🎩 欢迎来到技术探索的奇幻世界👨💻
📜 个人主页:@一伦明悦-CSDN博客
✍🏻 作者简介: C++软件开发、Python机器学习爱好者
🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+
如果文章有所帮助,欢迎留下您宝贵的评论,点赞加收藏支持我,点击关注,一起进步!
目录
前言
正文
01-Ledoit-Wolf与OAS估计器
02-稀疏逆协方差估计
03-收缩协方差估计:LedoitWolf VS OAS和极大似然
04-鲁棒协方差估计与Mahalanobis距离相关性
05-稳健与经验协方差估计
06-交叉分解法比较
总结
参考文献
前言
Scikit-Learn是一个功能丰富的机器学习工具包,提供了许多常用的机器学习算法和工具。其中,协方差估计和交叉分解是其中的两个重要功能,分别用于特征间关系的估计和数据分解。
协方差估计:
协方差是衡量两个变量之间线性关系的统计量,其值的正负表示两个变量之间的关系是正相关还是负相关,而其绝对值大小表示了关系的强度。Scikit-Learn中提供了covariance_estimator模块来进行协方差估计。
EmpiricalCovariance:这个类实现了通过观察样本数据来估计协方差矩阵的方法。它假设样本来自一个未知分布,并计算样本协方差矩阵作为总体协方差矩阵的估计。
ShrunkCovariance:这个类实现了一种通过对观察数据的协方差矩阵进行收缩来改善协方差估计的方法。收缩可以降低估计的方差,特别是在样本量相对较小时。
交叉分解:
交叉分解是一种将数据集分解成两个或多个矩阵的技术,常用于降维、特征提取等任务。Scikit-Learn提供了几种交叉分解的方法:
这些方法可以通过Scikit-Learn的decomposition模块来使用,用户可以根据具体任务选择合适的方法来进行数据分解和特征提取。
PCA:主成分分析是一种常见的线性降维技术,通过找到数据中的主要方差方向来减少特征的数量。
NMF:非负矩阵分解是一种用于从非负数据中提取特征的技术,常用于文本数据、图像数据等。
FastICA:独立成分分析是一种基于独立性原则的盲源信号分离方法,常用于处理混合信号。
正文
01-Ledoit-Wolf与OAS估计器
常用的协方差极大似然估计可以用shrinkage进行正则化。Ledoit和Wolf提出了一个计算渐近最优shrinkage 参数(最小MSE准则)的封闭公式,得到了Ledoit-Wolf协方差估计。
Chen等人提出了一种改进的Ledoit-Wolf shrinkage参数,在假设数据为高斯的情况下,其收敛性明显较好。
Ledoit-Wolf估计器(Ledoit and Wolf, 2004)和OAS(Oracle Approximating Shrinkage)估计器是用于估计协方差矩阵的两种方法,通常用于高维数据的协方差矩阵估计。它们的目标都是通过一些形式的收缩来改善样本协方差矩阵的估计,从而提高估计的稳定性和准确性。
Ledoit-Wolf估计器:
Ledoit-Wolf估计器提出了一种通过对样本协方差矩阵进行收缩来改善协方差估计的方法。该方法的基本思想是,在高维情况下,样本协方差矩阵往往不稳定,因为样本数量远远小于特征数量,导致估计不准确。Ledoit-Wolf方法通过对样本协方差矩阵的特征值进行调整,引入了一些先验信息,从而改善了估计的稳定性。具体来说,Ledoit-Wolf估计器通过最小化经验贝叶斯风险来选择最优的收缩参数,从而得到更加稳定和准确的协方差估计。
OAS估计器:
OAS估计器是对Ledoit-Wolf方法的改进,它提出了一种更精确的收缩方法,能够更好地适应不同的数据结构。OAS估计器采用了一种逼近贝叶斯理论中的“理想收缩”,并通过近似方法得到了一种可行的实现。与Ledoit-Wolf方法相比,OAS估计器更加灵活,能够更好地适应不同数据结构和样本规模。它在实践中表现出更好的性能,并且被证明在许多情况下能够提供更准确和稳定的协方差估计。
这两种方法都在解决高维数据中协方差矩阵估计的挑战方面发挥着重要作用,特别是在金融领域和其他需要处理大规模数据的应用中。它们提供了一种有效的方式来处理协方差矩阵的估计问题,从而为数据分析和建模提供了更可靠的基础。
下面给出具体的代码示例分析两者之间的区别,代码解释如下:代码展示了两种协方差估计器:Ledoit-Wolf(lw)和Oracle Approximating Shrinkage(oa)的比较:
导入库:导入了必要的库 - numpy、matplotlib.pyplot、scipy.linalg用于Toeplitz矩阵生成和Cholesky分解,以及从sklearn.covariance导入的协方差估计器。
参数:n_features:数据中的特征数。r:用于生成协方差矩阵的自回归参数。n_samples_range:生成数据的样本数量范围。repeat:每个样本大小重复的次数,以获得更稳定的结果。
协方差矩阵模拟:使用指定的自回归参数 r 模拟协方差矩阵,采用AR(1)过程。执行Cholesky分解以生成一个着色矩阵。
数据生成和指标计算:对于n_samples_range中的每个样本大小:计算每个估计器的均方误差(MSE)和收缩系数。应用Ledoit-Wolf和OAS估计器。使用着色矩阵和正态分布生成数据。
import numpy as np
import matplotlib.pyplot as plt
from scipy.linalg import toeplitz, cholesky
from sklearn.covariance import LedoitWolf, OAS
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
# Set seed for reproducibility
np.random.seed(0)
# Number of features
n_features = 100
# Simulation covariance matrix (AR(1) process)
r = 0.1
real_cov = toeplitz(r ** np.arange(n_features))
coloring_matrix = cholesky(real_cov)
# Range of number of samples
n_samples_range = np.arange(6, 31, 1)
repeat = 100
# Arrays to store results
lw_mse = np.zeros((n_samples_range.size, repeat))
oa_mse = np.zeros((n_samples_range.size, repeat))
lw_shrinkage = np.zeros((n_samples_range.size, repeat))
oa_shrinkage = np.zeros((n_samples_range.size, repeat))
# Generate data and calculate metrics
for i, n_samples in enumerate(n_samples_range):
for j in range(repeat):
X = np.dot(
np.random.normal(size=(n_samples, n_features)), coloring_matrix.T)
lw = LedoitWolf(store_precision=False, assume_centered=True)
lw.fit(X)
lw_mse[i, j] = lw.error_norm(real_cov, scaling=False)
lw_shrinkage[i, j] = lw.shrinkage_
oa = OAS(store_precision=False, assume_centered=True)
oa.fit(X)
oa_mse[i, j] = oa.error_norm(real_cov, scaling=False)
oa_shrinkage[i, j] = oa.shrinkage_
# Plot settings
plt.figure(figsize=(10, 8))
# Plot MSE
plt.subplot(2, 1, 1)
plt.errorbar(n_samples_range, lw_mse.mean(1), yerr=lw_mse.std(1),
label='Ledoit-Wolf', color='purple', lw=2, alpha=0.8)
plt.errorbar(n_samples_range, oa_mse.mean(1), yerr=oa_mse.std(1),
label='OAS', color='red', lw=2, alpha=0.8)
plt.ylabel("平方误差")
plt.legend(loc="upper right")
plt.title("协方差估计器的比较")
plt.xlim(5, 31)
plt.grid(True)
# Plot shrinkage coefficient
plt.subplot(2, 1, 2)
plt.errorbar(n_samples_range, lw_shrinkage.mean(1), yerr=lw_shrinkage.std(1),
label='Ledoit-Wolf', color='purple', lw=2, alpha=0.8)
plt.errorbar(n_samples_range, oa_shrinkage.mean(1), yerr=oa_shrinkage.std(1),
label='OAS', color='red', lw=2, alpha=0.8)
plt.xlabel("n_样品")
plt.ylabel("收缩")
plt.legend(loc="lower right")
plt.ylim(plt.ylim()[0], 1. + (plt.ylim()[1] - plt.ylim()[0]) / 10.)
