本期教程教大家训练自己的知识库回答chatgpt回答不了的问题
FastGPT 是一个知识库问答系统,可以通过调用大模型和知识库回答特定的问题
- 可以做成专属 AI 客服集成到现有的APP或者网站内当作智能客服
- 支持网络爬虫学习互联网上的很多知识
- 可以通过flow可视化进行工作流程编排
本期教程主要内容
- 实现fastgpt对接oneapi接入多种大模型
- 实现fastgpt自定义大模型
- 实现添加m3e索引模型
- 实现自定义文本处理模型
- 实现在线更新fastgpt
- 不需要以上5条功能可以查看往期教程一键部署教程
- ⚠️注意遇到报错或者问题请查看最后面的避坑指南或许能找到答案
推荐使用浪浪云服务器,省心 省时 省力安全稳定 教程全面且详细
需要采用一键部署的系统
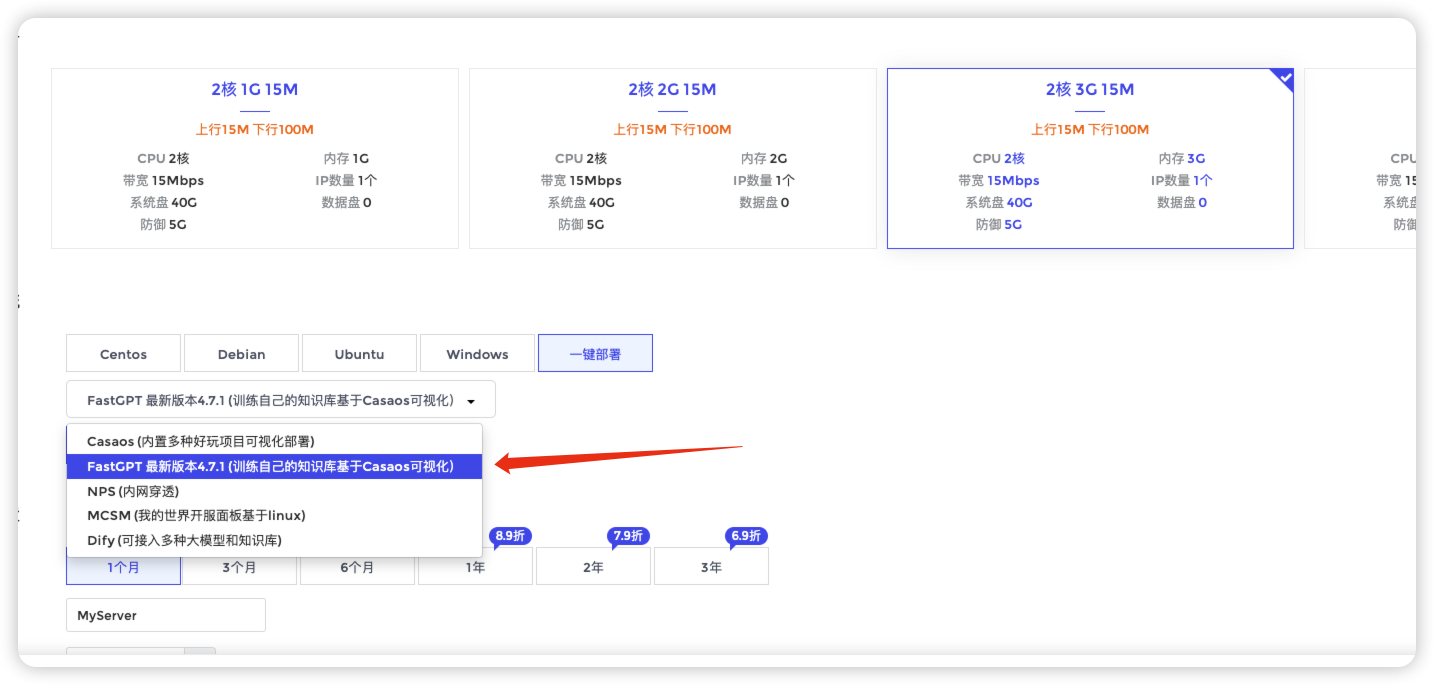
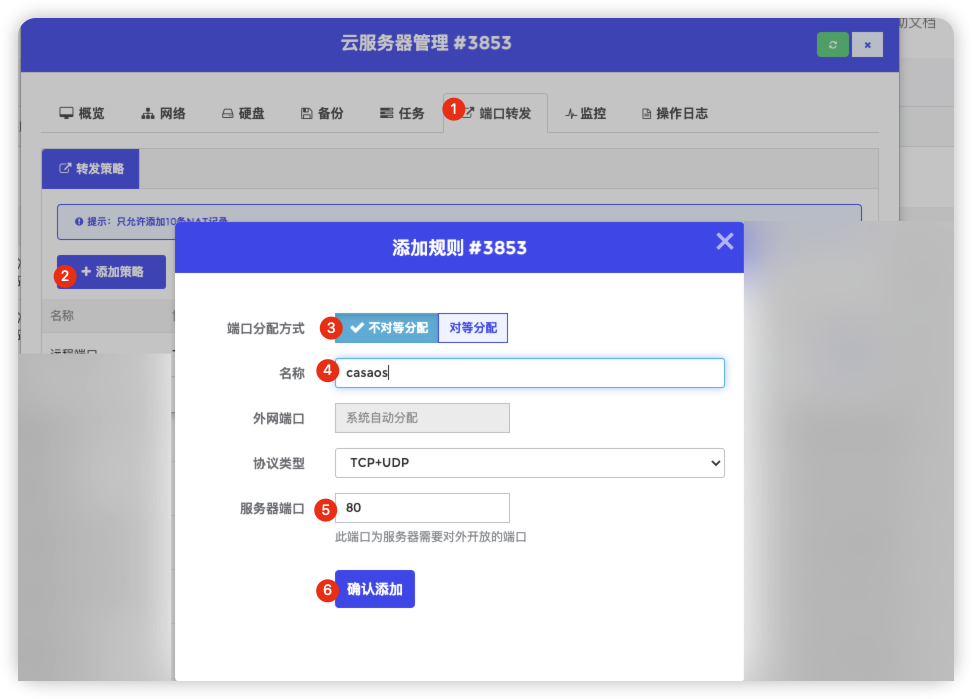
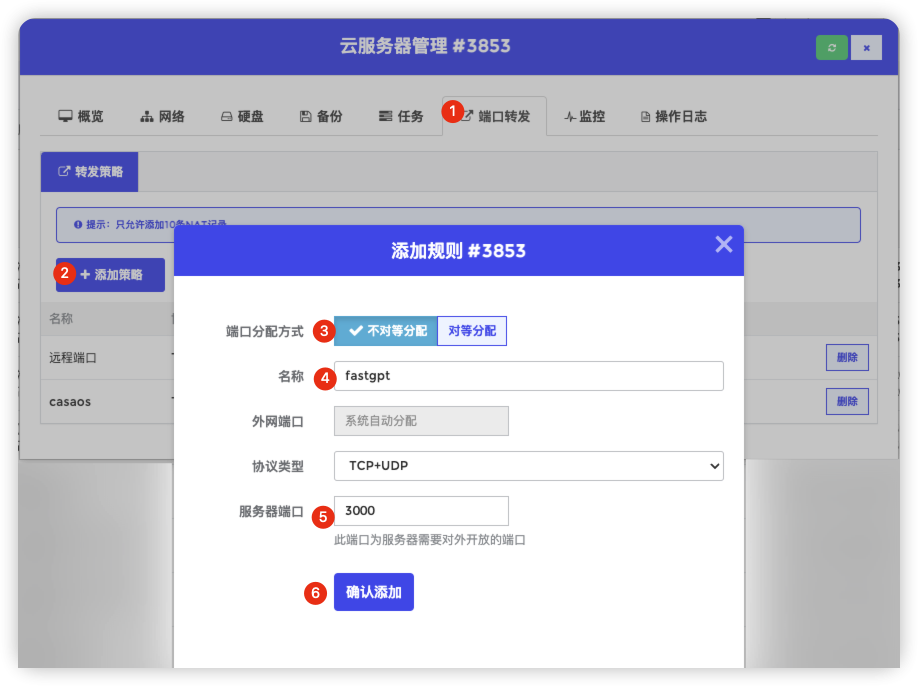
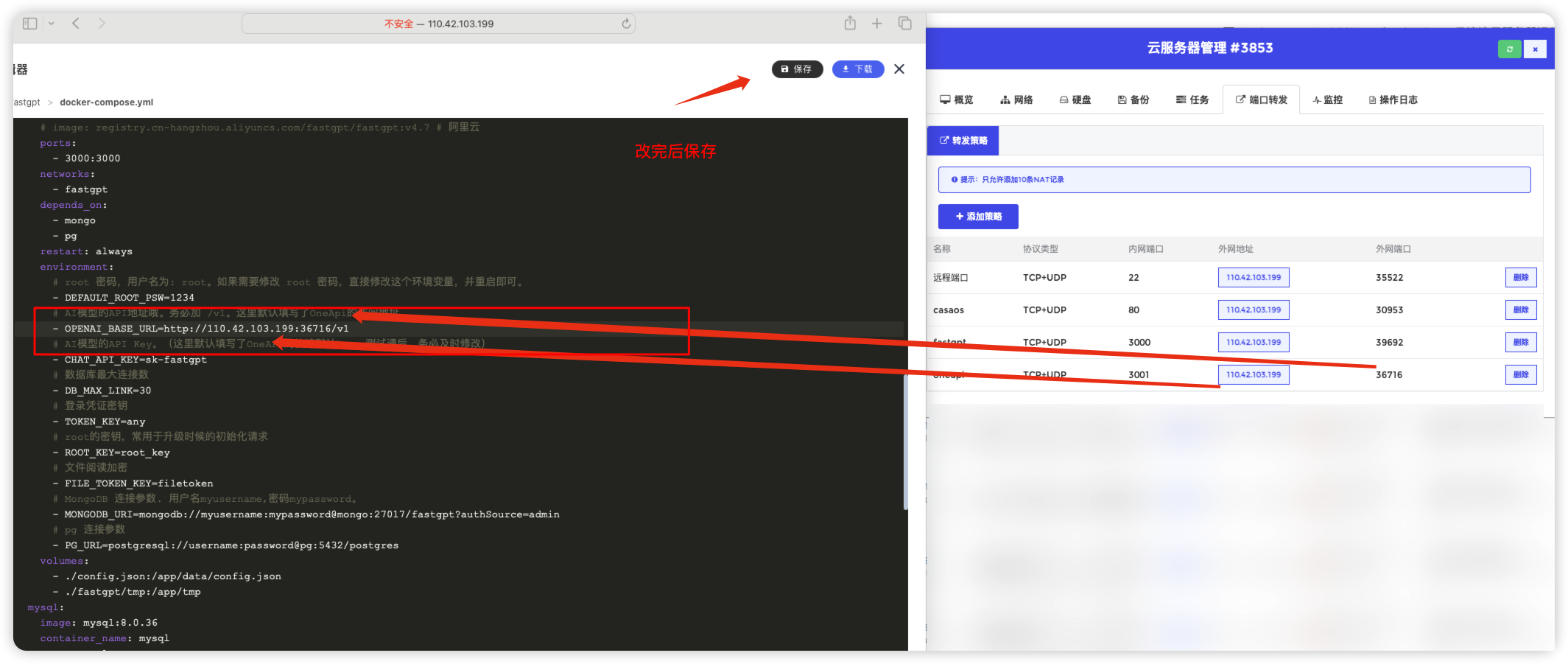
