首先,感谢imbyter的教程,我也是从他的教程中一步一步的了解了shellcode的原理和各种知识。
原理
shellcode仅是一段可执行代码,不需要入口函数。理解shellcode加载原理之前需要理解PE文件在系统中的执行原理,即代码在内存中的执行方式。生成shellcode的方式有很多,但最终原理是一样的,均是使用二进制的汇编,将其加载到可执行程序中,最后系统调用此段汇编。
准备工作
由于shellcode可以加载到其他进程中,所以编写shellcode不能有任何的导入导出函数。当我们编写正常的程序时肯定会有一些导入函数(导出函数一般在dll中会有),所以这是我们需要避免的,以一个简单的例子来解释:
main.cpp
int main()
{
return 0;
}
导入表
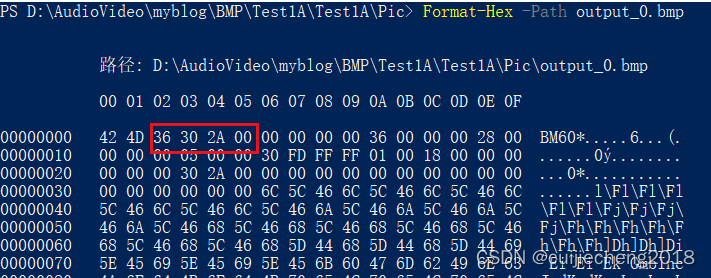
上边是一个简单的代码,下边看其生成的PE文件结构,主要是看其导入表:
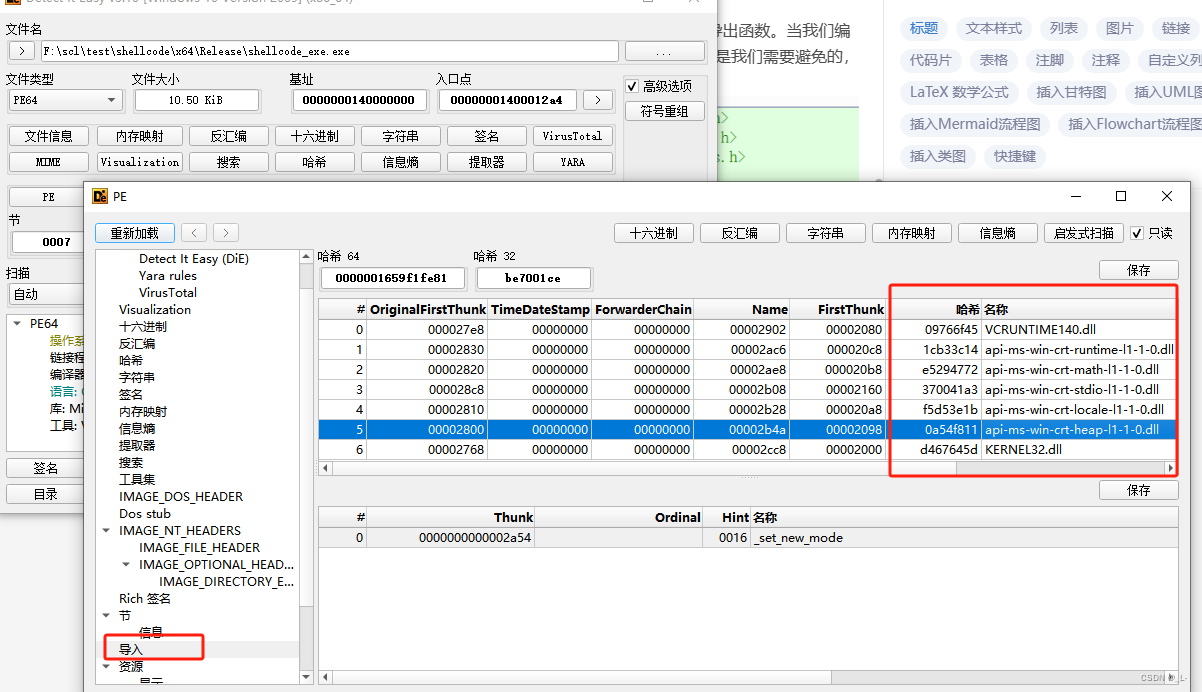
可以看到代码什么功能都没有,但是导入表中依然会有许多系统库被导入,这就涉及到windows的原理了,即使什么也不做也会包含许多系统库,那么如何解决呢?请继续往下看:
1、首先,修改程序的入口函数
将入口函数"main"修改为自定义的函数。有两种方式修改,第一种代码如下:
#pragma comment(linker,"/entry:ShellCodeEntry")
