文章目录
- 1 客户端程序和服务端程序的差别
- 2 问题类型
- 2.1 崩溃(crash)
- 2.2 CPU高
- 2.3 内存高
- 2.4 线程卡死
- 3 总结
1 客户端程序和服务端程序的差别
客户端程序是运行在终端上,通常都会与业务系统共存,而服务端程序通常会运行在单独的节点上,或者作为业务系统与客户端程序共存。
客户端程序主要关注的是资源占用和稳定性:
- 资源占用:客户端程序和业务系统共存,不能占用太多宿主机的资源,因此,客户端程序需要有能力限制自身的资源利用率,例如使用cgroup等机制
- 稳定性:客户端程序需要使用操作系统的许多机制,有时候还会使用内核模块,这可能会导致系统崩溃,在使用时需要详细评估
服务端程序主要关注的是业务功能和性能:
- 业务功能:前端作为展示入口,大量的功能需要服务端提供
- 性能:用户在操作系统时,最直观的感受是页面渲染的速度,这一方面包括前端页面展示的速度,另一方面还包括后端处理的速度,在使用一些消息队列时,还需要关注消息队列的拥塞导致的性能下降的问题
2 问题类型
2.1 崩溃(crash)
崩溃是程序遇到无法处理的错误时异常退出,对于程序来说,通常有两类错误:
- 预期会产生的错误,这种错误可以打印日志,然后让程序继续执行,或者进行重试
- 非预期的错误,这种错误通常无法完全避免,可能是代码缺少异常处理逻辑,也可能是并发处理造成的异常
对于预期会产生的错误,通常会有语言级别的处理机制:
- golang中有panic/recover
- c++/java中有try/catch
- python中有try/except
而对于非预期的错误,通常会造成程序崩溃,通常只能在问题出现时进行定位。
当程序崩溃时,最常用的手段是通过调用栈定位出现问题的代码行,然后根据出现问题代码行确认问题出现的原因和场景。
对于C++语言来说,如果是在开发环境崩溃,可以通过配置coredump的参数使得程序崩溃时生成core文件,然后使用gdb program core命令打开core文件,再执行bt查看崩溃时的堆栈。如果之前程序崩溃时没有拿到core文件,现在希望复现得到堆栈,可以直接使用gdb命令启动程序:gdb program或者gdb --args program args(分别对应程序启动时不带参数和带参数的情况),这种方式可以用于处理不能复现的崩溃。
如果是在生产环境崩溃,那肯定就不能直接使用gdb定位:
- 生产环境执行的程序一般没有调试信息,也就是编译时不会带上
-g选项 - 生产环境的权限一般管控很严格,不能随意登录和执行命令
如果是自有的服务器,可以开启服务器的coredump的参数,使得程序崩溃时生成coredump,当监控程序发现新的coredump文件,可以将coredump文件上报再将本地文件删除,开发人员可以从服务端下载coredump,然后使用gdb打开coredump找到对应的代码行。
以下面的代码为例:
// main.cpp
#include <iostream>
void func() {
int *ptr = nullptr;
*ptr = 0;
}
int main() {
func();
}
上述代码会在func()函数中的*ptr = 0处崩溃。
使用g++ -o main main.cpp编译上述程序,此时的二进制中是包含符号信息的(file main的输出包含字符串not stripped,使用nm main也可以看到输出了很多符号名),使用strip main将符号信息移除(使用nm main可以确认符号信息已被移除,输出no symbols),而二进制还是可以执行。
然后执行main二进制会发现生成core文件(当然,前提是已经配置过coredump的参数)。
执行gdb,然后在gdb中加载生成的core文件:core-file core-main.3272.1714987794(里面的core-main.3272.1714987794就是生成的core文件),此时用bt命令查看崩溃堆栈时会发现只有地址(崩溃的地址为0x000056382360917d)而不知道实际调用栈,而且这个地址还是加载到内存中的地址。然后执行info proc mappings可以查看内存加载的映像:
