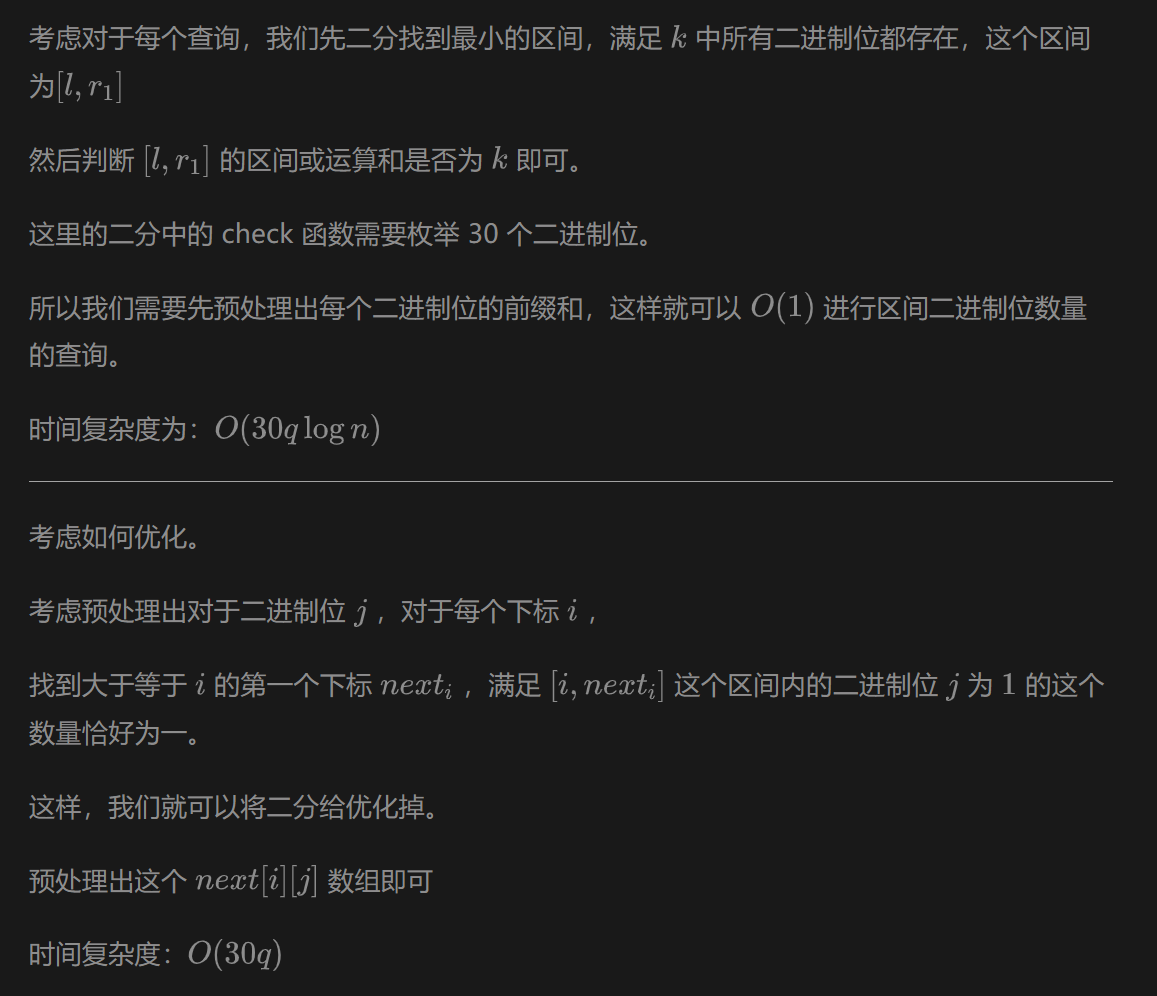
介绍
Flink DataSink是Apache Flink框架中的一个重要组件,它定义了数据流经过一系列处理后最终的输出位置。以下是关于Flink DataSink的详细介绍:
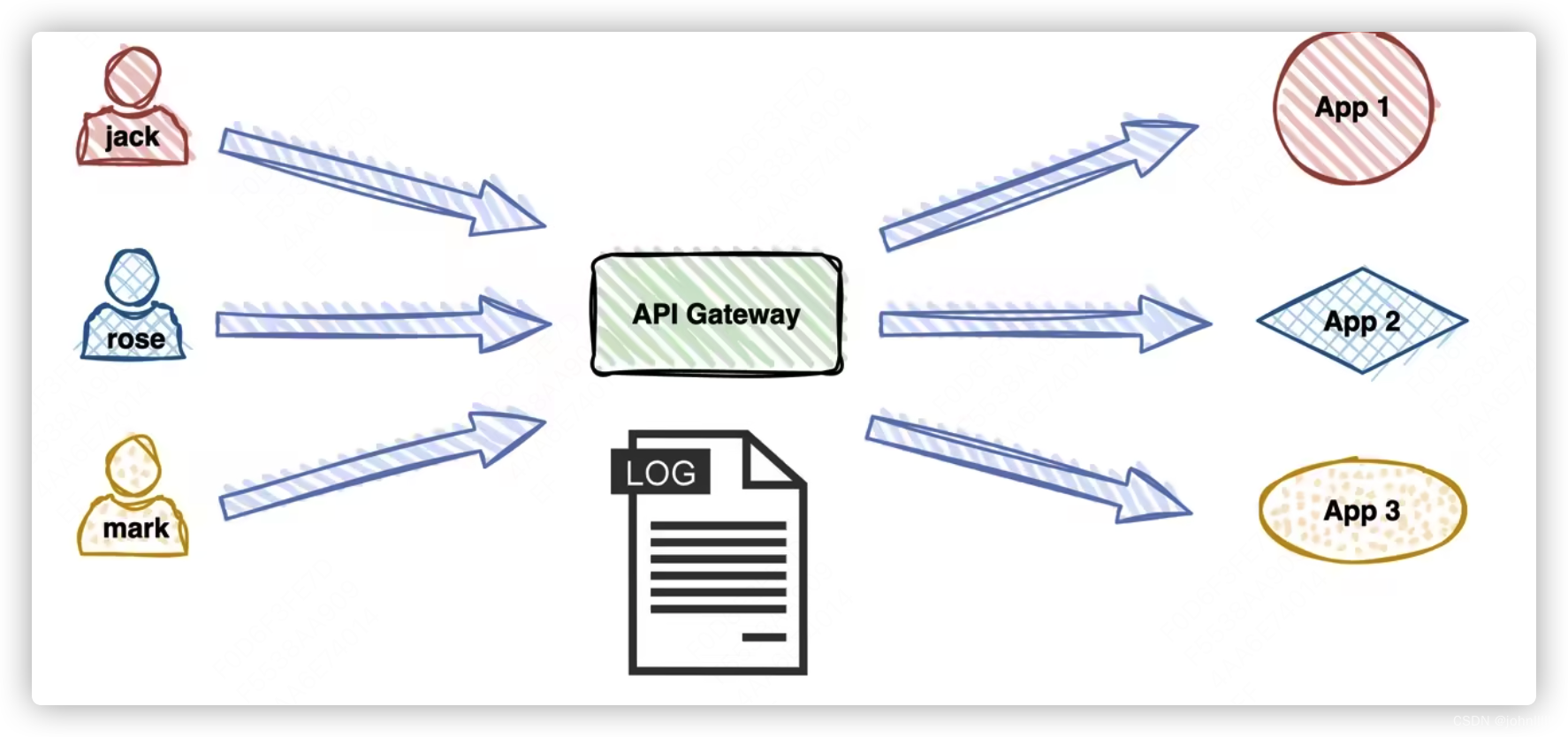
- 概念:DataSink主要负责对经过Flink处理后的流进行一系列操作,并将计算后的数据结果输出到指定的位置(如Kafka、ElasticSearch、Socket、RabbitMQ、JDBC、Cassandra、File等)。简单来说,它就是确定数据流流向的组件。
- 主要参与类:在Flink中,SinkFunction是DataSink的主要参与类。这个类包含了各种处理类对象,其中最重要的是invoke()方法。通过实现SinkFunction接口,可以自定义输出算子来与其他系统进行集成。
- 内置输出算子:Flink提供了多种内置的输出算子,如print()、printToErr()、writeAsText()等,用于将数据输出到控制台、文本文件等。此外,Flink还提供了一部分框架的Sink连接器,支持与许多外部系统集成的连接器,如Apache Kafka、Elasticsearch、JDBC、MongoDB等。这些连接器提供了专门的输出算子,可以直接与这些外部系统进行交互。
- 自定义Sink:除了使用Flink提供的内置输出算子和连接器外,用户还可以根据需求自定义Sink。通过实现SinkFunction接口,可以定义自己的输出逻辑,并将其用作addSink方法的参数。这样,用户就可以将数据输出到任何满足需求的位置。
- 整合Kafka Sink:Kafka是Flink中常用的数据源和输出目标之一。在整合Kafka Sink时,通常需要执行以下步骤:添加Kafka连接器依赖、创建Kafka生产者或消费者、配置Kafka参数、将数据写入Kafka等。
- 示例:以MySQL插入为例,用户可以创建一个Student实体类,并在Flink任务中使用该实体类来定义要插入的数据结构。然后,通过实现SinkFunction接口并覆盖其invoke()方法,将数据写入MySQL数据库。在invoke()方法中,可以使用JDBC连接MySQL并执行插入操作。
总之,Flink DataSink是Flink框架中用于定义数据流最终输出位置的组件。它提供了多种内置输出算子和连接器以及自定义Sink的能力,使得用户可以方便地将数据输出到任何满足需求的位置。
Sink
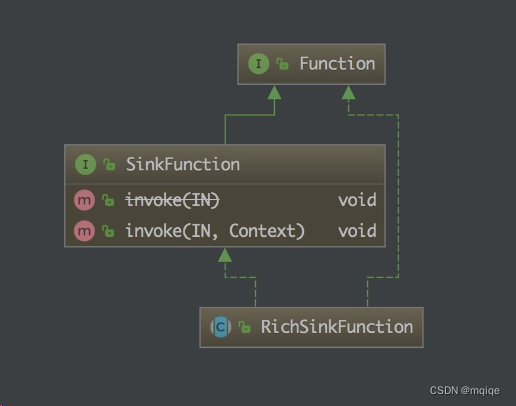
在 Apache Flink 中,SinkFunction 是一个接口,它定义了如何将数据流(DataStream)写入外部系统(如数据库、文件系统、消息队列等)。SinkFunction 的主要工作是接收 Flink 处理的元素,并将它们发送到指定的目标位置。