plt.xlim(5, 31)
plt.grid(True)
plt.tight_layout()
plt.savefig("../4.png", dpi=500)
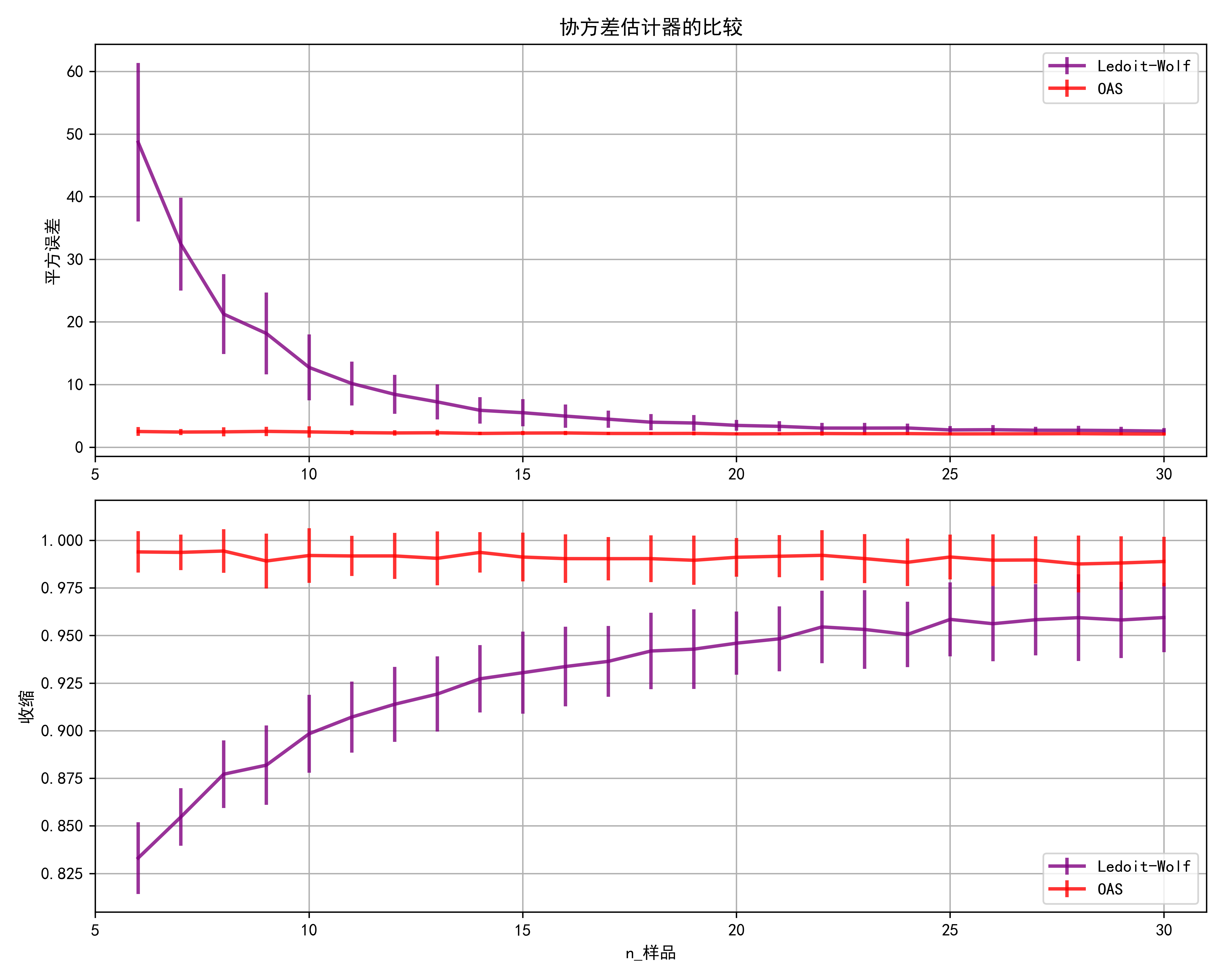
plt.show()示例运行结果如下图所示:
第一个子图显示了两个估计器的MSE随样本数量的变化情况。
第二个子图显示了两个估计器的收缩系数随样本数量的变化情况。
误差条表示每个样本大小的MSE和收缩系数在重复试验中的标准差。
MSE比较:随着样本数量的增加,两种估计器的MSE都会减小,这是预期的。Ledoit-Wolf的MSE通常比OAS更低,特别是对于较小的样本大小。
收缩比较:随着样本数量的增加,收缩程度减小。Ledoit-Wolf通常比OAS应用更多的收缩,这可以通过Ledoit-Wolf在所有样本大小上的较高收缩系数来观察到。
02-稀疏逆协方差估计
GraphicalLasso是一种常用的稀疏逆协方差矩阵估计器,它可以从少量样本中学习协方差矩阵的逆矩阵,即精度矩阵。让我们详细解释稀疏逆协方差估计的概念和GraphicalLasso的工作原理:
稀疏逆协方差矩阵:
逆协方差矩阵表示了变量之间的条件独立性关系。在实际数据中,往往存在很多变量之间的关联关系,但也有很多变量是条件独立的。
稀疏逆协方差矩阵通过设置许多相关系数为零,从而实现对变量间关系的稀疏表示,只保留了少量非零元素,反映了真实数据中的条件独立性结构。
GraphicalLasso工作原理:
GraphicalLasso通过最大似然估计来估计数据的协方差矩阵的逆矩阵(精度矩阵),同时对逆矩阵进行稀疏化。
在优化过程中,GraphicalLasso引入了L1正则化项(也称为Lasso惩罚项),以鼓励逆矩阵中的许多系数趋向于零,从而实现稀疏性。
这种正则化可以通过调节一个超参数来控制,超参数的选择通常通过交叉验证等技术来确定。
稀疏逆协方差估计的应用:
GraphicalLasso在实际中被广泛应用于各种领域,如生物信息学、金融领域和信号处理等。
在生物信息学中,GraphicalLasso常用于分析基因表达数据,帮助发现基因之间的调控关系。
在金融领域,GraphicalLasso可以用于建模不同金融资产之间的相关性,从而构建投资组合。在信号处理中,GraphicalLasso可以用于估计多变量时间序列数据之间的动态关系。
总的来说,GraphicalLasso通过学习数据的条件独立性结构,实现了对高维数据中的关联关系的稀疏表示,为数据分析和建模提供了有力工具。
下面给出具体代码分析应用过程,
这段代码首先生成了模拟数据,包括了60个样本和20个特征。数据是通过生成一个稀疏的正定对称矩阵作为精确的协方差矩阵,然后从这个协方差矩阵生成多元正态分布的样本。接着,它使用了两种方法来估计协方差矩阵和精度矩阵:GraphicalLassoCV(使用交叉验证选择最佳的alpha值)和Ledoit-Wolf方法。
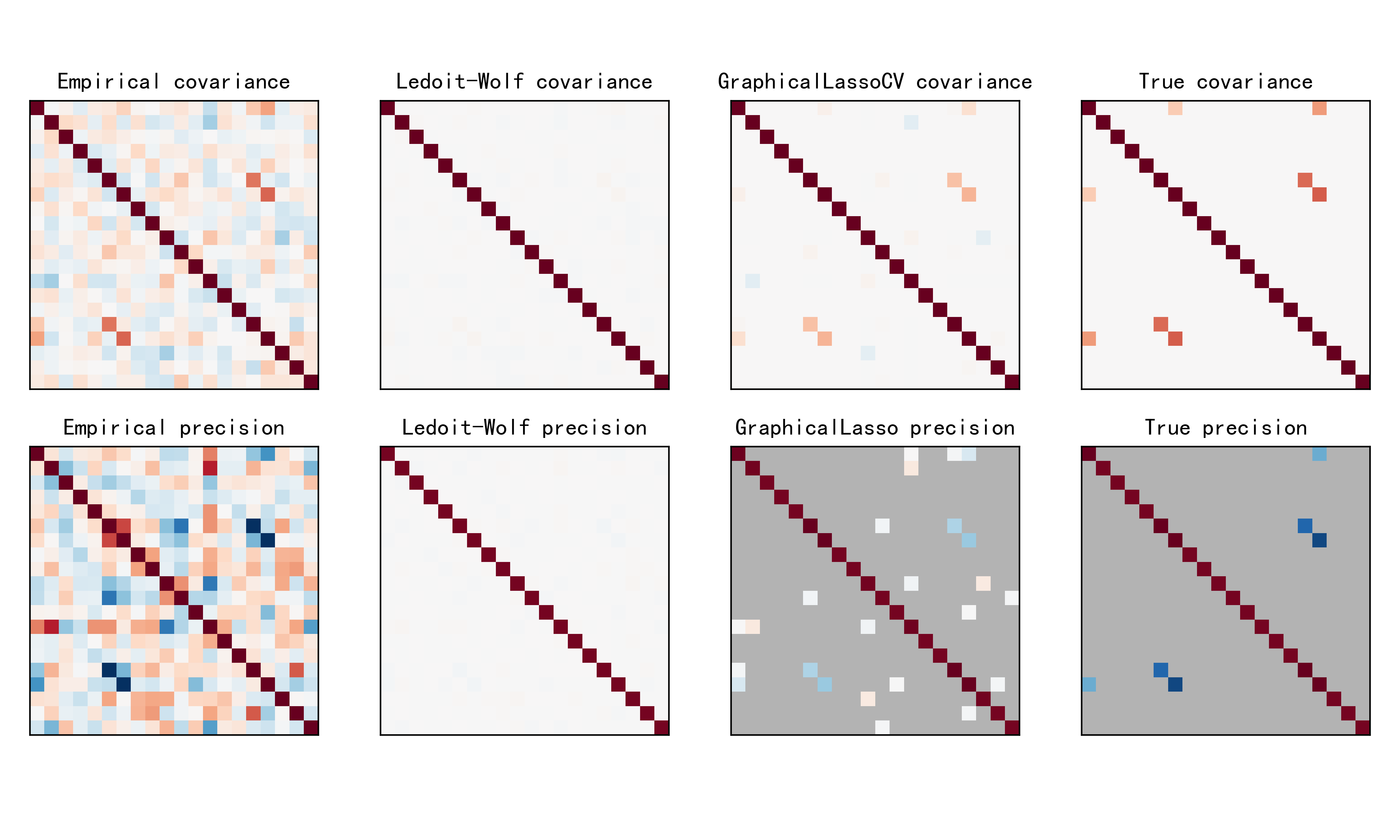
在估计完协方差矩阵和精度矩阵后,代码绘制了几个图形:
Covariance Plots(协方差矩阵图):分别展示了经验协方差矩阵、Ledoit-Wolf方法估计的协方差矩阵、GraphicalLassoCV方法估计的协方差矩阵和真实的协方差矩阵。每个子图的标题显示了对应的方法。
Precision Plots(精度矩阵图):分别展示了经验精度矩阵、Ledoit-Wolf方法估计的精度矩阵、GraphicalLassoCV方法估计的精度矩阵和真实的精度矩阵。每个子图的标题显示了对应的方法。
Model Selection Metric Plot(模型选择指标图):绘制了交叉验证得分随着alpha参数的变化情况,并在图中标出了最佳的alpha值。
下面给出具体代码分析稀疏逆协方差矩阵估计的应用过程,代码解释如下:
数据生成:首先使用make_sparse_spd_matrix函数生成了一个稀疏对称正定矩阵来表示精确的协方差矩阵。然后通过取其逆矩阵得到精确的精度矩阵。最后使用这个精度矩阵来生成符合多元正态分布的数据样本。
协方差估计:使用不同的方法估计数据的协方差矩阵。这里使用了三种方法:经验协方差估计 (emp_cov):简单地将数据矩阵的转置与其自身相乘,并除以样本数量得到。Ledoit-Wolf估计 (lw_cov_):利用Ledoit和Wolf提出的估计方法,通过给出的数据自适应地估计协方差矩阵。图形套索交叉验证 (cov_):使用图形套索法进行交叉验证来估计协方差矩阵。
精度估计:根据估计的协方差矩阵计算对应的精度矩阵(协方差矩阵的逆矩阵)。同样使用了三种方法,对应于上述的协方差估计方法。
这段代码的目的是对比不同估计方法得到的协方差矩阵和精度矩阵,以及真实的矩阵之间的差异。绘制的图像将有助于了解这些估计方法的表现。
import numpy as np
from scipy import linalg
from sklearn.datasets import make_sparse_spd_matrix
from sklearn.covariance import GraphicalLassoCV, ledoit_wolf
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
# #############################################################################
# Generate the data
n_samples = 60
n_features = 20
prng = np.random.RandomState(1)
prec = make_sparse_spd_matrix(n_features, alpha=.98,
smallest_coef=.4,
largest_coef=.7,
random_state=prng)
cov = linalg.inv(prec)
d = np.sqrt(np.diag(cov))
cov /= d
cov /= d[:, np.newaxis]
prec *= d
prec *= d[:, np.newaxis]
