问题背景:
接用户问题报障,应用服务出现大量会话堆积现象,数据库锁堵塞严重,需要协助进行问题定位和排除。
问题分析:
登录到数据库服务器上,首先查看一下数据库当前的等待事件情况,通过gv$session视图可以看到,当前会话存在大量的enq: TX - row lock contention行锁堵塞。
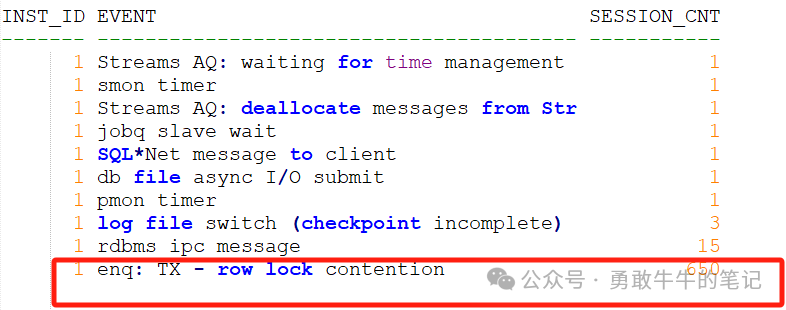
对应出现TX行锁堵塞情况,需要分析一下TX行锁的堵塞链情况,确认是否是同一个堵塞源还是多个不同的堵塞源,对于同一个堵塞源引发的TX行锁问题,需要重点去分析这个堵塞源的会话状态和操作行为是否存在问题,比如有没有在执行长时间拿锁的操作,语句的执行状态时间、会话的状态空闲还是活跃以及业务的事务执行逻辑。对于出现多条堵塞链和多个不同的堵塞源情况,通常是由于数据库的性能问题、表索引的设计问题、业务的事务逻辑问题导致,需要先分析整理堵塞链上的操作对象是否存在关联,业务的执行逻辑是否存在关系,再进一步分析堵塞产生的原因。
这里我们通过gv$session视图的blocking_session查询会话之间的堵塞链情况,可以看到会话的堵塞源最终都指向了节点一实例的SID:855会话。

select *
from (select a.inst_id, a.sid, a.serial#,
a.sql_id,
a.event,
a.status,
connect_by_isleaf as isleaf,
sys_connect_by_path(a.SID||'@'||a.inst_id, ' <- ') tree,
level as tree_level
from gv$session a
start with a.blocking_session is not null
connect by (a.sid||'@'||a.inst_id) = prior (a.blocking_session||'@'||a.blocking_instance))
where isleaf = 1
order by tree_level asc;由于堵塞源都指向855会话,因此这里我们只取其中一条堵塞链<- 69@1 <- 100@1 <- 368@1 <- 855@1进行分析。
查看堵塞源SID 855的会话执行情况,可以看到会话为LGWR进程,状态为ACTIVE,等待事件为rdbms ipc message。LGWR引发堵塞,很有可能是LGWR进程无法及时完成日志写工作。

再继续往下查看,堵塞链上的下一级会话SID 368,可以看到会话为JDBC应用会话,等待事件为log file switch (checkpoint incomplete),当前执行SQL为:gyc4mt35nxs83,可以看到当前会话是由于日志切换检查点未完成,导致会话出现堵塞。

再继续查看下一级会话SID 100和69,可以看到会话为JDBC应用会话,等待事件为enq: TX - row lock contention,当前执行SQL为:gyc4mt35nxs83。