SinkFunction 接口定义了一个方法 invoke(IN value, Context context),其中 IN 是输入元素的类型,Context 提供了关于当前调用的一些上下文信息,如时间戳和检查点信息。
类
SinkFunction
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
public class PrintSinkFunction implements SinkFunction<String> {
@Override
public void invoke(String value, Context context) throws Exception {
System.out.println(value);
}
}
然后,你可以在你的 Flink 作业中使用这个 SinkFunction:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkJob {
public static void main(String[] args) throws Exception {
// 创建执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// ... 假设你有一个名为 "dataStream" 的 DataStream<String> ...
// 将 dataStream 的数据发送到 PrintSinkFunction
dataStream.addSink(new PrintSinkFunction());
// 执行作业
env.execute("Flink Job - Print to Console");
}
}
除了实现 SinkFunction 接口,Flink 还提供了许多预定义的 Sink 连接器,这些连接器封装了与特定系统(如 Kafka、Elasticsearch、JDBC 等)的交互逻辑。使用这些连接器通常比直接实现 SinkFunction 接口更为方便。
例如,如果你想要将数据写入 Kafka,你可以使用 Flink 提供的 FlinkKafkaProducer 类,而无需自己实现一个 Kafka SinkFunction。
最后,需要注意的是,SinkFunction 的 invoke 方法是在并行子任务中调用的,因此它必须能够安全地处理并发调用。如果 SinkFunction 需要与外部系统建立连接(如数据库连接),则应该考虑在 open 方法中建立连接,并在 close 方法中关闭连接,以确保连接的正确管理和释放。
RichSinkFunction
