LSTM,全称Long Short-Term Memory,是一种特殊的递归神经网络。它通过巧妙的"门"结构,可以有效地捕捉时间序列数据中的长期依赖关系。这一特点,使得LSTM在处理股价这种具有时间序列特性的数据时,展现出了非凡的潜力。
这种特殊的递归神经网络 与一般的前馈神经网络不同,当使用前馈神经网络时,神经网络会认为我们 𝑡 时刻输入的内容与 𝑡+1 时刻输入的内容完全无关,对于许多情况,例如图片分类识别,这是毫无问题的,可是对于一些情景,例如自然语言处理 (NLP, Natural Language Processing) 或者我们需要分析类似于连拍照片这样的数据时,合理运用 𝑡 或之前的输入来处理 𝑡+𝑛 时刻显然可以更加合理的运用输入的信息。为了运用到时间维度上信息,人们设计了递归神经网络 (RNN, Recurssion Neural Network),一个简单的递归神经网络可表示为:
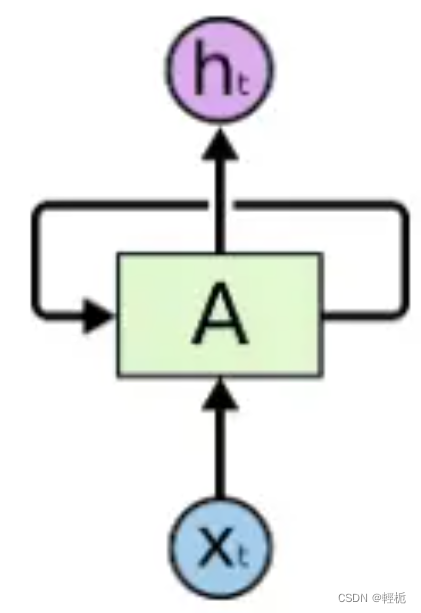
图中, 𝑥𝑡 是在 𝑡 时刻的输入信息, ℎ𝑡 是在 𝑡 时刻的输出信息,可以看到神经元 𝐴 会递归的调用自身并且将 𝑡−1 时刻的信息传递给 𝑡 时刻。递归神经网络在许多情况下运行良好,特别是在对短时间序列数据的分析时十分方便。但上图所示的简单递归神经网络存在一个“硬伤“,长期依赖问题:递归神经网络只能处理上下文较接近的情况:
Exp 1. 想象现在设计了一个基于简单RNN的句子自动补全器,当我输入"Sea is ..." 的时候会自动补全为"Sea is blue"。
在这种情况下,我们需要获取从上文获取的信息极短,而RNN可以很好的收集到 𝑡=0 时的信息"Sea"并且补上"blue"
Exp 2. 现在,假设我们用刚刚的RNN试图补全一篇文章"我一直呆在中国,……,我会说一口流利的 (?)"。
