点问题
- SecondaryNameNode
- 机架感知
- 数据完整性校验
- 校验和
- 数据块检测程序DataBlockScanner
- HDFS写流程
- HDFS读流程
- HDFS与MapReduce本地模式
- Block大小
- HDFS 2.0
- NameNode HA
- NameNode Federation
- HDFS Snapshot
- 缓存
- ACL
- Block大小
文章目录
- @[toc]
- HDFS 1.0
- NameNode
- 维护文件系统命名空间
- 存储元数据
- 解决NameNode单点问题
- SecondaryNameNode
- 机架感知
- 数据完整性校验
- 校验和
- 数据块检测程序DataBlockScanner
- HDFS写流程
- HDFS读流程
- HDFS与MapReduce本地模式
- Block大小
- HDFS 2.0
- NameNode HA
- NameNode Federation
- HDFS Snapshot
- 缓存
- ACL
- Block大小

个人主页:丷从心·
系列专栏:大数据

HDFS 1.0
NameNode
维护文件系统命名空间
存储元数据
- 元数据存储在内存中
- 维护文件名 → B l o c k \rightarrow Block →Block、 B l o c k → D a t a N o d e Block \rightarrow DataNode Block→DataNode的映射关系
- 持久化元数据的文件是 f s i m a g e fsimage fsimage
- 所有对元数据的操作都保存在内存中并被持久化到文件 e d i t l o g s edit \ logs edit logs中
- e d i t l o g s edit \ logs edit logs文件和 f s i m a g e fsimage fsimage文件会被 S e c o n d a r y N a m e N o d e SecondaryNameNode SecondaryNameNode周期性地合并
解决NameNode单点问题
- 将 H a d o o p Hadoop Hadoop元数据写入到本地文件系统的同时再实时同步到一个远程挂载的网络文件系统( N F S NFS NFS)中
- 当 N a m e N o d e NameNode NameNode发生故障时 S e c o n d a r y N a m e N o d e SecondaryNameNode SecondaryNameNode会通过自己合并的命名空间镜像 f s i m a g e fsimage fsimage副本来恢复 N a m e N o d e NameNode NameNode,但是 S e c o n d a r y N a m e N o d e SecondaryNameNode SecondaryNameNode保存的状态总是滞后于 N a m e N o d e NameNode NameNode,难免会丢失部分数据
SecondaryNameNode

- N a m e N o d e NameNode NameNode在下次重启时会使用新的 f s i m a g e fsimage fsimage文件,从而减少重启时间
机架感知
- 机架感知是 B l o c k Block Block副本放置策略
- 第一个副本放在客户端节点,如果客户端是集群外的一台机器,就随机选择节点,但是会避免挑选太满或者太忙的节点
- 第二个副本放在不同机架的节点
- 第三个副本放在与第二个副本同机架但是不同节点上
数据完整性校验
校验和
- 在第一次进入系统时计算数据的校验和,在通道传输后,如果新生成的校验和不完全匹配原始的校验和,那么数据就会被认为是损坏的
数据块检测程序DataBlockScanner
- 在 D a t a N o d e DataNode DataNode节点上开启一个后台线程,来定期验证存储在它上的所有块,防止物理介质出现损减而造成的数据损坏
- 一旦发现数据块损坏, D a t a N o d e DataNode DataNode会接收到 N a m e N o d e NameNode NameNode发送的 B l o c k Block Block修复指令
HDFS写流程

- F S D a t a O u t p u t S t r e a m FSData \ OutputStream FSData OutputStream将原始数据切分成数据块并写入一个队列
- 数据弱一致性:第一个副本写入后就立刻返回 A C K ACK ACK
HDFS读流程

HDFS与MapReduce本地模式
- 数据不移动,代码逻辑移动
Block大小
- H D F S 1.0 HDFS \ 1.0 HDFS 1.0默认 B l o c k Block Block大小为 64 M B 64 MB 64MB
HDFS 2.0
NameNode HA

- 运行 A c t i v e N a m e N o d e Active \ NameNode Active NameNode与 S t a n d b y N a m e N o d e Standby \ NameNode Standby NameNode的机器需要相同的硬件配置
- J o u r n a l N o d e JournalNode JournalNode本质是共享的网络文件系统,由奇数个节点组成,用于存储 e d i t l o g s edit \ logs edit logs
- F a i l o v e r C o n t r o l l e r FailoverController FailoverController本质是 Z o o K e e p e r ZooKeeper ZooKeeper的客户端,监控 N a m e N o d e NameNode NameNode状态信息,实现故障转移
NameNode Federation

- N a m e N o d e F e d e r a t i o n NameNode \ Federation NameNode Federation本质是命名空间的分离,解决了 N a m e N o d e NameNode NameNode内存资源不足的问题
- 一个 N a m e s p a c e Namespace Namespace对应一个 B l o c k P o o l Block \ Pool Block Pool,即一个 N a m e s p a c e Namespace Namespace下的所有 B l o c k Block Block的集合
- 通过视图文件系统 V i e w F S ViewFS ViewFS管理全局 N a m e s p a c e Namespace Namespace
HDFS Snapshot
- S n a p s h o t Snapshot Snapshot常用来作为数据备份
- S n a p s h o t Snapshot Snapshot只记录了文件系统元数据信息,并没有进行数据的拷贝
缓存
- H D F S 2.0 HDFS \ 2.0 HDFS 2.0支持集中式缓存,可以明确指定要缓存数据
- 支持对非递归目录和文件的缓存
ACL
- H D F S 2.0 HDFS \ 2.0 HDFS 2.0支持 A C L ACL ACL管理
Block大小
- H D F S 2.0 HDFS \ 2.0 HDFS 2.0默认 B l o c k Block Block大小为 128 M B 128 MB 128MB