int ShellCodeEntry()
{
return 0;
}
在文件中添加"#pragma comment(linker,“/entry:ShellCodeEntry”)",即可修改入口函数。
第二种则是在项目属性中修改:
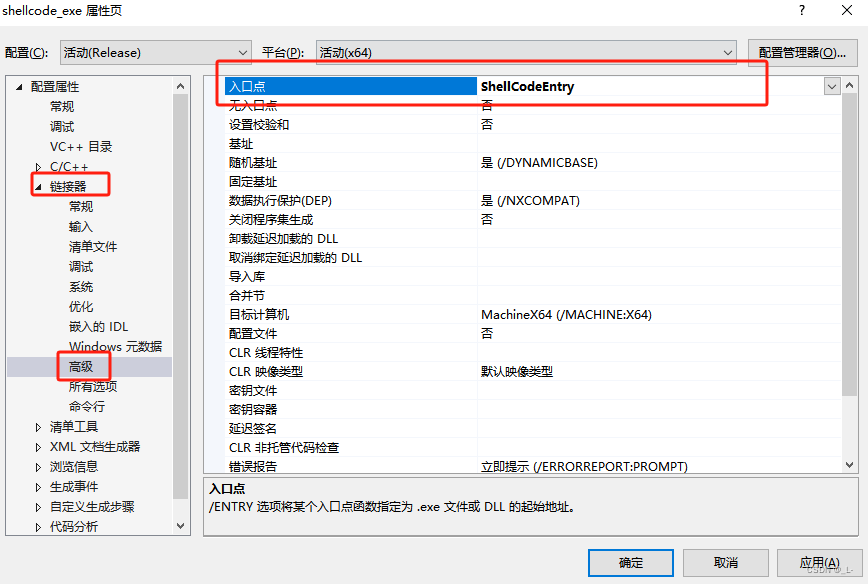
两种方式的效果是一样的,但是更建议使用第一种方式,不仅更直观,而且在可移植性方面会更好。
接下来我们再看看这样修改后的PE文件导入表情况:
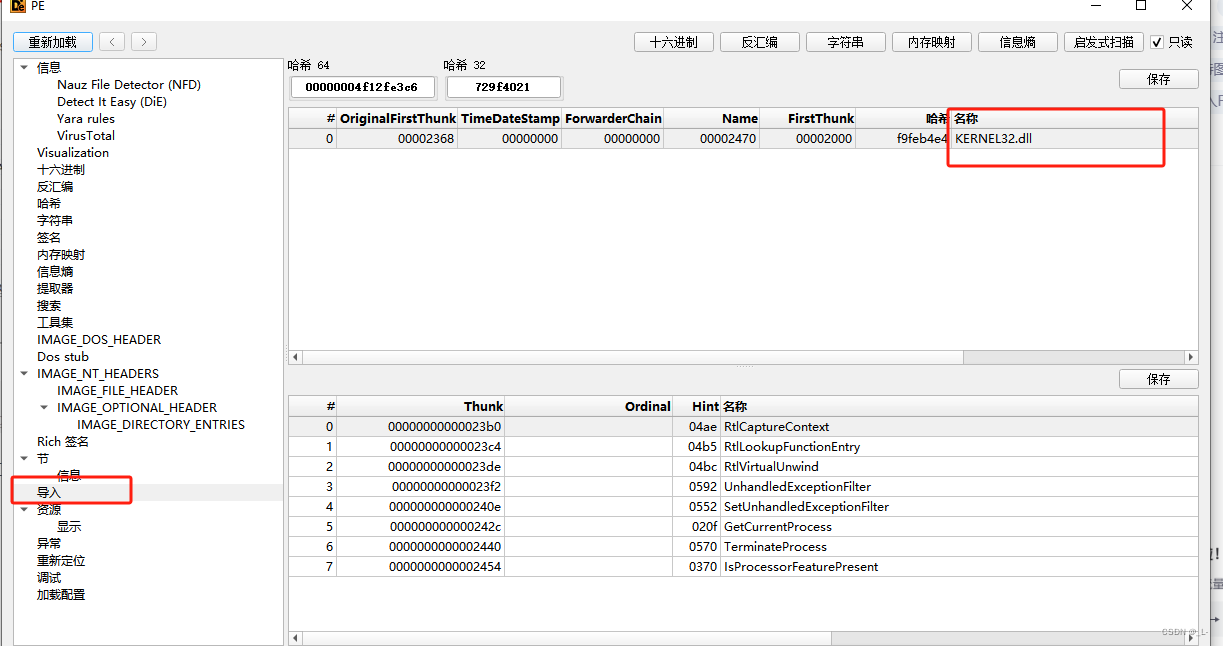
从上图中可以看到,导入表中的库明显少了,那么剩下的这个库怎么去掉呢,别着急,我们继续往下走。
2、将安全检查关掉
