文章目录
- 指令微调数据集
- 人类对齐数据集
为了增强模型的任务解决能力,大语言模型在预训练之后需要进行适应性微调,通常涉及两个主要步骤,即指令微调(有监督微调)和对齐微调。
指令微调数据集
在预训练之后,指令微调(也称为有监督微调)是增强或激活大语言模型特定能力的重要方法之一(例如指令遵循能力)。本小节将介绍几个常用的指令微调数据集,并根据格式化指令实例的构建方法将它们分为三种主要类型,即自然语言处理任务数据集、日常对话数据集和合成数据集。
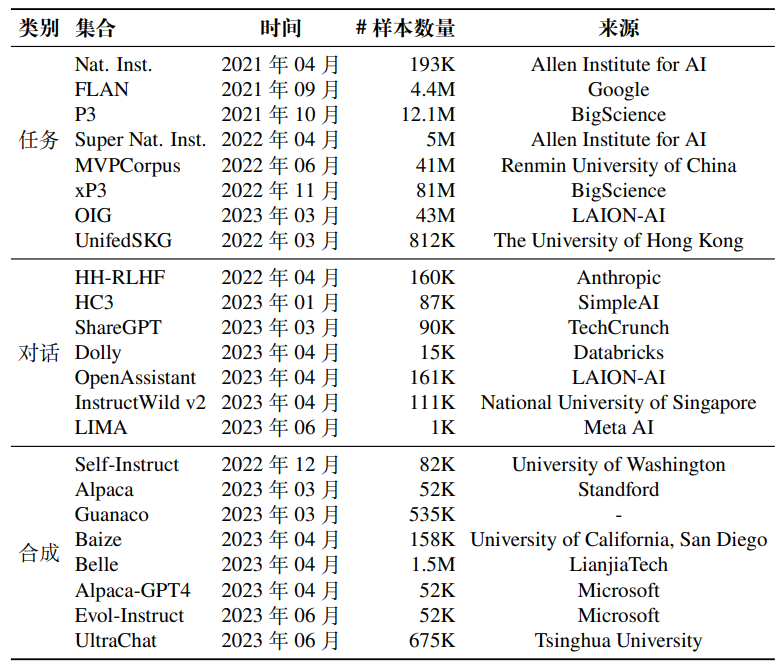
在指令微调被提出前,早期的研究通过收集不同自然语言处理任务(如文本分类和摘要等)的实例,创建了有监督的多任务训练数据集。这些多任务训练数据集成为了构建指令微调数据集的重要来源之一。一般的方法是使用人工编写的任务描述来扩充原始的多任务训练数据集,从而得到可以用于指令微调的自然语言处理任务数据集。其中,P3和 FLAN是两个代表性的基于自然语言处理任务的指令微调数据集。
P3(Public Pool of Prompts)是一个面向英文数据的指令微调数据集,由超过 270 个自然语言处理任务数据集和 2,000 多种提示整合而成(每个任务可能不止一种提示),全面涵盖多选问答、提取式问答、闭卷问答、情感分类、文本摘要、主题分类、自然语言推断等自然语言处理任务。P3 是通过 Promptsource(一个收集任务提示的众包平台)收集的,其子集被用来训练 T0 模型。
早期的 FLAN 是通过将 62 个广泛使用的 NLP 基准数据集进行格式化得到的英语指令数据集。现在俗称的 FLAN 实际上是指 FLAN-v2,主要由四个子集 Muffin、NIV2、T0-SF 和 CoT 构成。其中,Muffin 由之前 FLAN 的 62 个任务和新加入的 26 个任务组成(包括对话数据和代码合成数据);T0-SF 则是从T0 模型的数据中抽取出来,同时确保与 Muffin 不重叠;NIV2 指的是数据集Natural-Instructions v2;而 CoT 则是为了增强模型的推理能力而加入的九种不同推理任务的组合。与此同时,FLAN-v2 对每项任务都设置了最大上限,因为在同一混合数据集中,有些任务比其他任务大得多,这可能会在采样中占主导地位,从而影响模型的训练效果。据 FLAN 论文,使用了Muffin:52%,T0-SF:15%,CoT:3%,NIV2:30% 这一混合比例,通常能够使得模型具有较好表现。
日常对话数据集是基于真实用户对话构建的,其中查询主要是由真实用户提出的,而回复是由人类标注员回答或者语言模型所生成。主要的对话类型包括开放式生成、问答、头脑风暴和聊天。其中,三个较为常用的日常对话数据集包括ShareGPT、OpenAssistant和 Dolly。
ShareGPT,该数据集因来源于一个开源的数据收集平台 ShareGPT 而得名。在该平台中,用户可以将自己的各种对话数据通过浏览器插件进行上传。这些对话包括来自 OpenAI ChatGPT 的用户提示和回复,语种主要为英语和其他西方语言。具体来说,查询来自于用户的真实提问或指令,回复则是 ChatGPT 对此生成的回答。
