文章目录
- 💥一、PPT模版爬取
- 🔥1.1 第一个爬虫
- 🚲1. 获取下载页面链接
- ❤️1.2 第二个爬虫
- 🚲1.3 第三个爬虫
- 🎈2. 文件保存
- ❤️1.4 翻页处理
- 🔥二、完整代码
🔥🔥🔥 Python爬虫专栏
💥一、PPT模版爬取
🛤️目标网址
https://www.ypppt.com/moban/
关于第三方模块requests:
Python 的第三方模块 requests 是一个非常流行的 HTTP 客户端库,用于发送各种 HTTP 请求。它由 Kenneth > Reitz 开发,并被广泛用于 Python 社区。以下是 requests 模块的一些主要特点:
- 简单易用:requests 的 API 设计简洁,使得发送 HTTP 请求变得非常简单。
- 跨平台:它支持 Python 2.7 和 3.4+ 版本,可以在多种操作系统上运行。
- 国际化:支持国际域名和 URL。
- HTTP 连接保持:可以持久化连接,减少连接建立的开销。
- 支持多部分文件上传:方便地上传文件。
- 支持 Sessions:允许跨请求保持某些参数,如 cookies。
- 可连接的流式请求:可以方便地下载大文件。
- 支持同步和异步操作:虽然 requests 本身是同步的,但可以与异步框架如 grequests 或 aiohttp 结合使用。
- SSL 证书验证:默认情况下会验证 SSL 证书。
- 社区支持:由于其流行度,requests 有一个活跃的社区,可以快速获得帮助和支持。
安装:
pip install requests
✈1.1 爬虫框架
💥思路:
- 模板的主页链接:
https://www.ypppt.com/moban/ - 获取某一个PPT的下载页面链接:
https://www.ypppt.com/p/d.php?aid=8257 - 获取下载链接
# 导入请求模块
import requests
# 伪装
headers = {
'User-Agent': '浏览器信息',
'Cookie': '浏览器信息'
}
url = '目标网址'
# 请求网址获得响应
res = requests.get(url, headers=headers)
🔥1.1 第一个爬虫
根据我们的思路,首先我们要写第一个爬虫来从模版首页获取PPT编号
🛤️目标网址:https://www.ypppt.com/moban/
