说明,此项目是我的期末大作业,包括了对数据集探索,预处理以及分类的各个详细过程与描述,代码简单,主要是一个分类项目的流程,并没有对模型进行深度研究,因此我写在这里。
目录
一、问题介绍
二、数据探索性分析及数据预处理
多数以白葡萄酒为例
1.首先根据type进行分类
2.查看数据分布情况
3.查看数据是否有异常值
4.查看数据正态分布情况
5.查看数据间的相关性
数据预处理
1.缺失值的处理
1)中位数填补缺失值/删除缺失值所在样本
2.异常值的处理/绘制异常值分布图
3.样本均衡
4.数据标准化
红葡萄酒情况
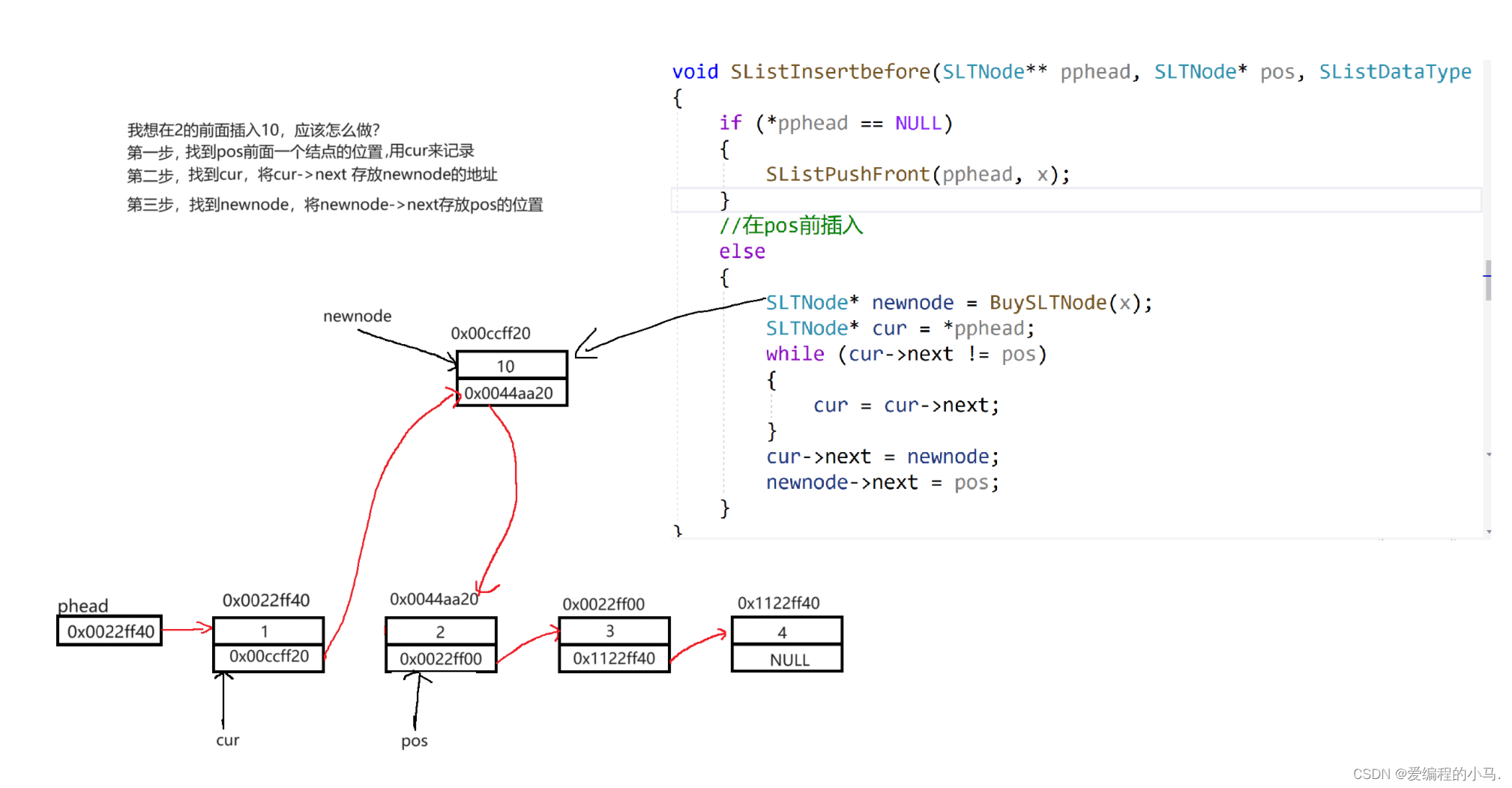
三、葡萄酒品质预测算法与实验结果分析
白葡萄酒:
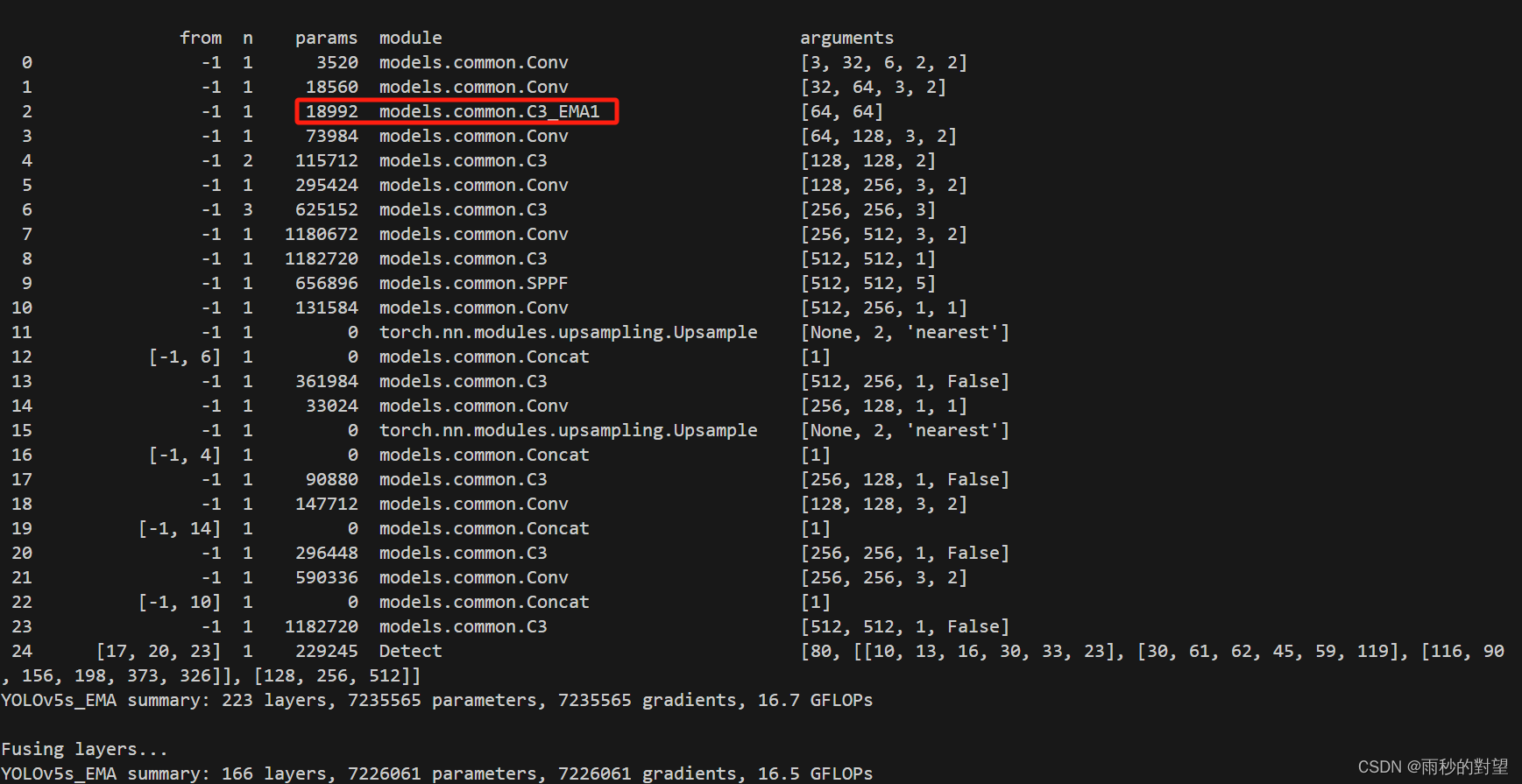
1.决策树
2.随机森林
3.XGBoost
4.多层感知机
5.支持向量机
随机森林调参
白葡萄酒
摘要