在这里,为了补全最后的空缺,需要的信息可能在非常远的上文提到的”中国“。在实验中简单的理想状态下,经过精心调节的RNN超参数可以良好的将这些信息向后传递。可是在现实的情况中,基本没有RNN可以做到这一点。不但如此,相比于一般的神经网络,这种简单的RNN还很容易出现两种在神经网络中臭名昭著的问题:梯度消失问题(神经网络的权重/偏置梯度极小,导致神经网络参数调整速率急剧下降:)和梯度爆炸问题(神经网络的权重/偏置梯度极大,导致神经网络参数调整幅度过大,矫枉过正:
)。对于任意信息递归使用足够多次同样的计算,都会导致极大或极小的结果。
根据微分链式法则,在RNN中,神经元的权重的梯度可以被表示为一系列函数的微分的连乘。因为神经元的参数(权重与偏置)都是基于学习速率(一般为常数)和参数梯度相反数(使得神经网络输出最快逼近目标输出)得到的,一个过小或过大的梯度会导致我们要么需要极长的训练时间(本来从-2.24 调节到 -1.99 只用500个样本,由于梯度过小,每次只调 ,最后用了几万个样本),要么会导致参数调节过度(例如本来应该从-10.02调节到-9.97,由于梯度过大,直接调成了20.7)。
基于以上问题,LSTM的设计者提出了“长短期记忆”的概念——只有一部分的信息需要长期的记忆,而有的信息可以不记下来。同时,还需要一套机制可以动态的处理神经网络的“记忆”,因为有的信息可能一开始价值很高,后面价值逐渐衰减,这时候我们也需要让神经网络学会“遗忘”特定的信息,这就是下面提到的遗忘门、记忆门、输出门。
一个普通的,使用tanh作为激活函数的RNN可以这么表示:
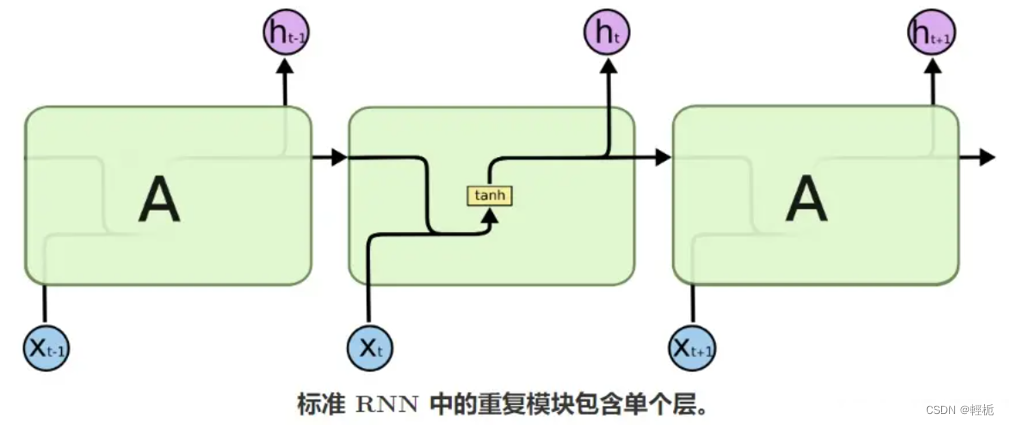
这里A在 𝑡−1 时刻的输出值被复制到了 𝑡 时刻,与 𝑡 时刻的输入
整合后经过一个带权重和偏置的tanh函数后形成输出,并继续将数据复制到 𝑡+1 时刻。
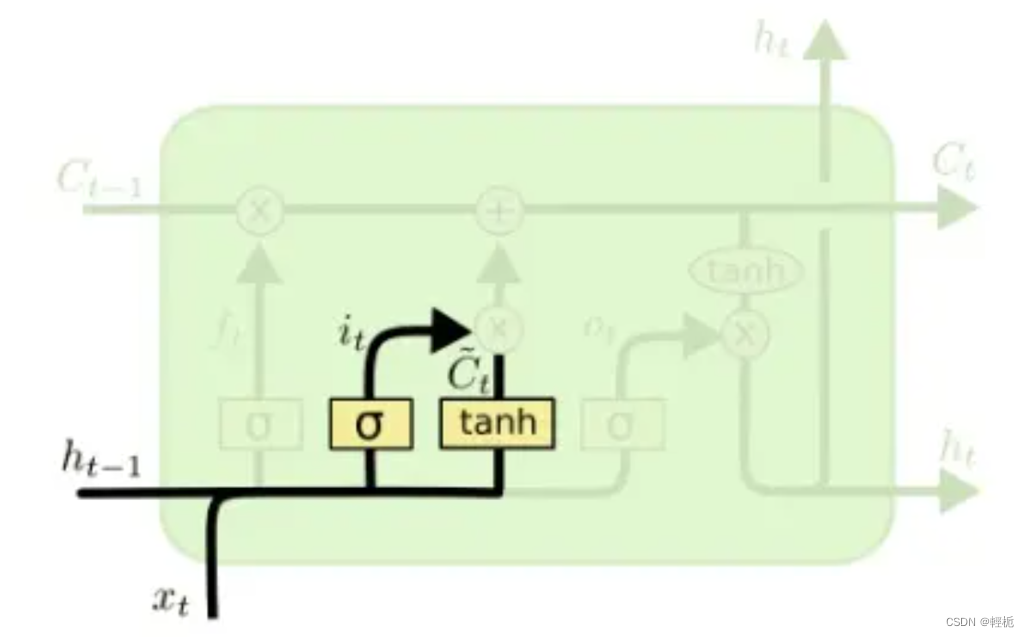
与上图朴素的RNN相比,单个LSTM单元拥有更加复杂的内部结构和输入输出:

上图中每一个红色圆形代表对向量做出的操作(pointwise operation, 对位操作),而黄色的矩形代表一个神经网络层,上面的字符代表神经网络所使用的激活函数