Mapped address spaces:
Start Addr End Addr Size Offset objfile
0x563823608000 0x563823609000 0x1000 0x0 /root/crash/main
0x563823609000 0x56382360a000 0x1000 0x1000 /root/crash/main
0x56382360a000 0x56382360b000 0x1000 0x2000 /root/crash/main
0x56382360b000 0x56382360c000 0x1000 0x2000 /root/crash/main
0x56382360c000 0x56382360d000 0x1000 0x3000 /root/crash/main
根据崩溃的地址可以找到代码段的偏移量为0x1000,因此,崩溃的地址在二进制文件中的地址为0x117d,然后使用IDA软件打开二进制文件,会发现崩溃的指令为:
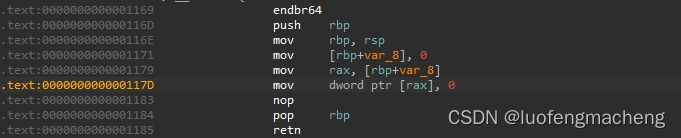
对照源代码,也能够发现代码是崩溃在*ptr = 0。
如果不想使用IDA,也可以使用addr2line工具通过该地址得到符号信息:addr2line -f -e main.bak -a 0x117d(此处的main.bak是执行strip命令前的带符号信息的二进制),会发现输出信息只包含所在的函数的名称,而且还是编译之后的函数名,也可以大致猜出对应的函数名,不过还是没有定位到具体的行,具体的行还是需要使用IDA软件查看。
总之,定位crash的方法主要就是通过生成的core文件中的堆栈地址得到源代码指令,然后再结合日志确定crash的原因和场景。
不过,这里有个问题:如果程序运行在自己的机器或者是定位可以复现的机器,是可以先配置core文件的大小和路径的,然后运行程序得到core,如果程序运行在其他人的机器上呢?难道每次都要求对方先配置下core吗?而且还需要管理生成的core文件,防止撑爆磁盘。
因此,需要有一种能力,可以在程序崩溃时自动生成core,并且将core上传到某个地方进行统一分析,Google的Breadpad就可以完成这项工作,它生成的core文件比较小,适合上报到服务端进行分析。
综上:
- 想办法获取到程序崩溃的堆栈文件(开发环境配置crash路径,生产环境使用Breadpad)
- 根据堆栈文件查看崩溃时的函数调用栈以及崩溃地址(如果带符号,可以直接获取到崩溃的代码行)
- 在带符号的二进制查找函数调用栈和崩溃的地址,就可以得到崩溃时的函数调用关系和代码行(根据崩溃的地址找到对应的代码行需要借助IDA)
- 根据崩溃的代码行猜测可能崩溃的原因和出现的场景,原因大部分都是由于访问空指针或者访问已经回收的指针
- 审查代码逻辑,确认出现问题的场景,然后确认修复方案
2.2 CPU高
CPU高分为内核态CPU占比高和用户态CPU占比高,分别表示执行系统调用和执行用户程序的耗时占比。
对于CPU高的问题,首先是能够发现CPU高的进程,这通常是通过top和pidstat命令来发现,首先通过top命令查看当前运行的进程的CPU占比(此处的%CPU包含内核态和用户态),观察一会发现某个进程的CPU占比高,然后使用pidstat -p PID 1 10查看该进程在10秒内的CPU占比情况,确定该进程是内核态CPU占比高还是用户态CPU占比高,或者是都高。
现在的程序通常都是多线程,如果发现某个进程的CPU高,可以先使用top -H -p PID确认是哪个线程的CPU高,然后再根据线程名称或者日志确认该线程属于哪个功能模块,当然,如果有每个线程的监控数据的话就可以直接看到哪个线程的CPU高。
再使用perf工具对进程进行采样,生成该进程的火焰图,确认耗时比较高的操作,可能是某个系统调用比较频繁,而该系统调用又比较耗时,也可能是某个用户态操作执行太过频繁。