OpenAssistant,该数据集是一个人工创建的多语言对话语料库,共有91,829条用户提示,69,614 条助手回复。OpenAssistant 共包含 35 种语言的语料,每条语料基本都附有人工标注的质量评级(例如回复的有用性、无害性等)。值得注意的是,这里所有的数据都是由用户真实提供的,与上面所提到 ShareGPT 的数据构建方式并不相同。
Dolly,该数据集是一个英语指令数据集,由 Databricks 公司发布。Dolly 包含了 15,000 个人类生成的数据实例,旨在让大语言模型与用户进行更符合人类价值的高效交互。该数据集由 Databricks 员工标注得到,主题涉及 InstructGPT 论文中提到的 7 个领域,包括头脑风暴、分类、封闭式质量保证、生成、信息提取、开放式质量保证和总结等。
合成数据集通常是使用大语言模型基于预定义的规则或方法进行构建的。其中,Self-Instruct-52K和 Alpaca-52K是两个具有代表性的合成数据集。
Self-Instruct-52K 是使用 self-instruct 方法生成的英语指令数据集,共包含 52K 条指令以及 82K 个实例输入和输出。最初,由人工收集创建了 175 个种子任务,每个任务包括 1 个指令和 1 个包含输入输出的实例。然后,每次随机抽取了 8 个指令作为示例,以此提示 GPT-3 生成了新的指令,之后在这些已有指令的基础上,继续利用 GPT-3 生成实例输入及其对应的输出,从而获得了更多数据。这些新得到的指令和输入输出经过滤(去除低质量或重复数据)后会加入数据集中,并继续类似的循环。通过迭代上述过程,最终获得了 52K 条指令和 82K 个实例数据,其中每一条指令可能会用于生成多个输入输出的实例。
Alpaca-52K 数据集同样是基于 self-instruct 方法进行构建的,它是在 Self-Instruct-52K 的 175 个种子任务上,利用 OpenAI 的 text-davinci-003模型获得了 52K 个不重复的指令,并根据指令和输入生成了输出,进而构成了完整的实例数据。与 Self-Instruct-52K 不同,这里每条指令仅对应于一个输入输出实例。此外,Alpaca-52K 在生成数据的过程中考虑到了输入的可选性,最终的数据中只有 40% 具有输入部分。也正是因此,Alpaca 也包含两种提示模板:包括输入以及不包括输入。
人类对齐数据集
除了指令微调之外,将大语言模型与人类价值观和偏好对齐也非常重要。现有的对齐目标一般聚焦于三个方面:有用性、诚实性和无害性。本节将介绍几个代表性的对齐微调数据集,它们各自针对上述对齐目标进行了标注,包括 HH-RLHF、SHP、PKU-SafeRLHF、Stack Exchange Preferences、Sandbox Alignment Data 和 CValues。下表展示了这些数据集合的详细信息。