本研究旨在利用葡萄酒的物理化学特征,通过分别构建模型实现对白葡萄酒和红葡萄酒品质的准确预测。首先,对数据集进行多方面的探索分析,并根据分析结果进行缺失值,异常值,样本均衡和标准化等预处理工作。然后采用多种分类器,例如随机森林,xgboost,多层感知机等对葡萄酒数据集的特征进行学习,以捕捉葡萄酒品质与其化学成分之间的复杂关系。为了进一步提升模型性能,选择准确率最高的随机森林模型,对其进行了调参处理,包括绘制学习曲线以及使用网格搜索技术,进一步提高模型的预测准确性。
一、问题介绍
在该项目中为葡萄酒品质预测问题。主要为将数据集分为红葡萄酒数据集和白葡萄酒数据集,分别利用其物理化学特征构建分类模型,然后对其品质进行预测分类。
在该过程中,首先根据type区分葡萄酒,然后分别对葡萄酒进行数据探索,包括数据特征的分布情况,异常值情况,样本分布情况等。然后对其进行预处理,包括缺失值,异常值的处理,均衡处理,以及对样本进行标准化处理。在一系列数据准备的过程完成后,最后构建分类模型对其进行训练和预测。以及使用网格搜索对模型参数进行优化。
二、数据探索性分析及数据预处理
多数以白葡萄酒为例
1.首先根据type进行分类