point-wise operation 对位操作
如果我要对向量<1, 2, 3> 和 <1, 3, 5>进行逐分量的相乘操作,会获得结果 <1, 6, 15>
layer 函数层
一个函数层拥有两个属性:权重向量(Weight) 和 偏置向量(bias),对于输入向量 𝐴 的每一个分量 𝑖 , 函数层会对其进行以下操作(假设激活函数为 𝐹(𝑥) ):常见的激活函数(也就是套在最外面的 𝐹(𝑥) )有ReLU(线性修正单元),sigmoid(写作 𝜎 ),和 tanh
LSTM的关键:单元状态
LSTM能够从RNN中脱颖而出的关键就在于图中从单元中贯穿而过的线 ——神经元的隐藏态(单元状态),可将神经元的隐藏态简单的理解成递归神经网络对于输入数据的“记忆”,用表示神经元在 𝑡 时刻过后的“记忆”,这个向量涵盖了在 𝑡+1 时刻前神经网络对于所有输入信息的“概括总结”

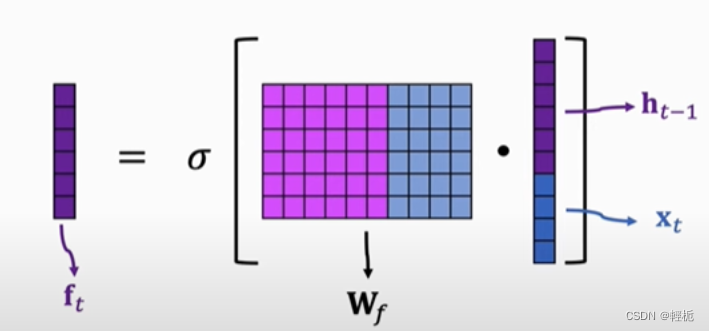
LSTM_1 遗忘门
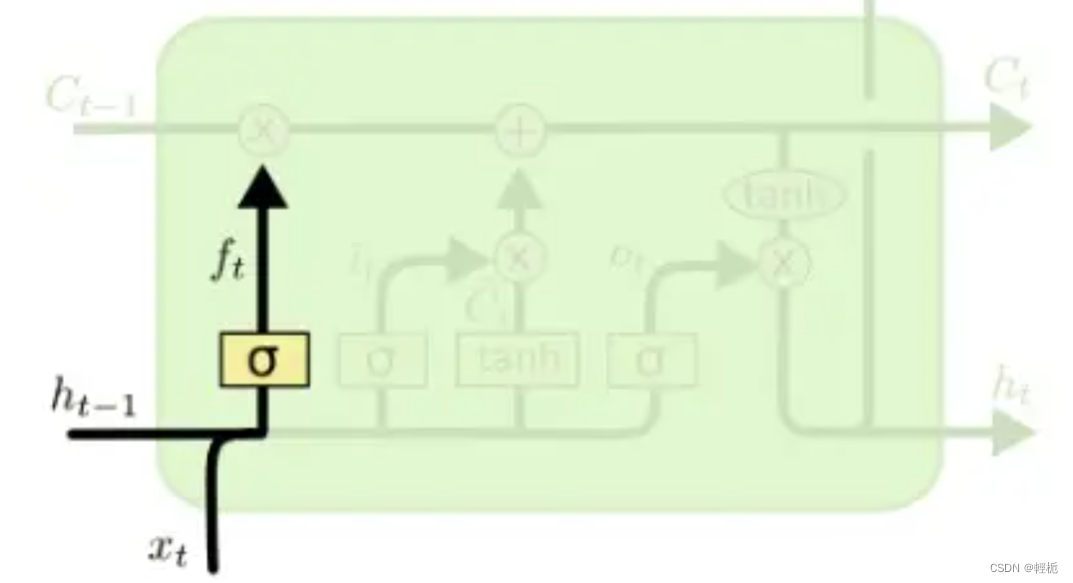
对于上一时刻LSTM中的单元状态来说,一些“信息”可能会随着时间的流逝而“过时”。为了不让过多记忆影响神经网络对现在输入的处理,模型应该选择性遗忘一些在之前单元状态中的分量——这个工作就交给了“遗忘门”,每一次输入一个新的输入,LSTM会先根据新的输入和上一时刻的输出决定遗忘掉之前的哪些记忆——输入和上一步的输出会整合为一个单独的向量,然后通过sigmoid神经层,最后点对点的乘在单元状态上。因为sigmoid 函数会将任意输入压缩到 (0,1) 的区间上,因此可以非常直觉的得出这个门的工作原理 —— 如果整合后的向量某个分量在通过sigmoid层后变为0,那么显然单元状态在对位相乘后对应的分量也会变成0,换句话说,“遗忘”了这个分量上的信息;如果某个分量通过sigmoid层后为1,单元状态会“保持完整记忆”。不同的sigmoid输出会带来不同信息的记忆与遗忘。通过这种方式,LSTM可以长期记忆重要信息,并且记忆可以随着输入进行动态调整, 计算遗忘门的公式为,其中 𝑓𝑡 就是sigmoid神经层的输出向量:
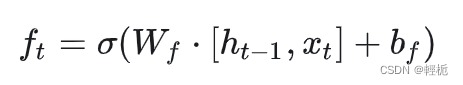
画图表示为:
LSTM_2 & 3 记忆门
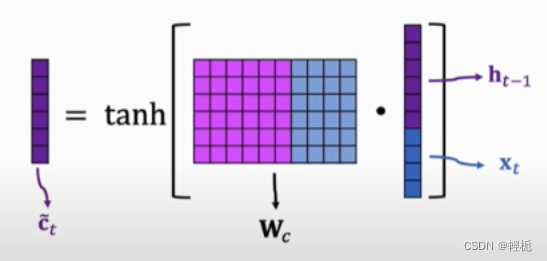
记忆门是用来控制是否将在 𝑡时刻(现在)的数据并入单元状态中的控制单位。首先,用tanh函数层将现在的向量中的有效信息提取出来,然后使用(图上tanh函数层左侧)sigmoid函数来控制这些记忆要放“多少”进入单元状态。这两者结合起来就可以做到:
- 从当前输入中提取有效信息
- 对提取的有效信息做出筛选,为每个分量做出评级(0 ~ 1),评级越高的最后会有越多的记忆进入单元状态
下面的公式分别表示这两个步骤在LSTM中的计算:
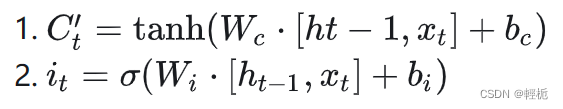
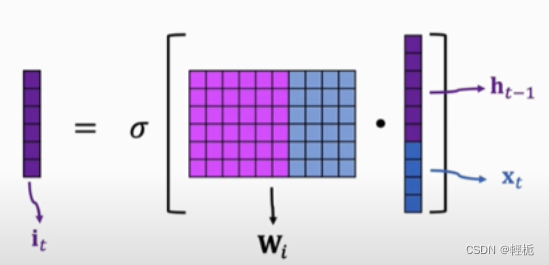
LSTM_4 输出门
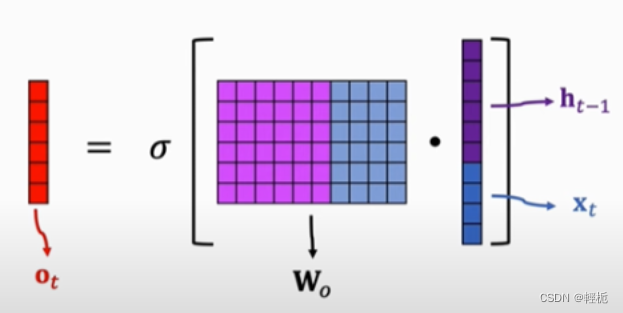
输出门就是LSTM单元用于计算当前时刻的输出值的神经层。输出层会先将当前输入值与上一时刻输出值整合后的向量(也就是公式中的 [ℎ𝑡−1,𝑥𝑡] )用sigmoid函数提取其中的信息,接着会将当前的单元状态通过tanh函数压缩映射到区间(-1, 1)中。
为什么我们要在LSTM的输出门上使用tanh函数?
1. 为了防止 梯度消失问题,我们需要一个二次导数在大范围内不为0的函数,而tanh函数可以满足这一点
2. 为了便于凸优化,我们需要一个 单调函数
3. tanh函数一般收敛的更快
4. tanh函数的求导占用系统的资源更少
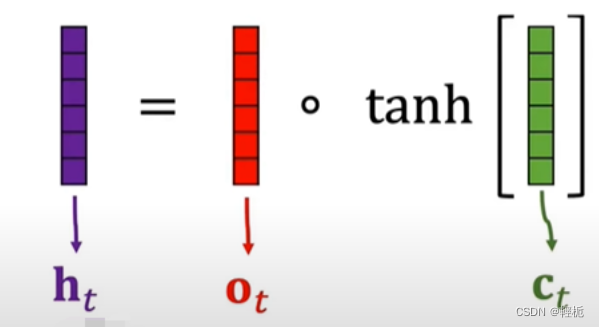
将经过tanh函数处理后的单元状态与sigmoid函数处理后的,整合后的向量点对点的乘起来就可以得到LSTM在 𝑡 时刻的输出了!