添加端口转发
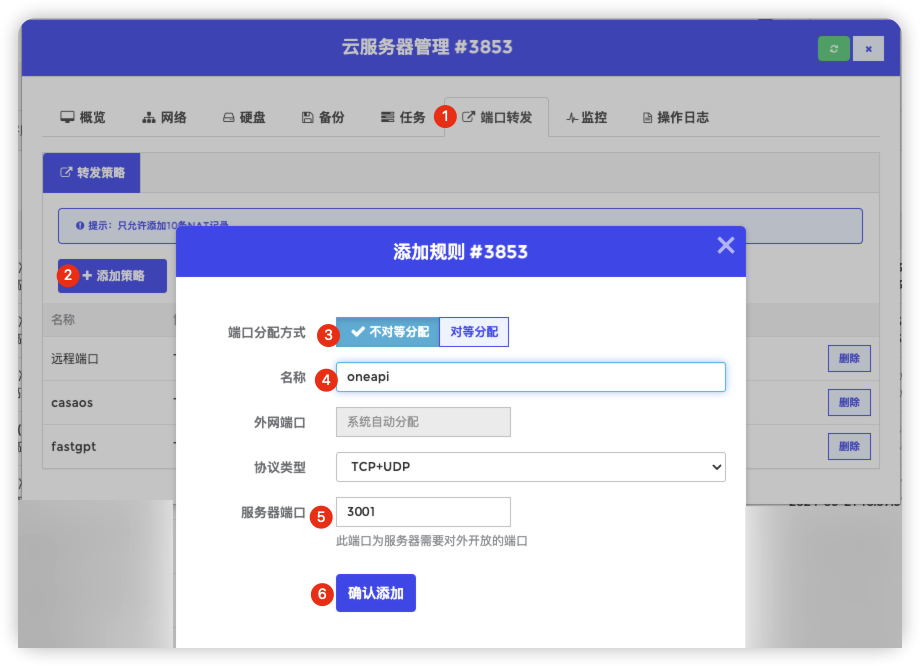
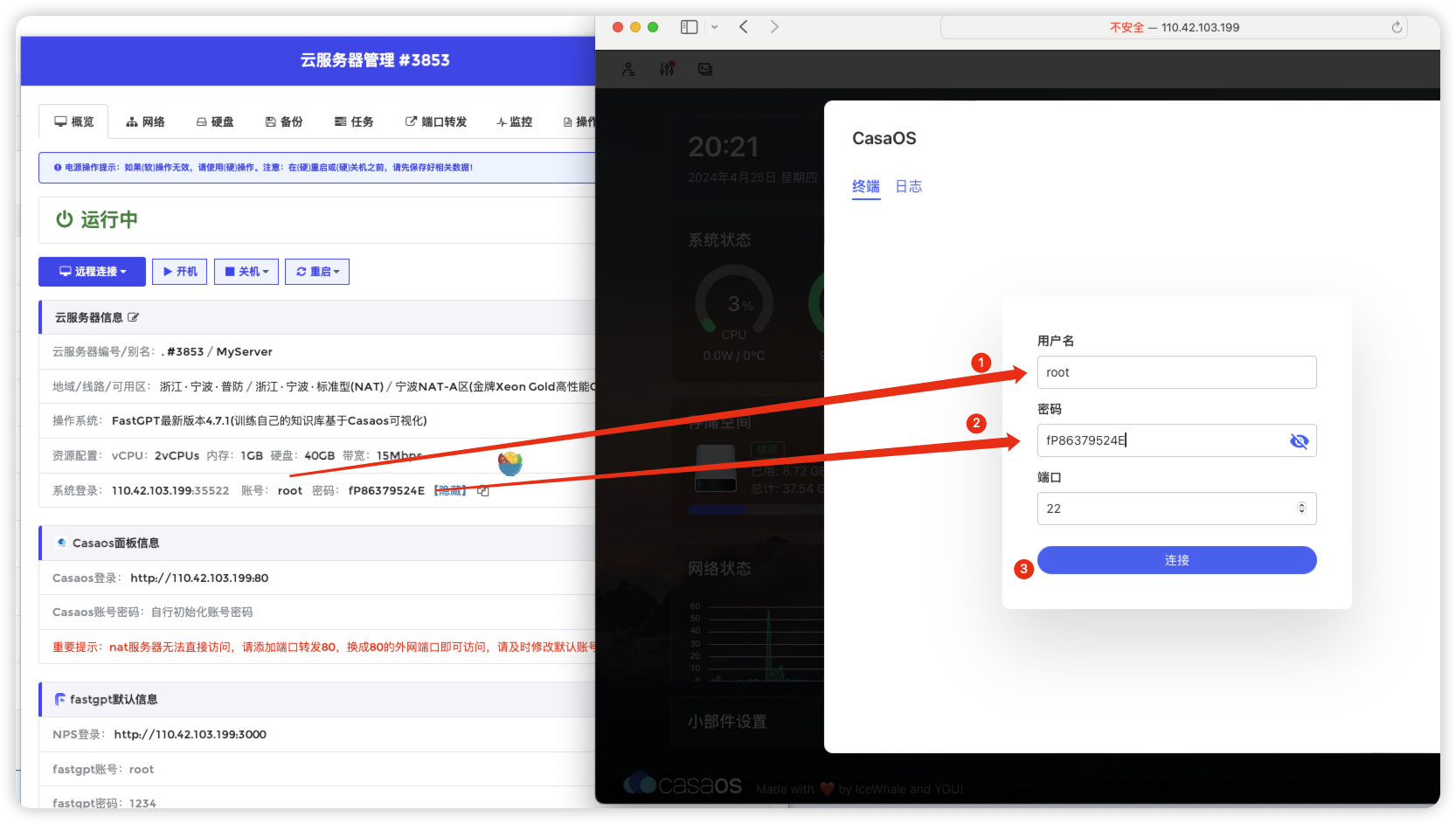
登录casaos
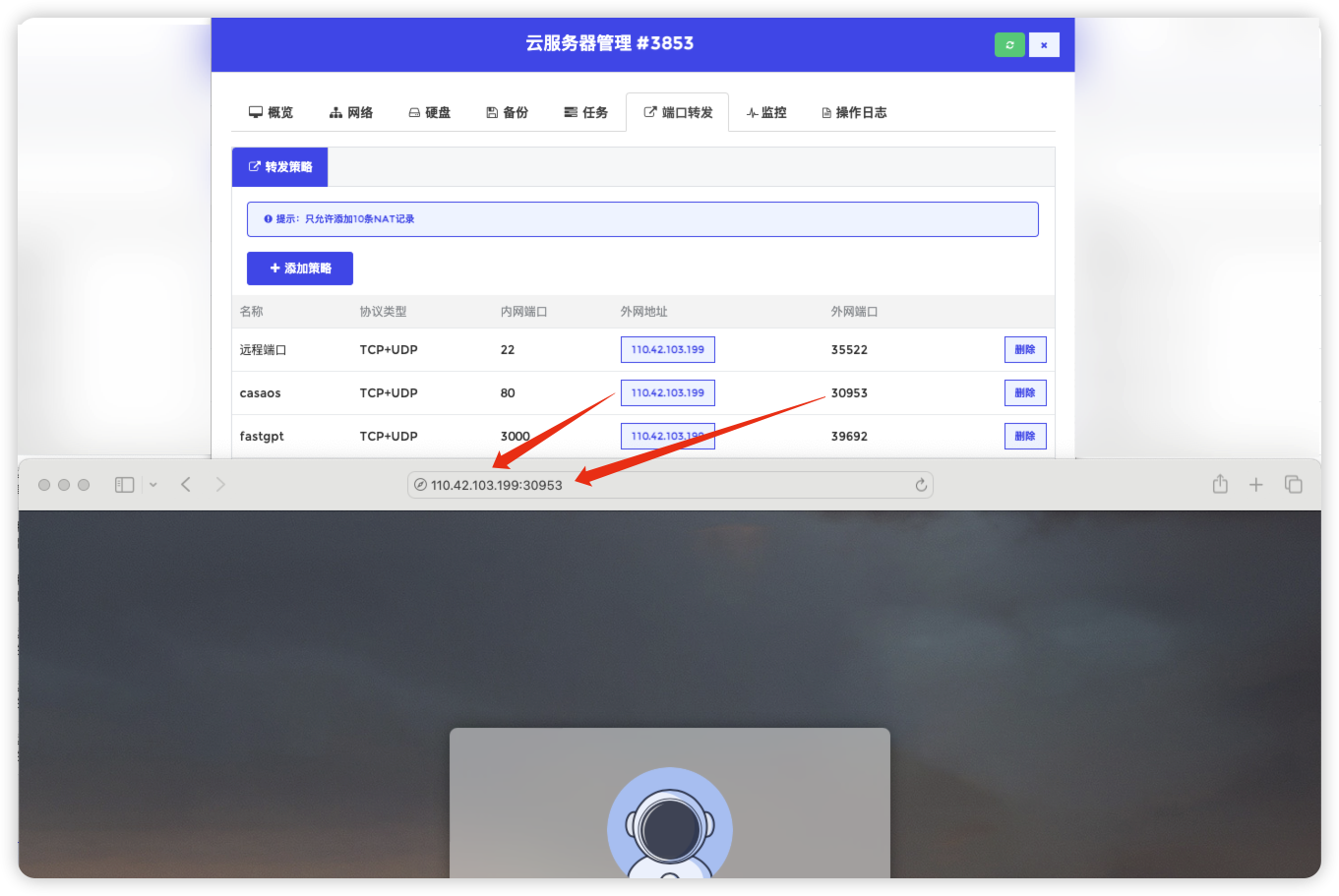
登录fastgpt
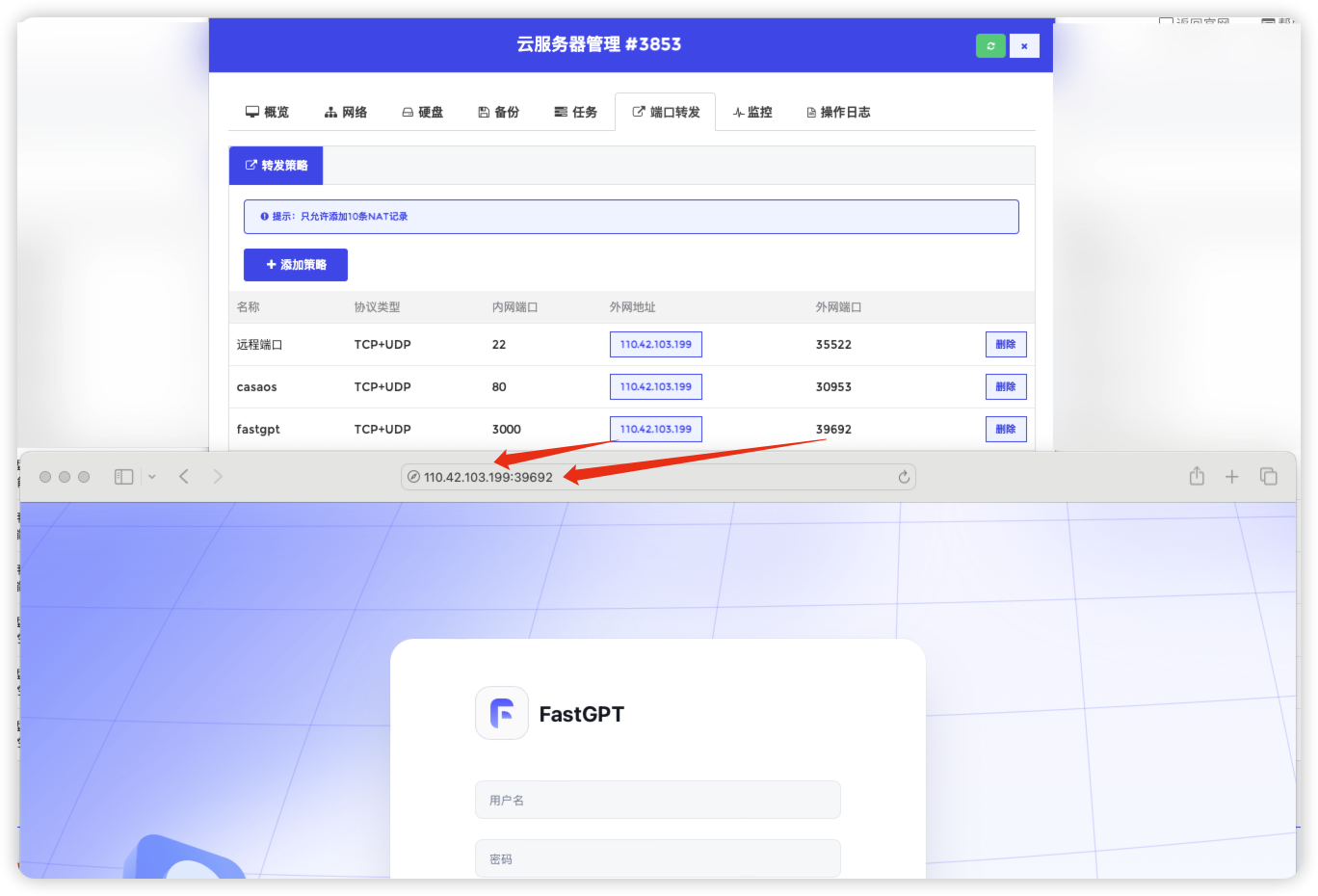
浏览器登录oneapi
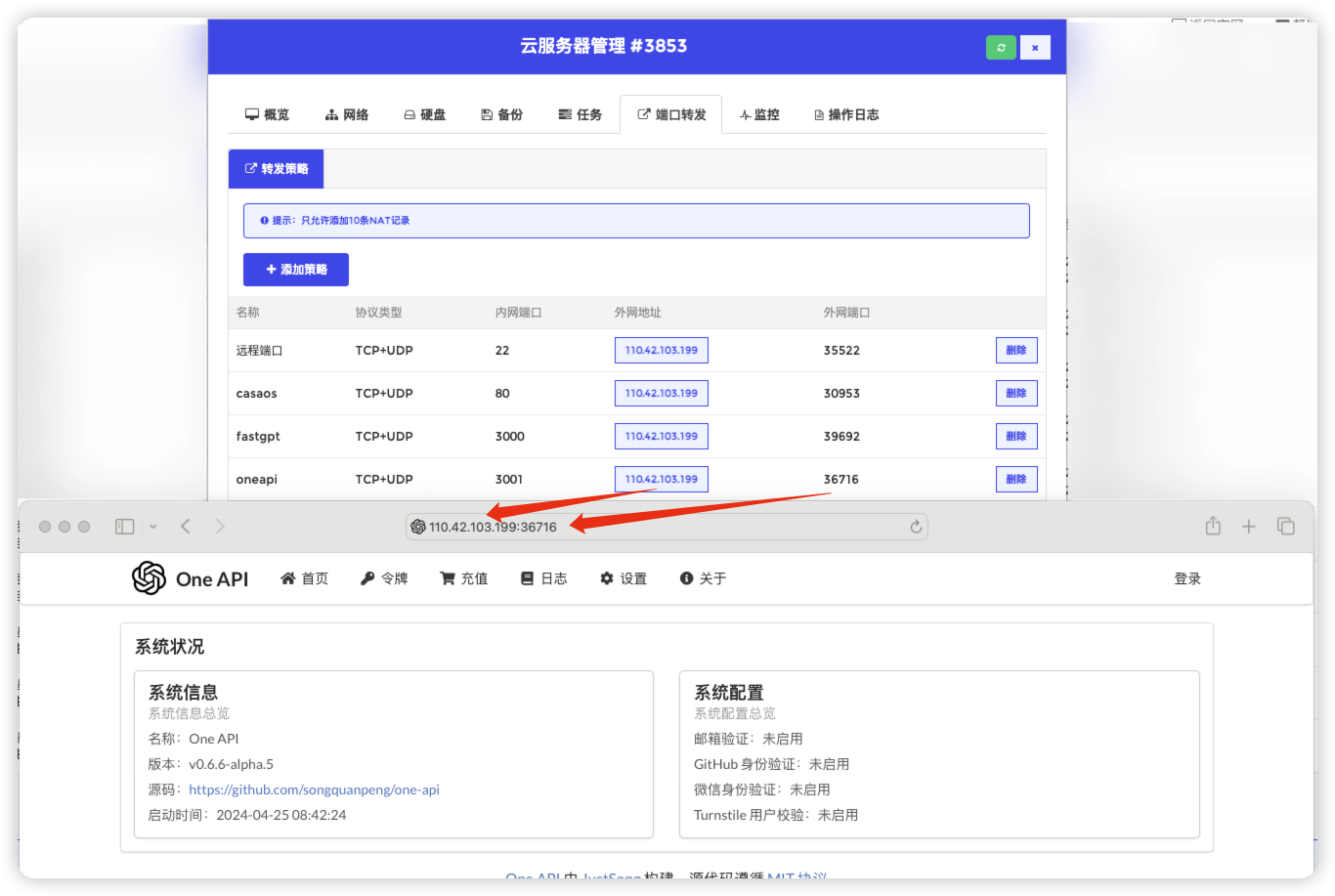
fastgpt如何对接oneapi
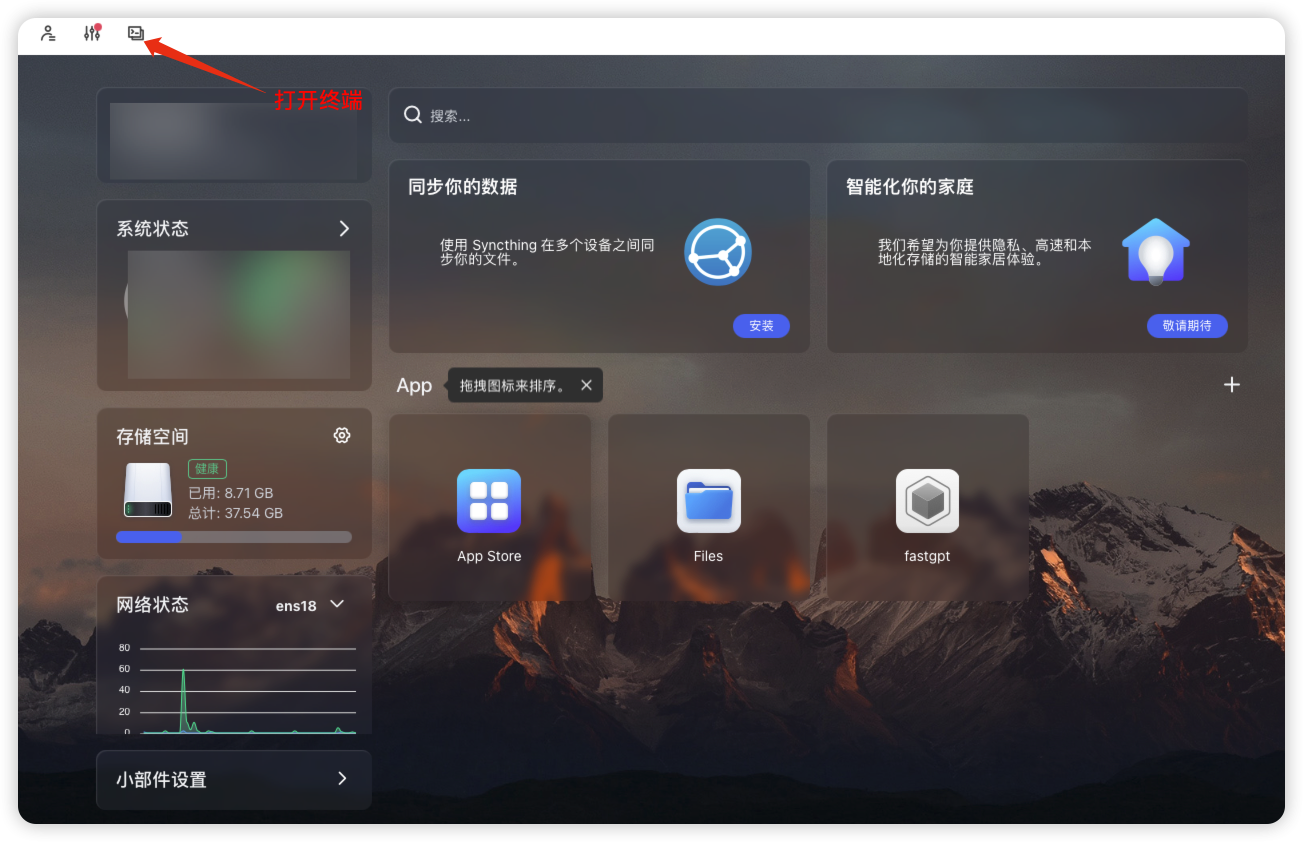
打开files
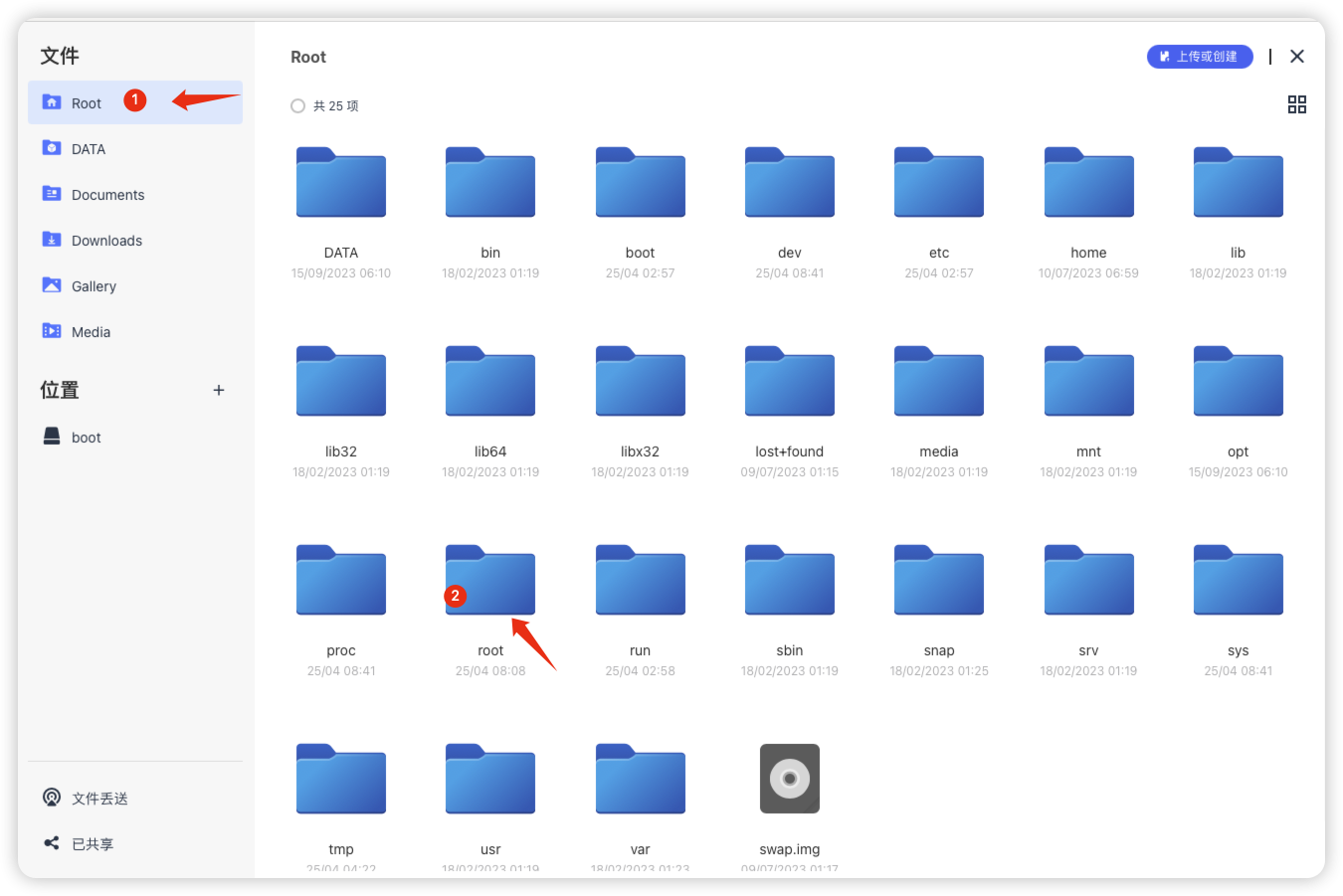
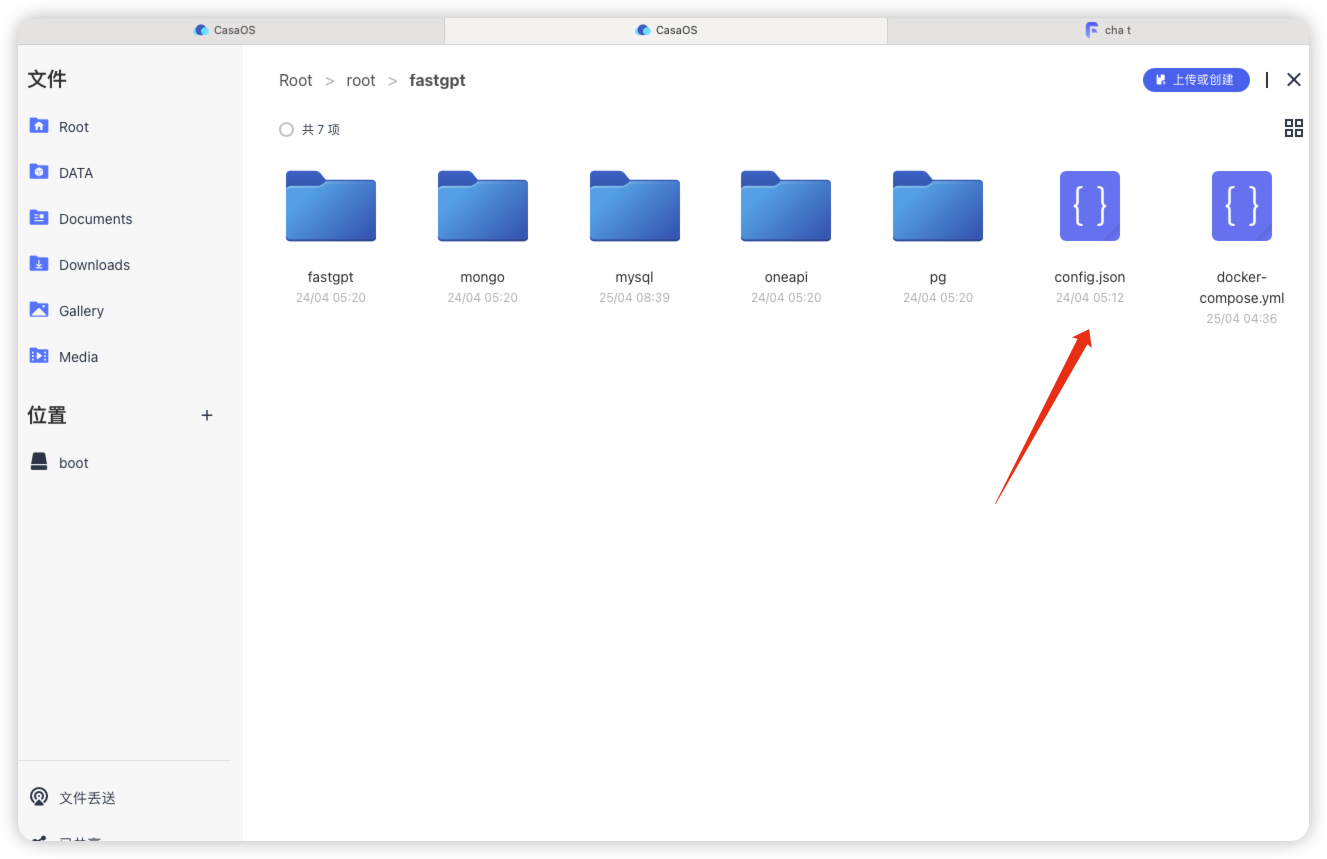
进入fastgpt文件下
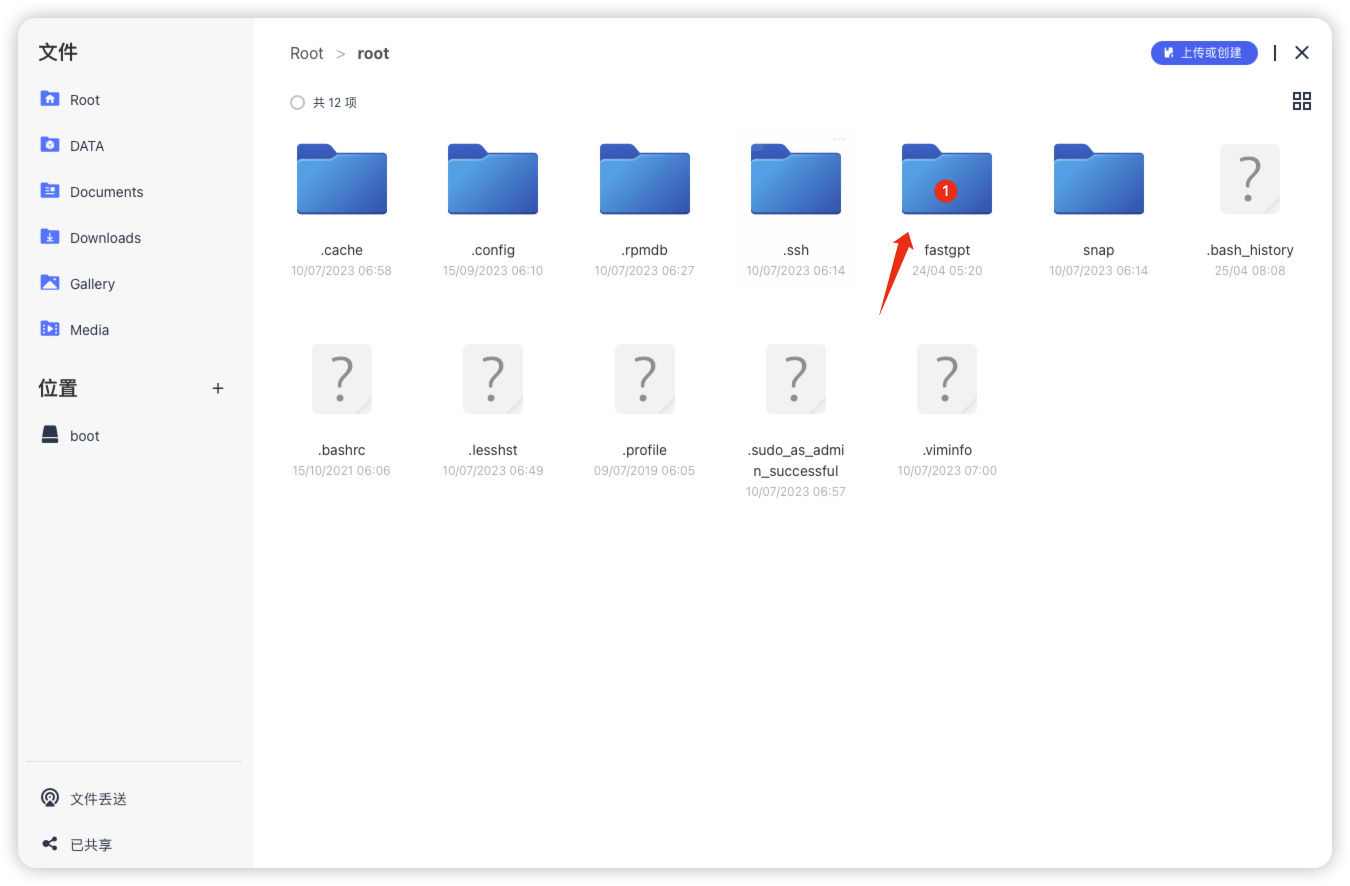
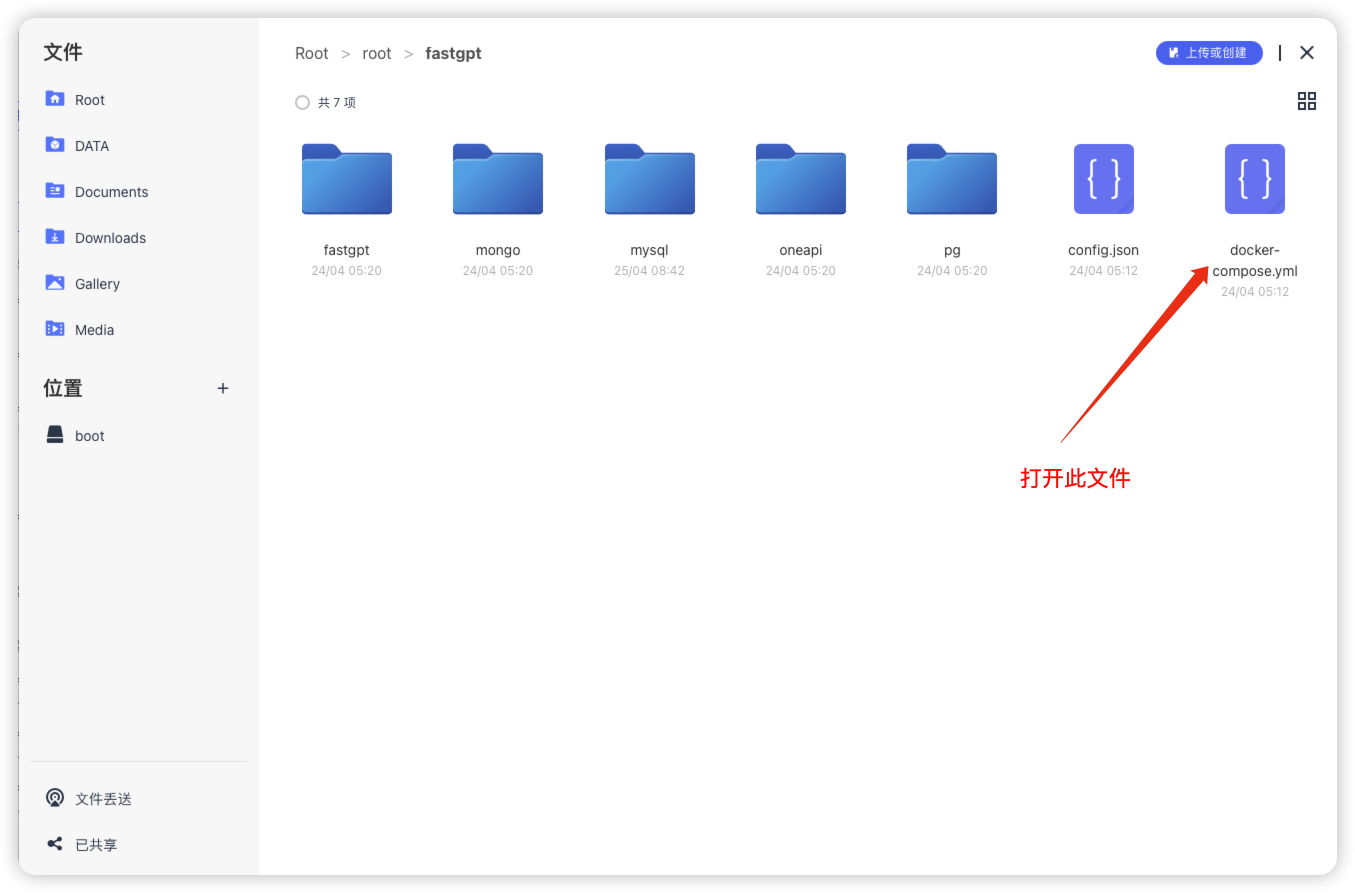
编辑docker-compose.yaml文件
修改配置文件
