序列到序列模型在语言识别Speech Applications中的应用
A Comparative Study on Transformer vs RNN in Speech Applications
序列到序列(Seq2Seq)模型在语音识别(Speech Applications)中有重要的应用。虽然Seq2Seq模型最初是为了解决自然语言处理中的序列生成问题而设计的,特别是机器翻译,但它在语音识别领域也展现出了强大的能力。
在语音识别中,Seq2Seq模型可以将输入的语音信号(即声音波形)转化为文字序列。这个过程通常包括两个主要步骤:首先,编码器(Encoder)将输入的语音信号转换为一种中间表示形式,这通常是一个固定长度的向量或者一系列向量。然后,解码器(Decoder)根据这个中间表示来生成对应的文字序列。
具体来说,在编码器部分,通常使用循环神经网络(RNN)或其变种(如长短期记忆网络LSTM或门控循环单元GRU)来处理输入的语音信号。这些网络能够捕捉语音信号中的时间依赖关系,并将其转换为一种适合解码器处理的表示形式。
在解码器部分,同样可以使用RNN或其变种来根据编码器的输出生成文字序列。解码器通常使用一种称为“注意力机制”(Attention Mechanism)的技术来关注输入序列中的不同部分,从而更准确地生成对应的输出。
通过结合编码器和解码器,Seq2Seq模型能够实现从语音信号到文字序列的转换,这在智能家居、智能客服等领域具有广泛的应用前景。例如,智能音箱可以通过语音识别技术来理解用户的语音指令,并执行相应的操作;智能客服系统也可以通过语音识别来与用户进行交互,提供更高效、更便捷的服务。
总的来说,Seq2Seq模型在语音识别中的应用展示了深度学习在处理序列数据方面的强大能力,为语音交互技术的发展提供了有力的支持。
介绍
随着深度学习技术的不断发展,Transformer模型在序列到序列任务中逐渐取代了传统的RNN模型,尤其是在自动语音识别(ASR)、语音翻译(ST)和文本到语音(TTS)等语音处理领域。以下是对您描述的论文内容的进一步概述和扩展:
将Transformer应用于语音的主要困难
Transformer模型在NLP领域取得了巨大成功,但在将其应用于语音领域时,面临了一些挑战。首先,语音数据通常具有更高的时间分辨率,这要求模型能够处理更长的序列。而Transformer模型在处理长序列时,由于自注意力机制的计算复杂度是O(n^2),可能导致计算资源和时间的急剧增加。
此外,语音数据中的特征表示通常与文本数据不同。在NLP中,单词或字符通常是模型的输入单元,而在语音中,常用的输入单元是帧级别的声学特征(如MFCC或log-Mel spectrograms)。这要求模型能够适应不同类型的输入数据。
Transformer与RNN的比较研究
论文通过大规模的实验比较了Transformer和RNN在ASR任务中的性能。实验结果显示,Transformer模型在多个数据集上均取得了比RNN模型更好的性能。这主要得益于Transformer模型中的自注意力机制,它能够捕捉输入序列中的全局依赖关系,而不仅仅是局部依赖关系。
Transformer在语音应用中的训练技巧
论文还提供了一些针对语音应用的Transformer训练技巧,这些技巧包括:
优化器选择:选择适合语音数据的优化器,如Adam、Noam学习率衰减等。
网络结构设计:针对语音数据的特性,设计合适的网络结构,如调整Transformer中的编码器和解码器的层数、注意力头数等。
数据增强:采用数据增强技术来增加训练数据的多样性,如添加噪声、混响、速度扰动等。
预训练:利用大规模无标注语音数据进行预训练,以提高模型的泛化能力。
开放源代码工具包ESPnet
论文还在ESPnet工具包中提供了可复制的端到端配置和预训练模型。ESPnet是一个用于端到端语音处理的开源工具包,它支持多种任务(如ASR、ST、TTS)和多种模型(如RNN、Transformer)。通过在ESPnet中提供预训练的模型和配置,其他研究人员可以更容易地复现论文中的实验结果,并进一步探索Transformer在语音处理中的应用。
将Transformer应用于语音处理领域是一个有前景的研究方向。通过克服一些挑战并采用合适的训练技巧,Transformer模型可以在ASR、ST和TTS等任务中取得更好的性能。同时,开放源代码工具包如ESPnet为研究人员提供了方便的实验平台,促进了该领域的发展。
序列到序列模型已广泛用于端到端语音处理中,例如自动语音识别(ASR),语音翻译(ST)和文本到语音(TTS)。本文着重介绍把Transformer应用在语音领域上并与RNN进行对比。与传统的基于RNN的模型相比,将Transformer应用于语音的主要困难之一是,它需要更复杂的配置(例如优化器,网络结构,数据增强)。在语音应用实验中,论文研究了基于Transformer和RNN的系统的几个方面,例如,根据所有标注数据、训练曲线和多个GPU的可伸缩性来计算单词/字符/回归错误。本文的几个主要贡献:
- 将Transformer和RNN进行了大规模的比较研究,尤其是在ASR相关任务方面,它们具有显着的性能提升。
- 提供了针对语音应用的Transformer的训练技巧:包括ASR,TTS和ST
- 在开放源代码工具包ESPnet中提供了可复制的端到端配置和模型,这些配置和模型已在大量可公开获得的数据集中进行了预训练。
端到端RNN
如下图中,说明了实验用于ASR,TTS和ST任务的通用S2S结构。
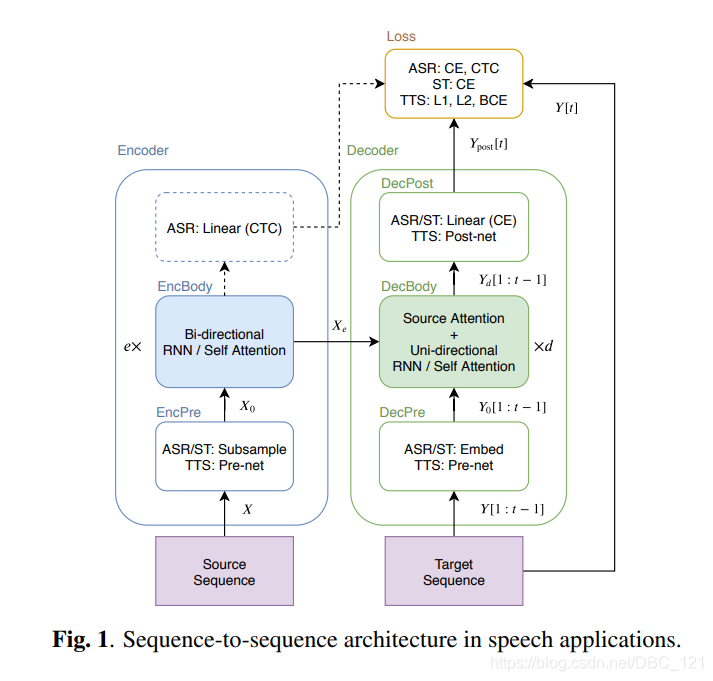
S2S包含两个神经网络:其中编码器如下:
( 1 ) : X 0 = E n c P r e ( X ) (1):X_0=EncPre(X) (1):X0=EncPre(X) ( 2 ) : X e = E n c B o d y ( X 0 ) (2):X_e=EncBody(X_0) (2):Xe=EncBody(X0)
解码器如下:
( 3 ) : Y 0 [ 1 : t − 1 ] = D e c P r e ( Y [ 1 : t − 1 ] ) (3):Y_0[1:t-1]=DecPre(Y[1:t-1]) (3):Y0[1:t−1]=DecPre(Y[1:t−1]) ( 4 ) : Y d [ t ] = D e c B o d y ( X e , Y 0 [ 1 : t − 1 ] ) (4):Y_d[t]=DecBody(X_e,Y_0[1:t-1]) (4):Yd[t]=DecBody(Xe,Y0[1:t−1]) ( 5 ) : Y p o s t [ 1 : t ] = D e c P o s t ( Y d [ 1 : t ] ) (5):Y_{post}[1:t]=DecPost(Y_d[1:t]) (5):Ypost[1:t]=DecPost(Yd[1:t])
其中 X X X 是源序列,例如,语音特征序列(对于ASR和ST)或字符序列(对于TTS), e e e 是EncBody层数, d d d 是DecBody中的层数, t t t 是目标帧索引,以上等式中的所有方法均由神经网络实现。对于解码器输入 Y [ 1 : t − 1 ] Y [1:t − 1] Y[1:t−1],我们在训练阶段使用一个真实标注的前缀,而在解码阶段使用一个生成的前缀。在训练过程中,S2S模型学习是将在生成的序列 Y p o s t Y_{post} Ypost 和目标序列 Y Y Y 之间标量损失值最小化:
( 6 ) : L = L o s s ( Y p o s t , Y ) (6):L=Loss(Y_{post},Y) (6):L=Loss(Ypost,Y)
本节的其余部分描述了基于RNN的通用模块:“EncBody”和“DecBody”。而将“EncPre”,“DecPre”,“DecPost”和“Loss”视为特定于任务的模块,我们将在后面的部分中介绍。
等式(2)中的EncBody将源序列 X 0 X_0 X0 转换为中间序列 X e X_e Xe,现有的基于RNN的EncBody实现通常采用双向长短记忆(BLSTM)。对于ASR,编码序列 X e X_e Xe 还可以在进行联合训练和解码中,用基于神经网络的时序类分类(CTC)进行逐帧预测。
等式(4)中的DecBody()将生成具有编码序列 X e X_e Xe 和目标前缀 Y 0 [ 1 : t − 1 ] Y_0 [1:t − 1] Y0[1:t−1] 的前缀的下一个目标帧。对于序列生成,解码器通常是单向的。 例如,具有注意力机制的单向LSTM通常用于基于RNN的DecBody()实现中。该注意力机制计算逐帧权重,以将编码后的帧 X e X_e Xe 求和,并作为要以前缀 Y 0 [ 0 : t − 1 ] Y0 [0:t-1] Y0[0:t−1] 进行转换的逐帧目标向量,我们称这种注意为“encoder-decoder attention”
Transformer
Transformer包含多个dot-attention层:
( 7 ) : a t t ( X q , X k , X v ) = s o f t m a x ( X q X k T d a t t ) X v (7):att(X^q,X^k,X^v)=softmax(\frac{X^qX^{kT}}{\sqrt{d^{att}}})X^v (7):att(Xq,Xk,Xv)=softmax(dattXqXkT)Xv
其中 X k , X v ∈ R n k × d