数据探索分析
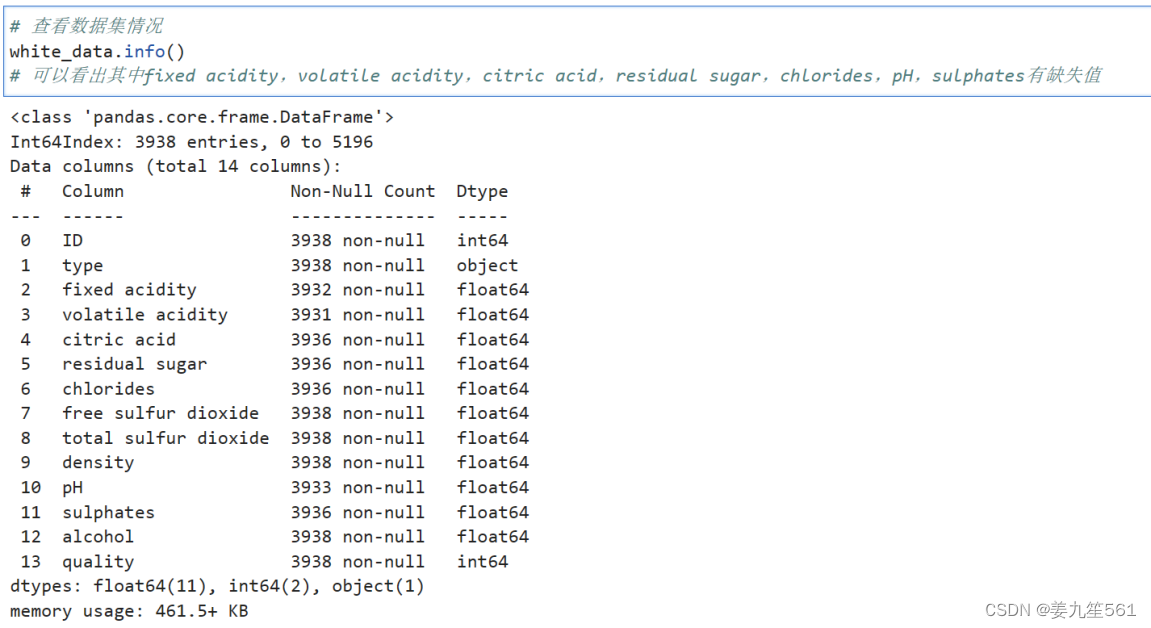
1.查看其数据情况
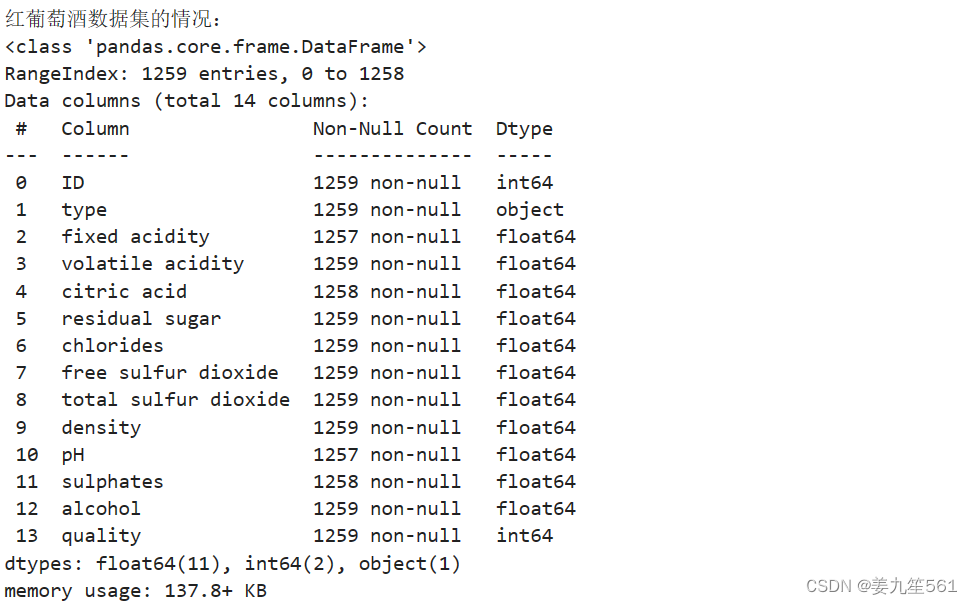
可以看出其中除了type是字符型数据外,其他都是数值型数据。一共共有14列数据,其中最后一列为标签数据。
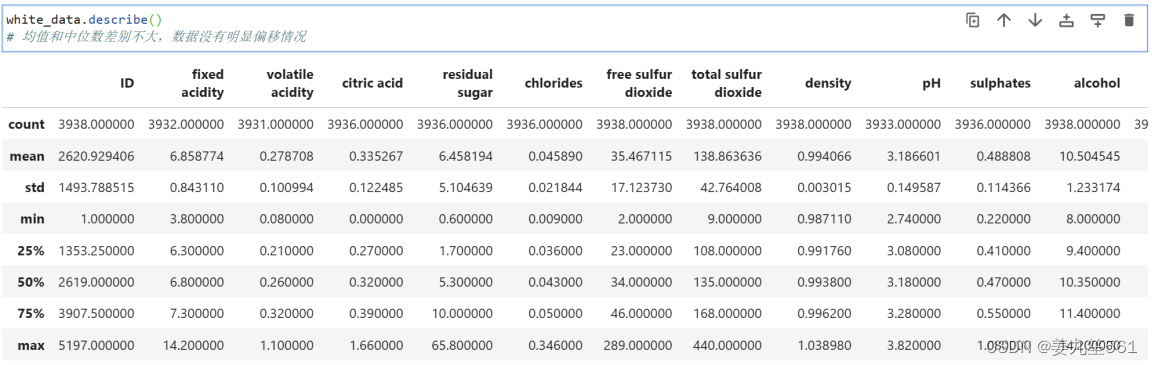
其中fixed acidity,volatile acidity,citric acid,residual sugar,chlorides,pH,sulphates有缺失值。中位数和均值相差不多,可以看出数据集还是分布比较均衡。
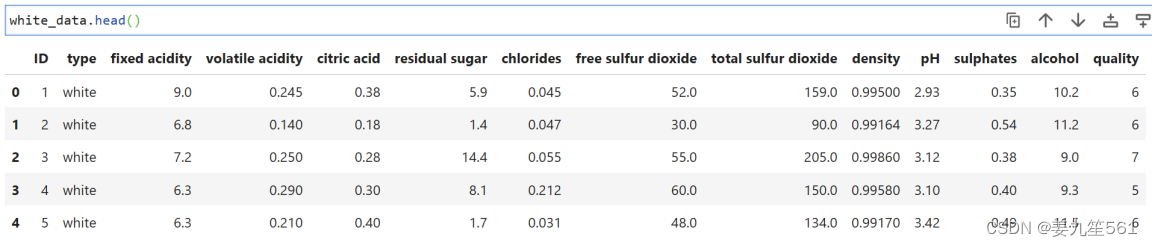
white_data.head():
white_data.info():
white_data.describe():
2.查看数据分布情况
通过描述除ID和type之外的列的直方图,可以看出各个特征和标签的分布情况,其中通过quality发现数据样本分布不均衡,需要考虑对其进行样本均衡处理