在CPU高的场景中有类特殊的场景:死循环。死循环既可以造成CPU高,也可能造成内存高:当某个线程的用户态CPU占比高,而该线程的逻辑中有循环,则可能是死循环导致。
2.3 内存高
与CPU高的问题类似,首先是需要发现内存高的进程,这通常是通过top和监控程序来发现。
常用的内存分析工具:
- Valgrind:Valgrind是Linux的一套开源的仿真调试工具的集合,由内核和调试工具组成。内核模拟CPU环境,调试工具利用模拟的CPU环境实现各种调试任务。
- Gperftools:Gperftools通过在用户代码中嵌入检测代码实现内存泄漏检测和CPU性能分析,由于不需要模拟器,通常比Valgrind更高效,适合生产环境或者对性能要求比较高的场景。
- Heaptrack:Heaptrack主要用于堆内存分析,可以追踪所有的内存分配并用调用栈进行注释。
- AddressSanitizer(ASAN):内存错误检查器,可以检查堆栈缓冲区溢出、内存泄漏等问题。
2.4 线程卡死
线程卡死是另一类不常出现,但是出现后也不太好定位的问题,从现象上看,就是线程不工作或者不处理任务了。
通常有两种方式发现线程卡死的问题:
- 程序定时打印日志(例如,打印性能指标数据),旁路进程监控日志的打印,如果一段时间没有打印日志,说明线程可能卡死,可以尝试干掉线程
- 多次查看程序的用户态堆栈(
/proc/pid/stack只能查看内核态堆栈,使用pstack或者gdb工具可以查看用户态堆栈),如果每次都一样,该线程可能卡死
使用gdb查看线程堆栈时,先执行gdb -p PID连接到某个进程,然后执行info threads查看所有的线程,每个线程前面有个序号,执行thread XX(XX就是线程前面的序号)可以切换到该线程,最后执行bt就可以查看该线程的用户态堆栈,而且,这个时候如果每个线程的都有唯一的名字就可以很容易确认线程的功能模块。
当程序运行在客户环境时,如果需要安装额外的软件是不太合适的,因此,第二种方式通常用于开发或者内部测试环境使用,取而代之的是程序可以使用命令行的方式获取自身的堆栈信息。
C++中可以使用glibc的backtrace或者第三方的libunwind:
- backtrace:backtrace适合快速获取当前线程的堆栈信息,开销比较小,在多线程环境中需要增加额外的逻辑
- libunwind:libunwind适合需要精确控制堆栈信息获取过程的场景,支持跨平台,可以为每个线程独立获取堆栈信息
综上:
- 如果某个功能没有打印任何日志,并且也不工作(不处理请求),可以怀疑线程退出和卡死
- 对于
开发和可以安装软件的环境来说,可以使用pstack或者gdb多次查看线程堆栈,确认线程是退出还是卡死以及卡死的代码 - 对于
正式和无法安装软件的环境来说,程序可以集成libunwind库来获取多线程的堆栈,并提供命令行的方式输出多线程的堆栈,多次获取多线程的堆栈,确认线程是退出还是卡死
3 总结
不管什么语言开发的程序,都会遇到两类比较棘手的问题:崩溃和性能问题,其中性能问题又可以分为CPU占用高和内存占用高。
对于崩溃,不同的语言有自己处理方式:
- C/C++需要获取core文件,根据堆栈分析出现问题的代码行,开发环境可以配置core路径,正式环境可以使用Breadpad
- golang中可以将GOTRACEBACK设置为crash让程序崩溃时生成core文件(但是,发现用gdb打开时没有程序的符号名,并且core文件很大),也可以在程序退出时利用
runtime/debug中的Stack()获取堆栈 - lua是脚本语言,不会由于指针问题崩溃,但是在出现无法处理问题的时候也会崩溃(例如,给cjson.decode()传递不是json的字符串)而退出lua线程,因此,lua提供了
xpcall()函数,将函数放在xpcall()中执行时如果出现问题得到调用堆栈
对于CPU高和内存高的问题,统一算作性能问题,性能问题需要通过perf和valgrind工具进行分析,找到导致问题的代码,然后重新审查代码,再给出优化方案。
对于线程卡死的问题,需要结合堆栈和代码,确认线程是已经退出,还是执行慢,或者是卡死在某个操作中。