修改前
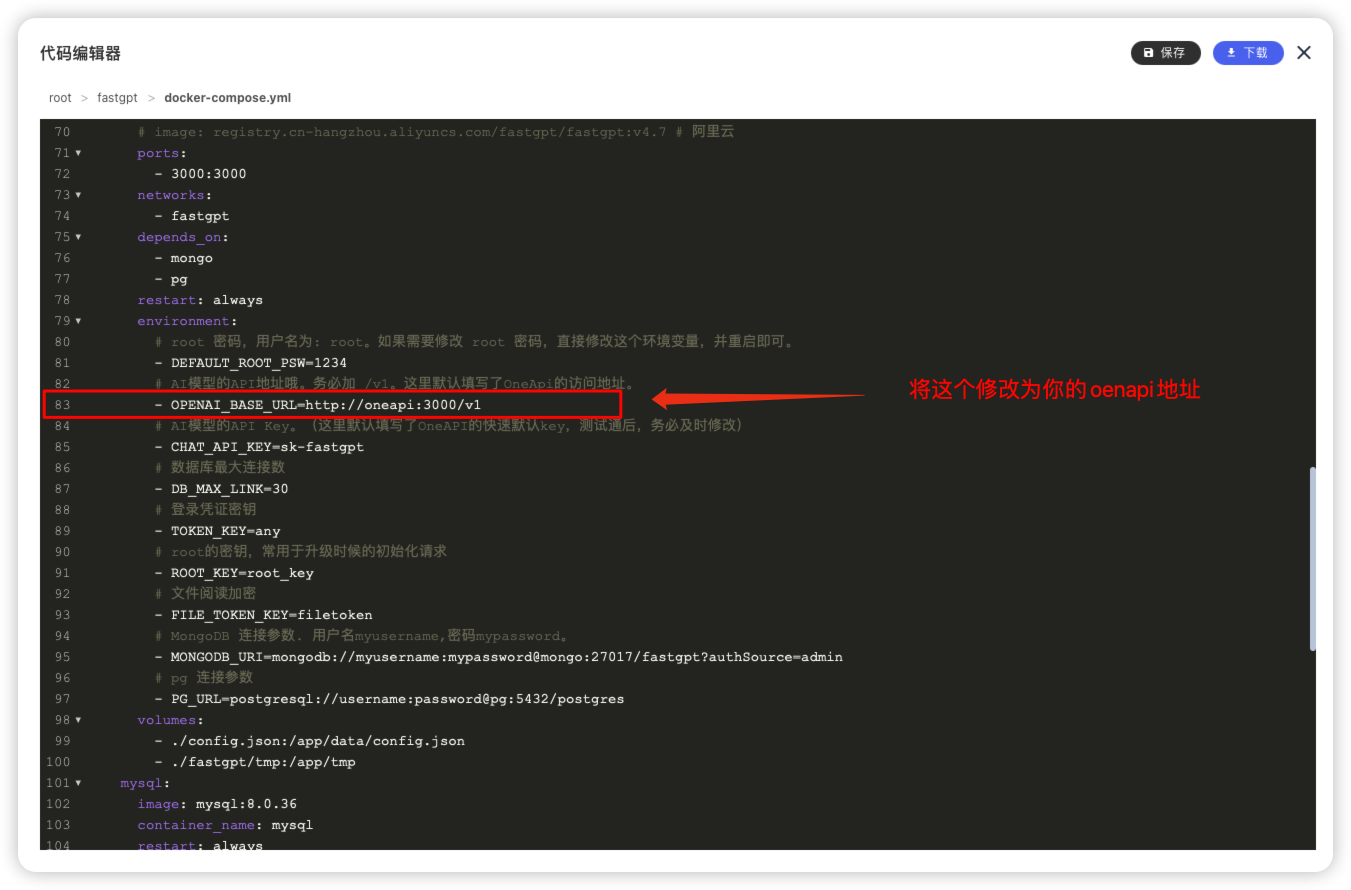
修改后
打开终端
登录终端
进入fastgpt文件夹下
cd fastgpt
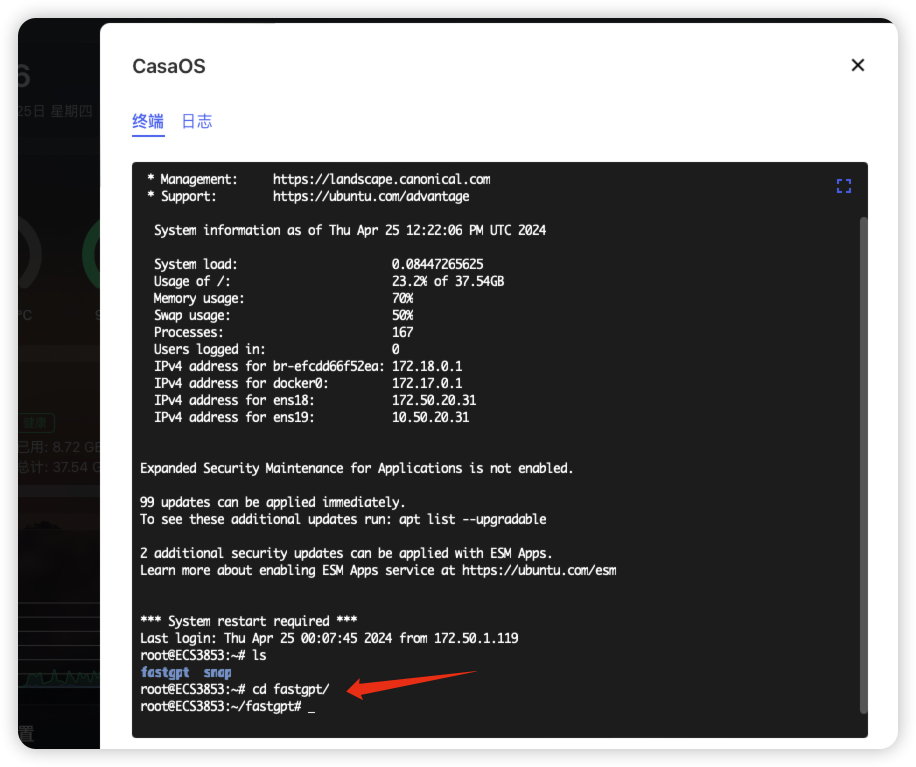
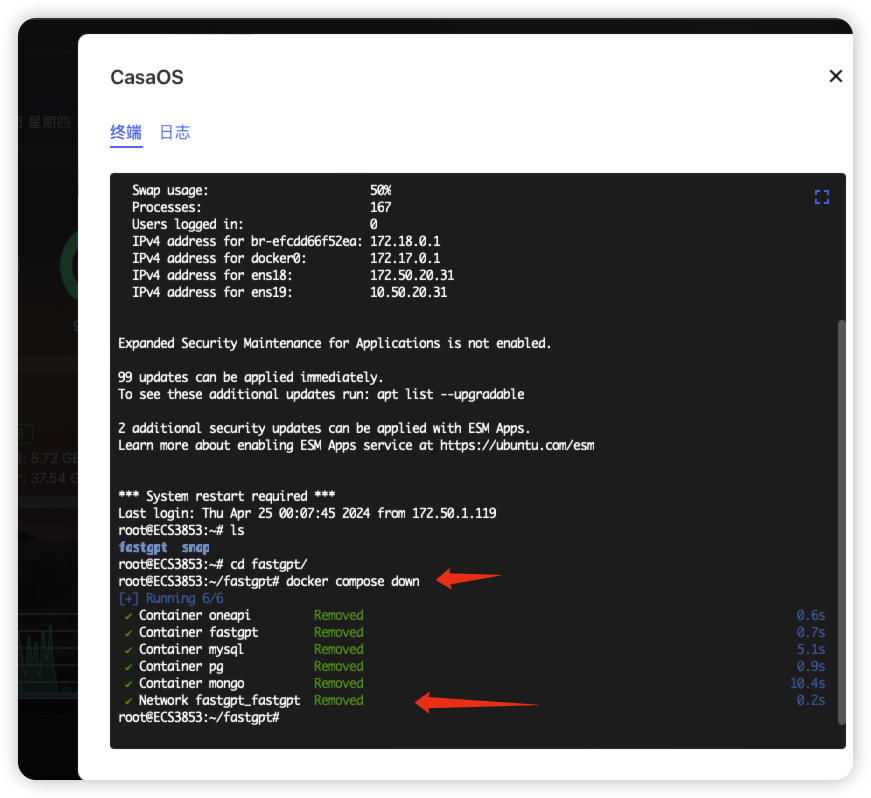
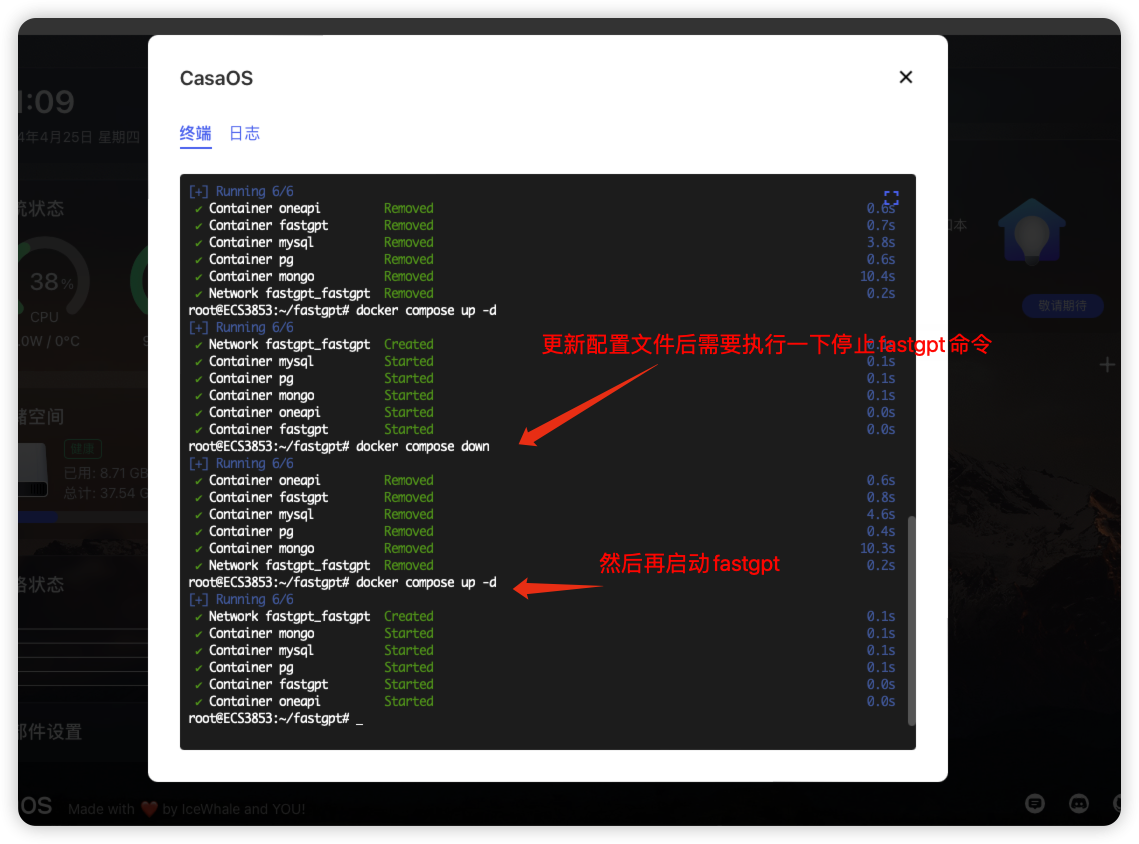
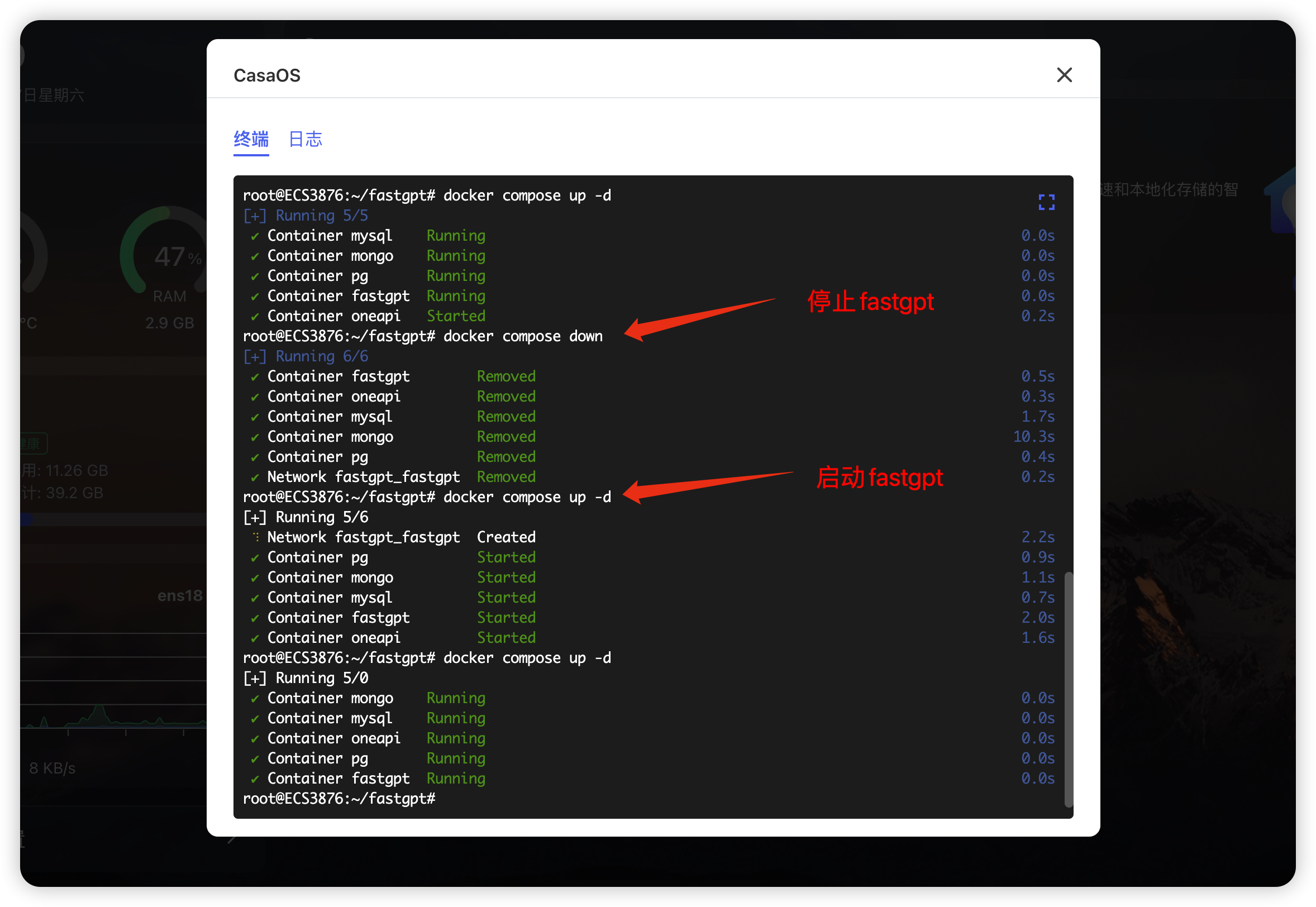
停止运行fastgpt
docker compose down
启动fastgpt
docker compose up -d
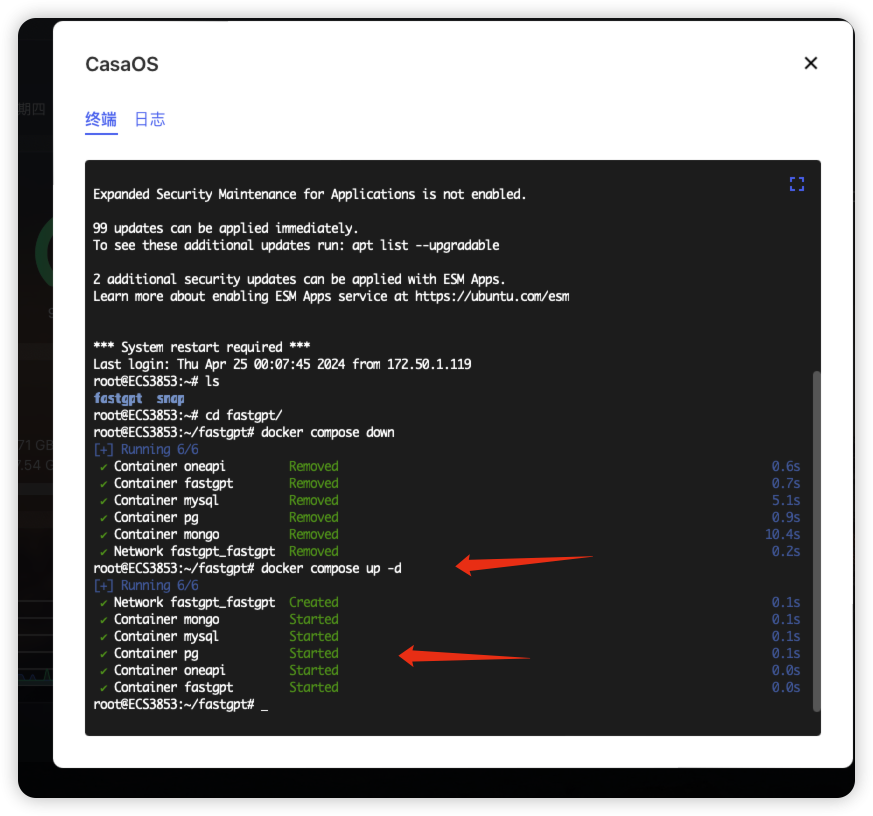
此时fastgpt已经对接到oneapi上了
oneapi对接chatgpt或其他大模型
本次演示对接xi的中转api
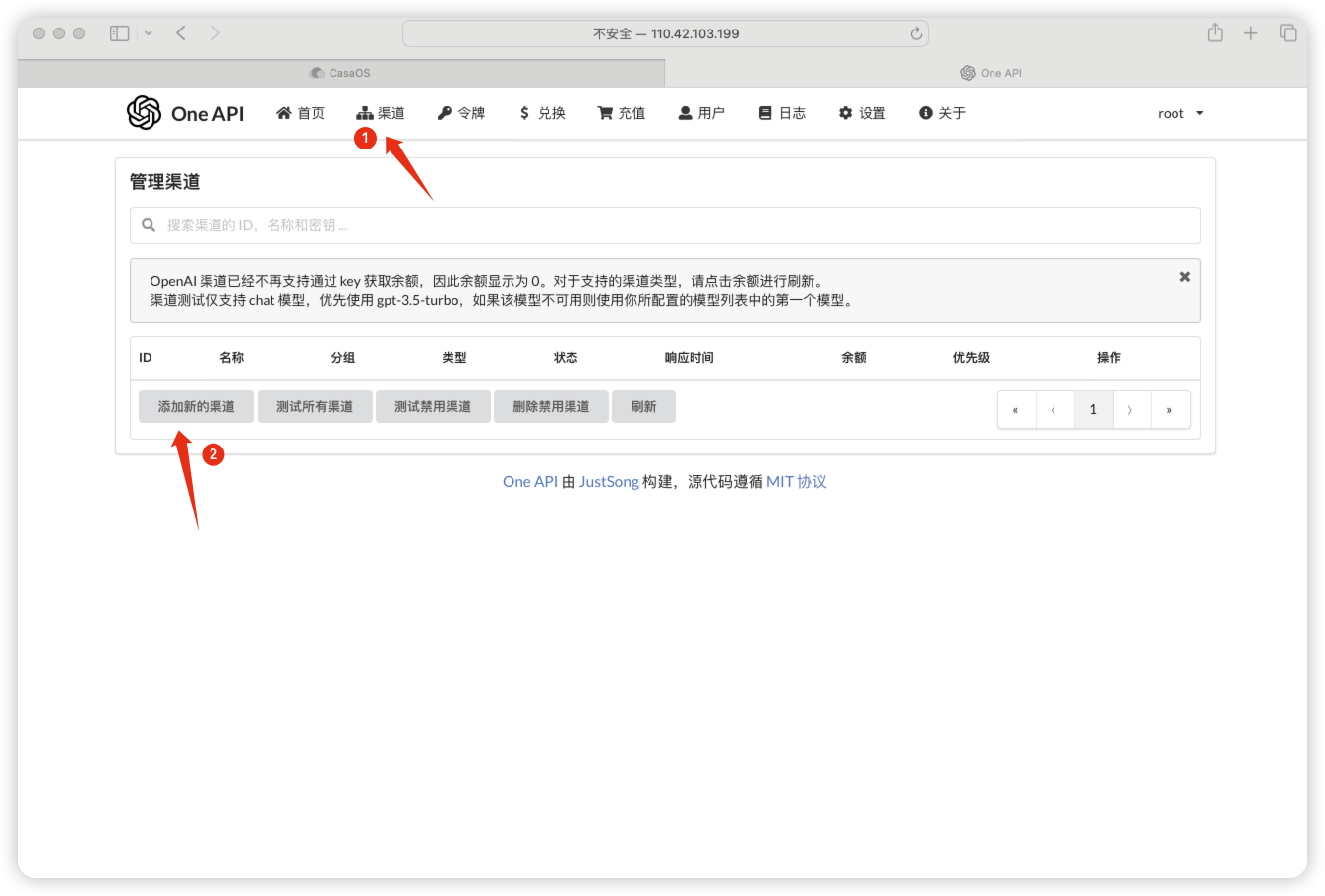
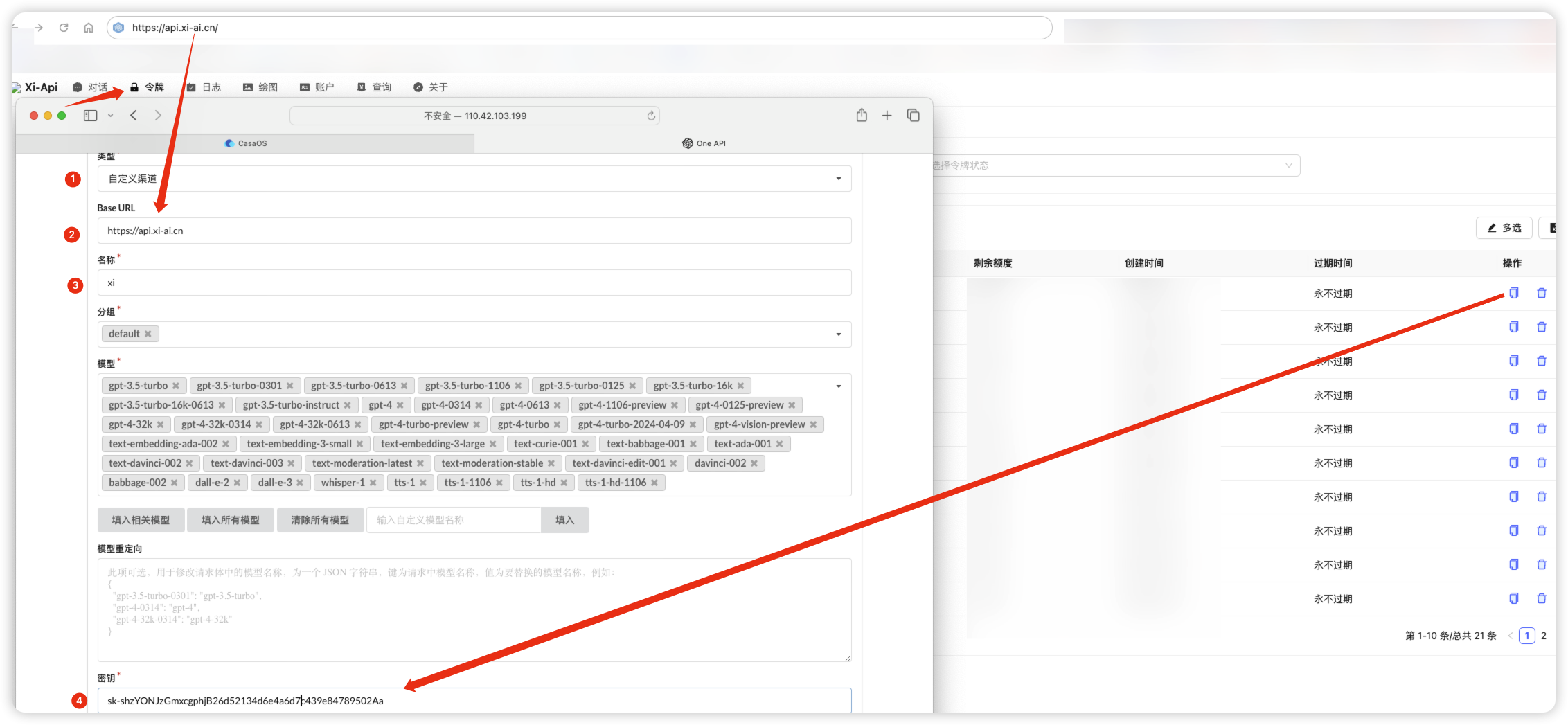
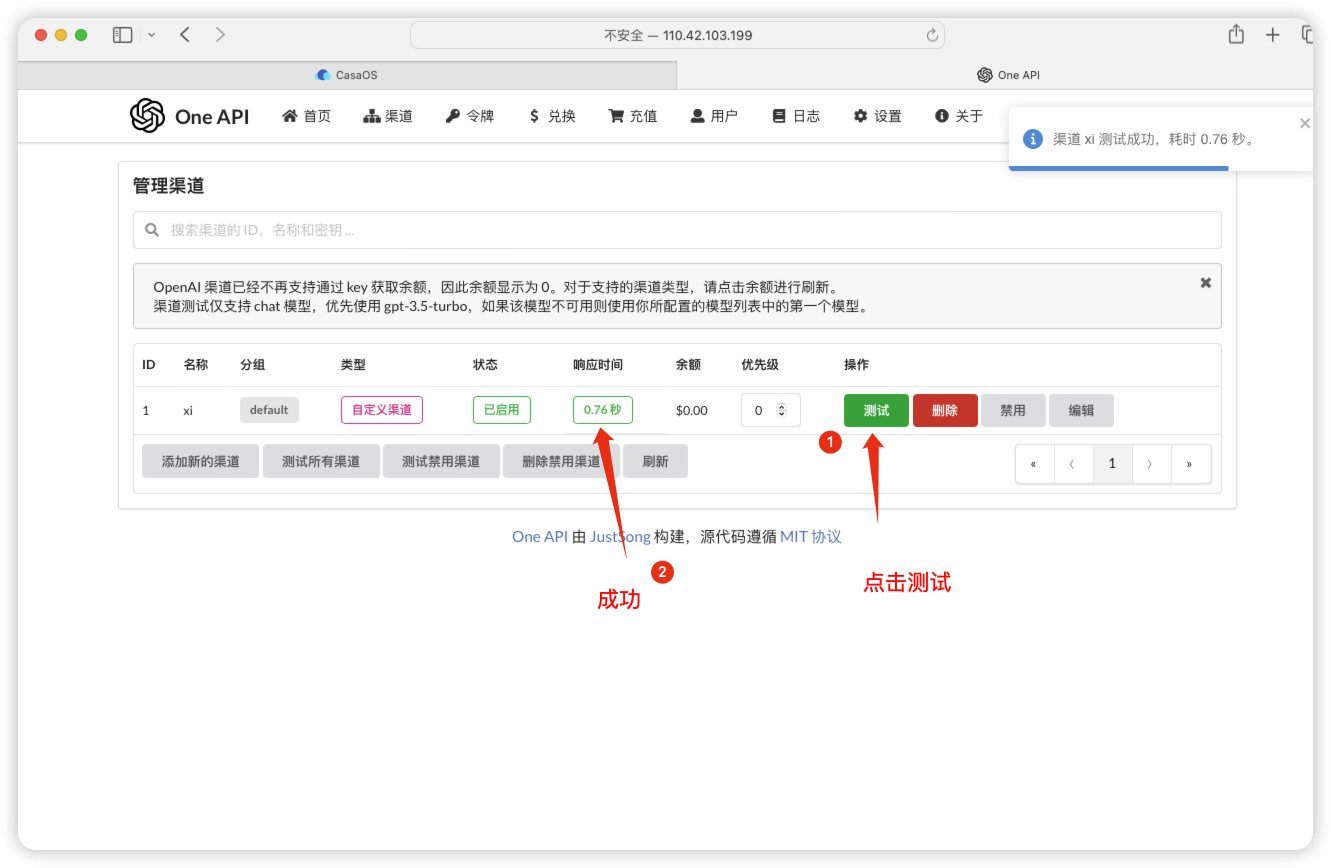
登录fastgpt看一下能否使用
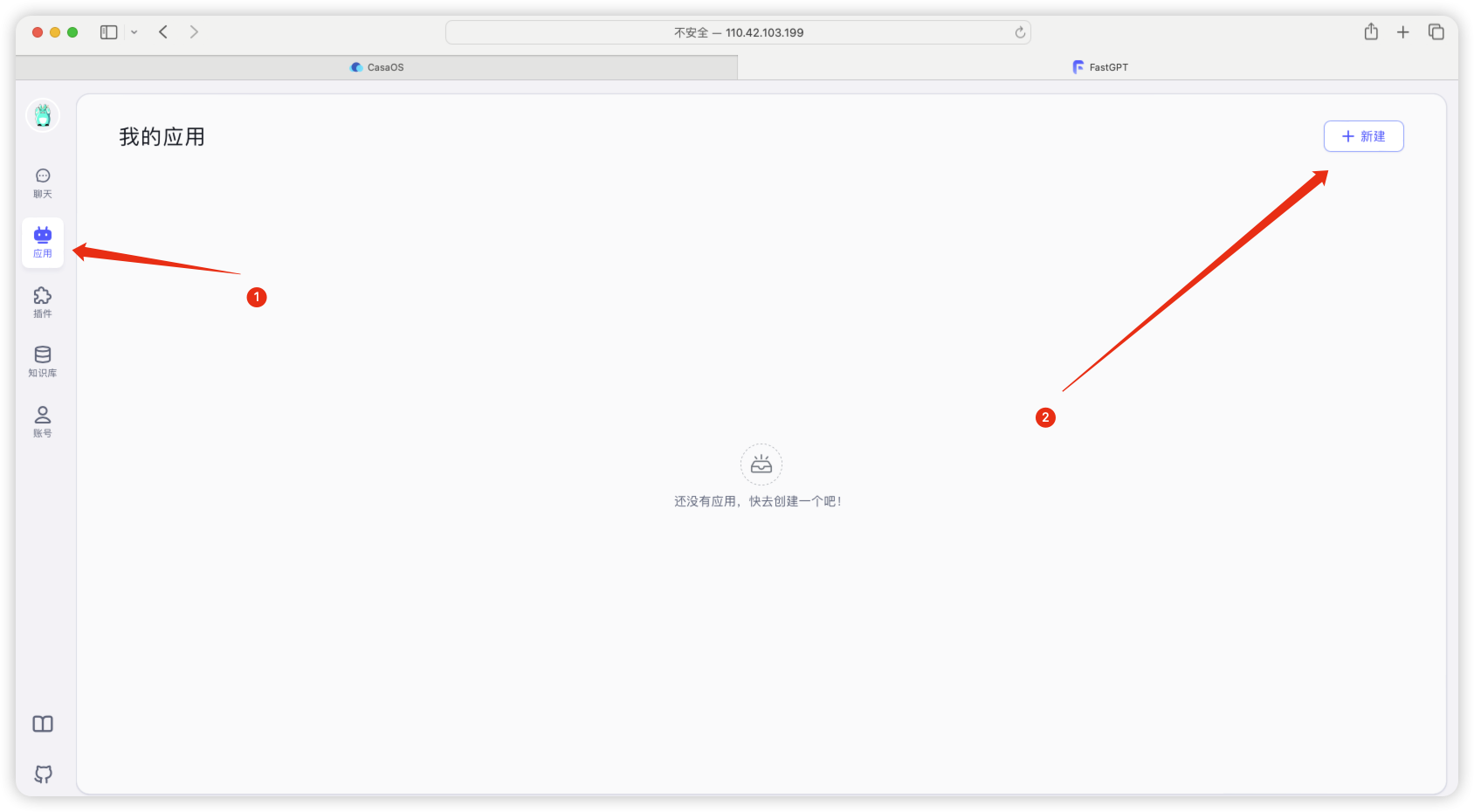
可以看到已经可以对话了,如果不能对话报错,就去检查一下docker-compose编辑那部检查一下时候填对了,填写没有问题就执行一下 停止fastgpt和启动fastgpt运行
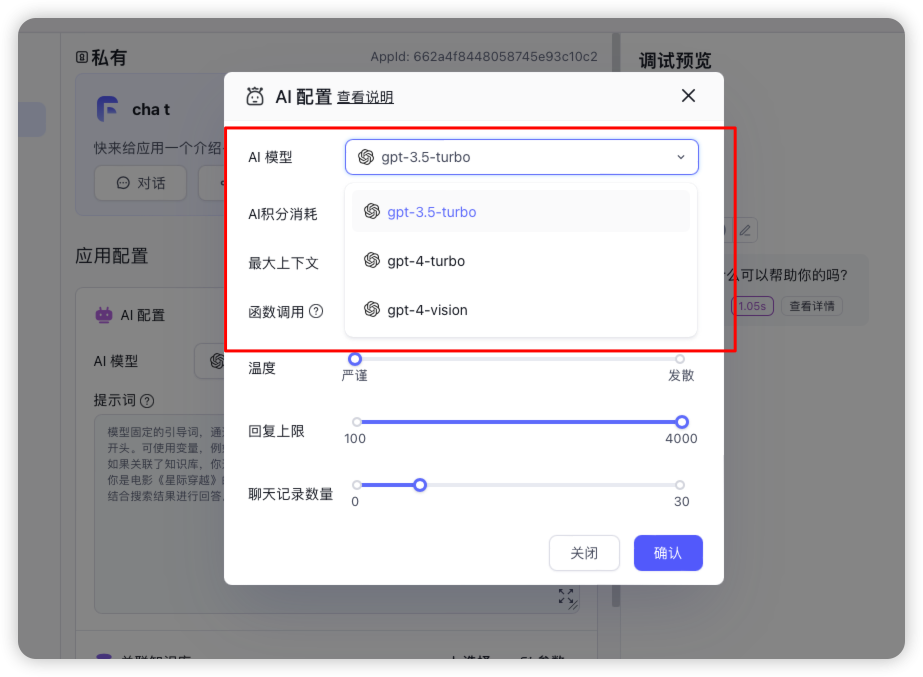
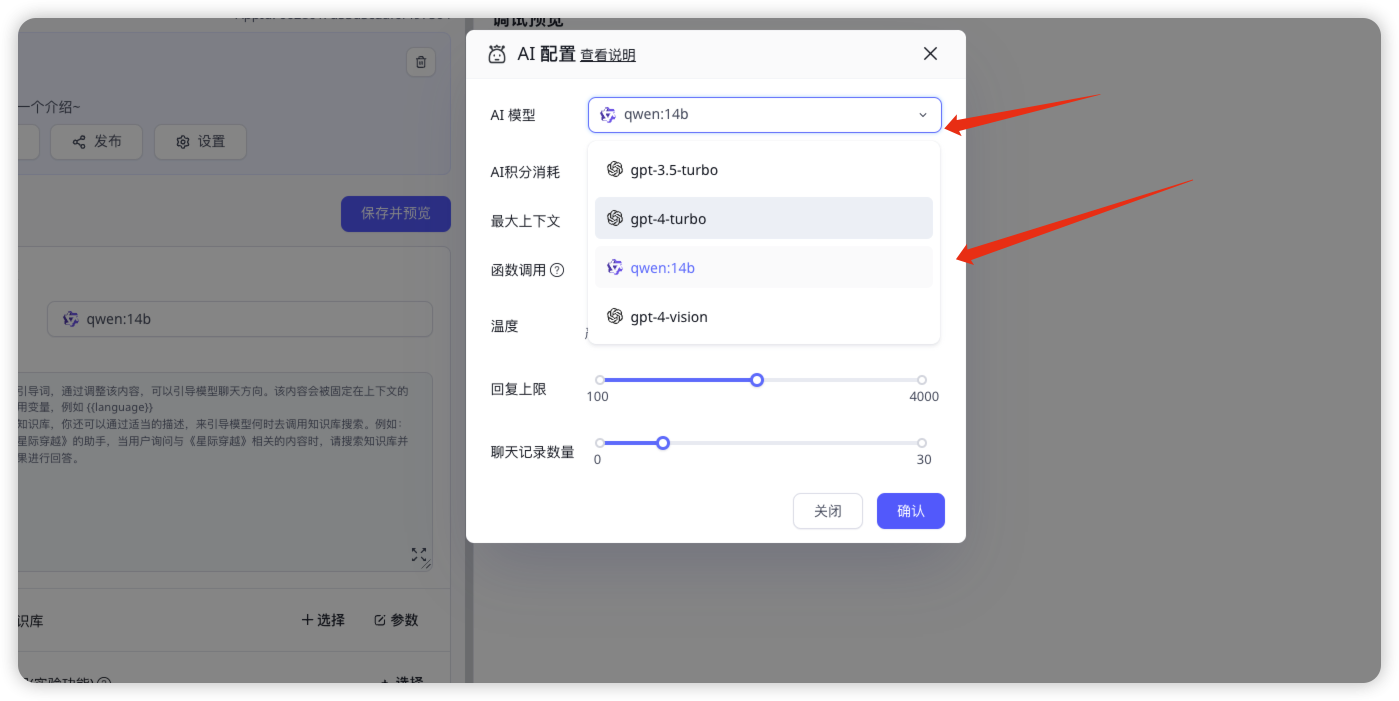
如何自定义添加大模型
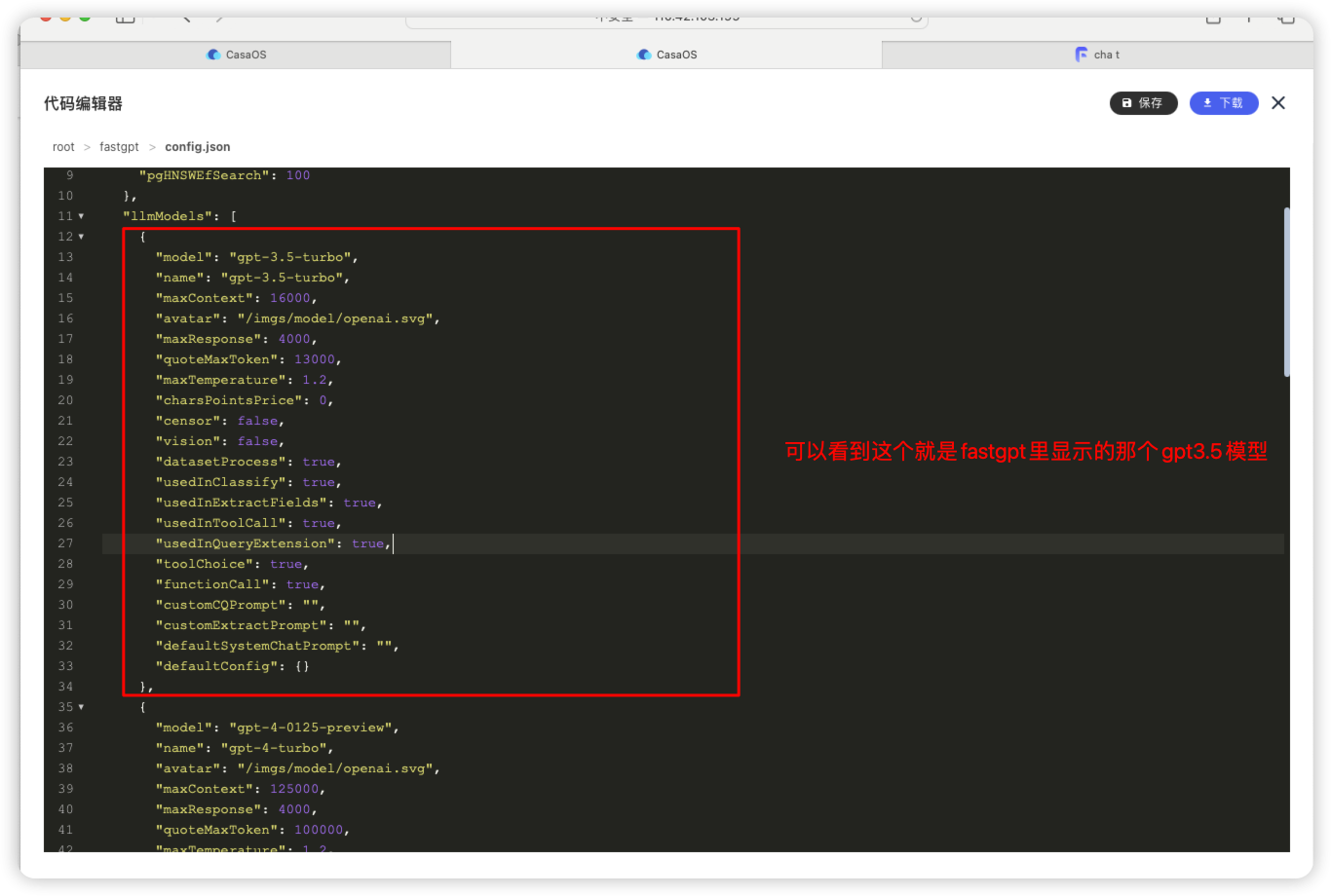
可以看到fastgpt里自带的模型只有3个,如何加入其他模型呢
编辑config.json
可以看到以下是相应的模型配置文件
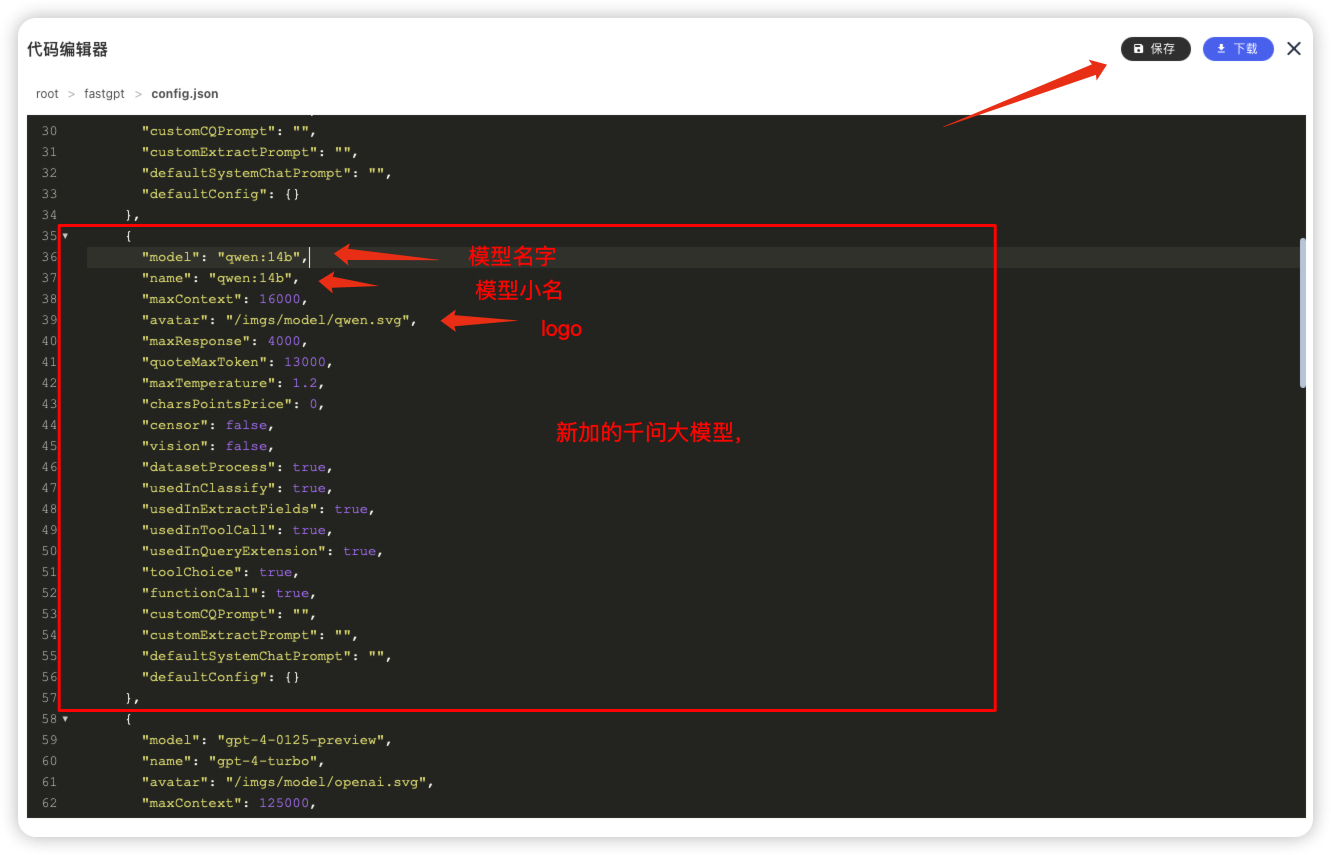
示例:添加千问大模型
{
"model": "gpt-3.5-turbo", // 模型名(对应OneAPI中渠道的模型名)