X = prng.multivariate_normal(np.zeros(n_features), cov, size=n_samples)
X -= X.mean(axis=0)
X /= X.std(axis=0)
# #############################################################################
# Estimate the covariance
emp_cov = np.dot(X.T, X) / n_samples
model = GraphicalLassoCV()
model.fit(X)
cov_ = model.covariance_
prec_ = model.precision_
lw_cov_, _ = ledoit_wolf(X)
lw_prec_ = linalg.inv(lw_cov_)
# #############################################################################
# Plot the results
plt.figure(figsize=(10, 6))
plt.subplots_adjust(left=0.02, right=0.98)
# plot the covariances
covs = [('Empirical', emp_cov), ('Ledoit-Wolf', lw_cov_),
('GraphicalLassoCV', cov_), ('True', cov)]
vmax = cov_.max()
for i, (name, this_cov) in enumerate(covs):
plt.subplot(2, 4, i + 1)
plt.imshow(this_cov, interpolation='nearest', vmin=-vmax, vmax=vmax,
cmap=plt.cm.RdBu_r)
plt.xticks(())
plt.yticks(())
plt.title('%s covariance' % name)
# plot the precisions
precs = [('Empirical', linalg.inv(emp_cov)), ('Ledoit-Wolf', lw_prec_),
('GraphicalLasso', prec_), ('True', prec)]
vmax = .9 * prec_.max()
for i, (name, this_prec) in enumerate(precs):
ax = plt.subplot(2, 4, i + 5)
plt.imshow(np.ma.masked_equal(this_prec, 0),
interpolation='nearest', vmin=-vmax, vmax=vmax,
cmap=plt.cm.RdBu_r)
plt.xticks(())
plt.yticks(())
plt.title('%s precision' % name)
if hasattr(ax, 'set_facecolor'):
ax.set_facecolor('.7')
else:
ax.set_axis_bgcolor('.7')
# plot the model selection metric
plt.savefig("../4.png", dpi=500)
plt.show() 示例运行结果如下图所示:将估计的协方差矩阵和精度矩阵以及真实的协方差矩阵和精度矩阵进行可视化比较。首先绘制协方差矩阵:对于每种估计方法,以热图的形式展示协方差矩阵,颜色表示数值大小,从负值(蓝色)到正值(红色)。接着绘制精度矩阵:同样以热图的形式展示精度矩阵,不过在此处利用了 np.ma.masked_equal 函数将精度矩阵中的0值进行了遮盖,避免了显示不必要的信息。
03-收缩协方差估计:LedoitWolf VS OAS和极大似然
当我们估计多元正态分布的协方差矩阵时,有时候由于样本数量较少或者其他原因,直接使用经验协方差矩阵(简单地将数据矩阵的转置与其自身相乘,并除以样本数量得到)可能会导致不准确的估计。在这种情况下,我们可以使用一些收缩估计方法来提高对协方差矩阵的估计准确性。常见的收缩估计方法包括Ledoit-Wolf估计、OAS估计(Oracle Approximating Shrinkage)、以及极大似然估计。
Ledoit-Wolf估计:Ledoit和Wolf提出了一种基于迹范数损失函数的收缩估计方法。该方法通过最小化经验协方差矩阵与一个对角矩阵的迹范数损失函数来估计收缩协方差矩阵。这种方法通过引入一个收缩系数来平衡经验协方差矩阵和单位矩阵,从而提高了估计的稳定性和准确性。
OAS估计:Oracle Approximating Shrinkage(OAS)估计是一种近似于理想收缩的方法。它通过在最小化估计的协方差矩阵与真实协方差矩阵的差异的同时,加上一个收缩参数的惩罚项,来实现收缩。OAS方法是一种有偏估计,但在特定情况下可以比Ledoit-Wolf方法更准确。
极大似然估计:极大似然估计是另一种常见的协方差矩阵估计方法。它直接最大化观测数据的似然函数来估计参数。虽然极大似然估计不涉及收缩,但在样本量充足时可以提供准确的估计。
这些方法在不同的场景下可能表现不同,Ledoit-Wolf和OAS估计方法通常在样本数量较少时效果更好,因为它们引入了一定程度的收缩来提高估计的稳定性。而极大似然估计则更适用于样本量较大的情况下。
当处理协方差估计时,通常的方法是使用极大似然估计。例如sklearn.covariance.EmpiricalCovariance ,这是不偏不倚的。当给出许多观测结果时,它收敛到真实的(总体)协方差。然而,正则化也可能是有益的,以减少它的方差;这反过来又带来一些偏差。这个例子说明了在 Shrunk Covariance估计中使用的简单正则化。特别是如何设置正则化的数量,即如何选择偏差-方差权衡。
在这里,我们比较了三种方法:
根据潜在收缩参数的网格,通过三折交叉验证的可能性来设置参数。
Ledoit和Wolf提出的求渐近最优正则化参数(最小MSE准则)的封闭公式,得到了sklearn.covariance.LedoitWolf协方差估计。