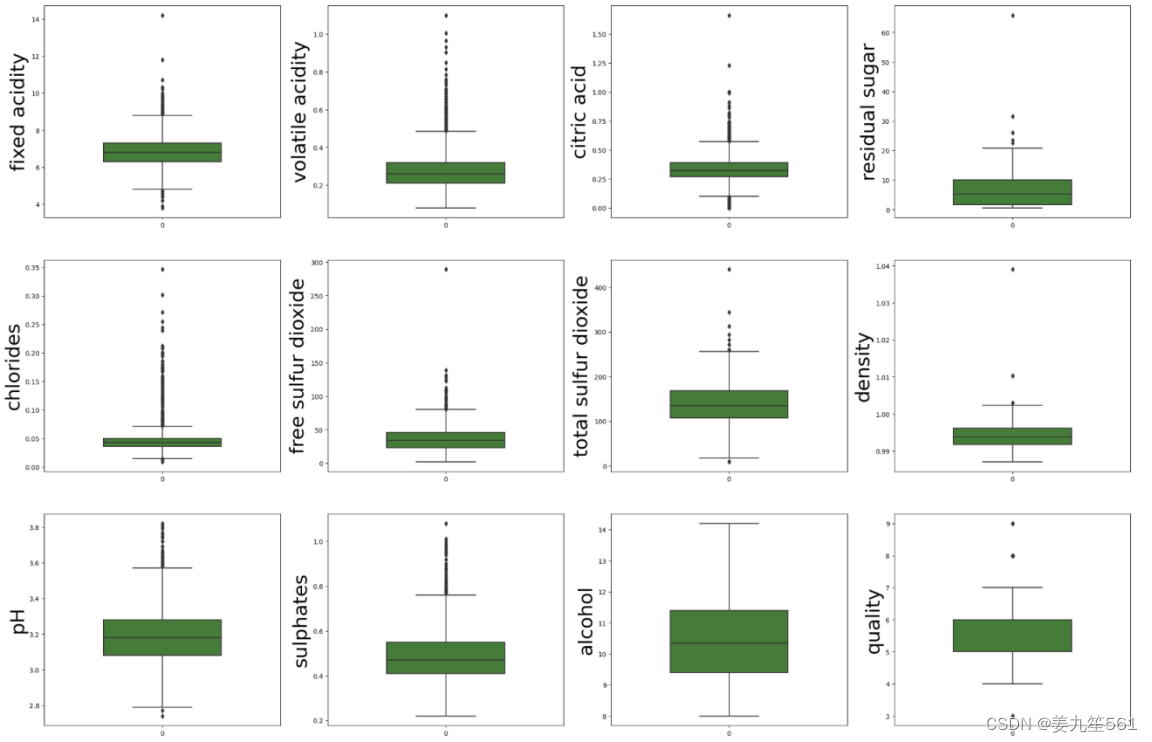
3.查看数据是否有异常值
通过对数据进行箱线图的绘制可以明显的看出其中的异常值的情况。从中可以发现许多特征的数据点都处在上限的上方,表明该特征具有相应的异常值,后续需要对其进行处理(删除或者填充)。如果异常值是较多的情况,考虑将数据分为两个不同的组,异常值归为一组,非异常值归为一组,两组分别建立模型,最终将两组的输出合并。