🛤️浏览器信息:
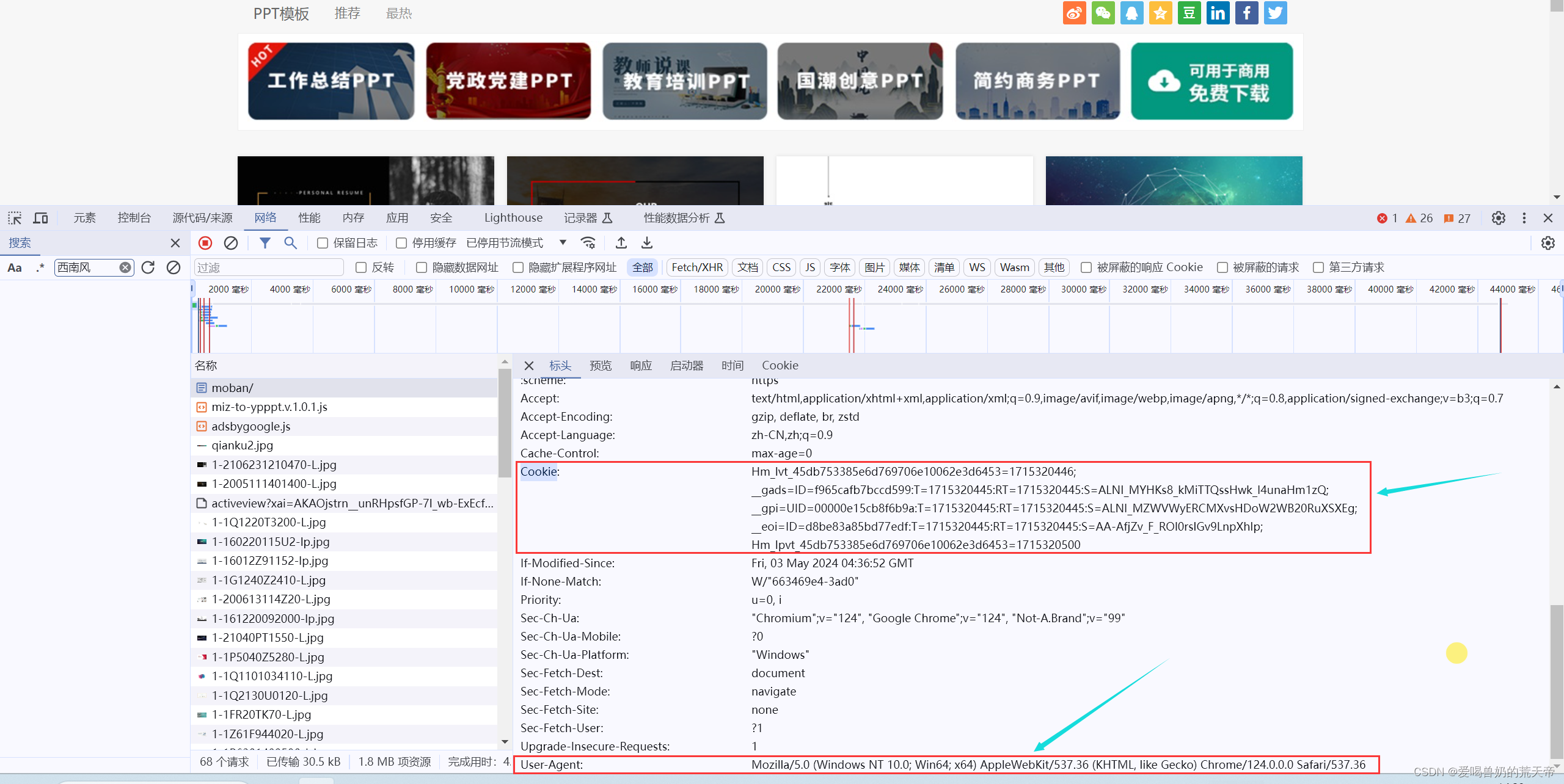
# 导入请求模块
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'Cookie': 'Hm_lvt_45db753385e6d769706e10062e3d6453=1715320446; __gads=ID=f965cafb7bccd599:T=1715320445:RT=1715320445:S=ALNI_MYHKs8_kMiTTQssHwk_I4unaHm1zQ; __gpi=UID=00000e15cb8f6b9a:T=1715320445:RT=1715320445:S=ALNI_MZWVWyERCMXvsHDoW2WB20RuXSXEg; __eoi=ID=d8be83a85bd77edf:T=1715320445:RT=1715320445:S=AA-AfjZv_F_ROl0rslGv9LnpXhIp; Hm_lpvt_45db753385e6d769706e10062e3d6453=1715320500'
}
url = 'https://www.ypppt.com/moban/'
# 请求网址获得响应
res = requests.get(url, headers=headers, verify=False)
print(res.text)
注意:在使用 Python 的 requests 库发送 HTTP 请求时,verify 参数是一个布尔值,它控制着 SSL 证书验证的行为。
-
当 verify=True(默认设置)时,requests 会验证 SSL 证书的有效性。这意味着 requests 将检查你正在与之通信的服务器是否拥有一个有效的、由受信任的证书颁发机构签发的 SSL 证书。如果证书无效或过期,或者与请求的主机名不匹配,requests 将抛出一个 SSLError 异常。
-
当 verify=False 时,requests 将不会验证 SSL 证书的有效性。这通常用于测试环境或某些特定情况下,服务器使用自签名证书或不安全的连接,而你又不希望因为证书验证而中断请求。
使用 verify=False 会降低安全性,因为它允许连接到可能不安全的服务器,这可能使你的应用程序容易受到中间人攻击。因此,除非有充分的理由,否则不建议在生产环境中禁用 SSL 证书验证。
此外,verify 参数也可以是一个字符串,指定一个文件路径,该文件包含多个受信任的SSL证书的路径。这允许你使用自定义的证书颁发机构的证书。
示例:
import requests
# 默认情况下,verify 为 True,将验证 SSL 证书
response = requests.get('https://example.com', verify=True)
# 禁用 SSL 证书验证
response = requests.get('https://example.com', verify=False)
# 使用自定义证书
response = requests.get('https://example.com', verify='path/to/custom/cert.pem')
在处理金融数据、用户个人信息或其他敏感数据时,确保 SSL 证书验证是启用的非常重要,以维护数据的安全性和完整性。
注意:在写爬虫的时候如果遇到SSL的错误,也就是证书检查,可以使用verify=False来忽略证书检查!
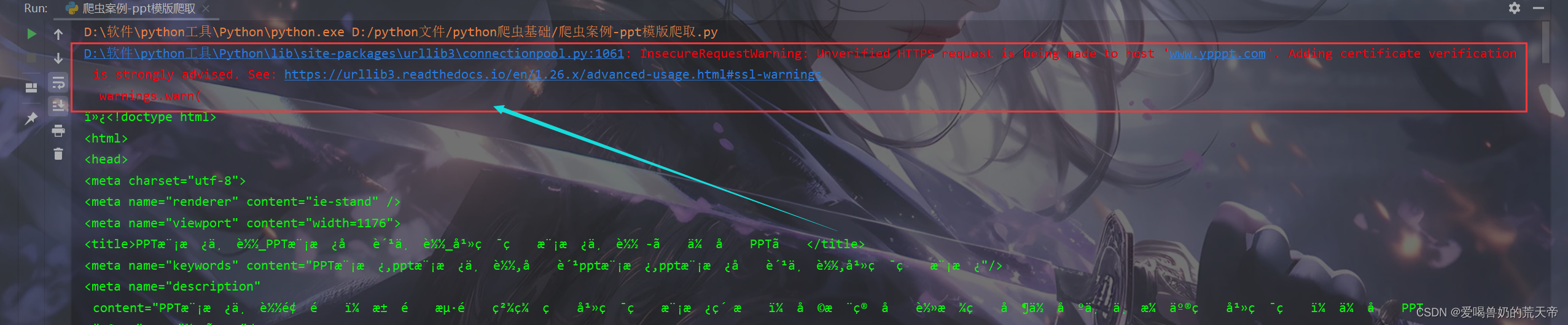
由于我们忽略了证书检查,所以每次运行都会有一个警告,忽略警告的代码如下:
# 导入请求模块
import requests
# 忽略警告
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
url = 'https://www.ypppt.com/moban/'
# 请求网址获得响应
res = requests.get(url, headers=headers, verify=False)
print(res.text)
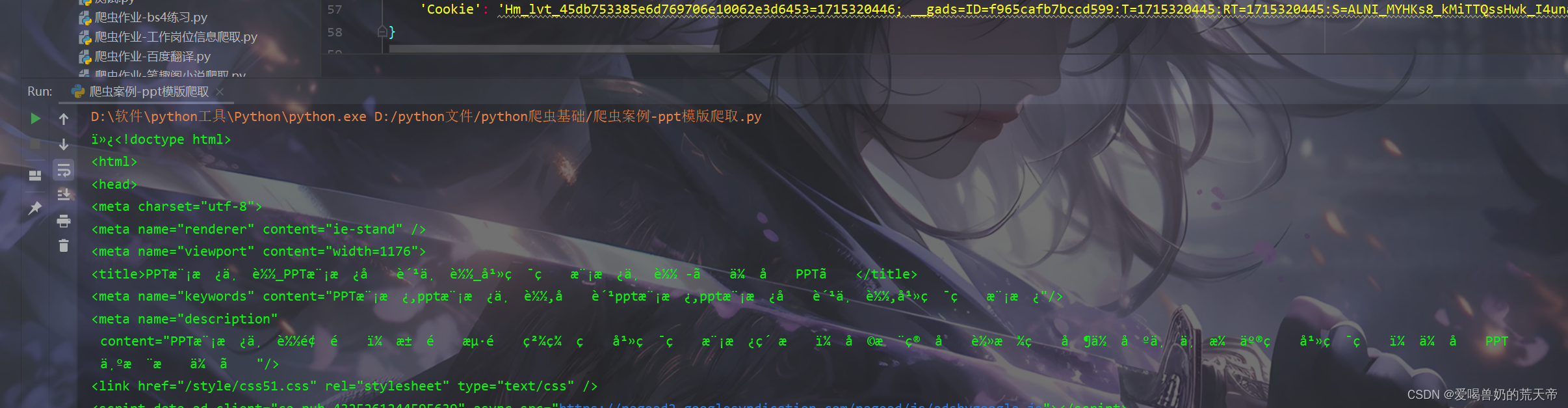
☔解决乱码问题
从上面的截图可以看出,打印出来的内容有许多我们不认识的符号,比如:è½½_å¹»ç¯ç‰‡æ¨¡æ¿ä¸‹è½½ -ã€ä¼˜å,这就是乱码造成的
我们可以通过改变编码方式来解决:
# 导入请求模块
import requests
# 忽略警告
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
url = 'https://www.ypppt.com/moban/'
# 请求网址获得响应
res = requests.get(url, headers=headers, verify=False)
# 编码改成utf-8
res.encoding = 'utf-8'
print(res.text)
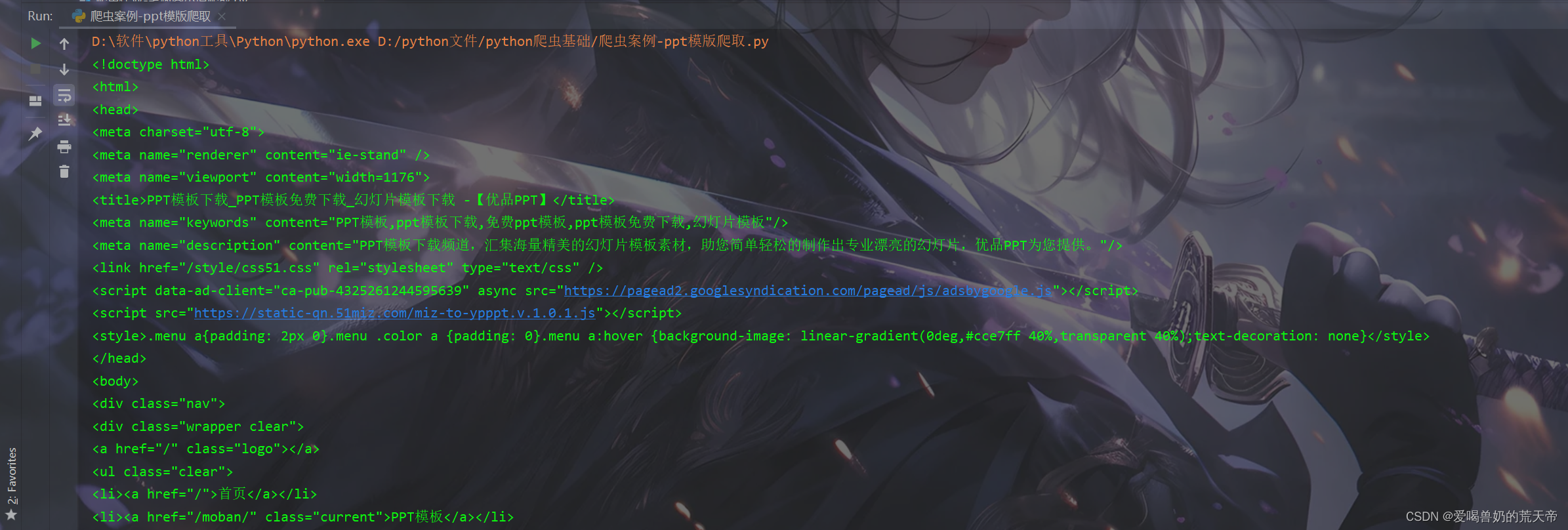
🚲1. 获取下载页面链接
我们可以通过正则表达式来获取PPT的下载页面链接
Python 的 re 模块是一个用于正则表达式操作的内置库,它提供了丰富的功能来处理字符串和模式匹配。正则表达式是一种用于字符串搜索和操作的强大工具,它们使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
re 模块的一些常用功能和方法:
- 模式匹配 (re.match(), re.search(), re.findall(), re.finditer(), re.match()):这些方法用于在字符串中查找与正则表达式模式相匹配的子串。
- 字符串替换 (re.sub(), re.subn()):用于替换字符串中的匹配项。
- 捕获组:正则表达式中的圆括号 () 用于创建捕获组,允许你捕获匹配表达式的部分内容。
- 编译正则表达式 (re.compile()):允许你编译一个正则表达式模式,然后使用编译后的模式进行匹配和其他操作。
- 特殊序列:如 \d 表示数字,\w 表示字母、数字或下划线,. 表示任意单个字符等。
- 量词:如 * 表示0次或多次,+ 表示1次或多次,? 表示0次或1次,{m,n} 表示m到n次。
- 贪婪与非贪婪:默认情况下,量词是贪婪的,尽可能多地匹配字符。添加一个问号 ? 可以使量词变为非贪婪的,尽可能少地匹配字符。
- 特殊字符转义:使用反斜杠 \ 来转义正则表达式中的特殊字符,如 . 匹配字面意义上的点(.)。
- 正则表达式标志:如 re.IGNORECASE 或 re.I 用于忽略大小写,re.MULTILINE 或 re.M 用于多行匹配。
# 导入请求模块
import requests
import re
# 忽略警告
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
url = 'https://www.ypppt.com/moban/'
# 请求网址获得响应
res = requests.get(url, headers=headers, verify=False)
# 提取数据
res.encoding = 'utf-8' # 编码改成utf-8
# print(res.text)
pptId = re.findall('href="/article/.*?/(.*?).html" class="p-title"', res.text)
print(pptId)

👊构造PPT下载页面链接
for i in pptId:
# 构造新的链接
url = 'https://www.ypppt.com/p/d.php?aid=' + i
print(url)
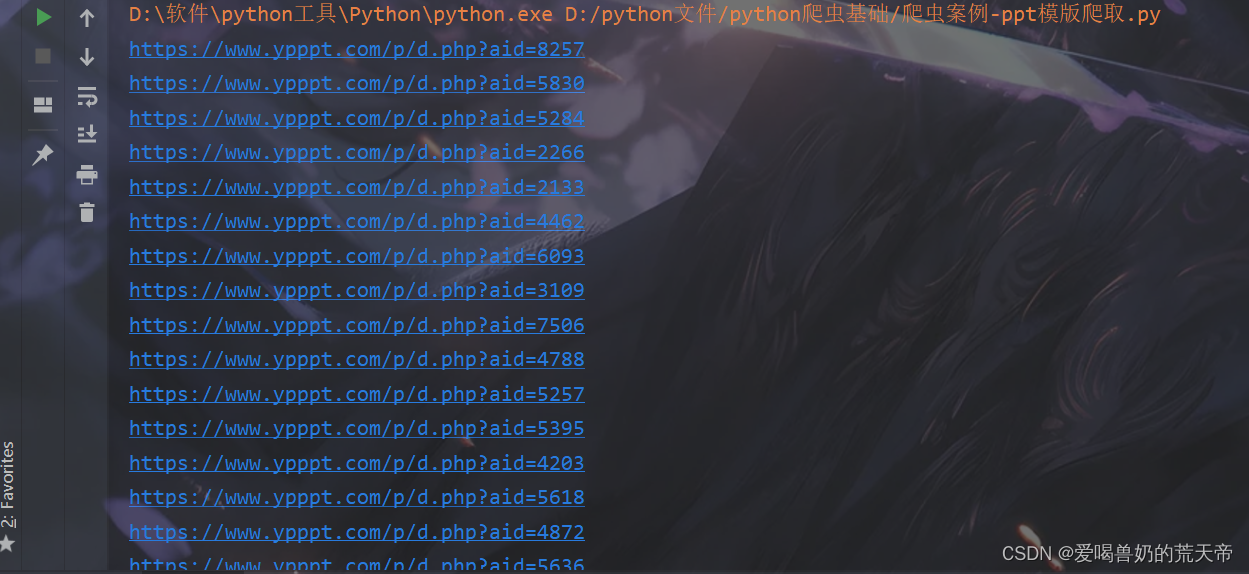
注意:构造出来的链接不是PPT的下载链接,这是PPT下载页面链接。
❤️1.2 第二个爬虫
for i in pptId:
# 构造新的链接
url1 = 'https://www.ypppt.com/p/d.php?aid=' + i
# print(url)
res1 = requests.get(url1, headers=headers, verify=False)
print(res1.text)
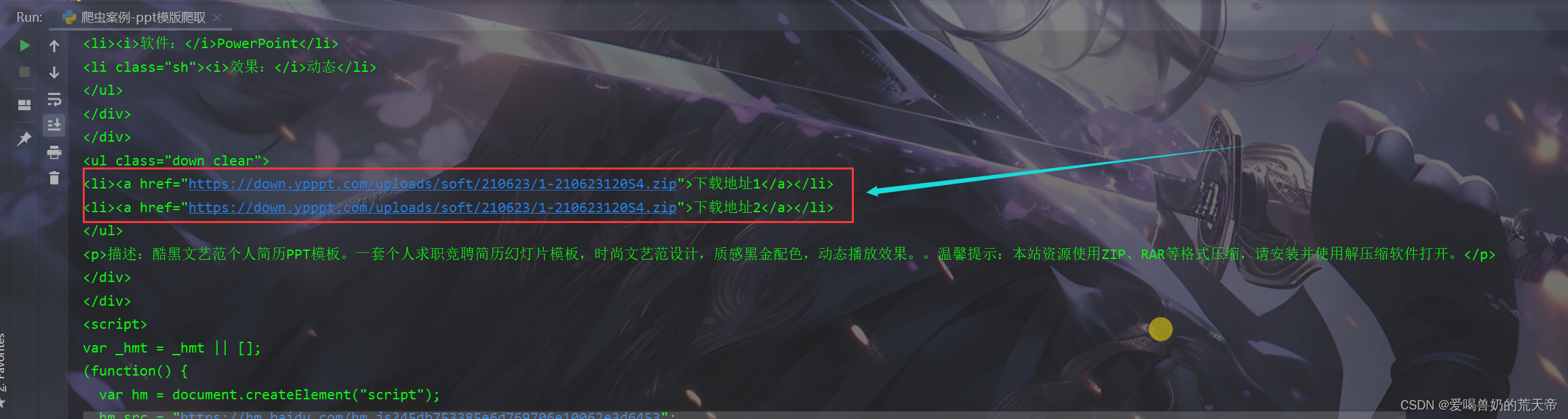
在第二次请求的时候我们就可以获取PPT模版的下载地址,接下来就和上面的数据提取一样,利用正则表达式将我们的PPT下载链接提取出来即可。
for i in pptId:
# 构造新的链接
url1 = 'https://www.ypppt.com/p/d.php?aid=' + i
# print(url)
res1 = requests.get(url1, headers=headers, verify=False)
# print(res1.text)
# 提取数据
down_url = re.findall('href="(.*?)">下载地址1</a>', res1.text)[0]
print(down_url)
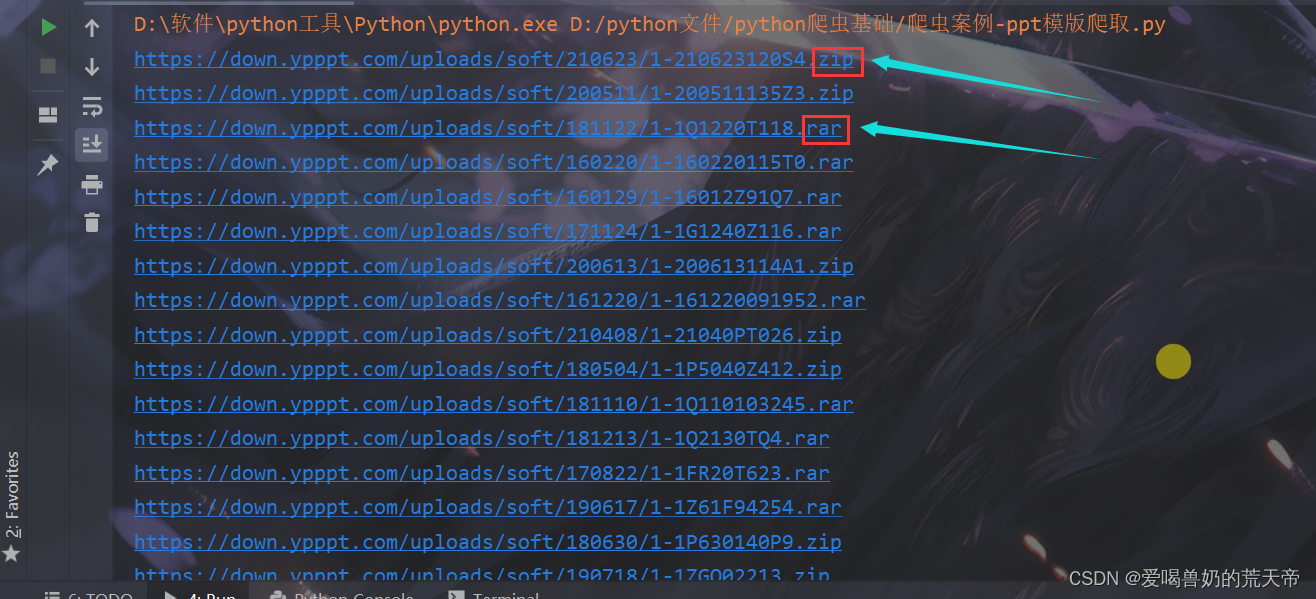
我们发现我们获取的链接的后缀名是不同的,另外这些PPT都是没有名字的,不方便后续保存。所以这里我们要修改一下,不单单只获取PPT的编号,还需要获取PPT的标题,根据标题等信息作为保存PPT模版的文件名。
ppt_info = re.findall('href="/article/.*?/(.*?).html" class="p-title" target="_blank">(.*?)</a>', res.text)