关于 Ledoit-Wolf收缩的改进,sklearn.covariance.OAS ,由Chen等人提出。在假设数据是高斯的情况下,特别是对于小样本,它的收敛性要好得多。为了量化估计误差,我们对收缩参数的不同值绘制了不可见数据的可能性图。我们还通过LedoitWolf和OAS估计的交叉验证进行选择显示。
下面给出具体代码分析应用过程,这段代码首先生成了一些样本数据,然后比较了不同收缩方法在估计协方差矩阵时的表现,并绘制了相应的结果图。
生成样本数据:使用了 NumPy 生成了一些随机样本数据 base_X_train 和 base_X_test,然后通过一个随机的颜色矩阵 coloring_matrix 对这些数据进行了变换,得到了 X_train 和 X_test。
计算在测试数据上的似然性:使用了不同的收缩系数对 X_train 进行了拟合,并在 X_test 上计算了负对数似然。这个过程中,采用了 ShrunkCovariance 类,该类可以通过指定不同的收缩系数来估计协方差矩阵。然后对比了真实协方差矩阵和经验协方差矩阵的似然性。
比较不同参数设置方法:通过网格搜索 (GridSearchCV) 和 Ledoit-Wolf 方法 (LedoitWolf) 来寻找最佳的收缩系数。同时也使用了 OAS 方法 (OAS) 来估计最佳的收缩系数。这个过程中,每个方法都计算了在测试数据上的负对数似然。
import numpy as np
import matplotlib.pyplot as plt
from scipy import linalg
from sklearn.covariance import LedoitWolf, OAS, ShrunkCovariance, \
log_likelihood, empirical_covariance
from sklearn.model_selection import GridSearchCV
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
# #############################################################################
# Generate sample data
n_features, n_samples = 40, 20
np.random.seed(42)
base_X_train = np.random.normal(size=(n_samples, n_features))
base_X_test = np.random.normal(size=(n_samples, n_features))
# Color samples
coloring_matrix = np.random.normal(size=(n_features, n_features))
X_train = np.dot(base_X_train, coloring_matrix)
X_test = np.dot(base_X_test, coloring_matrix)
# #############################################################################
# Compute the likelihood on test data
# spanning a range of possible shrinkage coefficient values
shrinkages = np.logspace(-2, 0, 30)
negative_logliks = [-ShrunkCovariance(shrinkage=s).fit(X_train).score(X_test)
for s in shrinkages]
# under the ground-truth model, which we would not have access to in real
# settings
real_cov = np.dot(coloring_matrix.T, coloring_matrix)
emp_cov = empirical_covariance(X_train)
loglik_real = -log_likelihood(emp_cov, linalg.inv(real_cov))
# #############################################################################
# Compare different approaches to setting the parameter
# GridSearch for an optimal shrinkage coefficient
tuned_parameters = [{'shrinkage': shrinkages}]
cv = GridSearchCV(ShrunkCovariance(), tuned_parameters)
cv.fit(X_train)
# Ledoit-Wolf optimal shrinkage coefficient estimate
lw = LedoitWolf()
loglik_lw = lw.fit(X_train).score(X_test)
# OAS coefficient estimate
oa = OAS()
loglik_oa = oa.fit(X_train).score(X_test)
# #############################################################################
# Plot results
fig = plt.figure()
plt.title("正则化协方差:似然和收缩系数")
plt.xlabel('正则化参数:收缩系数')
plt.ylabel('错误:测试数据的负对数似然')
# range shrinkage curve
plt.loglog(shrinkages, negative_logliks, label="负对数似然")
plt.plot(plt.xlim(), 2 * [loglik_real], '--r',
label="实协方差似然")