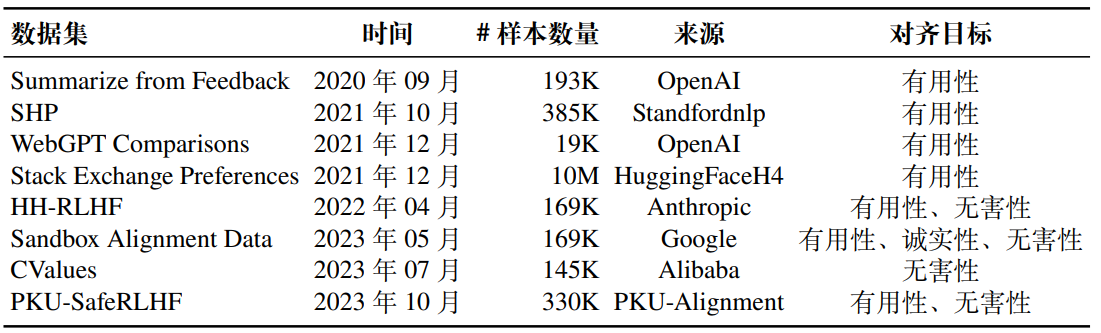
HH-RLHF,该数据集包含两大类标注数据,分别关注于大语言模型的有用性和无害性。整个数据集共包含约 169K 个开放式对话,每个对话涉及一个众包工作者向一个智能信息助手寻求帮助、建议或请求完成任务等情景。信息助手将会为每个用户查询提供两个回复,一个回复被选择而另一个被拒绝。对于有用性相关的数据中,被认为更有用的回复将被选择;而对于无害性相关的数据中,被认为更有害的回复则将被选择。
SHP,该数据集主要关注模型生成回复内容的有用性。该数据集共 385K 个数据实例,对于 18 个不同主题领域中问题/指令的人类偏好进行标注,涵盖了从烹饪到法律建议等各种主题。每个数据实例都是基于一个寻求帮助的 Reddit 帖子构建的,包含该帖子中的问题和帖子下两个排名较高的评论。这两个评论其中一个被 Reddit 用户认为更有用,另一个被认为不太有帮助。与 HH-RLHF不同,SHP 中的数据并非模型生成,而是人类的回复贴子。
PKU-SafeRLHF,该数据集侧重于对回复内容的有用性和无害性进行标注。该数据集囊括了 330K 个专家注释的实例,每一个实例都包含一个问题及其对应的两个回答。其中,每个回答都配备了安全性标签,用以明确指出该回答是否安全。此外,标注者还会就这两个回答在有用性和无害性方面进行细致的比较和偏好注释。
Stack Exchange Preferences,该数据集专注于对答案的有用性进行标注,涵盖了来自知名编程问答社区 Stack Overflow 的约 10M 个问题和答案,具有很高的实用价值。每个数据实例均包含一个具体的问题以及两个或更多的候选答案。每个候选答案都附有一个根据投票数计算得出的分数,并附带了一个表示是否被选中的标签。
Sandbox Alignment Data,该数据集致力于运用模型自身的反馈机制来进行数据标注,而非依赖人类的直接参与。此数据集源自于一个名为 SANDBOX 的虚拟交互环境,该环境模拟了人类社交互动的场景。在这个环境中,多个大语言模型根据问题给出回复然后互相“交流”,并根据彼此的反馈来不断修正和完善自己的回复,以期达到更佳的交互效果。该数据集涵盖了 169K 个实例,每个实例均包含一个查询、多个回复选项以及由其他模型给出的相应评分。
CValues,该数据集是一个面向中文的大模型对齐数据集,提出了安全性和责任性这两个评估标准。这个数据集包含了两种类型的提示:安全性提示和责任性提示。安全性提示共有 1,300 个,主要用于测试模型的安全性表现,这些提示的回复被人工标注为安全或不安全,但由于内容敏感,因此并未开源;责任性提示共有 800 个,这些提示由领域专家提供,并用于评估模型在特定领域内的责任性表现,专家也为这些提示的回复进行了打分。由于内容敏感,实际开放的数量有删减。除此之外,CValues 还提供对比形式的数据集,该数据集中一共有 145K 样例,每条样例包含提示、正例回复(被认为更安全更负责任的回复)和负例回复,这部分数据被完全开源。