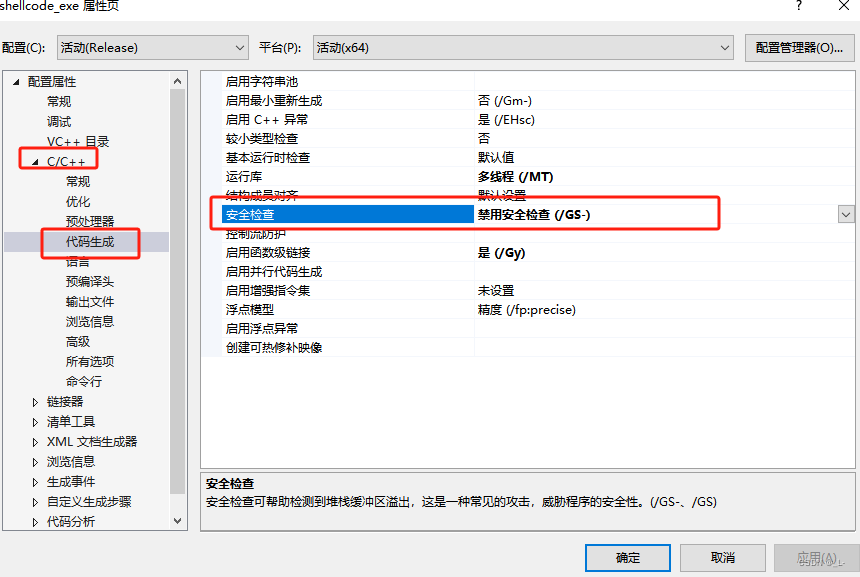
好了,继续让我们看一下PE文件的导入表:
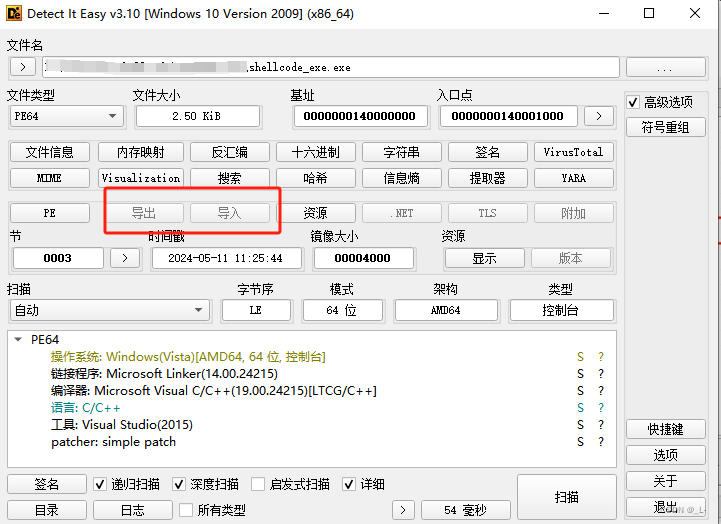
可以明显的发现生成的PE文件已经没有导入表了。
字符串优化
解决了导入表的问题,大家是不是就以为终于可以写shellcode代码了,no,no,no,天真了,其实生成的PE文件中还有一个问题,那就是在“.rdata”节中还会有一些无用的数据,看图:
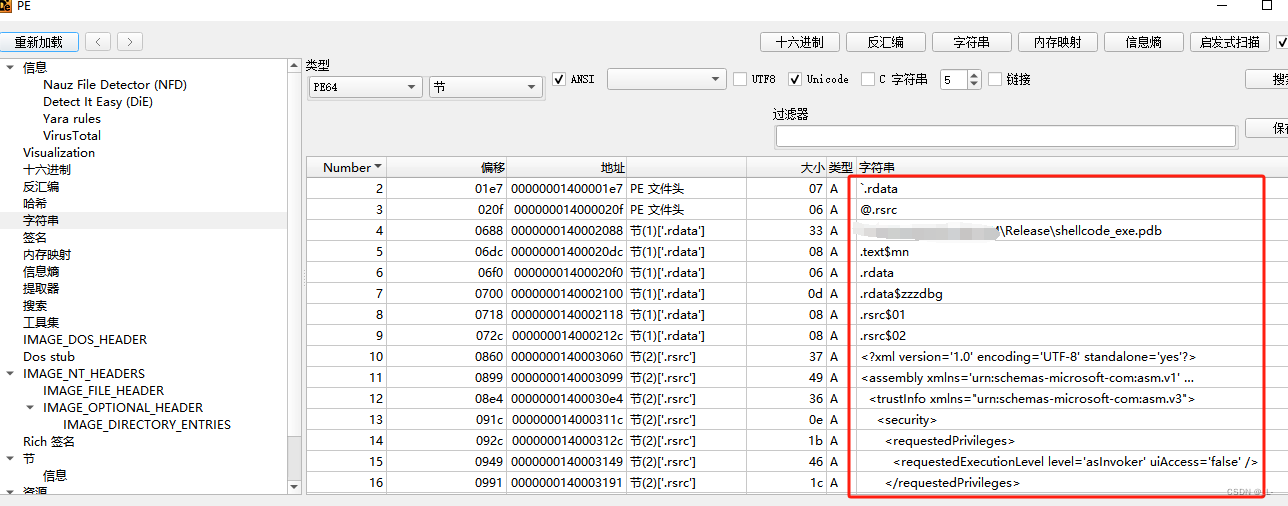
可以看到,这个数据节中包含一些数据。