# adjust view
lik_max = np.amax(negative_logliks)
lik_min = np.amin(negative_logliks)
ymin = lik_min - 6. * np.log((plt.ylim()[1] - plt.ylim()[0]))
ymax = lik_max + 10. * np.log(lik_max - lik_min)
xmin = shrinkages[0]
xmax = shrinkages[-1]
# LW likelihood
plt.vlines(lw.shrinkage_, ymin, -loglik_lw, color='magenta',
linewidth=3, label='Ledoit-Wolf 估计')
# OAS likelihood
plt.vlines(oa.shrinkage_, ymin, -loglik_oa, color='purple',
linewidth=3, label='OAS 估计')
# best CV estimator likelihood
plt.vlines(cv.best_estimator_.shrinkage, ymin,
-cv.best_estimator_.score(X_test), color='cyan',
linewidth=3, label='Cross-validation best 估计')
plt.ylim(ymin, ymax)
plt.xlim(xmin, xmax)
plt.legend()
plt.savefig("../4.png", dpi=500)
plt.show()示例运行结果如下图所示:
绘制了收缩系数与测试数据上负对数似然的关系图。在图中,x 轴表示收缩系数的取值范围,y 轴表示在测试数据上的负对数似然。图中有几条曲线:
蓝色的曲线表示不同收缩系数下的负对数似然。
红色虚线表示真实协方差矩阵在测试数据上的似然性。
品红色和紫色的垂直线表示了 Ledoit-Wolf 方法和 OAS 方法分别估计出的最佳收缩系数。
青色的垂直线表示了通过交叉验证得到的最佳收缩系数。

04-鲁棒协方差估计与Mahalanobis距离相关性
鲁棒协方差估计与 Mahalanobis 距离之间存在密切的关联,理解它们之间的关系有助于更好地理解数据的分布和异常值的检测。
鲁棒协方差估计:在现实世界的数据中,经常会遇到异常值或者不符合正态分布假设的情况。在这种情况下,传统的协方差估计方法可能会受到异常值的影响,导致估计不准确。鲁棒协方差估计旨在解决这个问题,它采用了一些统计上鲁棒的技术,例如中位数替代均值和 MAD(Median Absolute Deviation)替代方差,来估计数据的协方差矩阵。这样可以减少异常值对估计结果的影响,提高估计的稳健性和准确性。
Mahalanobis 距离:Mahalanobis 距离是一种用来衡量样本点与一个数据集中其他点之间的距离的指标。与欧氏距离不同,Mahalanobis 距离考虑了数据的协方差结构。具体而言,对于一个样本点 x,其与数据集中其他点的 Mahalanobis 距离计算公式为:
[ D_M(x) = \sqrt{(x - \mu)^T \Sigma^{-1} (x - \mu)} ]
其中,( \mu ) 是数据集的均值向量,( \Sigma ) 是数据集的协方差矩阵。Mahalanobis 距离考虑了样本点与数据集中其他点的距离,并根据数据的协方差结构对距离进行了归一化,使得在高维空间中更加合理地衡量样本之间的相似性。
鲁棒协方差估计和 Mahalanobis 距离之间的关联在于:当我们使用鲁棒协方差估计来估计数据的协方差矩阵时,得到的协方差矩阵通常更能反映数据的真实结构,包括异常值的影响。而当我们利用这个鲁棒估计得到的协方差矩阵来计算 Mahalanobis 距离时,得到的距离更能准确地衡量样本点之间的相似性或差异性,因为它考虑了数据的真实结构和异常值的影响。因此,鲁棒协方差估计和 Mahalanobis 距离通常会结合使用,特别是在异常值检测和离群点识别等任务中。
下面给出具体代码分析应用过程:这段代码主要是用于展示如何使用 Minimum Covariance Determinant (MCD) 鲁棒估计器来检测异常值。让我简要分析一下:
首先,通过导入必要的库,包括 NumPy、Matplotlib 和 scikit-learn 中的 EmpiricalCovariance 和 MinCovDet。
接着定义了一些参数,包括样本数量、异常值数量和特征数量,并生成了一些数据。这些数据包括正常数据和一些被异常值干扰的数据。
使用 MinCovDet() 函数来拟合数据,它会计算出一个鲁棒的协方差估计。
然后,使用 EmpiricalCovariance() 函数来计算样本的经验协方差,作为参照。
在图像的展示部分,首先创建了一个图形窗口,并设置了子图的布局。
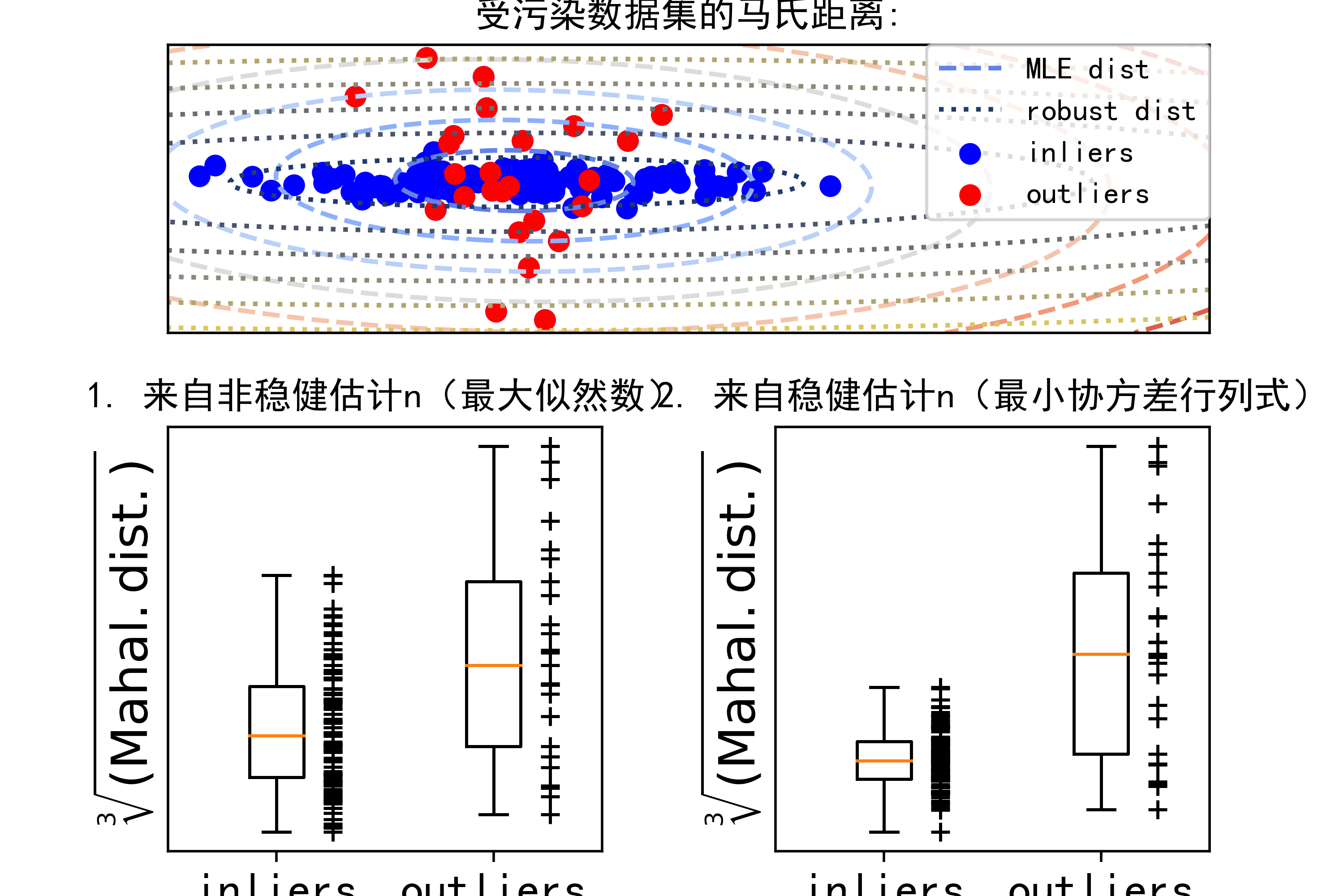
在第一个子图中,展示了数据点的分布,包括正常点和异常点。通过 Mahalanobis 距离,异常被标记成红色。
在第二个子图中,展示了 Mahalanobis 距离的轮廓,分别使用最大似然估计(MLE)和鲁棒估计的方式来计算。
最后两个子图分别展示了每个数据点的 Mahalanobis 距离的箱线图,分别使用了最大似然估计和鲁棒估计。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.covariance import EmpiricalCovariance, MinCovDet
n_samples = 125
n_outliers = 25
n_features = 2
# 生成数据
gen_cov = np.eye(n_features)
gen_cov[0, 0] = 2.
X = np.dot(np.random.randn(n_samples, n_features), gen_cov)
# 添加一些异常值
outliers_cov = np.eye(n_features)
outliers_cov[np.arange(1, n_features), np.arange(1, n_features)] = 7.
