1 深度学习简述

机器学习:相当于把公式实现出来了而已。
深度学习:
(1)中的特征工程使机器学习更智能。
(2)真正能学什么样的特征才是最合适的。
(3)主要应用于计算机视觉和自然语言处理
(4)最大的问题在于参数太多,计算速度太慢了

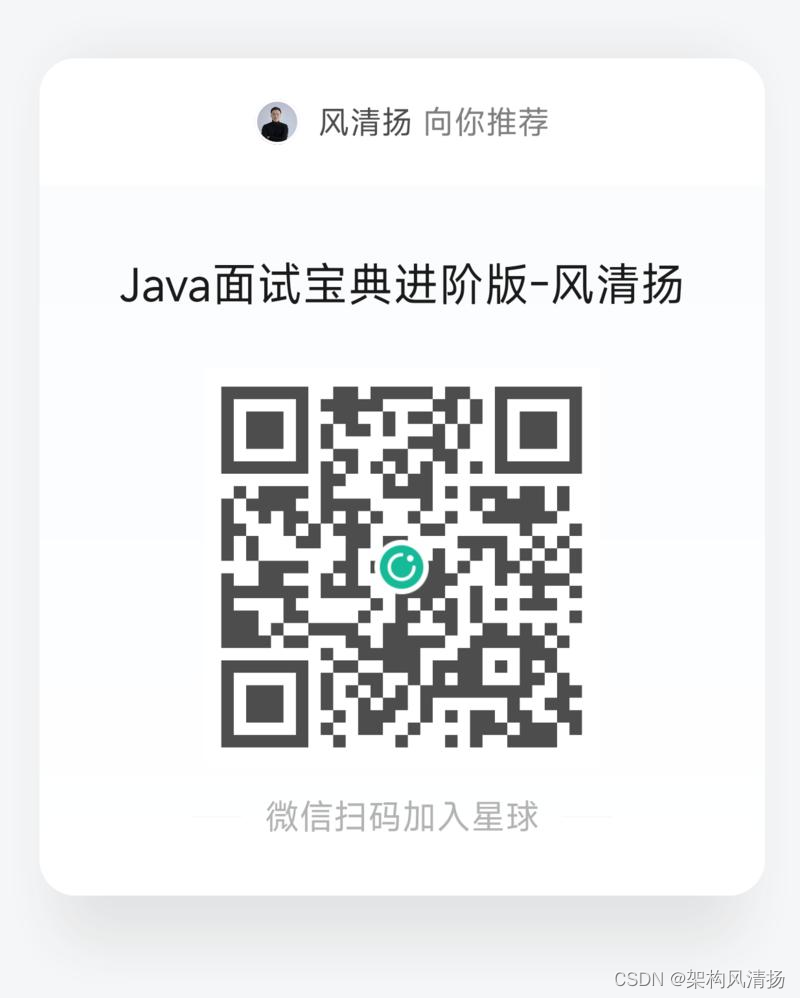
深度学习与传统人工智能算法对比
2 计算机视觉任务
2.1 图像表示
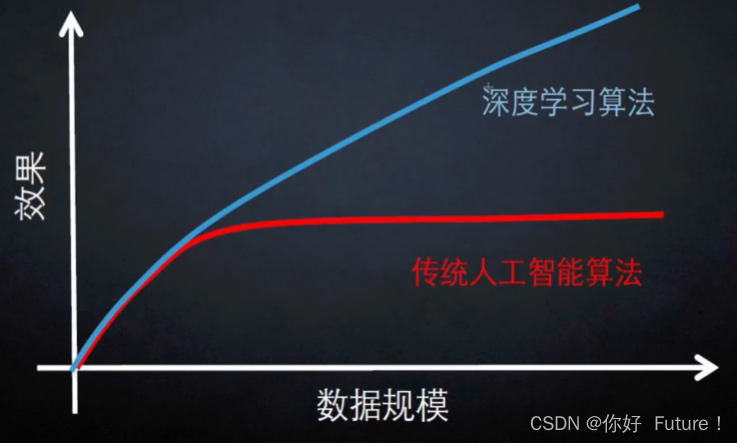
在计算机中一张图片被表示成三维数组的形式,每个像素点的值从0到255,例如:300*100*3【表示:图片高度为300像素(即有300个像素点),宽度为100像素,其中3表示有3个颜色通道,如RGB】