这些数据会导致什么问题呢,那就是当当我们的shellcode代码调用这些数据地址时,执行shellcode的进程若不是我们shellcode的进程则会出现一些无法预料错误,它是找不到这些数据的地址的。
怎么优化呢?只需要将生成清单文件和生成调试信息就好了,如下:
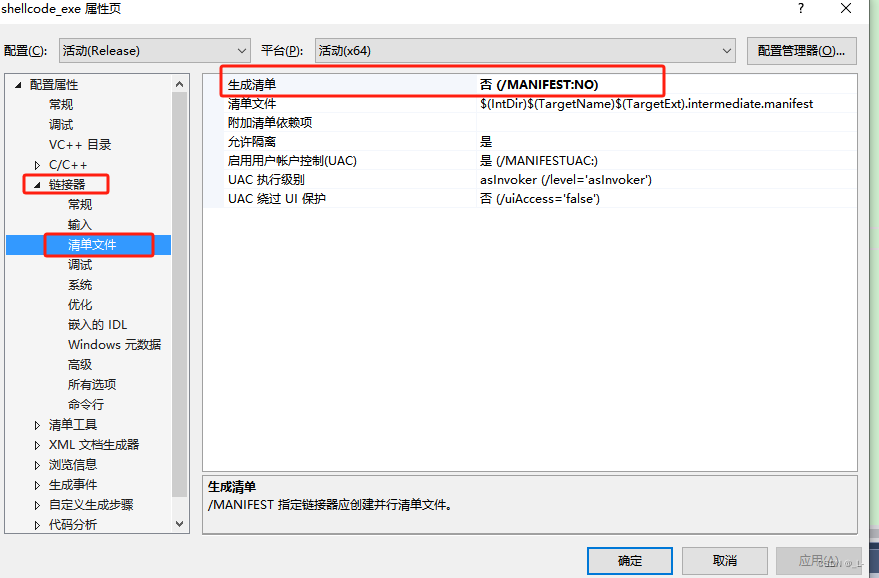
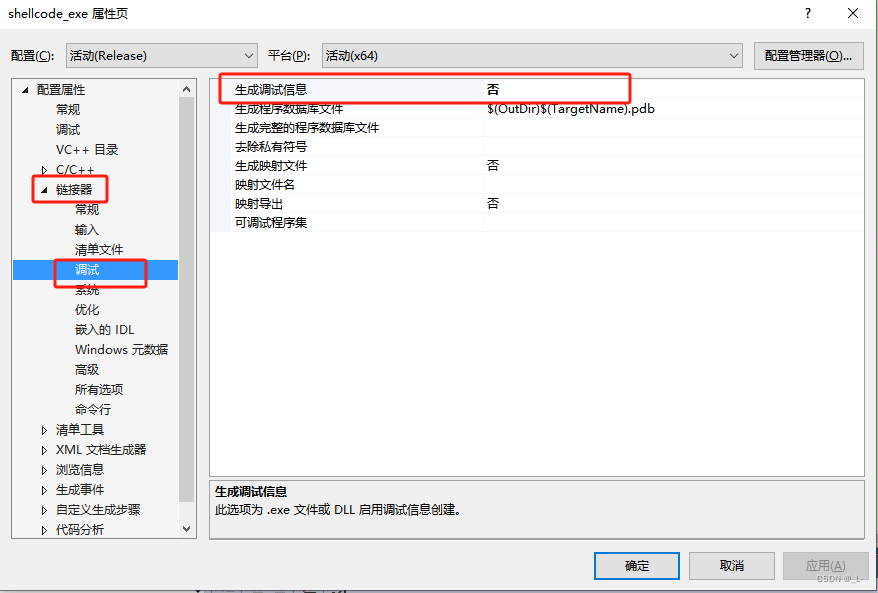
然后让我们再看一下设置之后的PE文件:
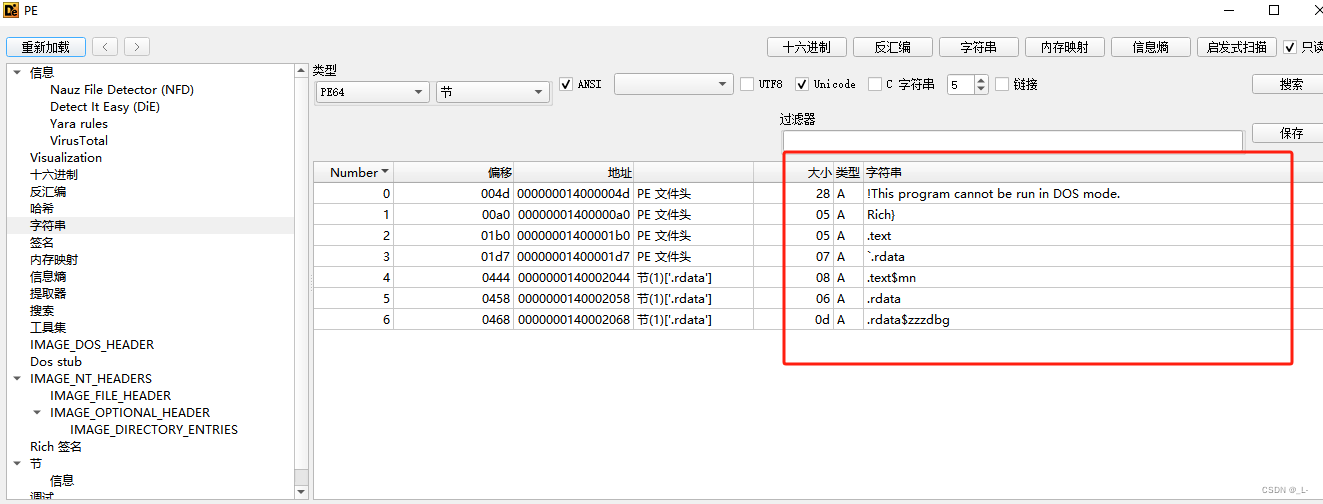
大功告成,现在已经没有那些杂乱的数据了,剩下的就可以不用管了,它并不影响我们的shellcode代码,接下来就到了我们的正题了(编写shellcode代码),哈哈哈,别着急,请听下回分解^ - ^