X[-n_outliers:] = np.dot(np.random.randn(n_outliers, n_features), outliers_cov)
# 使用 Minimum Covariance Determinant (MCD) 鲁棒估计器拟合数据
robust_cov = MinCovDet().fit(X)
# 用来自完整数据集的估计器与真实参数进行比较
emp_cov = EmpiricalCovariance().fit(X)
# 展示结果
fig = plt.figure()
plt.subplots_adjust(hspace=-.1, wspace=.4, top=.95, bottom=.05)
# 显示数据集
subfig1 = plt.subplot(3, 1, 1)
inlier_plot = subfig1.scatter(X[:, 0], X[:, 1],
color='blue', label='inliers')
outlier_plot = subfig1.scatter(X[:, 0][-n_outliers:], X[:, 1][-n_outliers:],
color='red', label='outliers')
subfig1.set_xlim(subfig1.get_xlim()[0], 11.)
subfig1.set_title("受污染数据集的马氏距离:")
# 显示距离函数的轮廓
xx, yy = np.meshgrid(np.linspace(plt.xlim()[0], plt.xlim()[1], 100),
np.linspace(plt.ylim()[0], plt.ylim()[1], 100))
zz = np.c_[xx.ravel(), yy.ravel()]
mahal_emp_cov = emp_cov.mahalanobis(zz)
mahal_emp_cov = mahal_emp_cov.reshape(xx.shape)
emp_cov_contour = subfig1.contour(xx, yy, np.sqrt(mahal_emp_cov),
cmap=plt.cm.coolwarm, # 修改颜色映射为coolwarm
linestyles='dashed')
mahal_robust_cov = robust_cov.mahalanobis(zz)
mahal_robust_cov = mahal_robust_cov.reshape(xx.shape)
robust_contour = subfig1.contour(xx, yy, np.sqrt(mahal_robust_cov),
cmap=plt.cm.cividis, # 修改颜色映射为cividis
linestyles='dotted')
subfig1.legend([emp_cov_contour.collections[1], robust_contour.collections[1],
inlier_plot, outlier_plot],
['MLE dist', 'robust dist', 'inliers', 'outliers'],
loc="upper right", borderaxespad=0)
plt.xticks(())
plt.yticks(())
# 绘制每个点的得分
emp_mahal = emp_cov.mahalanobis(X - np.mean(X, 0)) ** (0.33)
subfig2 = plt.subplot(2, 2, 3)
subfig2.boxplot([emp_mahal[:-n_outliers], emp_mahal[-n_outliers:]], widths=.25)
subfig2.plot(np.full(n_samples - n_outliers, 1.26),
emp_mahal[:-n_outliers], '+k', markeredgewidth=1)
subfig2.plot(np.full(n_outliers, 2.26),
emp_mahal[-n_outliers:], '+k', markeredgewidth=1)
subfig2.axes.set_xticklabels(('inliers', 'outliers'), size=15)
subfig2.set_ylabel(r"$\sqrt[3]{\rm{(Mahal. dist.)}}$", size=16)
subfig2.set_title("1. 来自非稳健估计n(最大似然数)")
plt.yticks(())
robust_mahal = robust_cov.mahalanobis(X - robust_cov.location_) ** (0.33)
subfig3 = plt.subplot(2, 2, 4)
subfig3.boxplot([robust_mahal[:-n_outliers], robust_mahal[-n_outliers:]],
widths=.25)
subfig3.plot(np.full(n_samples - n_outliers, 1.26),
robust_mahal[:-n_outliers], '+k', markeredgewidth=1)
subfig3.plot(np.full(n_outliers, 2.26),
robust_mahal[-n_outliers:], '+k', markeredgewidth=1)
subfig3.axes.set_xticklabels(('inliers', 'outliers'), size=15)
subfig3.set_ylabel(r"$\sqrt[3]{\rm{(Mahal. dist.)}}$", size=16)
subfig3.set_title("2. 来自稳健估计n(最小协方差行列式)")
plt.yticks(())
plt.savefig("../4.png", dpi=500)
plt.show()示例运行结果如下图所示:
第一个子图展示了数据的分布情况,黑色点代表正常数据,红色点代表异常数据。
第二个子图中的轮廓表示了 Mahalanobis 距离,红色表示异常值边界,蓝色表示正常值边界。可以看出,鲁棒估计的边界更加紧凑,更适应于异常值的存在。
最后两个子图中的箱线图展示了每个数据点的 Mahalanobis 距离。可以看出,使用鲁棒估计得到的距离更能有效地区分异常值和正常值。
05-稳健与经验协方差估计
稳健协方差估计和经验协方差估计是两种不同的方法,用于在统计学和机器学习中处理数据的协方差结构。下面是它们的详细分析:
经验协方差估计(Empirical Covariance Estimation)
原理:经验协方差是最简单的协方差估计方法之一,它直接使用数据的样本协方差矩阵来估计总体协方差矩阵。样本协方差矩阵是通过计算数据中每对变量之间的协方差得到的。
优点:实现简单,易于理解。对于数据分布未知或样本量较小的情况下,是一种常用的估计方法。
缺点:对于异常值敏感,即数据中存在异常值时,样本协方差矩阵的估计会受到影响,导致估计的不准确性。对于非高斯分布的数据,估计可能会失真。
鲁棒协方差估计(Robust Covariance Estimation)
原理:鲁棒协方差估计旨在减少异常值对估计结果的影响,提高估计的稳健性。它通常采用一些鲁棒的统计方法,例如 Minimum Covariance Determinant (MCD)。
优点:对异常值具有较强的鲁棒性,能够有效地抵御异常值的影响。对于非高斯分布的数据也有较好的适应性。
缺点:计算成本较高,特别是在高维数据集上。对于特定数据集可能不适用,需要根据数据的特点进行选择。
比较与应用场景
数据分布:经验协方差适用于数据服从多元正态分布或近似服从多元正态分布的情况。鲁棒协方差更适用于数据中存在异常值或非高斯分布的情况。
鲁棒性:在数据中存在异常值时,鲁棒协方差估计通常比经验协方差更可靠,因为它能够减少异常值对估计的影响。
计算复杂度:经验协方差估计的计算成本通常比较低,因为它只涉及简单的样本协方差计算。鲁棒协方差估计的计算成本较高,尤其是在处理大型高维数据集时。
适用性:对于一般情况下的数据分析,经验协方差通常是一个不错的选择。当数据中存在异常值或者对数据分布没有先验假设时,考虑使用鲁棒协方差估计。
在实际应用中,根据数据的特点和需求选择合适的协方差估计方法非常重要。
下面代码是对应用的分析:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn.covariance import EmpiricalCovariance, MinCovDet
# example settings
n_samples = 80
n_features = 5
repeat = 10
range_n_outliers = np.concatenate(
(np.linspace(0, n_samples / 8, 5),
np.linspace(n_samples / 8, n_samples / 2, 5)[1:-1])).astype(np.int)