对于任何机器学习任务,数据都是一切的基石。而对于股价预测这样的时间序列问题,我们需要的是结构化的时间序列数据。为了方便直接用接口了:
import akshare as ak
# data = ak.stock_zh_a_minute(symbol='sz000001',period='1',adjust="") # 1, 5, 15, 30, 60
df = ak.stock_zh_a_hist(symbol="000001", period="daily", start_date="20100301", end_date='20240508', adjust="")
对数据进行一些预处理。这包括检查和填补缺失值,以及将数据归一化到0到1的范围内。归一化可以帮助神经网络更快地收敛。
pd.isna(df).sum()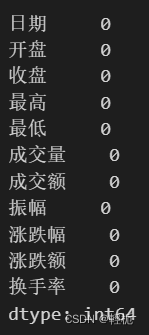
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
df = df[['日期', '开盘', '收盘', '最高', '最低', '成交量', '成交额']]
df.columns=['trade_date', 'open', 'close', 'high', 'low', 'vol','amount']
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index('trade_date', inplace=True)
# 填补缺失值(如果有的话)
# df.fillna(method="ffill", inplace=True)
# 选择要预测的特征
features = ["open", "high", "low", "close", "vol"]
# 归一化数据
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df[features])
# 将归一化后的数据转换为DataFrame
scaled_df = pd.DataFrame(scaled_data, columns=features, index=df.index)
用Keras库来搭建神经网络。首先需要将数据转换为LSTM所需的格式。LSTM期望数据具有以下形状:[样本数,时间步数,特征数]。时间步数表示我们要根据过去多少天的数据来预测未来的股价。
import numpy as np
# 设定时间步数
time_steps = 60
# 准备LSTM输入数据
X = []
y = []
for i in range(time_steps, len(scaled_df)):
X.append(scaled_df[i-time_steps:i])
y.append(scaled_df["close"][i])
X = np.array(X)
y = np.array(y)这里设定时间步数为60,即根据过去60天的数据预测下一天的收盘价。然后,用一个循环来准备LSTM的输入数据。对于每个时间点,取前60天的数据作为输入,下一天的收盘价作为预测目标。接下来搭建LSTM模型:
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
# 构建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(units=1))
model.compile(optimizer="adam", loss="mean_squared_error")用Keras的Sequential模型来搭建LSTM网络。网络包含三层LSTM,每层有50个神经元。在每个LSTM层之后,我们添加了一个Dropout层来防止过拟合。最后添加一个全连接层来输出预测结果。用Adam优化器和均方误差损失函数MSE来编译模型。
开始训练模型,神经网络通过不断调整权重,从数据中学习模式和规律:
# 训练模型
model.fit(X, y, epochs=100, batch_size=32)这里调用模型的fit方法来训练网络。设置训练的轮数(epochs)为100,每个批次(batch)的大小为32。这意味着,神经网络将遍历整个训练数据集100次,每次更新权重时使用32个样本。在训练过程中会看到每个epoch的损失值(loss)。损失值越低,通常意味着模型的性能越好。
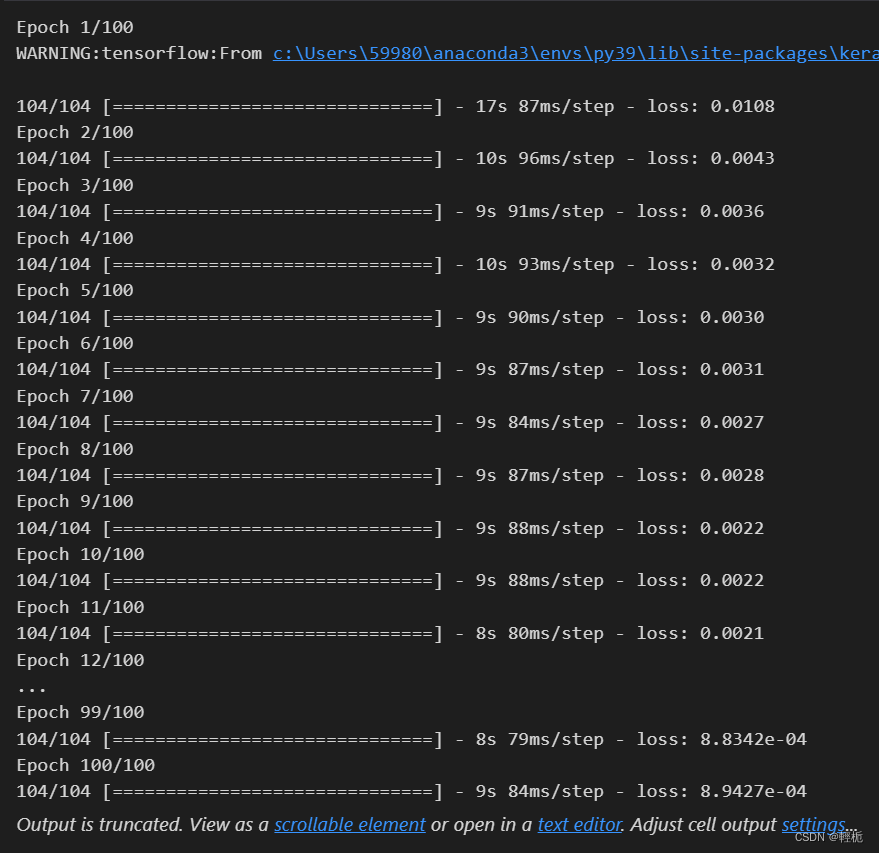
模型评估:将数据分为训练集和测试集,用训练集数据训练模型,然后在测试集上评估模型的预测能力。
from sklearn.metrics import mean_squared_error
# 进行预测
y_pred = model.predict(X)
# 计算均方误差
mse = mean_squared_error(y, y_pred)
print(f"Mean Squared Error: {mse}")简单画了一下走势图:
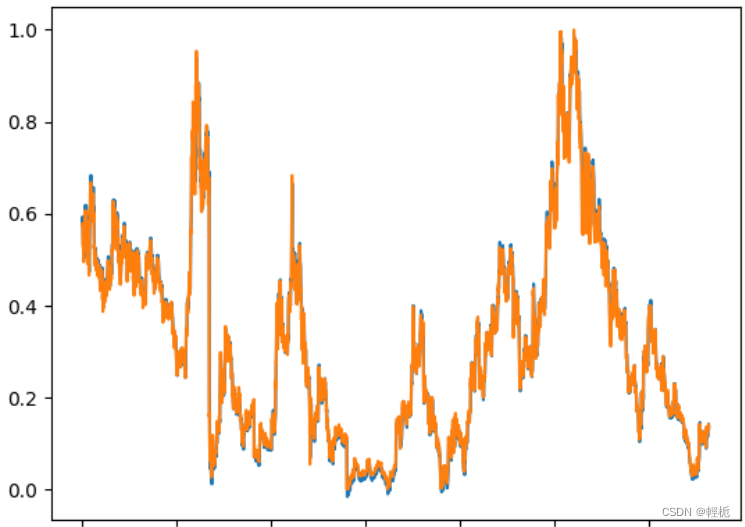
预测值和实际值偏离度不大。
上面是用训练好的模型对输入数据进行预测,得到预测值y_pred。然后,我们使用mean_squared_error函数计算预测值和真实值之间的均方误差(MSE)。MSE是一个常用的回归问题的评估指标,它衡量了预测值与真实值之间的平均squared距离。MSE越小,通常意味着模型的预测性能越好。得到的结果为:

如果你对模型的性能满意,就可以用它来进行实际的股价预测了。为了进行预测,需要准备最近60天的股价数据作为输入(这里仅训练了一个特征,需要重新初始化一下):
# 准备最近60天的数据
last_60_days = scaled_df[-60:]
last_60_days_arr = np.array(last_60_days)
last_60_days_arr = np.reshape(last_60_days_arr, (1, last_60_days_arr.shape[0], last_60_days_arr.shape[1]))
# 重新初始化scaler对象,只包含一个特征的归一化信息
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df['close'].values.reshape(-1, 1))