print(ppt_info)

可以看到得到的数据是一个列表嵌套这元组,直接通过循环获取ID和标题即可。
ppt_info = re.findall('href="/article/.*?/(.*?).html" class="p-title" target="_blank">(.*?)</a>', res.text)
for i, title in ppt_info:
# 构造新的链接
url1 = 'https://www.ypppt.com/p/d.php?aid=' + i
res1 = requests.get(url1, headers=headers, verify=False)
# print(res1.text)
# 提取数据
down_url = re.findall('href="(.*?)">下载地址1</a>', res1.text)[0]
print(title, down_url)
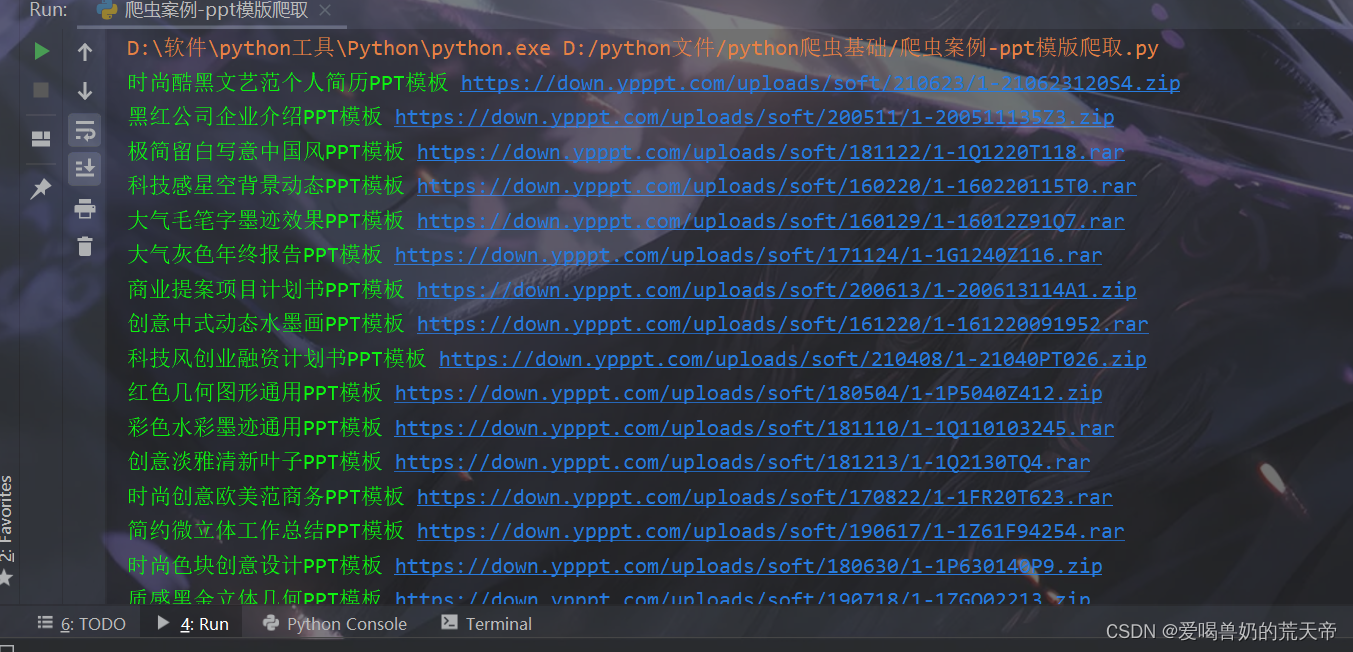
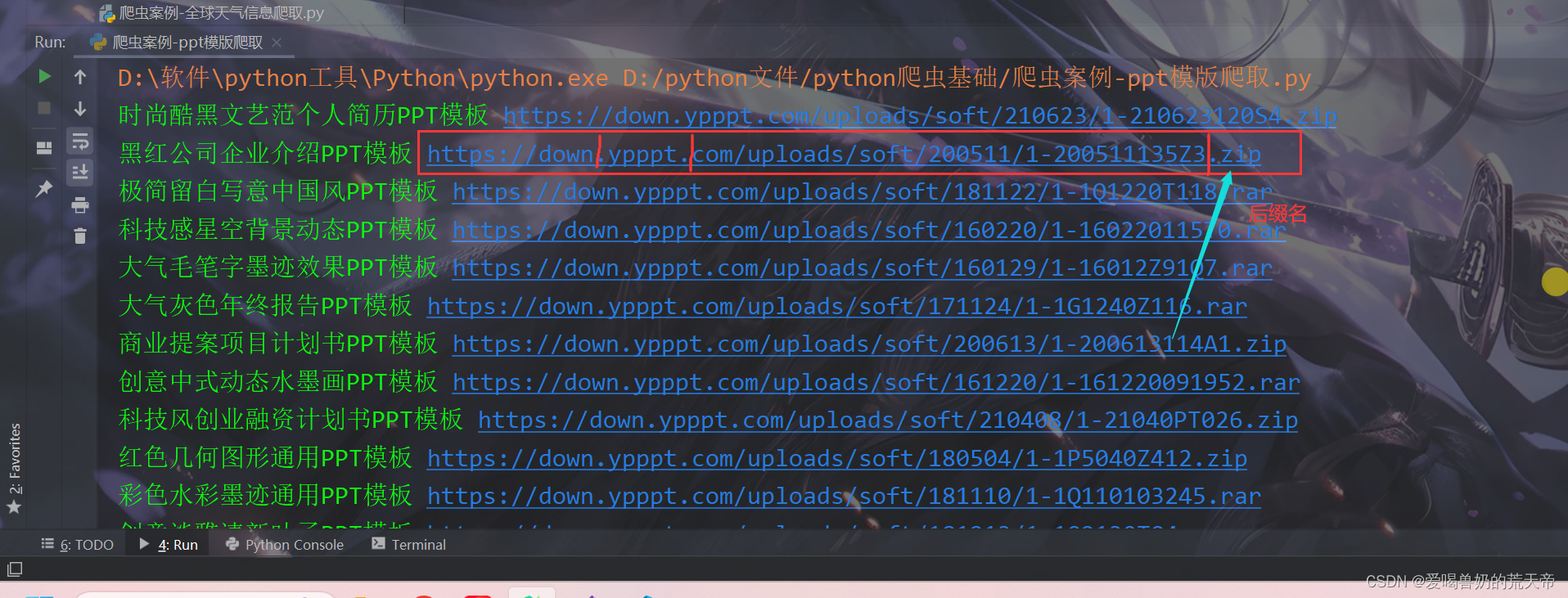
对于链接的后缀名的不同,我们可以对链接以 . 进行切割,然后取最后一个就是他的后缀名。
suffix = down_url.split(".")[-1] # 获取后缀名
🚲1.3 第三个爬虫
res2 = requests.get(down_url, headers=headers, verify=False)
通过第三次请求去下载PPT模版。
🎈2. 文件保存
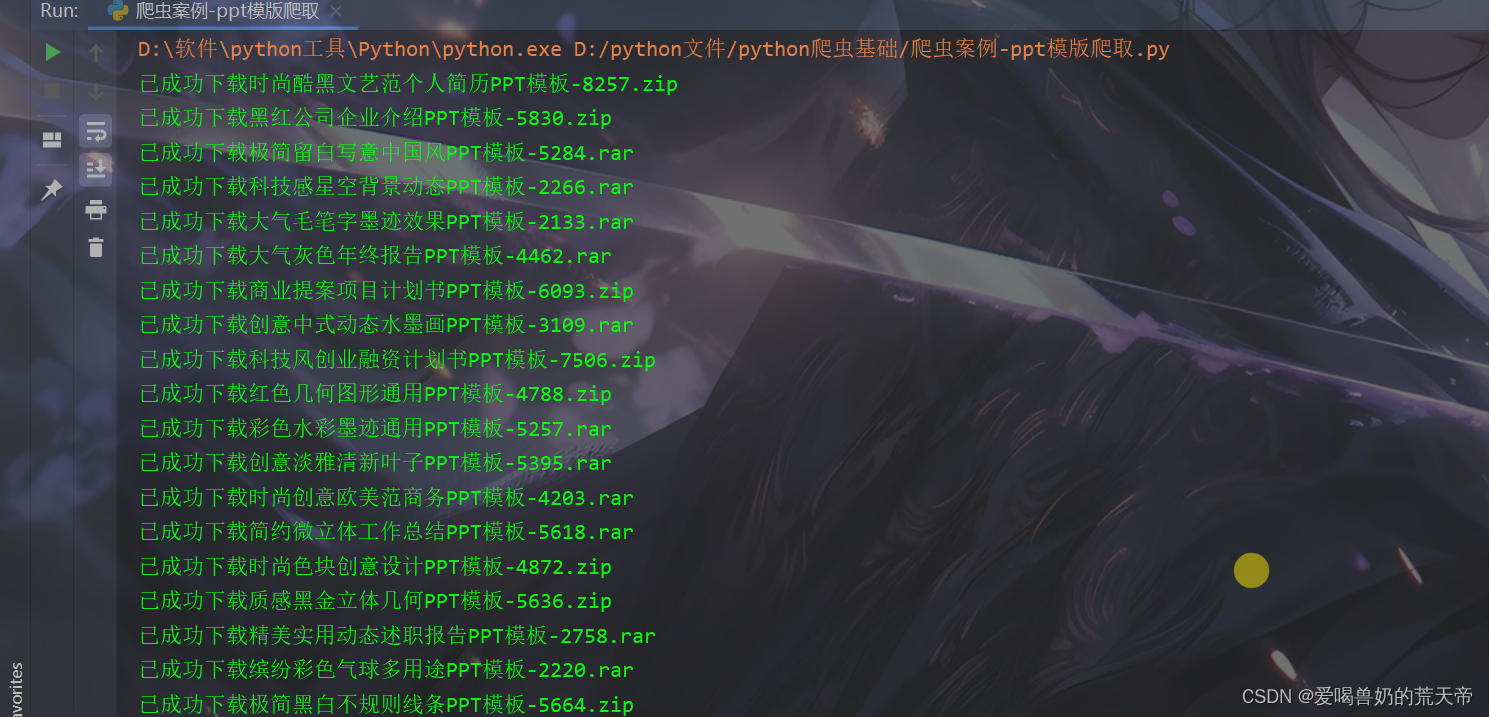
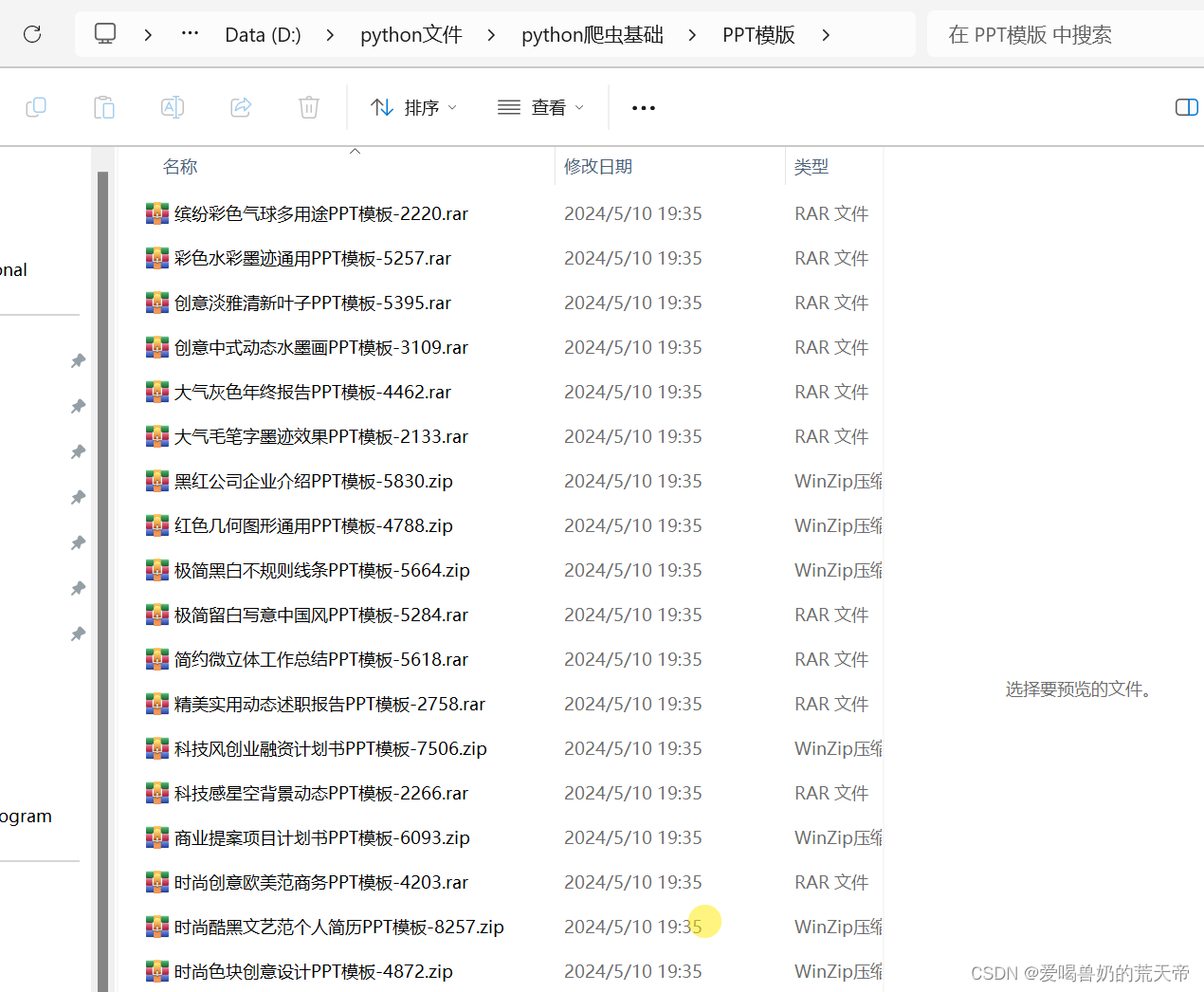
open(f'PPT模版/{title}-{i}.{suffix}', 'wb').write(res2.content)
这里为了避免文件名相同,我们在标题的后面加上他们的id号,文件的后缀名就是我们获取到的后缀名。
❤️1.4 翻页处理
要进行翻页处理,我们只需要观察不同页数的url的变化规律即可。
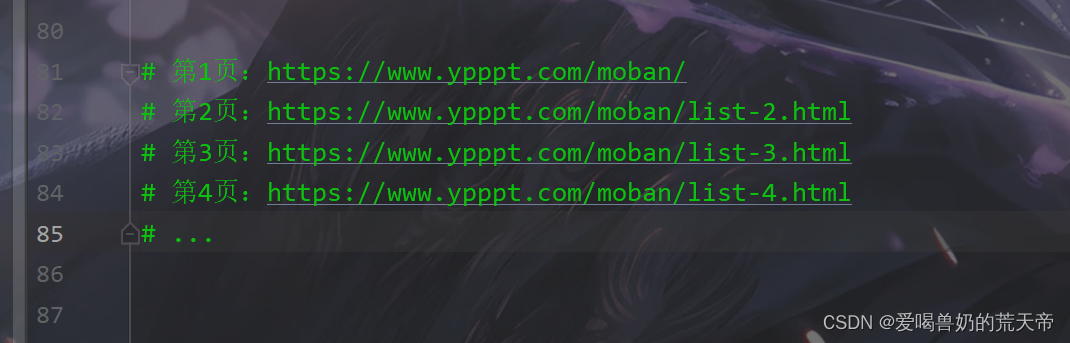
我们发现,除了第一页的url外,从第二页开始,url都是规律变化的,那首先我们可以尝试一下在第一页的url后面加上list-1.html,看是否可以访问,如果可以就直接加上,如果不可以,那我们就单独判断一下就可以了。
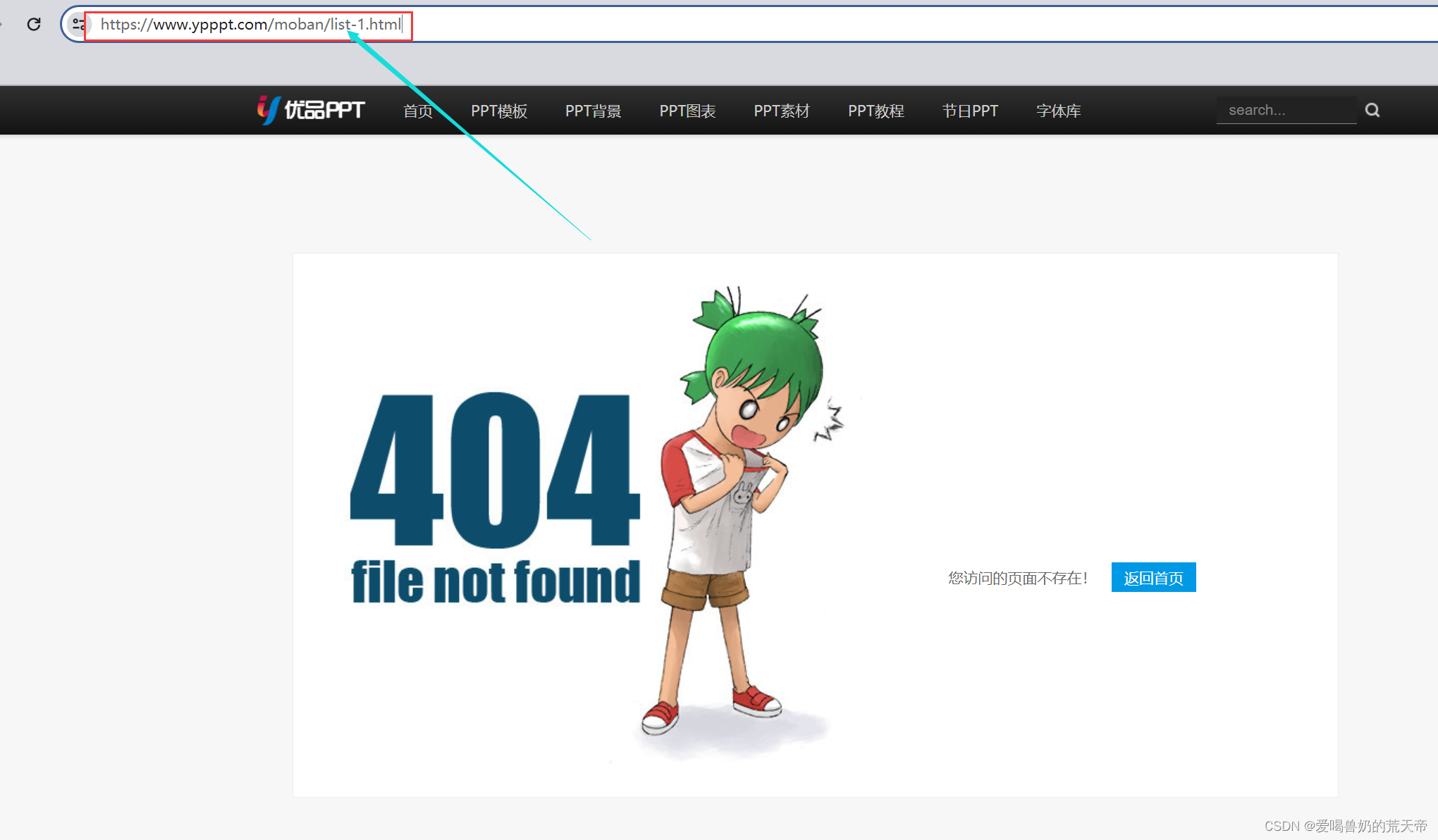
可以发现,加上后这个链接是无法访问的,所以我们只能单独的进行判断。
page = 1 # 页数, 从第一页开始
while True:
if page == 1:
# 第一页
url = 'https://www.ypppt.com/moban/'
else:
# 从第二页开始
url = f'https://www.ypppt.com/moban/list-{page}.html'
# 请求网址获得响应
res = requests.get(url, headers=headers, verify=False)
# 提取数据
res.encoding = 'utf-8' # 编码改成utf-8
# print(res.text)
ppt_info = re.findall('href="/article/.*?/(.*?).html" class="p-title" target="_blank">(.*?)</a>', res.text)
for i, title in ppt_info:
# 构造新的链接
url1 = 'https://www.ypppt.com/p/d.php?aid=' + i
res1 = requests.get(url1, headers=headers, verify=False)
# print(res1.text)
# 提取数据
down_url = re.findall('href="(.*?)">下载地址1</a>', res1.text)[0]
suffix = down_url.split(".")[-1] # 获取后缀名
res2 = requests.get(down_url, headers=headers, verify=False)
open(f'PPT模版/{title}-{i}.{suffix}', 'wb').write(res2.content)
page += 1 # 爬完之后页数+1
到这里其实还有一个问题没有解决,除了以链接下载PPT模版外,还有通过百度网盘链接下载的,这个由于有些复杂,另外通过网盘下载的模版数量很少,这里我们可以直接跳过不下载。
if 'pan.baidu' in down_url: # 百度网盘下载
continue
else:
suffix = down_url.split('.')[-1] # 获取后缀名
🔥二、完整代码
# 导入请求模块
import requests
import re
# 忽略警告
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
page = 1 # 页数, 从第一页开始
while True:
if page == 1:
# 第一页
url = 'https://www.ypppt.com/moban/'
else:
# 从第二页开始
url = f'https://www.ypppt.com/moban/list-{page}.html'
# 请求网址获得响应
res = requests.get(url, headers=headers, verify=False)
# 提取数据
res.encoding = 'utf-8' # 编码改成utf-8
# print(res.text)
ppt_info = re.findall('href="/article/.*?/(.*?).html" class="p-title" target="_blank">(.*?)</a>', res.text)
for i, title in ppt_info:
# 构造新的链接
url1 = 'https://www.ypppt.com/p/d.php?aid=' + i
res1 = requests.get(url1, headers=headers, verify=False)
# print(res1.text)
# 提取数据
down_url = re.findall('href="(.*?)">下载地址1</a>', res1.text)[0]
if 'pan.baidu' in down_url: # 百度网盘下载
continue
else:
suffix = down_url.split('.')[-1] # 获取后缀名
res2 = requests.get(down_url, headers=headers, verify=False)
open(f'PPT模版/{title}-{i}.{suffix}', 'wb').write(res2.content)
print(f'已成功下载{title}-{i}.{suffix}')
page += 1 # 爬完之后页数+1