执行SQL:gyc4mt35nxs83为UPDATE XXXX_TAB语句。

从这里,我们可以确认整个堵塞链的发生原因,由于LGWR进程日志切换检查点无法及时完成,导致执行XXXX_TAB的UPDATE语句的会话出现等待,进而引发后续的对该表的UPDATE会话出现TX锁堵塞。
从后台日志也可以看到有很多由于检查点未完成导致日志无法分配的信息,那么数据库当前出现日志切换检查点未完成的原因是什么呢,我们继续往下分析。
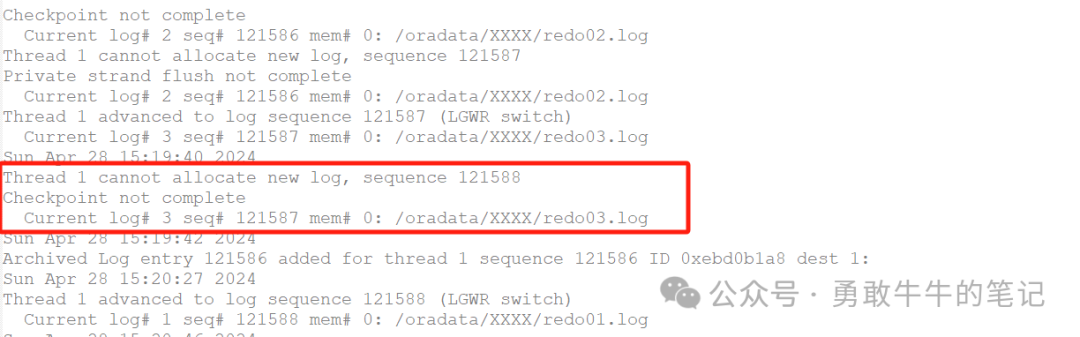
当前数据库REDO日志组的配置为1G*3组,属于合理的日志组配置,查看数据库的磁盘IO负载情况,可以看到当前的磁盘IO负载非常繁忙,IO util已经达到100%,很明显当前数据库的IO写操作较多,频繁触发检查点,加上DBWR进程不断写数据,最终导致日志切换由于检查点来不及完成出现等待。
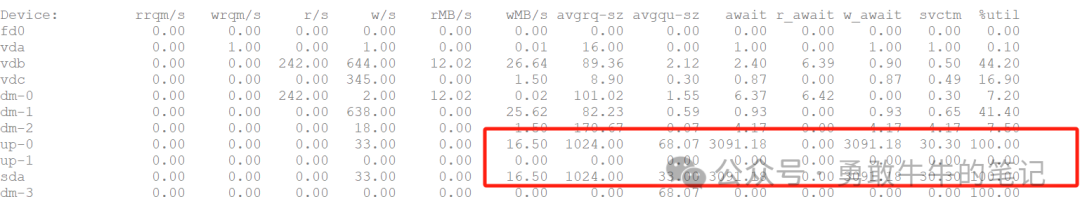
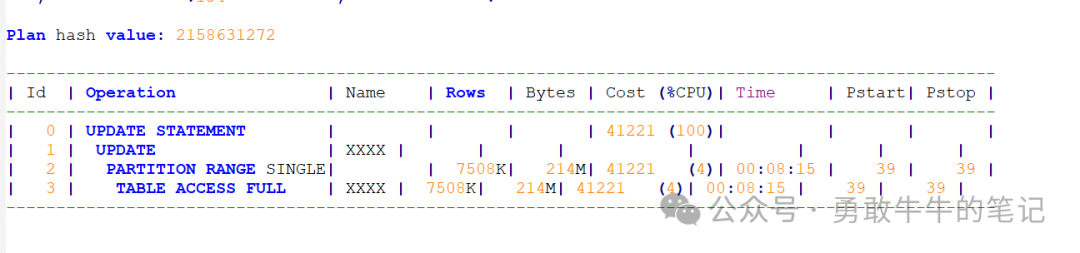
检查数据库的写操作,发现罪魁祸首原来是之前的TX锁执行语句gyc4mt35nxs83,语句对千万级的分区进行全扫描,加上服务器的磁盘为机械盘,磁盘IO性能很快就被打满。
问题解决:
1 跟应用确认,当前的会话模块为非核心业务,可以先将TX锁堵塞会话kill,释放服务器IO资源,避免影响其他业务模块。
2 先关闭引发TX锁的非核心业务模块,待语句优化之后再进一步启动。
Tip:欢迎关注公众号:勇敢牛牛的笔记,超100+的原创内容,每周不定期更新数据库技术文章