4.查看数据正态分布情况
通过绘制带有正态分布曲线的直方图和概率图(Q-Q图)。比较每个特征的分布情况,看它们是否接近正态分布。左侧的直方图显示了特征的分布,而右侧的概率图(Q-Q图)则用于比较样本数据的分位数和理论正态分布的分位数。如果点在直线上,说明数据近似于正态分布。
从中可以看出数据整体上满足正态分布。后续在对数据进行预处理的时候,可以选择对其进行数据标准化处理。


5.查看数据间的相关性
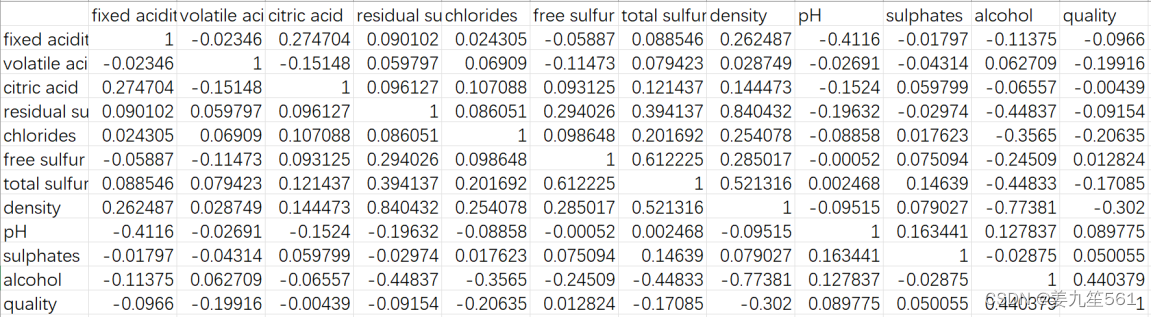
通过绘制特征之间的相关性热力图展示了特征之间的相关性系数,并通过颜色来表示相关性的强度。考虑到图有点大并且有些模糊,这里我通过获取train_corr的数据将其以表格的形式展示,其中标注了各个特征之间以及特征和quality之间的相关系数。(热力图就未给出了)
通过热力图可以发现特征之间的相关性不是很强,特征与标签之间的相关性也比较弱,从相关性来看不用进行特征的筛选。在后续建模的过程中发现尽量不选择线性模型。(事实也确实如此,我使用逻辑回归和支持向量机的线性模型进行多分类时,准确率只有百分之六十多)

数据预处理
ID只是个序号,以及type都是一样的,因此这里不需要它,将这两个特征进行删除。

1.缺失值的处理
1)中位数填补缺失值/删除缺失值所在样本
对数据集中citric acid,chlorides,sulphates,pH直接用中位数填补,删除了residual sugar缺失的两个样本。

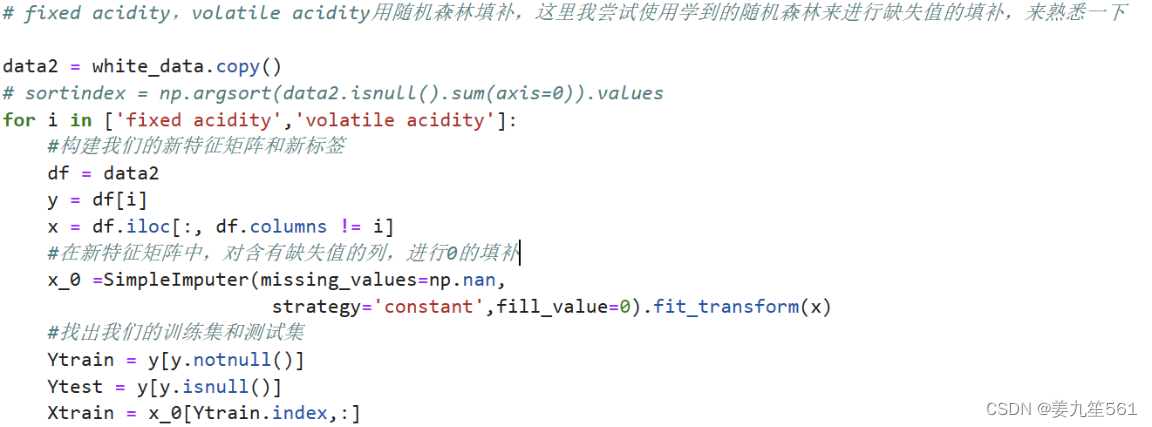
2)随机森林填补缺失值
之前学习随机森林的时候,学习到了利用随机森林填补缺失值,一直还未实践过。随机森林填补缺失值的原理是将有缺失值的数据作为标签,其他数据作为特征对其进行填补,特征里面的缺失值就用0填补,然后通过随机森林回归填补缺失值。从缺失值最少的先开始填补,每完成一次预测,就将预测值放入原数据集中,继续填补下一个。
在这里我利用随机森林对数据集中缺失值数量较大的两个特征fixed acidity,volatile acidity进行缺失值的填补。填补完成之后一共有3936个样本。