RGB:RGB颜色模式中,每个像素都由三个8位整数表示,分别代表红、绿、蓝三个通道的强度值。这三个通道可以分别控制图像中红色、绿色和蓝色部分的颜色强度和变化,从而实现对图像颜色的准确控制和调整。

2.2 计算机视觉面临的挑战


机器学习常规套路:
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
数据库推荐:CIFAR-10,这个数据库并不大,但分类多,数据量多,很适合用来测试。

K近邻算法(KNN)
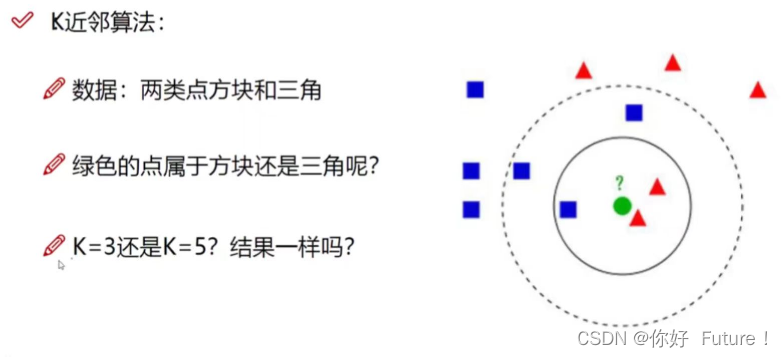

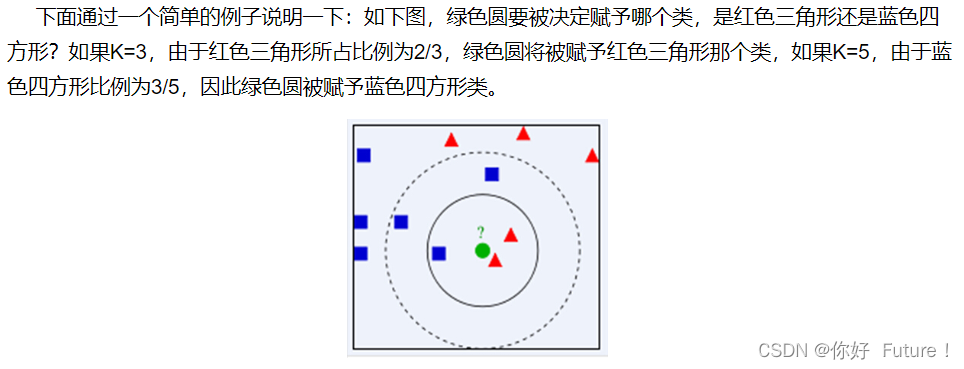
假如我们对图像采用KNN算法进行识别,其中距离计算采用如下方式(test-image像素值减去pixel-wise absolute value differences像素值得到training image像素值)

结果:

问题在于图像中的背景起到了很大的干扰作用!
3.1 实例计算
3.1.1 引言
思考其他的距离函数?
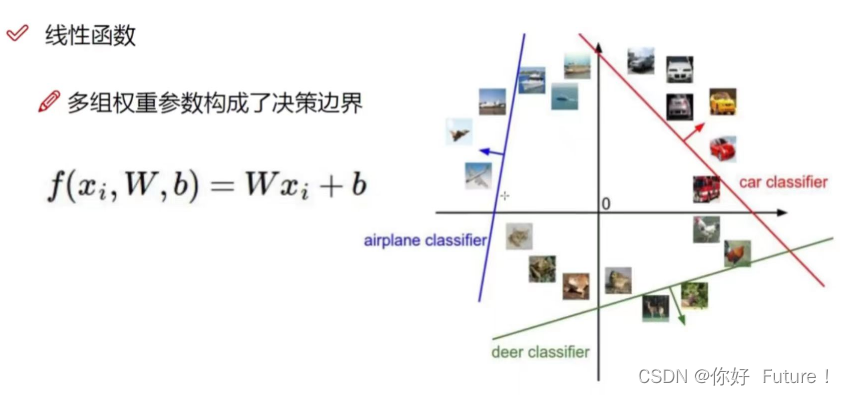
考虑像素点的权重:W是权重参数,x表示输入图像像素值,b是偏置参数(微调)