# definition of arrays to store results
err_loc_mcd = np.zeros((range_n_outliers.size, repeat))
err_cov_mcd = np.zeros((range_n_outliers.size, repeat))
err_loc_emp_full = np.zeros((range_n_outliers.size, repeat))
err_cov_emp_full = np.zeros((range_n_outliers.size, repeat))
err_loc_emp_pure = np.zeros((range_n_outliers.size, repeat))
err_cov_emp_pure = np.zeros((range_n_outliers.size, repeat))
# computation
for i, n_outliers in enumerate(range_n_outliers):
for j in range(repeat):
rng = np.random.RandomState(i * j)
# generate data
X = rng.randn(n_samples, n_features)
# add some outliers
outliers_index = rng.permutation(n_samples)[:n_outliers]
outliers_offset = 10. * \
(np.random.randint(2, size=(n_outliers, n_features)) - 0.5)
X[outliers_index] += outliers_offset
inliers_mask = np.ones(n_samples).astype(bool)
inliers_mask[outliers_index] = False
# fit a Minimum Covariance Determinant (MCD) robust estimator to data
mcd = MinCovDet().fit(X)
# compare raw robust estimates with the true location and covariance
err_loc_mcd[i, j] = np.sum(mcd.location_ ** 2)
err_cov_mcd[i, j] = mcd.error_norm(np.eye(n_features))
# compare estimators learned from the full data set with true
# parameters
err_loc_emp_full[i, j] = np.sum(X.mean(0) ** 2)
err_cov_emp_full[i, j] = EmpiricalCovariance().fit(X).error_norm(
np.eye(n_features))
# compare with an empirical covariance learned from a pure data set
# (i.e. "perfect" mcd)
pure_X = X[inliers_mask]
pure_location = pure_X.mean(0)
pure_emp_cov = EmpiricalCovariance().fit(pure_X)
err_loc_emp_pure[i, j] = np.sum(pure_location ** 2)
err_cov_emp_pure[i, j] = pure_emp_cov.error_norm(np.eye(n_features))
# Display results
font_prop = matplotlib.font_manager.FontProperties(size=11)
plt.subplot(2, 1, 1)
lw = 2
plt.errorbar(range_n_outliers, err_loc_mcd.mean(1),
yerr=err_loc_mcd.std(1) / np.sqrt(repeat),
label="坚固的地理位置", lw=lw, color='m')
plt.errorbar(range_n_outliers, err_loc_emp_full.mean(1),
yerr=err_loc_emp_full.std(1) / np.sqrt(repeat),
label="完整数据集均值", lw=lw, color='red')
plt.errorbar(range_n_outliers, err_loc_emp_pure.mean(1),
yerr=err_loc_emp_pure.std(1) / np.sqrt(repeat),
label="纯数据集均值", lw=lw, color='blue')
plt.title("异常值对位置估计的影响")
plt.ylabel(r"Error ($||\mu - \hat{\mu}||_2^2$)")
plt.legend(loc="upper left", prop=font_prop)
plt.subplot(2, 1, 2)
x_size = range_n_outliers.size
plt.errorbar(range_n_outliers, err_cov_mcd.mean(1),
yerr=err_cov_mcd.std(1),
label="鲁棒协方差 (mcd)", color='m')
plt.errorbar(range_n_outliers[:(x_size // 5 + 1)],
err_cov_emp_full.mean(1)[:(x_size // 5 + 1)],
yerr=err_cov_emp_full.std(1)[:(x_size // 5 + 1)],
label="全数据集经验协方差", color='green')
plt.plot(range_n_outliers[(x_size // 5):(x_size // 2 - 1)],
err_cov_emp_full.mean(1)[(x_size // 5):(x_size // 2 - 1)],
color='green', ls='--')
plt.errorbar(range_n_outliers, err_cov_emp_pure.mean(1),
yerr=err_cov_emp_pure.std(1),
label="纯数据集经验协方差", color='black')
plt.title("异常值对协方差估计的影响")
plt.xlabel("污染量 (%)")
plt.ylabel("RMSE")
plt.legend(loc="upper center", prop=font_prop)
plt.savefig("../4.png", dpi=500)
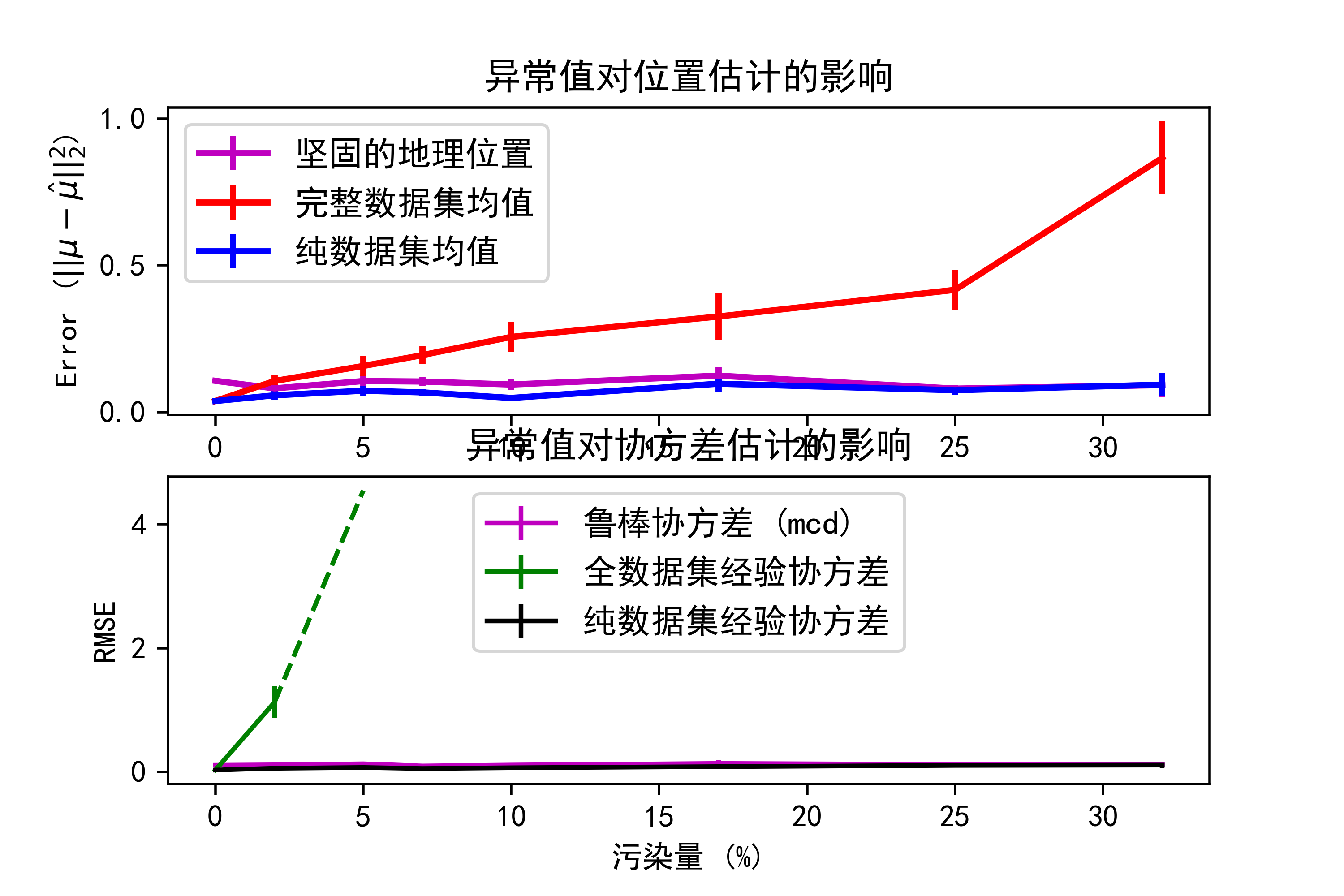
plt.show()示例运行结果如下图所示:在图像中,可以观察到以下几点:
随着异常值数量的增加,鲁棒估计的位置和协方差误差相对较稳定,而基于完整数据集的经验估计和基于纯净数据集的经验估计的误差会显著增加。
鲁棒估计对异常值的影响较小,而经验估计对异常值非常敏感,在异常值数量较多时,估计的误差增加明显。
在异常值数量较少时,基于完整数据集的经验协方差估计误差较小,但随着异常值数量的增加,误差会迅速增加,表现出对异常值的敏感性。
06-交叉分解法比较
交叉分解法(Cross Decomposition)是一种常用于多变量数据分析的技术,主要用于寻找多个变量之间的关联性和模式。这种方法通常被用于数据降维、特征提取、变量选择等任务中。在 Scikit-Learn 中,交叉分解法主要通过 Partial Least Squares (PLS) 和 Canonical Correlation Analysis (CCA) 来实现。下面是对 Scikit-Learn 中交叉分解法的详细分析:
Partial Least Squares (PLS)
原理:PLS 是一种线性回归方法,旨在通过对两个数据集之间的关系进行建模,从而找到最能解释两个数据集之间协方差的方向。它通过寻找投影方向,使得投影后的数据具有最大的协方差。
优点:能够处理多个响应变量的情况。在多重共线性较严重时,PLS 能够提供稳定的估计。
缺点:对异常值敏感,因为它是基于最小二乘法的。可能会过度拟合数据。
Canonical Correlation Analysis (CCA)
原理:CCA 旨在寻找两个数据集之间的最大相关性方向。它通过找到两个数据集之间的线性组合,使得这些组合之间的相关性最大化。
优点:能够捕获两个数据集之间的相关性。对异常值相对较稳健。
缺点:对于高维数据,可能会出现维度灾难问题。需要对数据进行标准化或缩放,以确保结果的可解释性。
比较与应用场景:
多响应变量:如果需要同时处理多个响应变量,PLS 是一个较好的选择。如果只关注数据集之间的相关性,并且每个数据集只有一个响应变量,可以考虑使用 CCA。
异常值敏感性:对于异常值敏感的数据集,可以考虑使用 CCA。如果数据集中存在异常值,而且对异常值相对不敏感,可以尝试使用 PLS。
数据分布:如果数据集满足多元正态分布假设,PLS 和 CCA 都可以有效地工作。对于非高斯分布的数据,需要谨慎选择合适的方法。
在实际应用中,根据数据集的特点和分析的目的选择合适的交叉分解方法非常重要。通常可以通过交叉验证等技术来评估不同方法的性能,并选择最适合的方法。
下面给出具体代码分析应用过程,这段代码主要是使用了Scikit-Learn中的PLSCanonical(偏最小二乘典型相关分析)模型对数据进行了拟合和转换,并绘制了相关的图像。下面是代码的作用和图像的分析:
数据生成:首先,使用numpy生成了一个大小为500的数据集,其中包含两个潜在变量。这两个潜在变量分别以正态分布生成。接着,通过加入随机噪声,生成了具有四个特征的X和Y数据集,这些特征由潜在变量和随机噪声混合而成。将生成的数据集分为训练集和测试集。
PLSCanonical模型拟合与转换:使用PLSCanonical模型对训练数据进行拟合,指定了2个主成分(n_components=2)。然后,将训练数据集和测试数据集分别通过拟合好的PLSCanonical模型进行转换,得到了转换后的数据集X_train_r、Y_train_r、X_test_r和Y_test_r。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cross_decomposition import PLSCanonical, PLSRegression, CCA
n = 500
# 2 latents vars:
l1 = np.random.normal(size=n)
l2 = np.random.normal(size=n)
latents = np.array([l1, l1, l2, l2]).T
X = latents + np.random.normal(size=4 * n).reshape((n, 4))
Y = latents + np.random.normal(size=4 * n).reshape((n, 4))
X_train = X[:n // 2]
Y_train = Y[:n // 2]
X_test = X[n // 2:]
Y_test = Y[n // 2:]
print("Corr(X)")
print(np.round(np.corrcoef(X.T), 2))
print("Corr(Y)")
print(np.round(np.corrcoef(Y.T), 2))
# ~~~~~~~~~~~~~~
plsca = PLSCanonical(n_components=2)
plsca.fit(X_train, Y_train)
X_train_r, Y_train_r = plsca.transform(X_train, Y_train)
X_test_r, Y_test_r = plsca.transform(X_test, Y_test)
plt.figure(figsize=(12, 8))
plt.subplot(221)
plt.scatter(X_train_r[:, 0], Y_train_r[:, 0], label="train",
marker="o", c="b", s=25)
plt.scatter(X_test_r[:, 0], Y_test_r[:, 0], label="test",
marker="o", c="r", s=25)
plt.xlabel("x scores")
plt.ylabel("y scores")
plt.title('Comp. 1: X vs Y (test corr = %.2f)' %
np.corrcoef(X_test_r[:, 0], Y_test_r[:, 0])[0, 1])
plt.xticks(())
plt.yticks(())
plt.legend(loc="best")
plt.subplot(224)
plt.scatter(X_train_r[:, 1], Y_train_r[:, 1], label="train",
marker="o", c="b", s=25)
plt.scatter(X_test_r[:, 1], Y_test_r[:, 1], label="test",
marker="o", c="r", s=25)
plt.xlabel("x scores")
plt.ylabel("y scores")
plt.title('Comp. 2: X vs Y (test corr = %.2f)' %
np.corrcoef(X_test_r[:, 1], Y_test_r[:, 1])[0, 1])
plt.xticks(())
plt.yticks(())
plt.legend(loc="best")
# 2) Off diagonal plot components 1 vs 2 for X and Y
plt.subplot(222)
plt.scatter(X_train_r[:, 0], X_train_r[:, 1], label="train",
marker="*", c="b", s=50)
plt.scatter(X_test_r[:, 0], X_test_r[:, 1], label="test",
marker="*", c="r", s=50)
plt.xlabel("X comp. 1")
plt.ylabel("X comp. 2")
plt.title('X comp. 1 vs X comp. 2 (test corr = %.2f)'
% np.corrcoef(X_test_r[:, 0], X_test_r[:, 1])[0, 1])
plt.legend(loc="best")
plt.xticks(())
plt.yticks(())
plt.subplot(223)
plt.scatter(Y_train_r[:, 0], Y_train_r[:, 1], label="train",
marker="*", c="b", s=50)
plt.scatter(Y_test_r[:, 0], Y_test_r[:, 1], label="test",
marker="*", c="r", s=50)
plt.xlabel("Y comp. 1")
plt.ylabel("Y comp. 2")
plt.title('Y comp. 1 vs Y comp. 2 , (test corr = %.2f)'
% np.corrcoef(Y_test_r[:, 0], Y_test_r[:, 1])[0, 1])
plt.legend(loc="best")
plt.xticks(())
plt.yticks(())
plt.savefig("../4.png", dpi=500)
plt.show()示例运行结果如下图所示:
图1和图4:分别展示了第一个主成分的X和Y的训练集和测试集的得分分布,以及它们的相关性。蓝色点表示训练集,红色点表示测试集。
图2和图3:分别展示了训练集和测试集在第一个和第二个主成分上的分布情况,用来展示主成分之间的相关性。

总结
综上所述:在实际应用中,可以根据数据集的特点和分析任务选择合适的协方差估计方法和交叉分解方法。例如,对于高维数据,可能需要使用收缩协方差来避免过拟合;对于多变量数据分析,可以考虑使用PLS或CCA来寻找变量之间的关联性和模式。通过交叉验证等技术,可以评估不同方法的性能,并选择最适合的方法。
参考文献
[1] “Shrinkage Algorithms for MMSE Covariance Estimation” Chen et al., IEEE Trans. on Sign. Proc., Volume 58, Issue 10, October 2010.
[2] Johanna Hardin, David M Rocke. The distribution of robust distances. Journal of Computational a2nd Graphical Statistics. December 1, 2005, 14(4): 928-946.
[3] Zoubir A., Koivunen V., Chakhchoukh Y. and Muma M. (2012). Robust estimation in signal processing: A tutorial-style treatment of fundamental concepts. IEEE Signal Processing Magazine 29(4), 61-80.
[4] P. J. Rousseeuw. Least median of squares regression. Journal of American Statistical Ass., 79:871, 1984