"name": "gpt-3.5-turbo", // 别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 16000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 13000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
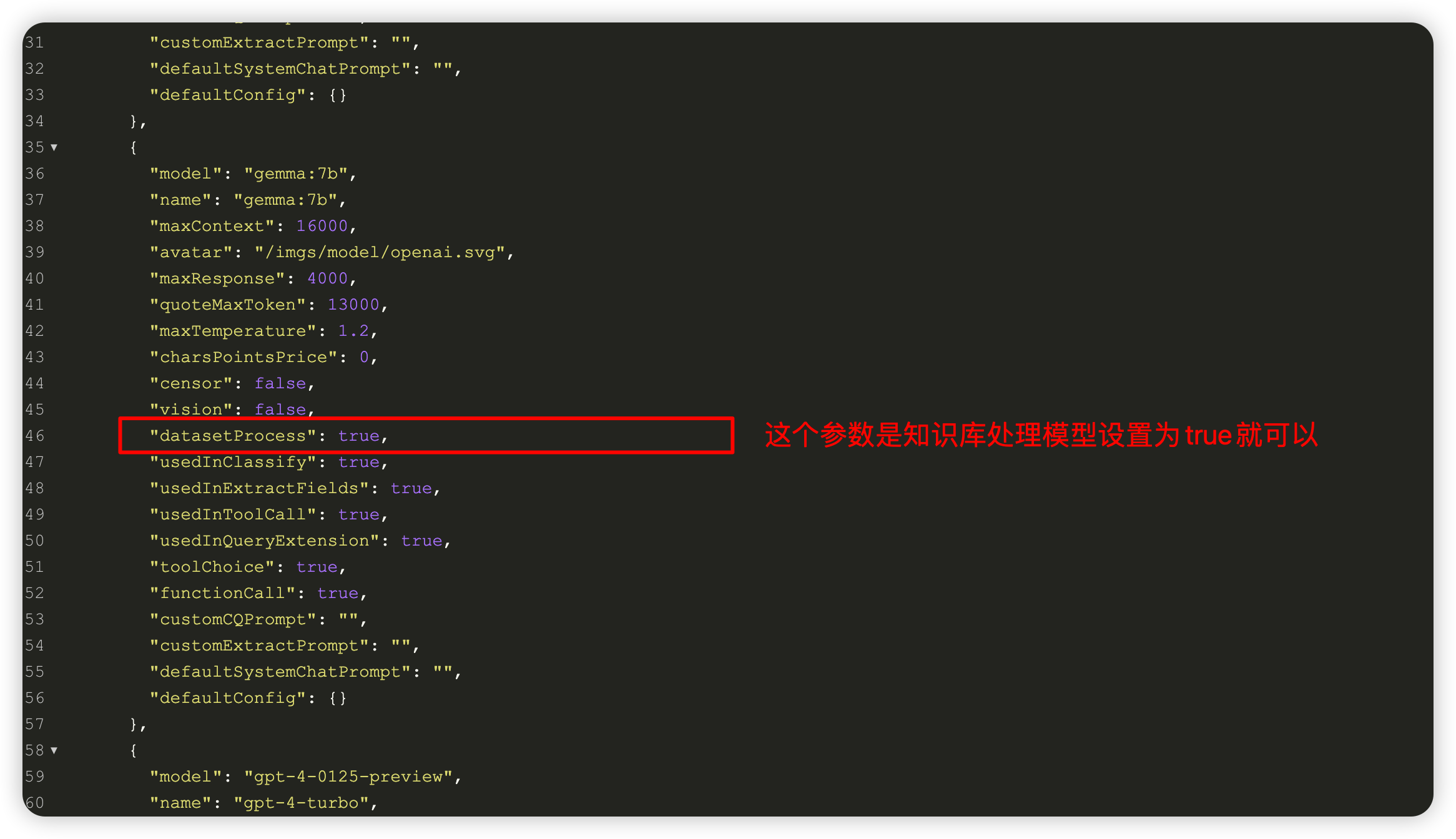
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true) "usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true) "usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true) "usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true) "toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持) "functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式) "customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型 "customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig":{} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
},
千问大模型
{
"model": "qwen:14b",
"name": "qwen:14b",
"maxContext": 16000,
"avatar": "/imgs/model/qwen.svg",
"maxResponse": 4000,
"quoteMaxToken": 13000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": false,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": true,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
},
重启一下fastgpt
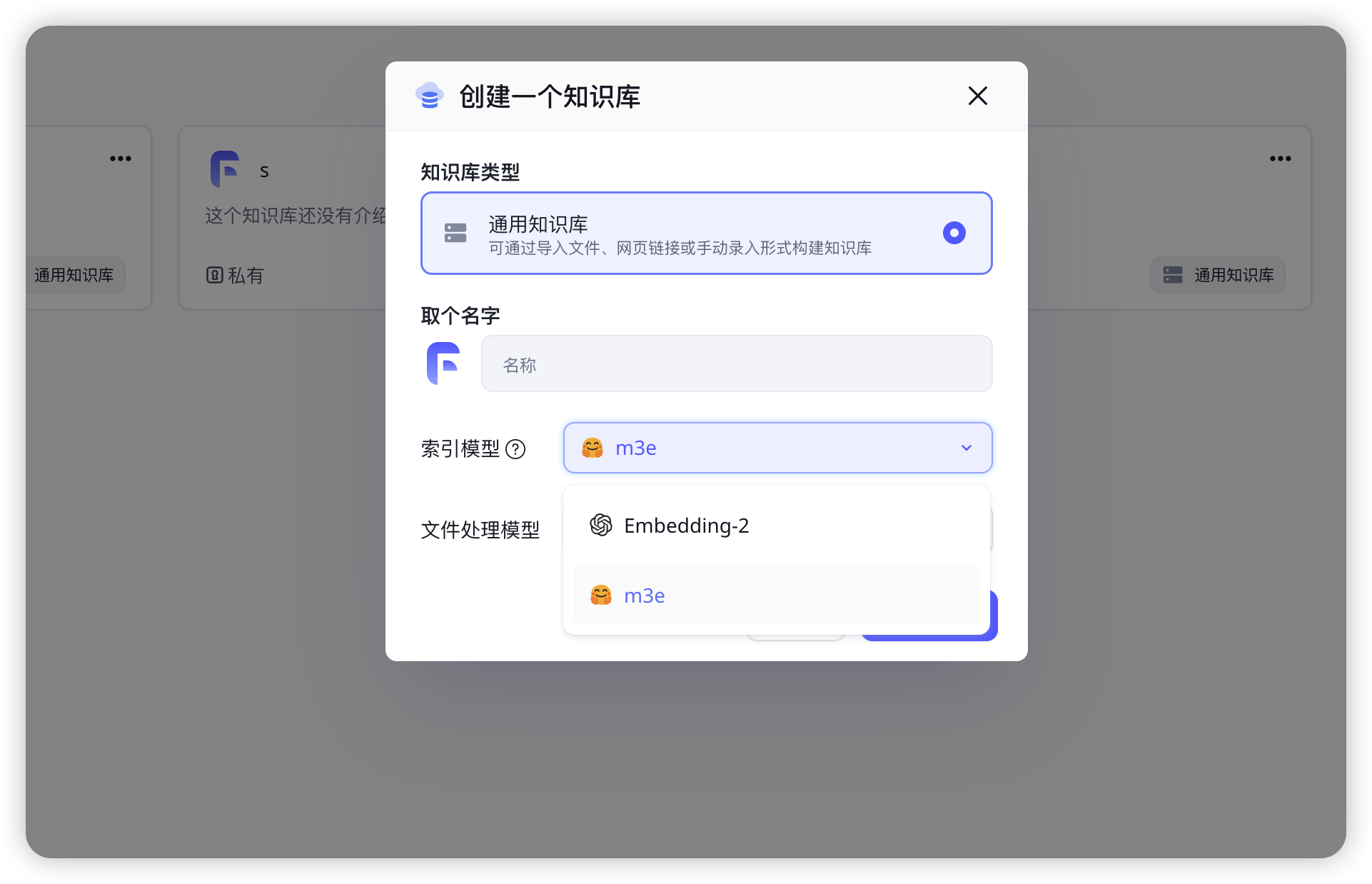
添加知识库m3e索引模型
fastgpt支持的索引模型有embedding和m3e,但是自带的只有emnedding,如何添加m3e索引模型
编辑这个config.json文件
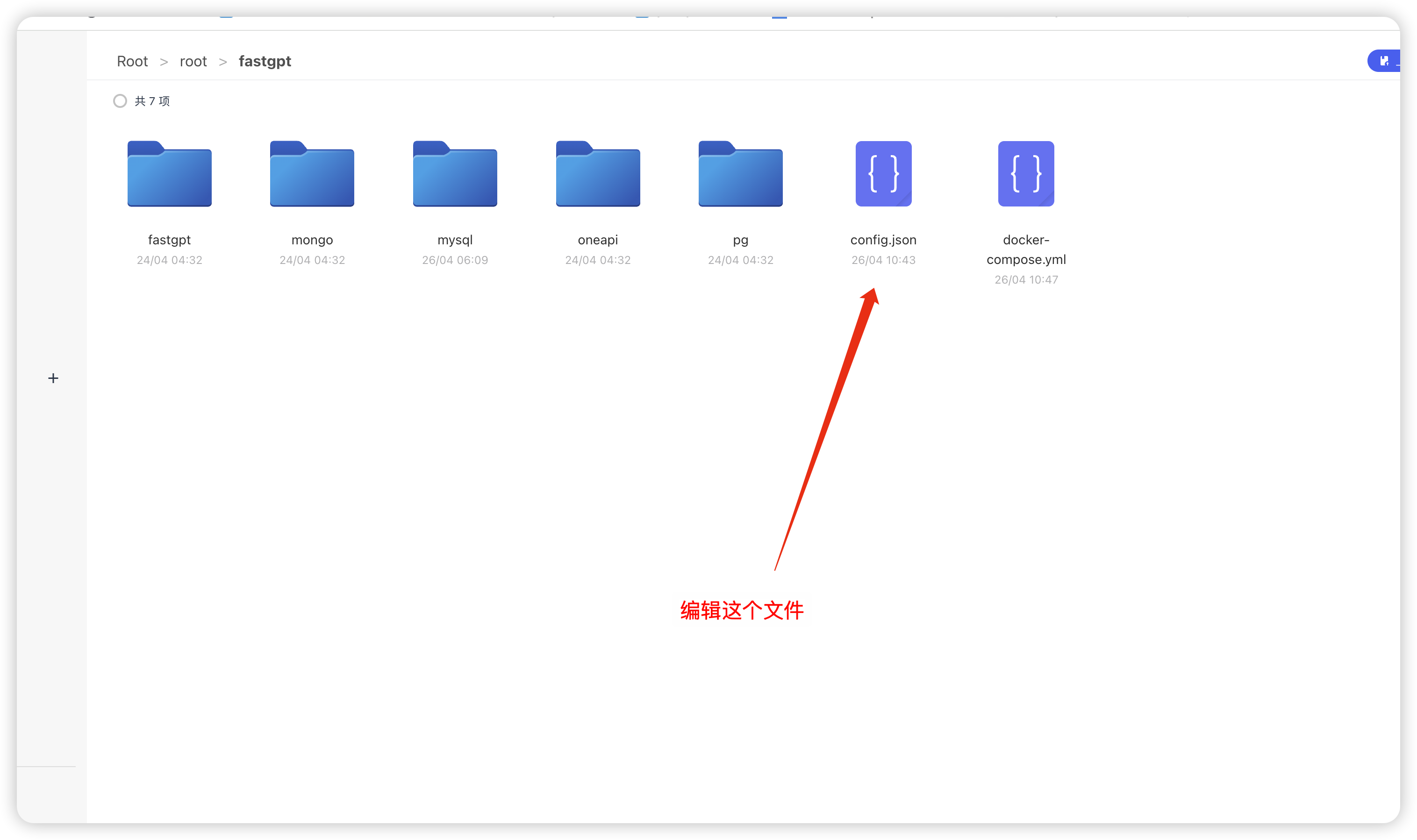
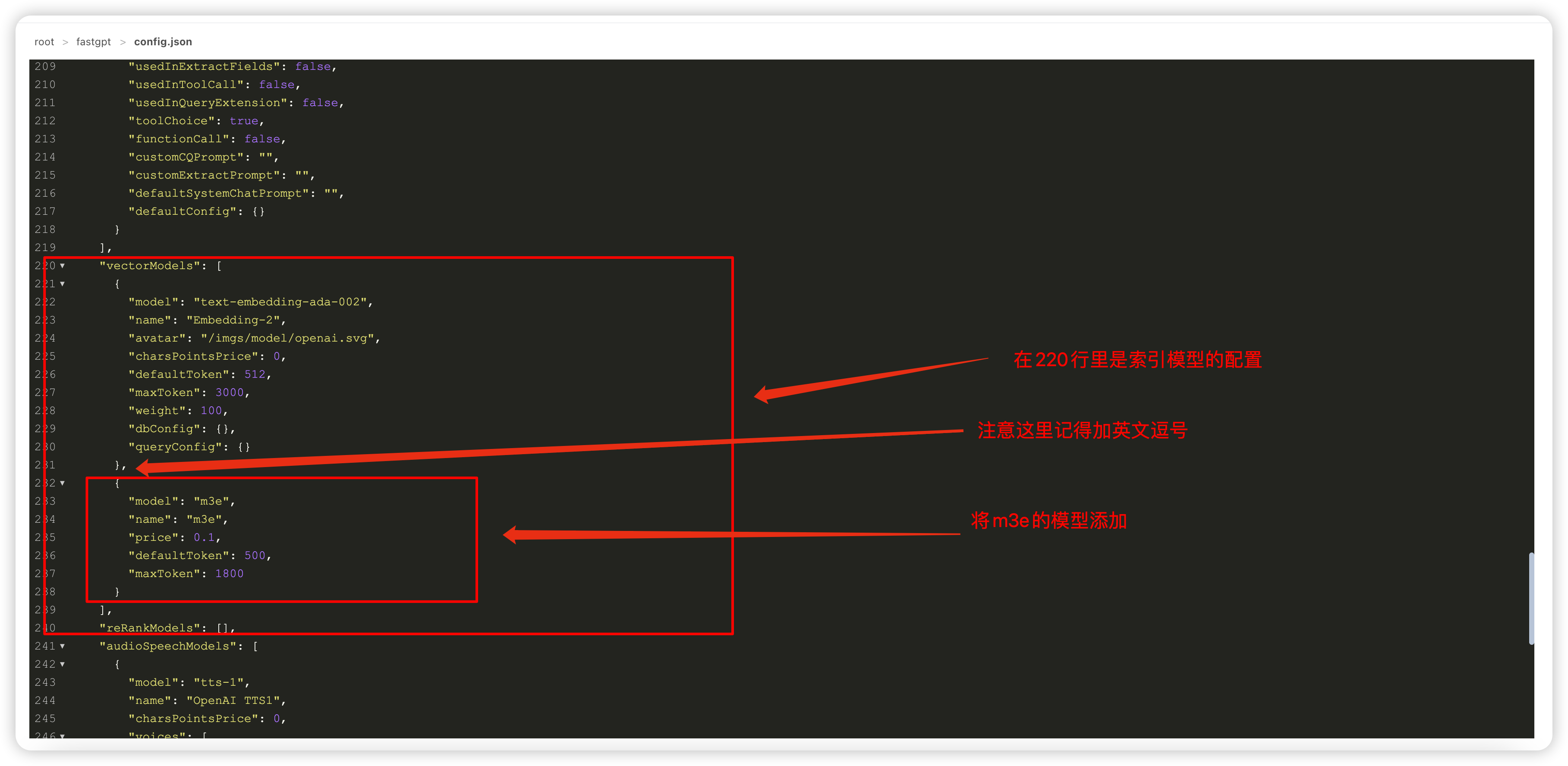
添加m3e模型
{
"model": "m3e",
"name": "m3e",
"price": 0.1,
"defaultToken": 500,
"maxToken": 1800
}
重启fastgpt
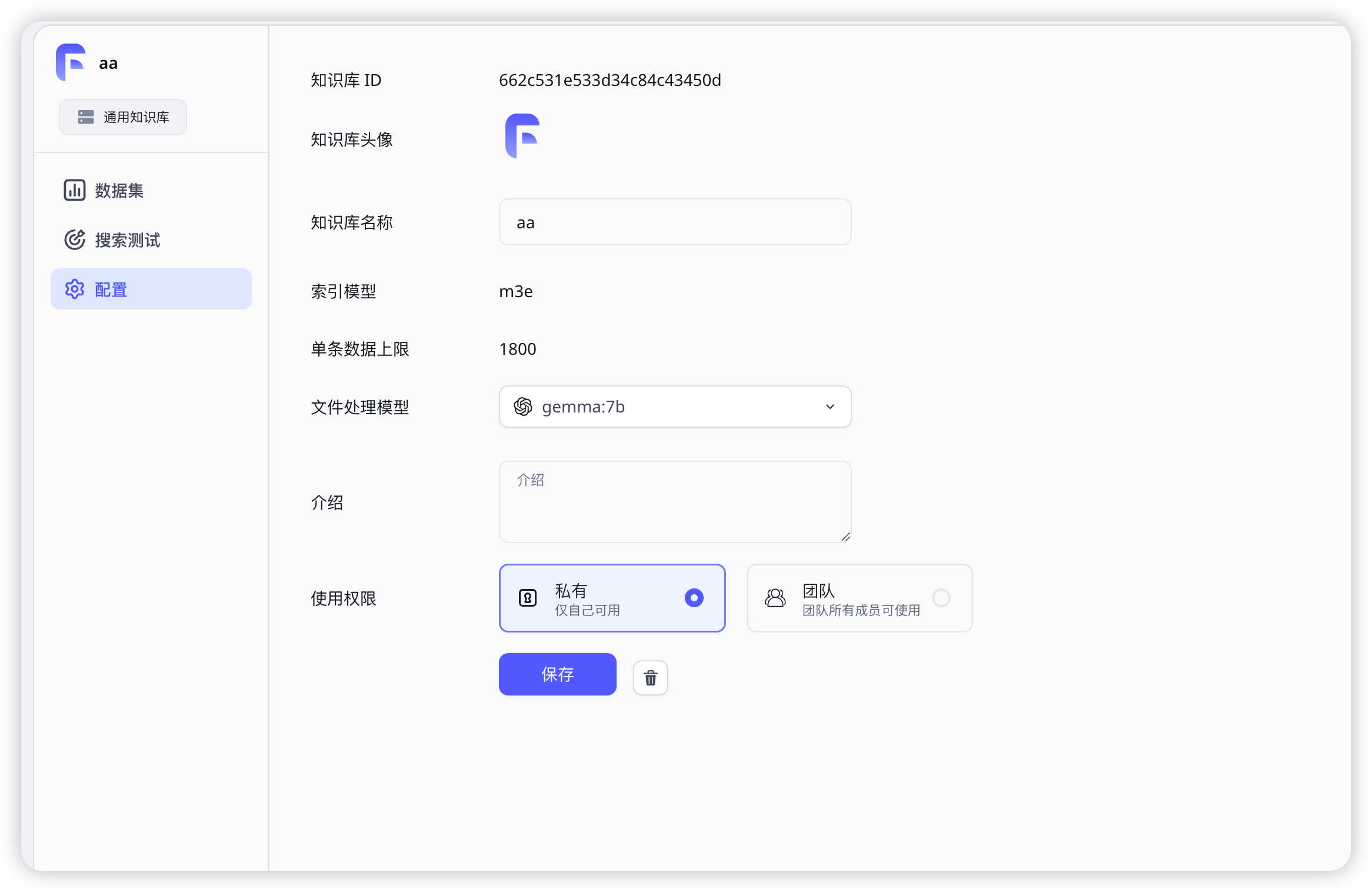
可以看到知识库创建已有M3e
知识库文本处理是如何添加的
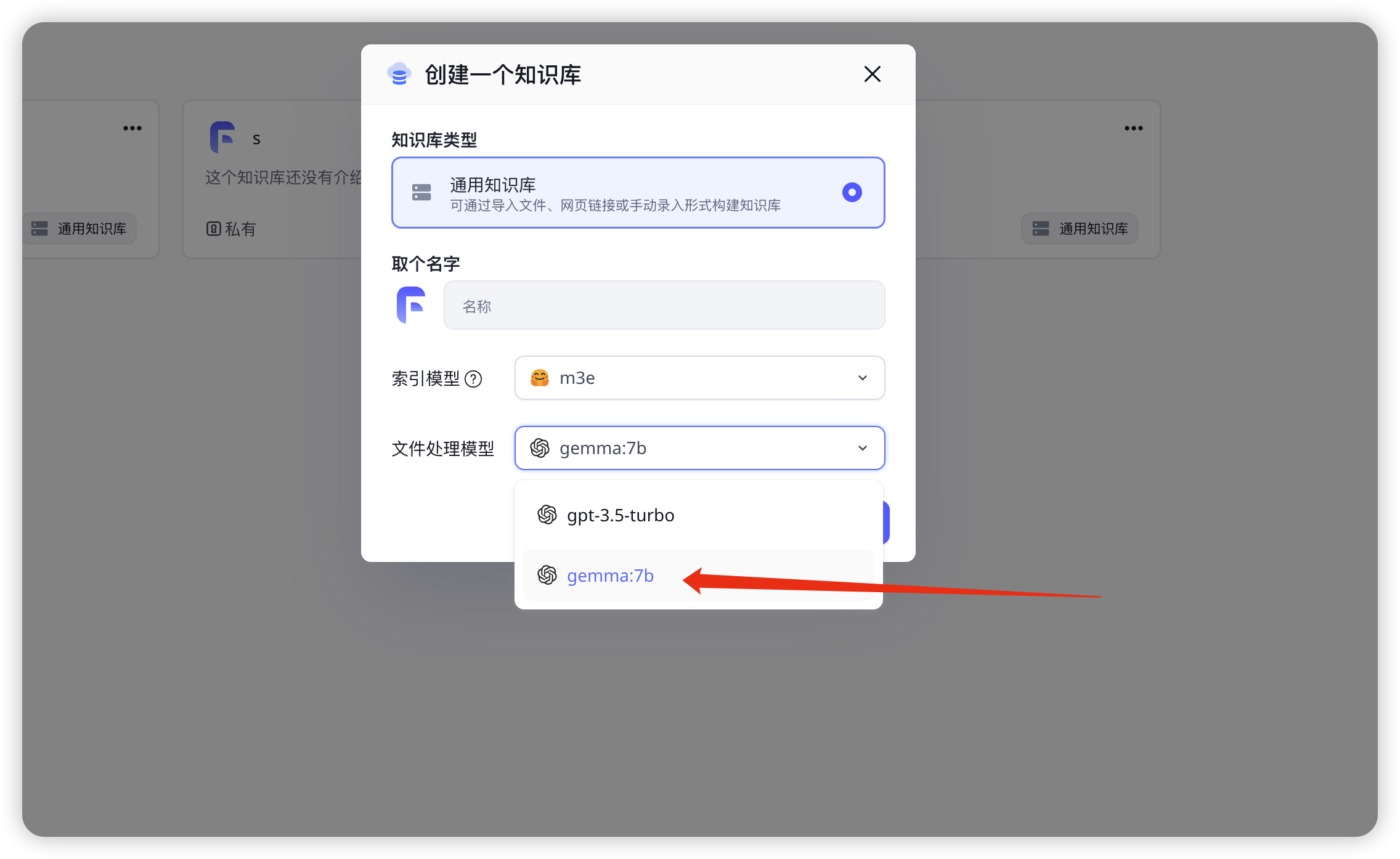
在模型配置文件里设置为true就会显示在此
并且要在fastgpt对接的oneapi里添加索引模型m3e