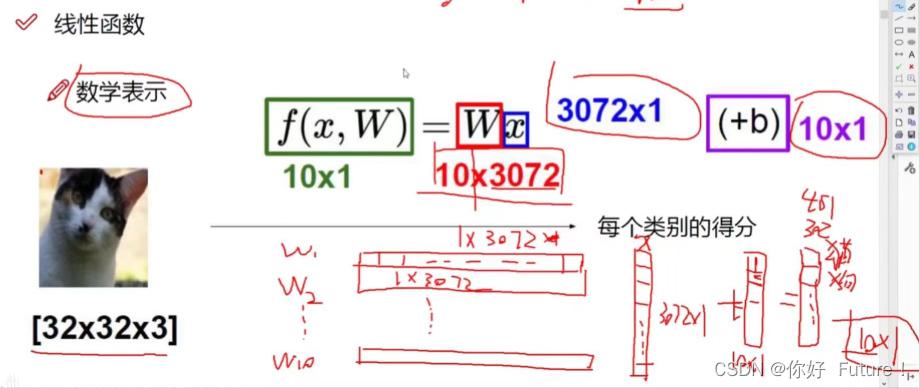
10*1表示输入图像在10个类别中各自的得分
10*3072表示每个类别对于每个像素点的权重值
3072*1表示输入图像总的像素(注意不是像素值)
3.1.2 实际计算过程
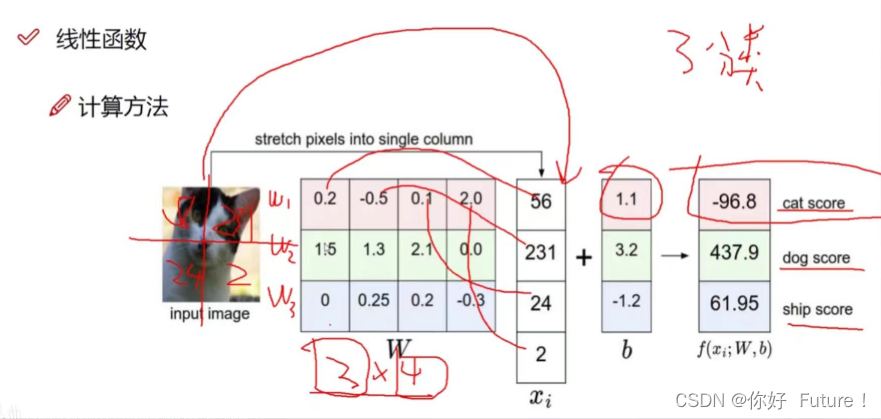
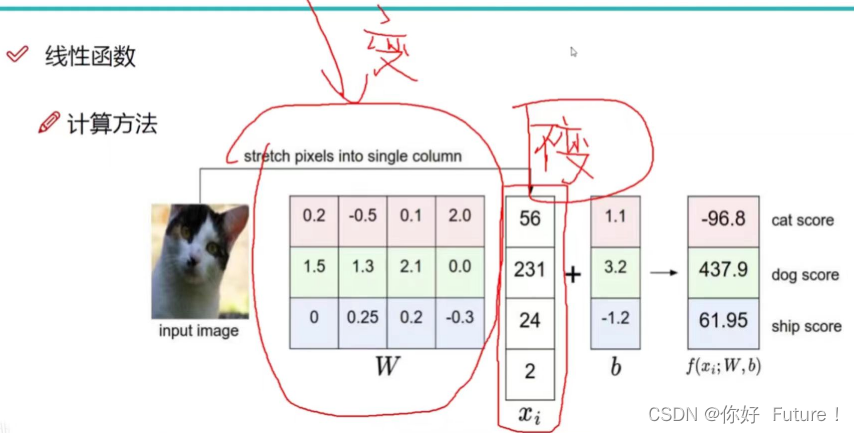
神经网路做的事情
神经网络在整个生命周期中,就在做:什么样的W能更适合于咱们的数据去做当前这个任务,我就怎么样去改变这个W。
迭尔塔相当于容忍程度的意思。
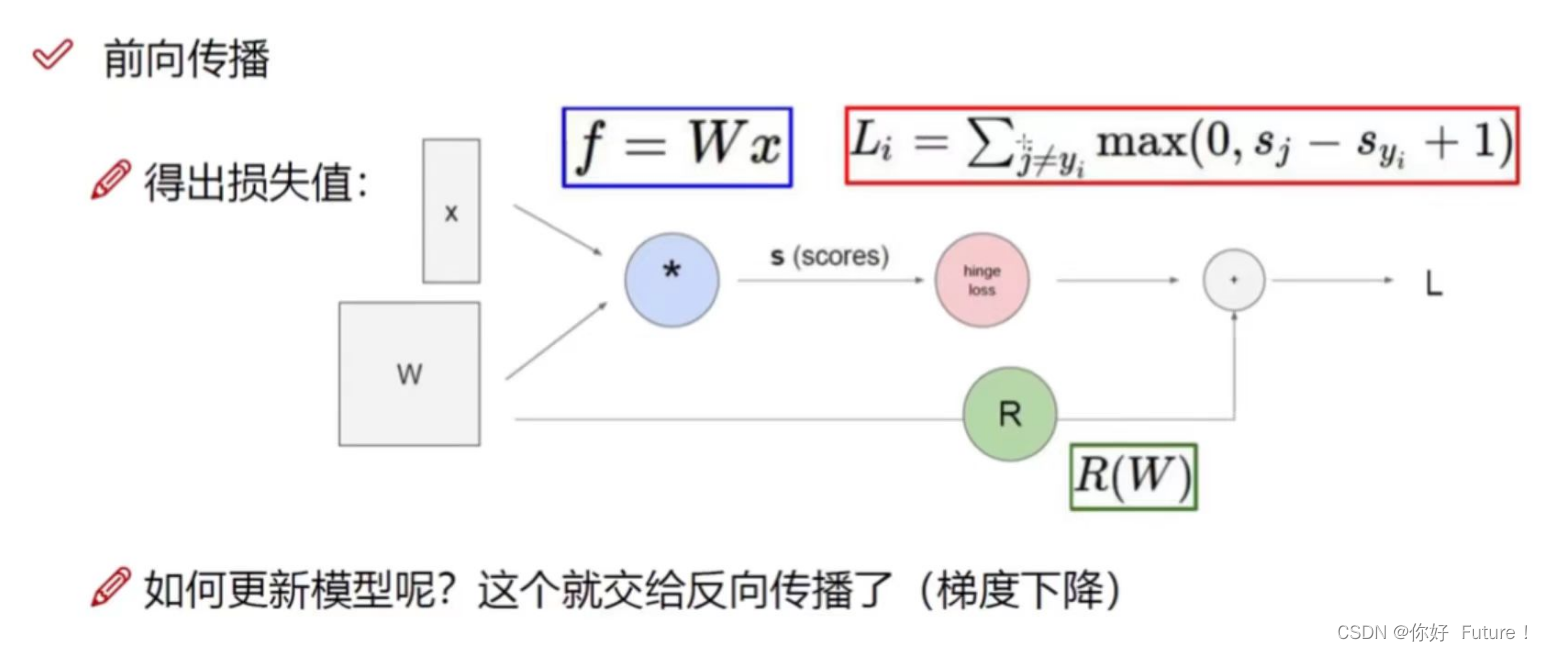
Sj:其他错误类别 Syj:正确类别 +1:表示容忍程度为1,也就是说只有当正确类别至少比错误类别高1才能说这个结果是正确的。
例如第一组数据中,Sj:5.1 Syj:3.2

损失值为0表示无损失,计算结果正确。

很明显,模型A只关注某一个数据,这样偏差太大,这是变异的
正则化惩罚项:由权重参数所带来的损失,蓝色方框为计算公式,λ表示惩罚系数,系数越大表示我不要那些变异的;系数越小表示变异的数据我也能接受。

不希望模型复杂的原因:
神经网络的优点在于能解决的问题多,缺点也在于它过于强大了。
过拟合是指模型在训练数据上表现很好,但在未见过的测试数据上表现较差的情况。
如何分类呢?

回归任务是由得分值去计算损失,分类任务由概率值计算损失
以上计算过程都是前向传播。反向传播是说得到的损失大的W该如何调整呢?(为了能让损失下降,即优化的过程)