2.异常值的处理/绘制异常值分布图
在数据探索分析的时候通过箱线图发现许多特征都存在有异常值的情况,对于异常值的处理。
这里因为我发现异常值所在样本数量有700多个,我先考虑填充的方式对其进行处理,我考虑用中位数填补和随机森林填补的方式进行处理。
中位数填补:交叉验证的结果为0.9372。
随机森林填补:交叉验证的结果交叉验证的结果为:0.9356。
删除异常值:交叉验证的结果交叉验证的结果为0.9481。
上面所有进行交叉验证选用的预测模型为随机森林。可以发现用中位数填补课用随机森林进行填补的准确率比删除异常值低,因此这里我考虑选择将其所在样本删除。
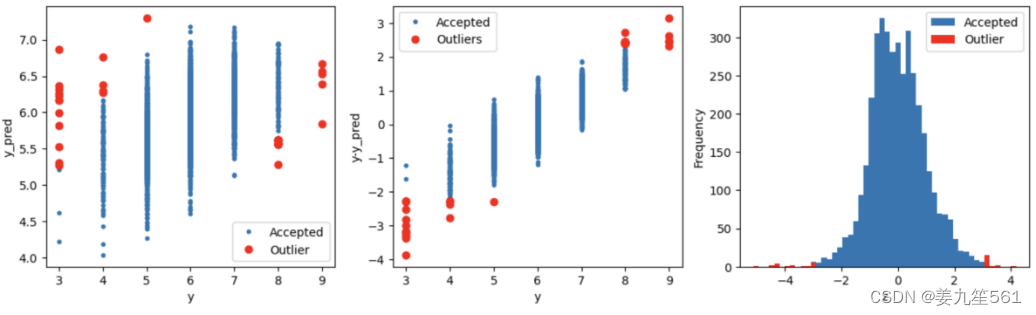
对异常值进行删除之后我对数据是比较担心的。我在缺失值处理后又通过岭回归的方式对异常值进行检查并绘制异常值的分布情况。通过下列图片可以看出异常值主要分布在标签值为3和9上面。对异常值进行删除后,可能会导致失去3和9为标签的样本,从而影响模型对这些标签的学习,在模型训练过程中,难以训练到这两个标签的真实的样本数据。
因此,我选择有两个方案,第一为暂时不删除异常值的样本,对其进行数据增强处理,以增加模型对这些标签的学习。第二则就为删除异常值的样本,对剩下的样本数进行过采样处理。最终还是选择删除异常值的操作。

3.样本均衡
通过直方图可以发现数据样本存在严重的不均衡的情况。因此我选择过采样和欠采样相结合的方式对其进行样本均衡处理。最先我打算使用Python库imblearn中的SMOTE进行采样,但他要求样本数要大于6,我的标签为3的样本只有4份。因此我进行手动的逐次采样。
该图为采样前的样本分布情况:

因此根据样本的数量,我选择对标签数为3,4,5,7,8,9的样本进行过采样。标签为6的进行欠采样。(但是因为样本数的严重不均衡,我担心过采样使得数据样本过度重合。)最后将样本再重新组合。
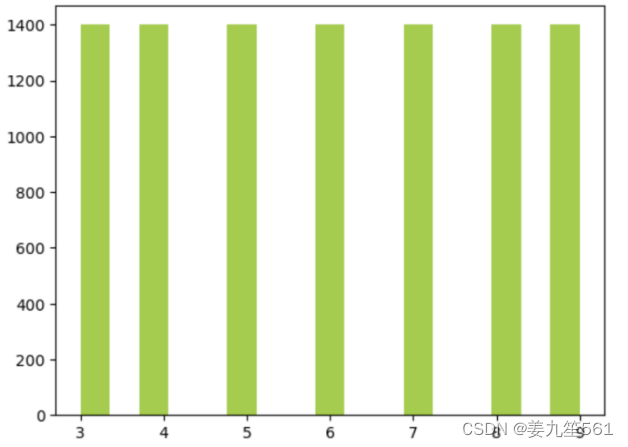
样本均衡后的样本分布情况如下图所示,每个类别都有1400个样本数量:
4.数据标准化
数据标准化有助于确保数据在训练模型时具有相似的尺度,可以提高模型性能。一种常见的标准化方法是 Z-score 标准化,也称为标准差标准化。对于每个特征,Z-score 标准化的公式如下:
这个过程将每个特征的值转换为其相对于该特征的均值和标准差的偏差。这样,所有特征都具有相似的尺度。
在进行数据探索分析的时候,发现数据整体上都偏向于正态分布,因此我在划分完训练集和验证集之后,进行了标准化处理。
划分训练集和验证集