# 进行预测
pred_price = model.predict(last_60_days_arr)
# 将预测值反归一化
pred_price = scaler.inverse_transform(pred_price)
print(f"Predicted Price: {pred_price[0][0]}")下面输出了预测的股价。这个预测价格表示模型对下一个交易日收盘价的预期。当然,这只是一个预测,你如果相信就死定了(明天可能会回到10.8):
![]()
模型优化
虽然已经能够用LSTM模型来预测股价,但模型的性能还有很大的提升空间。以下是一些可能的优化策略:
-
增加特征:除了开盘价、最高价、最低价、收盘价和成交量,我们还可以加入其他技术指标,如移动平均线、RSI、MACD等。这些指标可能包含了一些有助于预测的信息。
-
调整模型结构:我们可以尝试不同的LSTM层数、神经元数、激活函数、正则化方法等,以找到最优的模型结构。这可能需要一些反复试验和调优。
-
引入注意力机制:注意力机制可以帮助模型更好地关注到重要的时间步。我们可以在LSTM层之上添加一个注意力层,让模型自动学习每个时间步的权重。
-
集成学习:我们可以训练多个不同的LSTM模型,然后将它们的预测结果进行平均或投票。这种集成学习的方法通常可以提高预测的稳健性和准确性。
-
引入更多数据:除了历史价格数据,我们还可以考虑引入一些基本面数据,如公司财报、宏观经济指标等。这可能需要我们对数据进行更复杂的预处理和特征工程。
如3引入self-attention机制的模型训练:
from keras.models import Model
from keras.layers import Input, LSTM, Dense, Dropout, Activation, Permute, multiply
# 构建带注意力机制的LSTM模型
input_data = Input(shape=(time_steps, X.shape[2]))
lstm_out = LSTM(60, return_sequences=True)(input_data)
attention_probs = Dense(time_steps, activation='softmax', name='attention_probs')(lstm_out)
attention_mul = multiply([lstm_out, attention_probs])
attention_mul = Permute((2,1))(attention_mul)
final_output = Dense(1)(attention_mul)
model = Model(input_data, final_output)
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X, y, epochs=200, batch_size=32)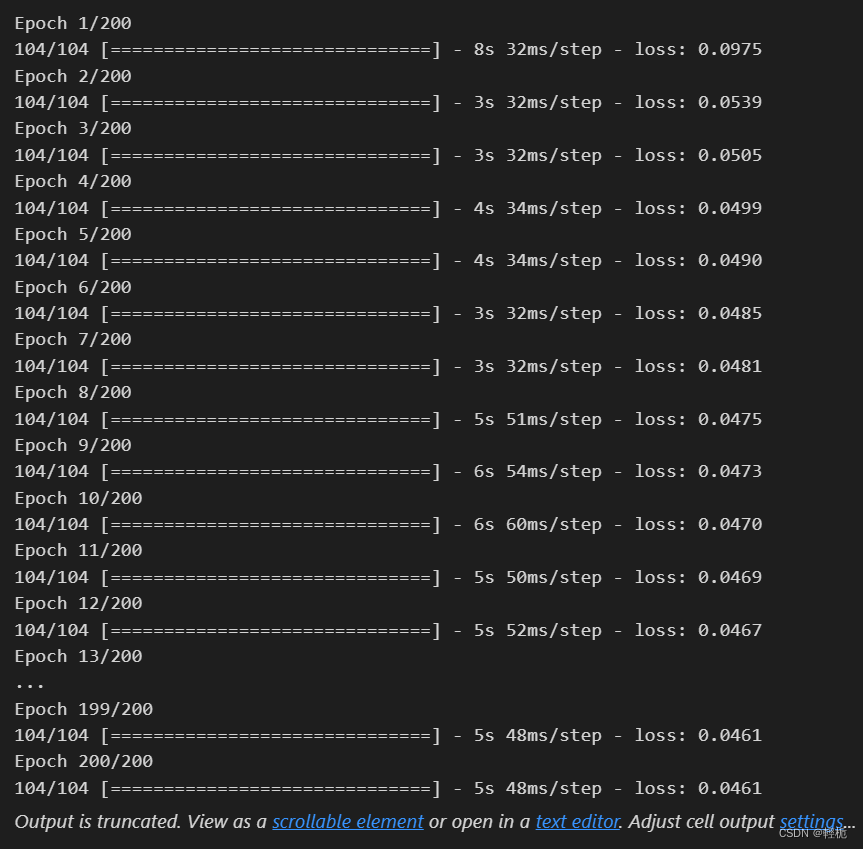
得到的结果为:

Transformer模型在NLP领域掀起了一场革命,其独特的自注意力机制和并行计算架构,让其在机器翻译、文本生成等任务上大幅刷新了SOTA记录。更重要的是,Transformer并不限于文本数据,其处理序列数据的能力同样可以拓展到时间序列领域。将Transformer应用于金融市场建模时,其记忆容量和建模能力可显著超越传统的RNN模型。直观来说,股票市场蕴藏着极为复杂的多尺度动力学过程,价格波动受基本面、资金面、市场情绪等诸多因素的交互影响,这些影响往往跨越不同的时间尺度。Transformer凭借其强大的注意力机制,能够自适应地关注不同时间尺度上的关键特征,挖掘出价格波动背后的深层逻辑,可谓深度长期记忆建模的利器。
Transformer的一些重要组成部分和特点:
自注意力机制(Self-Attention):这是Transformer的核心概念之一,它使模型能够同时考虑输入序列中的所有位置,而不是像循环神经网络(RNN)或卷积神经网络(CNN)一样逐步处理。自注意力机制允许模型根据输入序列中的不同部分来赋予不同的注意权重,从而更好地捕捉语义关系。
多头注意力(Multi-Head Attention):Transformer中的自注意力机制被扩展为多个注意力头,每个头可以学习不同的注意权重,以更好地捕捉不同类型的关系。多头注意力允许模型并行处理不同的信息子空间。
堆叠层(Stacked Layers):Transformer通常由多个相同的编码器和解码器层堆叠而成。这些堆叠的层有助于模型学习复杂的特征表示和语义。
位置编码(Positional Encoding):由于Transformer没有内置的序列位置信息,它需要额外的位置编码来表达输入序列中单词的位置顺序。
残差连接和层归一化(Residual Connections and Layer Normalization):这些技术有助于减轻训练过程中的梯度消失和爆炸问题,使模型更容易训练。
编码器和解码器:Transformer通常包括一个编码器用于处理输入序列和一个解码器用于生成输出序列,这使其适用于序列到序列的任务,如机器翻译。
Transformer的结构:
Nx = 6,Encoder block由6个encoder堆叠而成,图中的一个框代表的是一个encoder的内部结构,一个Encoder是由Multi-Head Attention和全连接神经网络Feed Forward Network构成。如下图所示:
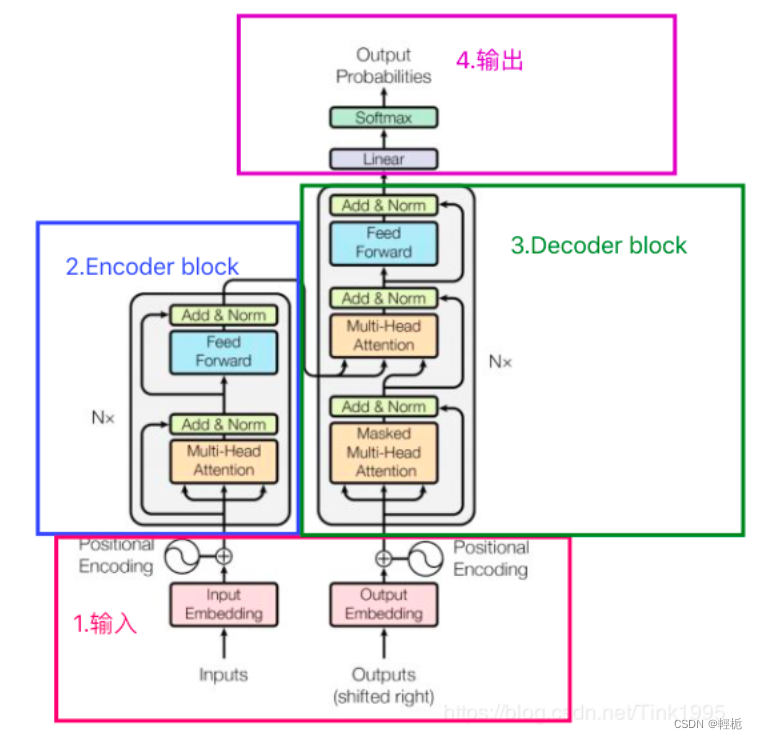
每一个编码器都对应上图的一个encoder结构:

Transformer的编码组件是由6个编码器叠加在一起组成的,解码器同样如此。所有的编码器在结构上是相同的,但是它们之间并没有共享参数。从编码器输入的句子首先会经过一个自注意力层,这一层帮助编码器在对每个单词编码的时候时刻关注句子的其它单词。解码器中的解码注意力层的作用是关注输入句子的相关部分,类似于seq2seq的注意力。原结构中使用到的是多头注意力机制(Multi-Head Attention)。
Multi-Head Attention:
数据集准备:
搭建模型:
数据预处理与模型训练:
模型评估与预测: