框架的主要成分称为 DEtection TRansformer 或 DETR,是基于集合的全局损失,它通过二分匹配强制进行独特的预测,以及 Transformer 编码器-解码器架构。
DETR 会推理对象与全局图像上下文的关系,以直接并行输出最终的预测集。
1. 介绍
对象检测的目标是预测每个感兴趣对象的一组边界框和类别标签。
在计算机图形学和图像处理中,锚点(Anchor Point)是一个特定的位置,通常用于描述图像中的特征点或区域。它可以是单个像素点,也可以是一个更复杂的区域如矩形或椭圆。锚点的主要作用是为图像处理和计算机视觉任务提供一个参考点,以便更准确地描述和定位图像中的特征。在目标检测任务中,锚点用于预测目标物体的位置和大小;在图像匹配任务中,它帮助找到图像中的相似区域。
DETR 通过将通用 CNN 与 Transformer 架构相结合来直接(并行)预测最终的检测集。

二分匹配:模型的预测结果(包括坐标和类别概率)与真实框之间会进行最优的一一配对,即每个预测结果都会与一个真实框(或背景类,如果没有真实框与之匹配)进行匹配。
通过将对象检测视为直接集合预测问题来简化训练流程。我们采用基于 Transformer 的编码器-解码器架构,这是一种流行的序列预测架构。 Transformer 的自注意力机制明确地模拟了序列中元素之间的所有成对交互,使这些架构特别适合集合预测的特定约束,例如删除重复的预测。
DEtection TRansformer(DETR)会同时预测所有对象,并使用一组损失函数进行端到端训练,该函数在预测对象和真实对象之间执行二分匹配。DETR 通过删除多个手工设计的编码先验知识的组件(例如空间锚点或非极大值抑制)来简化检测流程。
DETR 的主要特征是二分匹配损失和Transformer与(非自回归)并行解码的结合。
2. 相关工作
我们的工作建立在多个领域的先前工作的基础上:集合预测的二分匹配损失、基于Transformer的编码器-解码器架构、并行解码和对象检测方法。
2.1 集合预测
基本的集合预测任务是多标签分类,这些任务中的第一个困难是避免近似重复。当前大多数检测器使用非极大值抑制等后处理来解决此问题,但直接集预测无需后处理。他们需要全局推理方案来对所有预测元素之间的交互进行建模,以避免冗余。
后处理主要用于对目标检测算法的输出进行调整和优化,以提高检测结果的准确性和稳定性
损失函数应该通过预测的排列而保持不变。通常的解决方案是基于匈牙利算法设计损失,以找到真实值和预测之间的二分匹配。
匈牙利算法![]() https://blog.csdn.net/qq_52302919/article/details/132170356
https://blog.csdn.net/qq_52302919/article/details/132170356
2.2 Transformer和并行解码
Transformer,作为机器翻译的新的基于注意力的构建块。注意力机制 是聚合来自整个输入序列的信息的神经网络层。 Transformer 引入了自注意力层,与非局部神经网络类似,它扫描序列的每个元素,并通过聚合整个序列的信息来更新它。基于注意力的模型的主要优点之一是它们的全局计算和完美的记忆,这使得它们比 RNN 更适合长序列。
RNN循环神经网络![]() https://blog.csdn.net/zyf918/article/details/136172798
https://blog.csdn.net/zyf918/article/details/136172798
Transformer 最初用于自回归模型,遵循早期的序列到序列模型 ,一一生成输出标记。结合了变压器和并行解码,以在计算成本和执行集合预测所需的全局计算的能力之间进行适当的权衡。
Transformer模型中,并行解码(Parallel Decoding)指的是解码器(Decoder)部分能够同时处理多个输出位置,而不是像传统的递归神经网络(RNN)那样逐个位置地顺序生成输出。
2.3 对象检测
大多数现代物体检测方法都会根据一些初始猜测进行预测。在我们的模型中,通过使用绝对框预测直接预测检测集来简化检测过程。输入图像而不是锚点。
基于集合的损失
一些物体检测器使用了二分匹配损失。然而,在这些早期的深度学习模型中,不同预测之间的关系仅使用卷积层或全连接层进行建模。最近的检测器使用地面实况和预测之间的非唯一分配规则以及 NMS(非极大值抑制)。
NMS的主要目的是解决目标检测算法输出目标框时的重叠问题。在目标检测任务中,算法通常会生成多个候选框来表示可能包含目标的区域。这些候选框往往会有一定的重叠,NMS的作用就是对这些重叠的候选框进行筛选,以保留最优的检测结果。
可学习的 NMS 方法和关系网络通过注意力显式地建模不同预测之间的关系。使用直接设置损失。然而,这些方法采用额外的手工制作的上下文特征 来有效地建模检测之间的关系,同时我们寻找减少模型中编码的先验知识的解决方案。
循环检测器
最接近的方法的是对象检测和实例分割的端到端集合预测。
使用基于 CNN 激活的编码器-解码器架构的二分匹配损失来直接生成一组边界框。
3. DETR模型
对于检测中的直接集合预测来说,有两个要素至关重要:
(1) 集合预测损失,强制预测框和真实框之间进行唯一匹配;
(2) 一种能够(在一次传递中)预测一组对象并对其关系进行建模的架构。
3.1 对象检测集预测损失
DETR 在通过解码器的单次传递中推断出一组固定大小的 N 个预测,其中 N 设置为明显大于图像中对象的典型数量。训练的主要困难之一是根据真实情况对预测对象(类别、位置、大小)进行评分。我们的损失在预测对象和真实对象之间产生最佳二分匹配,然后优化特定于对象(边界框)的损失。
y 表示对象的真实集合,并且 表示 N 个预测的集合。假设 N 大于图像中的对象数量,我们也将 y 视为大小为 N 的集合,并用
填充。为了找到这两个集合之间的二分匹配,我们以最低成本搜索 N 个元素
的排列:
其中是真实值
和索引为
的预测之间的成对匹配成本。
匹配成本考虑了类别预测以及预测框和地面实况框的相似性。
真实集的每个元素 i 都可以视为 ,其中
是目标类标签(可能是
),
是一个向量,定义真实框中心坐标及其相对于图像大小的高度和宽度。
对于索引为 的预测,我们将类
的概率定义为
,将预测框定义为
。利用这些符号,我们将
定义为
。需要找到一对一的匹配来进行直接集预测,而无需重复。
边界框损失
我们的框损失是定义为:
3.2 DETR架构
一个用于提取紧凑特征表示的 CNN 主干、一个编码器-解码器 Transformer 以及一个简单的前馈网络 (FFN),该网络用于提取紧凑的特征表示。做出最终的检测预测。
主干
从初始图像开始,传统的 CNN 主干网生成较低分辨率的激活图
,使用的典型值为 C = 2048 和
。
Transformer编码器
首先,1x1 卷积将高级激活图 f 的通道维度从 C 减少到更小的维度 d。创建新的特征图
。编码器期望一个序列作为输入,因此我们将
的空间维度折叠为一维,从而产生 d×HW 的特征图。每个编码器层都有一个标准架构,由多头自注意力模块和前馈网络(FFN)组成。由于 Transformer 架构是排列不变的,我们用固定位置编码对其进行补充,并将其添加到每个注意层的输入中。
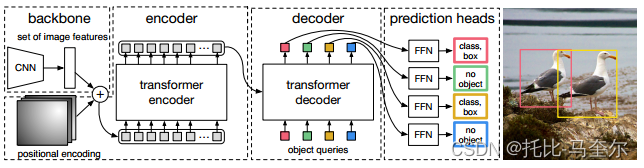
Transformer解码器
解码器遵循 Transformer 的标准架构,使用多头自注意力机制和编码器-解码器注意力机制来转换大小为 d 的 N 个嵌入。与原始 Transformer 的区别在于,我们的模型在每个解码器层并行解码 N 个对象,由于解码器也是排列不变的,因此 N 个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是学习的位置编码,我们将其称为对象查询。
N 个对象查询被解码器转换为输出嵌入。然后通过前馈网络将它们独立解码为框坐标和类标签,从而产生 N 个最终预测。利用对这些嵌入的自注意力和编码器-解码器注意力,该模型使用它们之间的成对关系对所有对象进行全局推理,同时能够使用整个图像作为上下文。
预测前馈网络(FFNs)
最终预测由具有 ReLU 激活函数和隐藏维度 d 的 3 层感知器以及线性投影层计算。FFN 预测框的标准化中心坐标、高度和宽度。输入图像,线性层使用 softmax 函数预测类标签。
辅助解码损失
在每个解码器层之后添加预测 FFN 和匈牙利损失。所有预测 FFN 共享其参数。
使用额外的共享层范数来规范化来自不同解码器层的预测 FFN 的输入。



![[Flutter GetX使用] Getx路由和状态管理-GetController使用过程中的踩坑记录](https://img-blog.csdnimg.cn/direct/a4560dd6203d41c49db5249dc40edea5.png)