红葡萄酒情况
在进行数据探索以及数据预处理阶段与白葡萄酒类似,代码也是类似的,因此在这里不再赘述,只简要概括以下几个方面。
数据探索包括以下几个方面:
①查看数据缺失值情况
②绘制直方图查看数据分布情况
③绘制箱线图查看数据异常值情况
④绘制数据分布曲线查看数据正态分布情况
⑤绘制热力图查看数据之间的相关性
通过数据探索得出以下结论:
①原始数据一共有1259个样本,13个特征,其中fixed acidity,citric acid,pH,sulphates有缺失值。通过绘制箱线图,大多特征都含有异常值。根据岭回归算法对异常值分布的绘制,发现其将标签为3和8的数据样本基本上全认作为异常值。
②特征大多数满足正态分布性,特征之间、特征与标签之间的相关程度不高。
数据预处理包括以下几个方面:
缺失值的处理(删除)
异常值的处理(考虑删除还是填补后,根据模型结果选择中位数填补)
样本均衡(为避免数据信息的损失和造成大量冗余信息。将标签为3,4,7,8的样本过采样至500,标签为5,6欠采样至500)
数据标准化
三、葡萄酒品质预测算法与实验结果分析
白葡萄酒:
在这个阶段,我采用了多种机器学习算法,然后对不同算法模型的准确率结果进行了比较,通过交叉验证的结果来评估不同模型之间的性能和优劣,最后选用性能较好的模型进行调参处理,以求增加模型的性能。
1.决策树
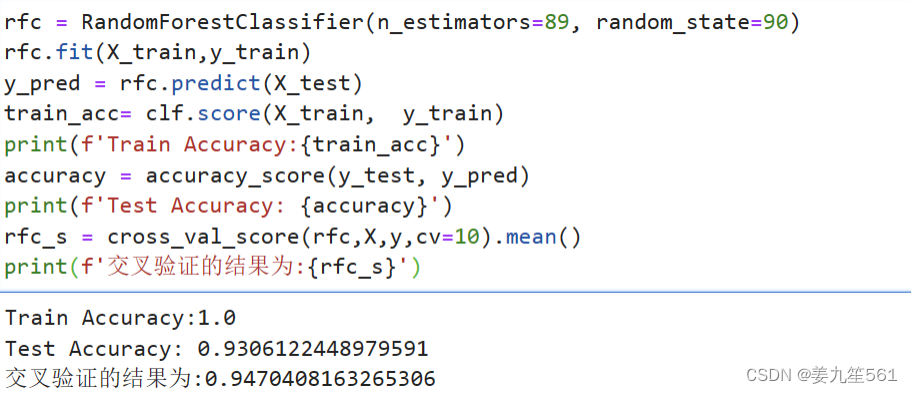
首先我使用决策树算法来对葡萄酒品质进行预测,决策树是一种常用来进行分类的机器学习算法。我使用决策树原始参数对数据集进行了学习,通过交叉验证的结果,其准确率表现为0.9268。