RichSinkFunction 是 Apache Flink 中的一个类,它扩展了 SinkFunction 接口,并增加了一些额外的功能,如生命周期管理和运行时上下文访问。RichSinkFunction 提供了 open(), close(), getRuntimeContext() 等方法,这些方法在 Flink 任务的并行子任务中非常有用。
生命周期方法
- open(Configuration parameters): 在并行子任务开始执行之前调用。它允许你在执行任务之前执行一些初始化操作,如打开数据库连接或加载资源文件。
- close(): 在并行子任务执行完毕之后调用。它允许你执行一些清理操作,如关闭数据库连接或释放资源。
运行时上下文
getRuntimeContext() 方法返回一个 RuntimeContext 对象,该对象提供了对 Flink 运行时环境的访问,包括并行子任务的索引、并行度、广播变量等。
使用示例
下面是一个简单的 RichSinkFunction 示例,它将接收到的字符串元素写入到标准输出(控制台),并在 open() 方法中输出一些初始化信息:
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
public class CustomRichSinkFunction extends RichSinkFunction<String> {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("CustomRichSinkFunction opened with subtask index: " + getRuntimeContext().getIndexOfThisSubtask());
}
@Override
public void invoke(String value, Context context) throws Exception {
System.out.println(value);
}
@Override
public void close() throws Exception {
super.close();
System.out.println("CustomRichSinkFunction closed.");
}
}
然后, Flink 作业中使用这个 CustomRichSinkFunction:
// ... 省略了创建 DataStream 的代码 ...
dataStream.addSink(new CustomRichSinkFunction());
// ... 省略了执行作业的代码 ...
这样,当运行 Flink 作业时,CustomRichSinkFunction 的 open(), invoke(), 和 close() 方法将在相应的时机被调用
预定义Sink

官网:https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/connectors/datastream/overview/