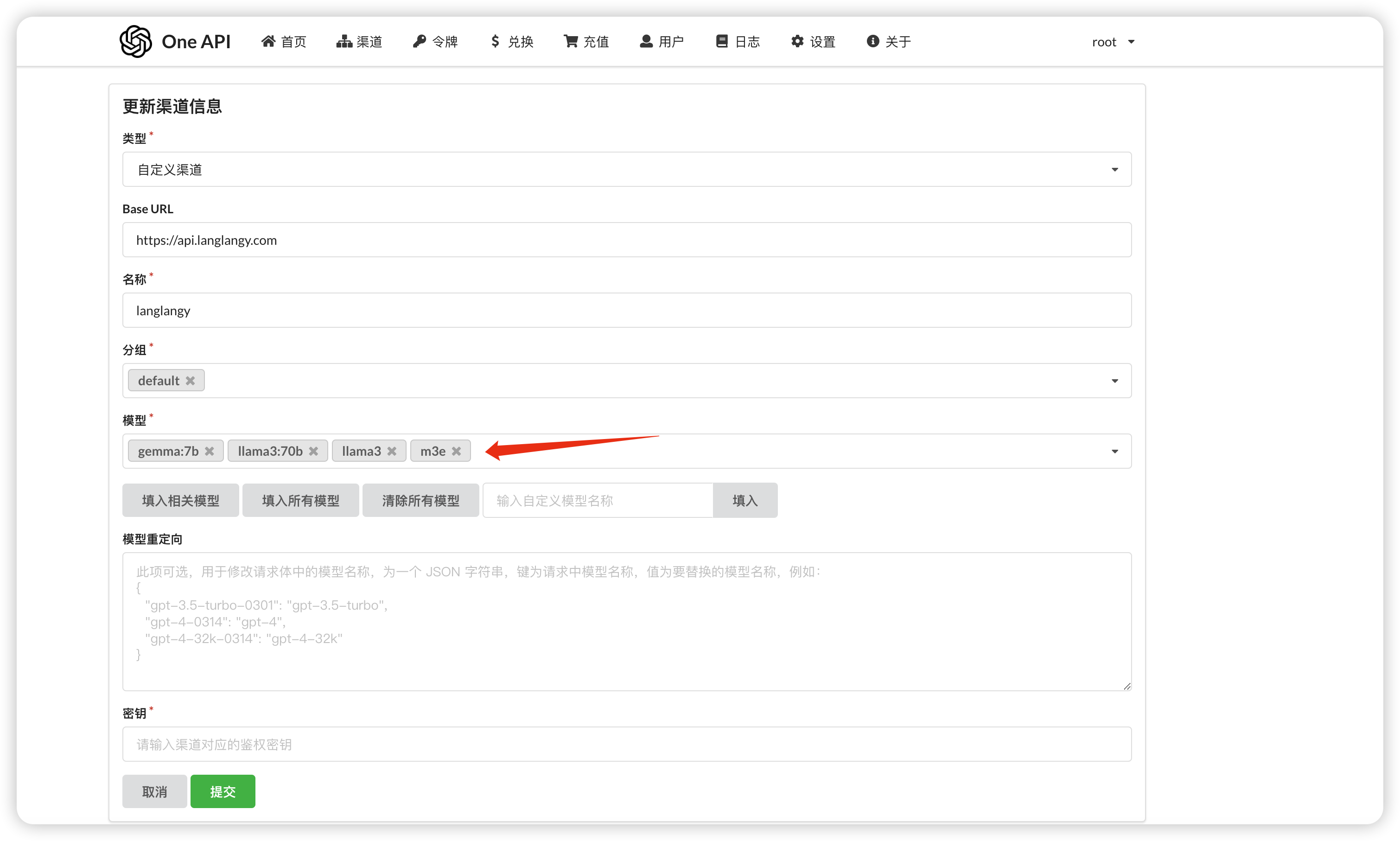
测试是否成功
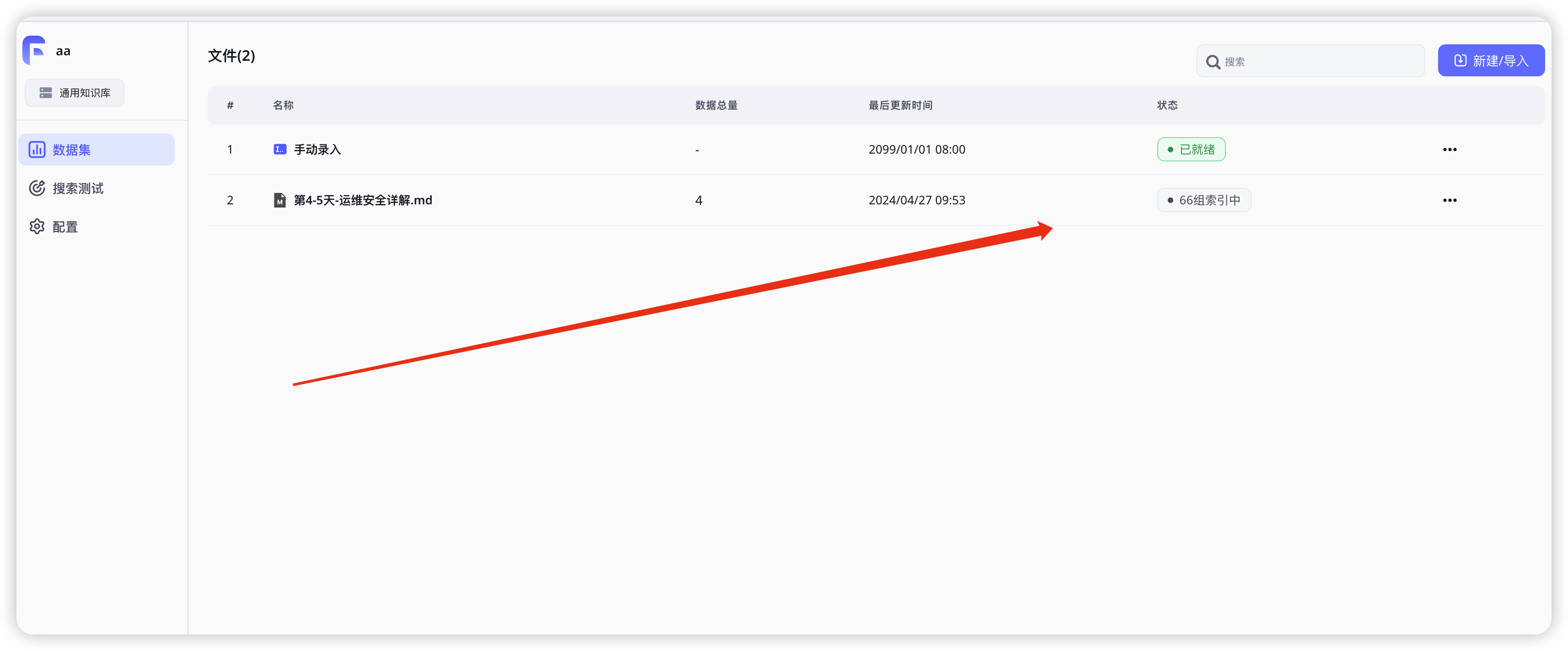
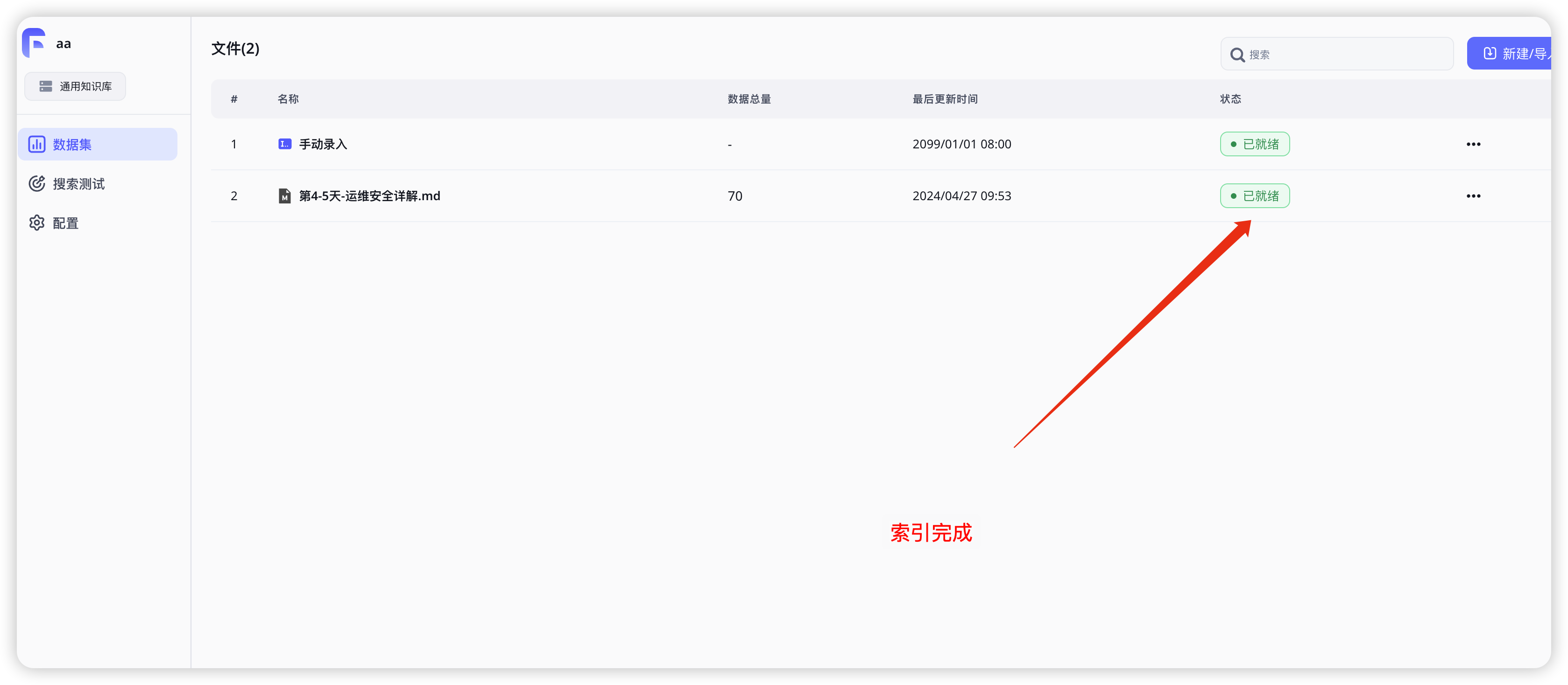
索引完成
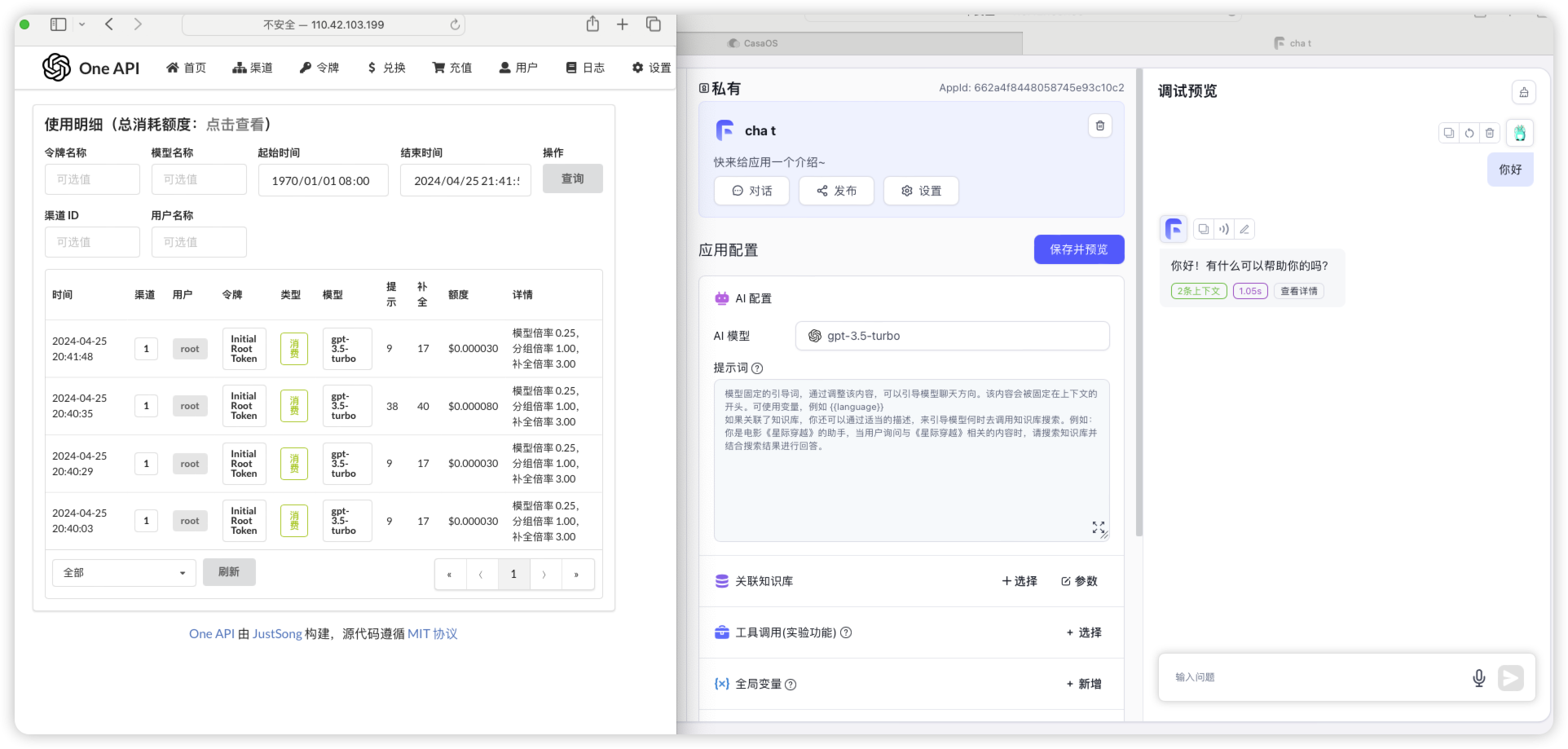
可以看到可以回答知识库相关内容了
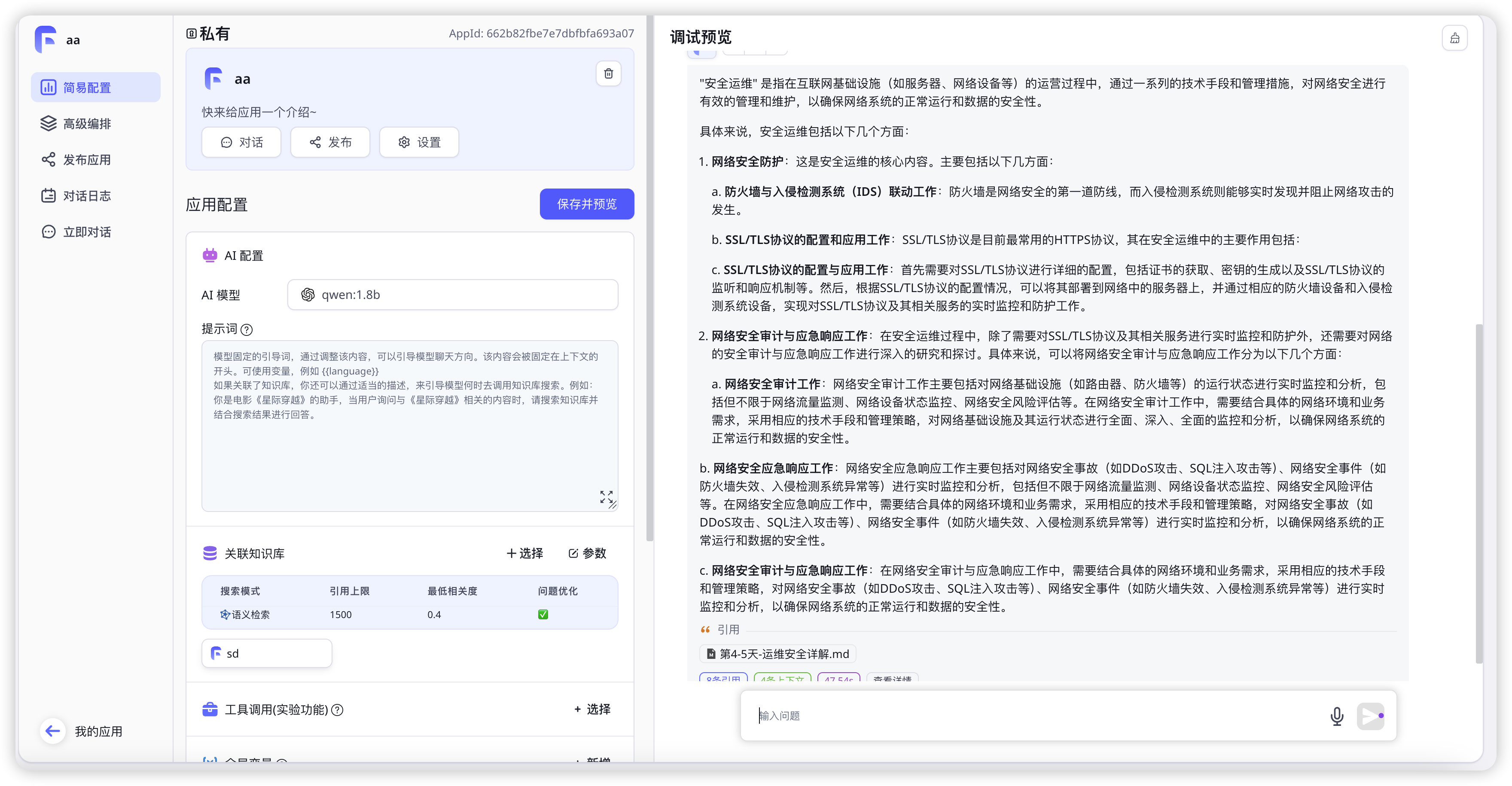
如何更新fastgpt
# 更新fastgpt
docker compose pull
# 启动fastgpt
docker compose up -d
避坑指南
在测试过程中出现配置文件中添加了模型并且也重启了fastgpt,发现fastgpt里还是没有自定义添加的模型
- 仔细检查一下配置文件是否填对
- 配置文件没问题,可以多次重启fastgpt,大概率就会解决问题
oneapi里添加了模型名字,fastgpt里也添加了,但是就是提示无所用模型
- 仔细检查一下模型名字时候填对,或者多等一会在进行测试
更多问题可以加QQ群反馈