2.随机森林
随机森林模型在所有模型中表现最好,因此我后续对其进行了调参处理,以期望能够增加准确率。

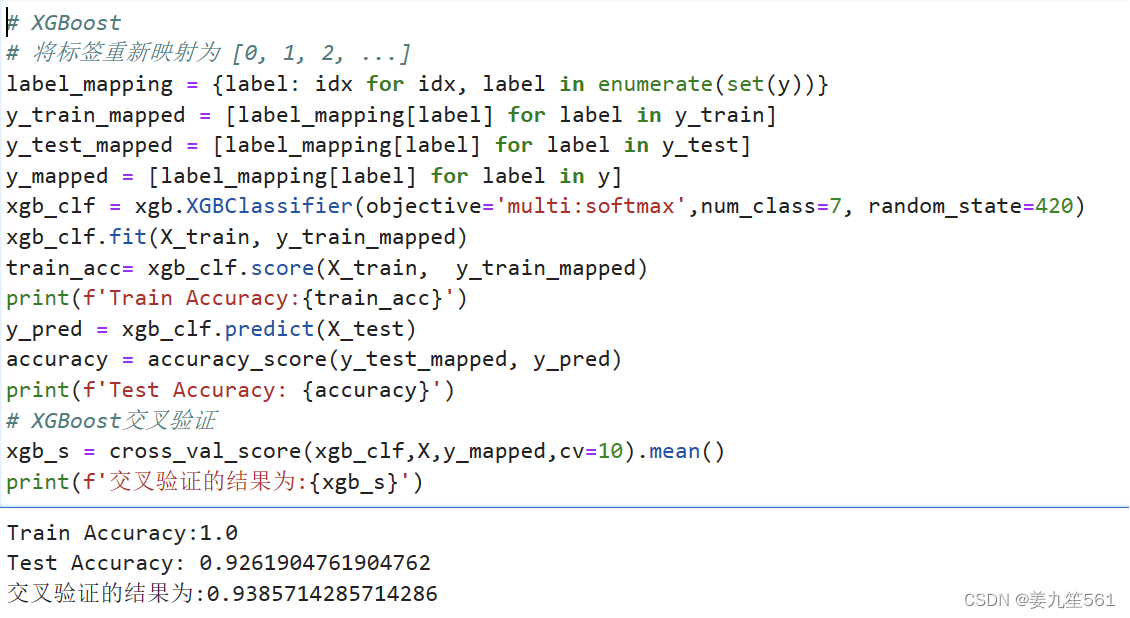
3.XGBoost
XGBoost是一种梯度提升树算法,是集成学习中强大且高效的模型。为了方便,我将数据集中的标签重新映射为从0开始的数,然后进行模型的训练和预测。通过模型可以看出,XGBoost对于训练集的学习到达了1,交叉验证的结果上表现为0.938。
4.多层感知机
多层感知机是一种由人工构建的神经网络模型。

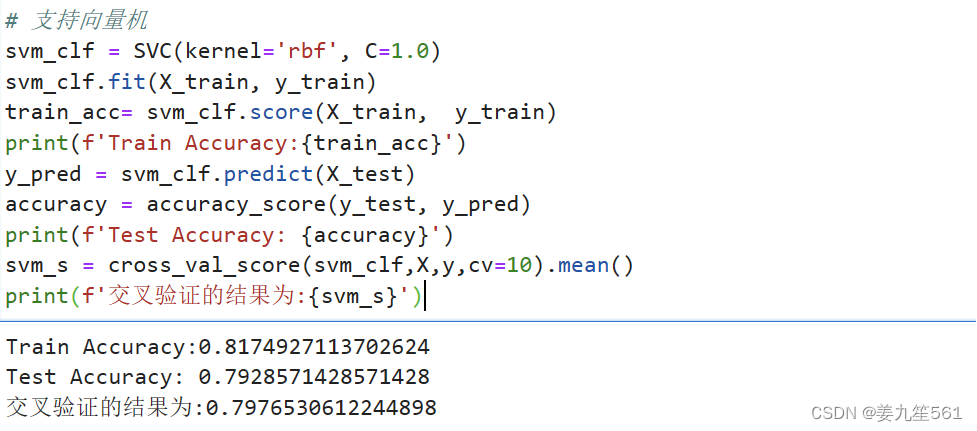
5.支持向量机
支持向量机是一种用于分类和回归的机器学习算法。SVM 的目标是找到一个超平面,将不同类别的样本分隔开,并确保分隔的间隔最大化。
在这里,选用的核函数为rbf进行多分类任务。
Ps:用线性模型准确率就很低。


随机森林调参
白葡萄酒
首先我对n_estumators进行调整,进行学习曲线的绘制。发现当n_estumators为89的时候,模型得到最高准确率94.71%。


然后我对max_depth进行调参。采用网格搜索的方式。

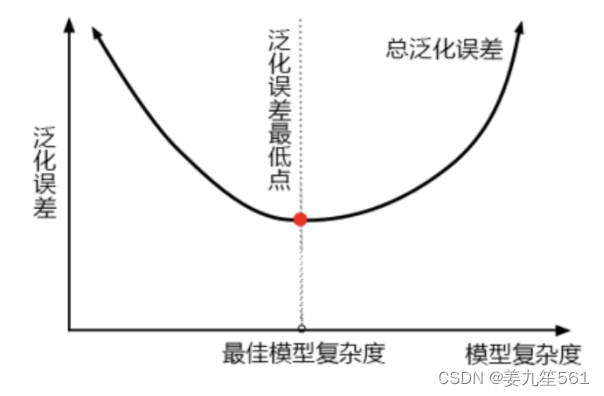
当限制了模型的深度之后,模型的准确率反而下降了,说明此时模型还没有达到最小的泛化误差的点,可以看出该模型拟合不足。用下面模型复杂度和泛化误差的关系这张图来看,限制max depth,是让模型变得简单,把模型向左推,而模型整体的准确率下降了,即整体的泛化误差上升了,表明此时我们的模型处在泛化误差最低点的左边(一般来说过拟合才正常,但此时是一个欠拟合的状态)。
因此我尝试调整max_feature。发现网格搜索返回的max_features最小值为2,此时准确率依然下降,说明模型本身已经处于泛化误差最低点,已经达到了模型的预测上限。

那因此我只调整n_estumators,其他的不作调整。